卷积神经网络
1.边缘检测
输入带有边界的图片
[[[ [10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0]
]]]#第一维度是batch,第二个维度是通道,第三个维度是高,第四个维度是宽
在图片中数字越大代表的像素越亮,所以上图中形成了明显的垂直明亮分界线
使用的检测垂直边界的卷积核
[[[[-1, 0, 1],
[-1, 0, 1],
[-1, 0, 1]]]]#第一个维度是几种kernel,也就是kernel的种数,第二个维度是有几个通道,第三个,第四个分别是高和宽
实验
import torch
import torch.nn.functional as F
if __name__ == '__main__':
w = torch.tensor([[[[-1, 0, 1],
[-1, 0, 1],
[-1, 0, 1]]]]) # 1种1通道的3乘3卷积核
# w=nn.Parameter(data=w, requires_grad=False)
print(w)
b = torch.tensor([0]) # 和卷积核种类数保持一致(不同通道共用一个bias)
print(b)
"""定义输入样本"""
x = torch.tensor([[[
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0]
]]]) # 1张1通道的6乘6的图像
print(x)
"""2D卷积得到输出"""
out = F.conv2d(x, w, b, stride=1, padding=0) # 步长为1,外加1圈padding,即上下左右各补了1圈的0,
print(out)
输出
[[[[ 0, -30, -30, 0],
[ 0, -30, -30, 0],
[ 0, -30, -30, 0],
[ 0, -30, -30, 0]]]]
可以看到很明显在中间为-30,两边为0,出现了一条分界线
边缘检测的算子sobel算子
sobel算子可以对边缘进行检测,sobel算子是一个包含差分和平滑的算子
垂直sobel算子
垂直sobel算子
[-1,0,1]
[-2,0,2]
[-1,0,1]
水平sobel算子
[1,2,1]
[0,0,0]
[-1,-2,-1]
本质是一次差分、一次平滑的连续运算。其中[1 0 -1]及其转置,分别表示水平差分和垂直差分;[1 2 1]及其转置,分别代表水平平滑和垂直平滑。
- 差分运算 计算是是像素值之间的差距
- 平滑:模糊:在提取较大目标前,去除太小细节,或将目标内的小间断连接起来。
消除噪声:改善图像质量,降低干扰。
平滑处滤波对图像的低频分量增强,同时削弱高频分量,用于消除图像中的随机噪声,起到平滑作用。
Scharr算子
Scharr算子是对Sobel算子差异性的增强,因此两者之间的在检测图像边缘的原理和使用方式上相同。Scharr算子的边缘检测滤波的尺寸为3×3,因此也有称其为Scharr滤波器。可以通过将滤波器中的权重系数放大来增大像素值间的差异,弥补Sobel算子对图像中较弱的边缘提取效果较差的缺点。
带有边缘检测功能还有
Laplacian算子
Canny算子
问题
观察上述卷积,会发现卷积后形成的图片相比原图片小了很多,而且边缘区域只进行了一次卷积,就会丢失大量的边缘信息,解决的办法使用padding,在原图片周围填充一块区域,这样在卷积后可以形成与原图片大小相同的图片,且边缘区域进行了多次计算,此为Same卷积,如果不进行填充为Valid卷积
strider
在进行卷积的时候的步长,当为1的时候filter在在图像上以1位长度进行卷积,可以设置其他的值,
计算卷积后的大小
\(\frac{n+2p-f}{s}+1\)向下取整 其中n为输入图片大小,p为padding大小,f为卷积核大小,s为步长
向下取整的操作反应在卷积上就是当卷积核在图像外部的时候不进行计算

就像上面的图片所示,由于步长s不是1,移动之后可能会跑到外部,所以这种外部的就不进行计算,这就是向下取整的直观表示
卷积核为什么大多是奇数
假设s=1,使用padding
\(n+2p-f+1=n \\
2p=f-1\\
p=\frac{f-1}{2}\)
- 当f为偶数的时候只能使用不对称padding,那么一边的边缘信息就会漏掉
- 奇数会有一个中心点,在计算机视觉中有一个中心点会方便一些
多通道卷积
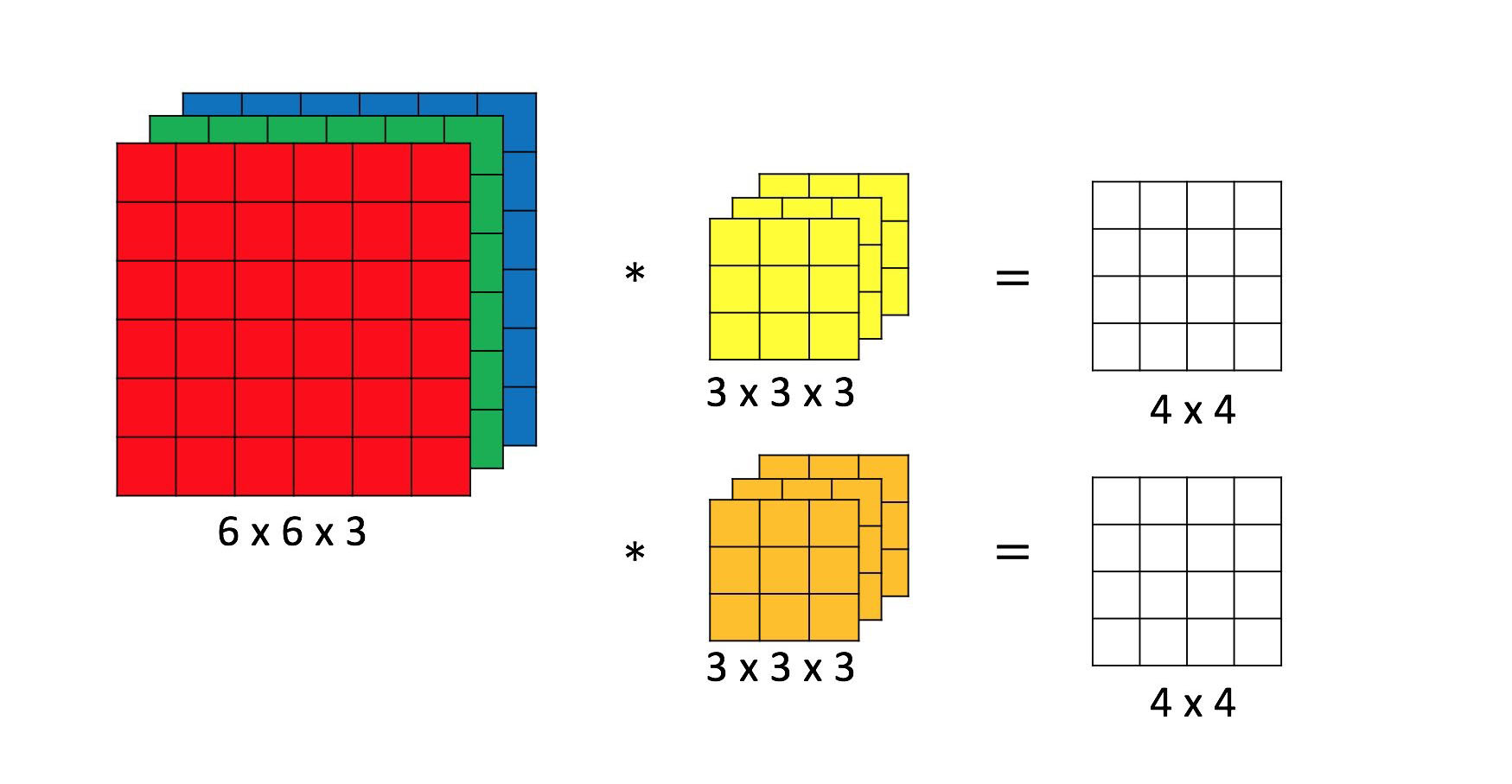
上图中为图片为3通道,卷积核为3通道,上图中卷积核有两种,输出为4*4的图片,然后经过一次线性变换和relu函数后就是一次卷积操作
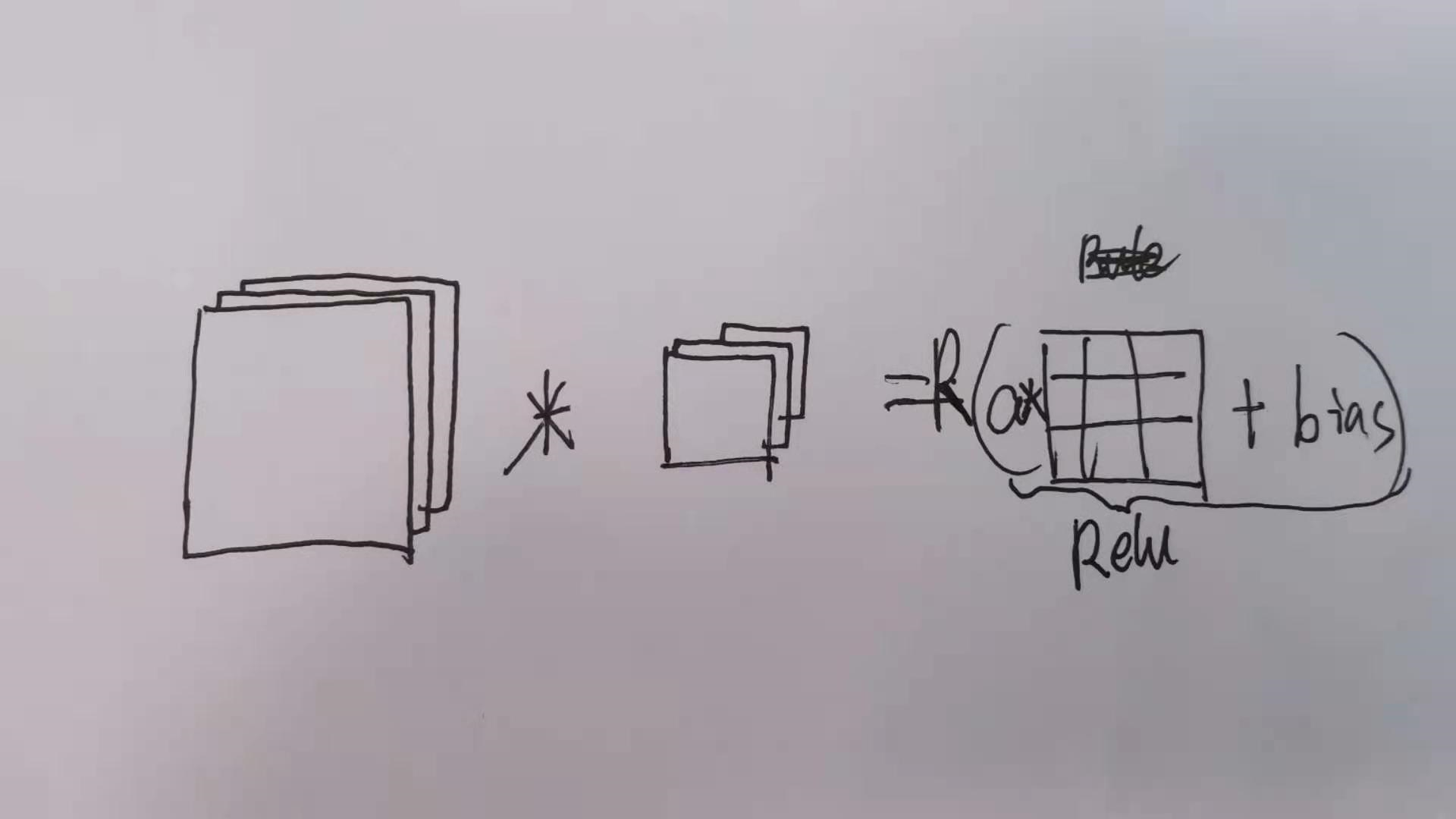
上图中将一个图片与一个卷积核进行运算,运算完成后进行线性运算然后经过relu函数
Relu函数
\(f(x)=max(0,x)\)
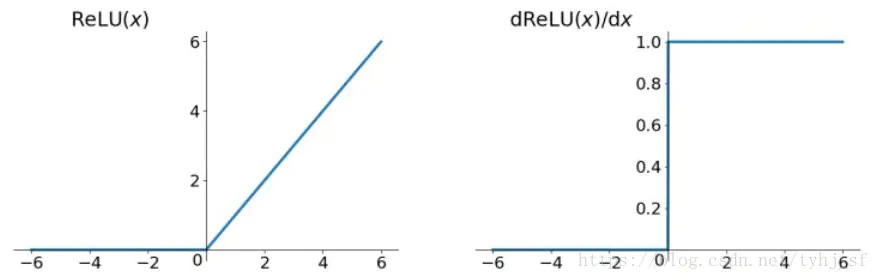
relu就是个取最大值的函数,当为负值的时候为0,当为正值的时候为x
relu的优势
- 不存在梯度消失问题
相比sigmoid图像
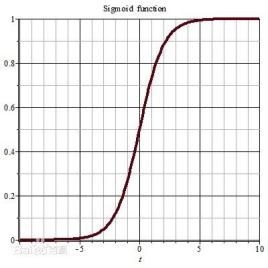
上图为isgmoid图像,当x大于3的时候梯度明显太小了,梯度消失,而观察rulu函数它的梯度在x>0一直保持不变
sigmoid在接近0的时候梯度具有较好的激活性,在其他区域梯度弥散 - 会使得数据更加的稀疏,在x小于0的时候,为0,而反观sigmoid函数在小于0的时候会输出一部分激励值,同时减少了参数之间的相互依赖关系,缓解了过拟合问题的发生
- 运算较快,相比sigmoid运算,要求幂,relu直接使用max
卷积神经网络中各个参数的数量
kernel:\(f^[l]*f^[l]*n^[l-1]\)
激活函数:a[1]的参数个数 n[l]*n[l]*channel
weight: kernel数*过滤器数量
bias=通道的数量
如何确定卷积核大小,卷积层数????
池化
- 最大池化:当有个象限中数字较大,意味着这个区域提取到了一个重要的特征,最大池化就是将这个最大数字,也就是提取到的特征保留下来,同时这样也就会减少了无用的信息,同时减少了参数,也起到一定防止过拟合的作用
- 平均池化:
在每个窗口中取平均值
原来人们认为池化可以保持平移不变性
CNN中平移不变性已经被证实是错误的
paper :Making Convolutional Network shift-Invariant Again
https://zhuanlan.zhihu.com/p/38024868
https://blog.csdn.net/ytusdc/article/details/107666902
其核心的问题在于下采样,下采样导致的
相关视频https://www.bilibili.com/video/av63925068
约定一些符号表达
第一个代表原始图片3通道,经过一系列的卷积后它的分辨率变为了第一个式子,然后我们进行上采样到与原来图片一样的分辨率
上采样的方法??
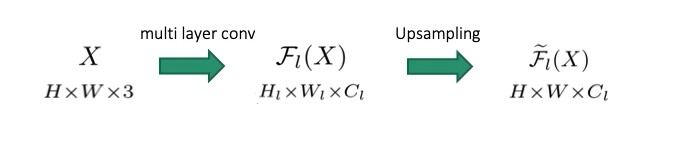
平移相等性
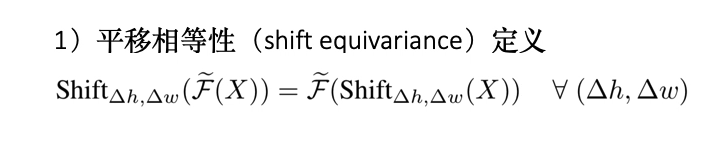
这个就是对输入做平移后的输出等于输入不做平移输出做平移
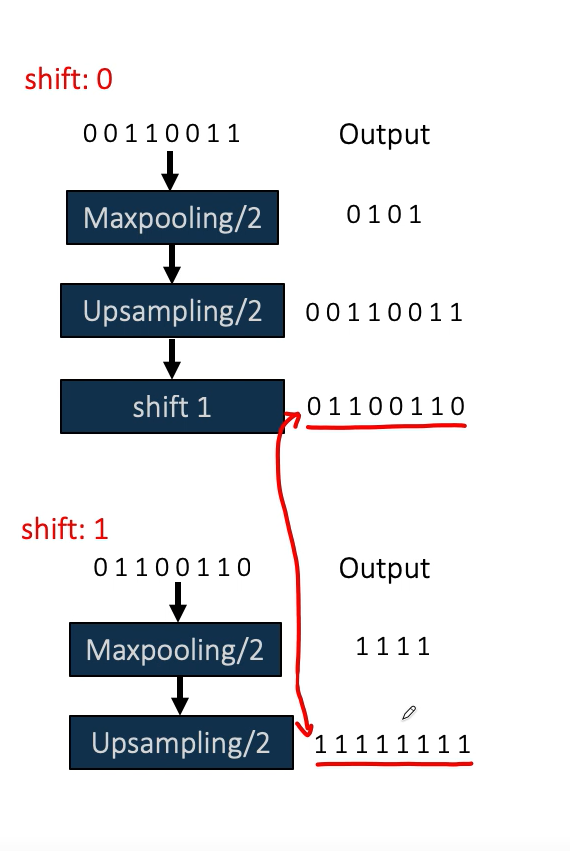
为了简化我们取原始图片为00110011为一维,shift0就是输入不做平移输出做平移,shift1就是输入做平移输出不做平移,很明显这俩不等(做的是左移,maxpooling),左边箭头叫平移相等性
平移相等的程度,就是上述式子两边之间的差距,也就是输入做平移后的输出与输入不做平移输出做平移后结果差距的度量

平移不变性,输入无论怎样平移它的输出是不变的,举个例子,识别猫咪,无论猫咪在图中的什么位置,它总能识别为猫咪
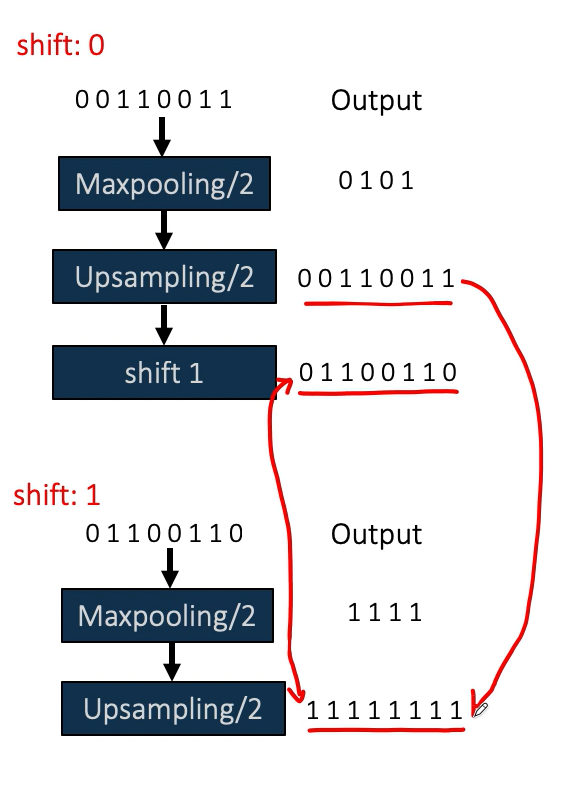
右边箭头是平移不变性
如何保持平移不变性
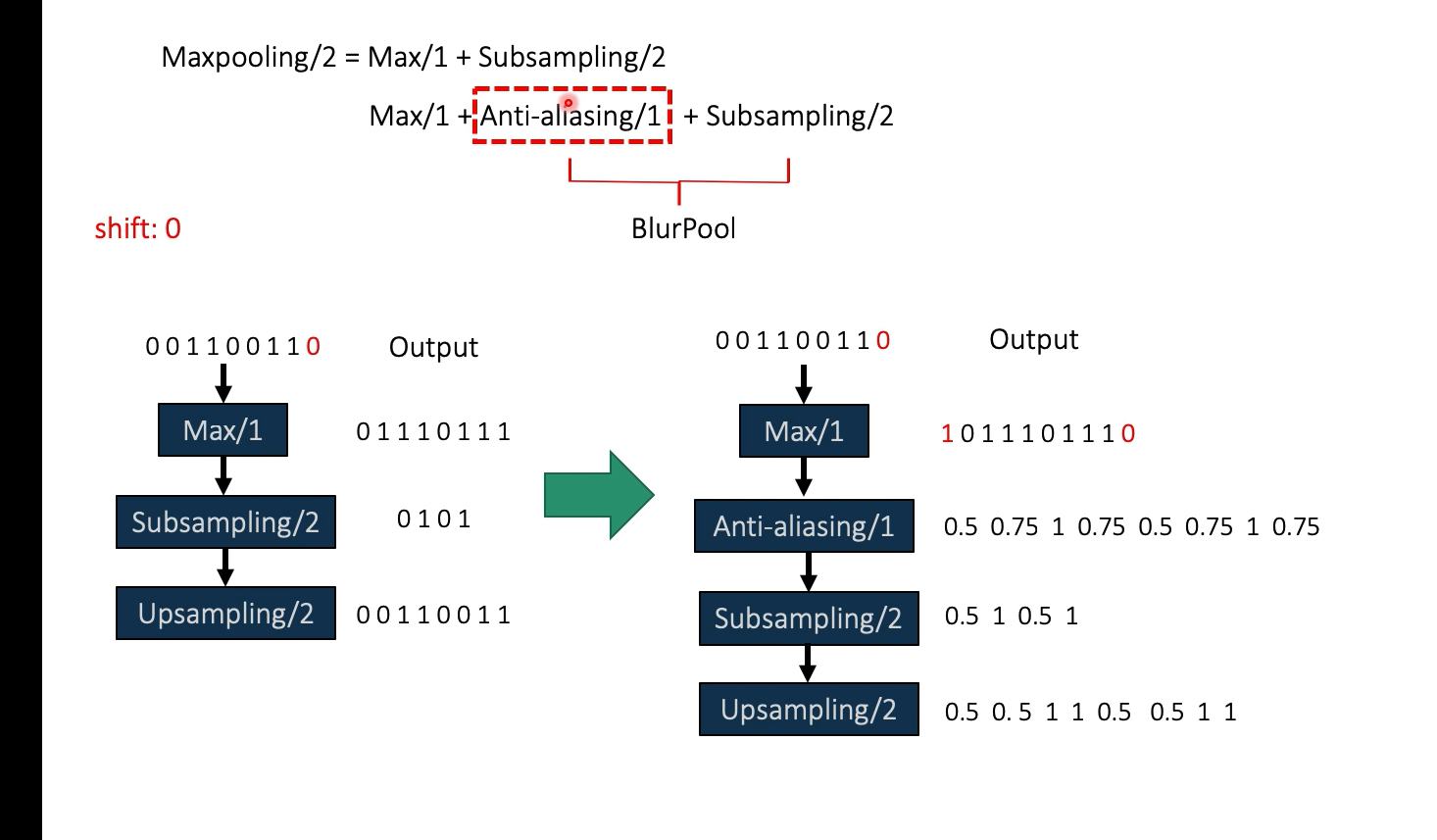
这个式子来自于文章,作者发现步长为2的maxpooling等价于一个先做一个步长为1 的max然后进行步长为2的下采样
作者在两者之间加入了一个步长为1的抗锯齿操作,将抗锯齿与采样称作BlurPool,其中的下采样只是在步长为2的相应点进行采样,不做max,比如01110111,下采样在第一个点0,第三个点1,第5个点0,第7个点1 则下采样为0101,
上述图片中下面的流程最后又上采样回了原来的分辨率
对于开头的平移相等性

可以看到在不加抗锯齿操作的时候,距离为0.71,加了之后为0.95
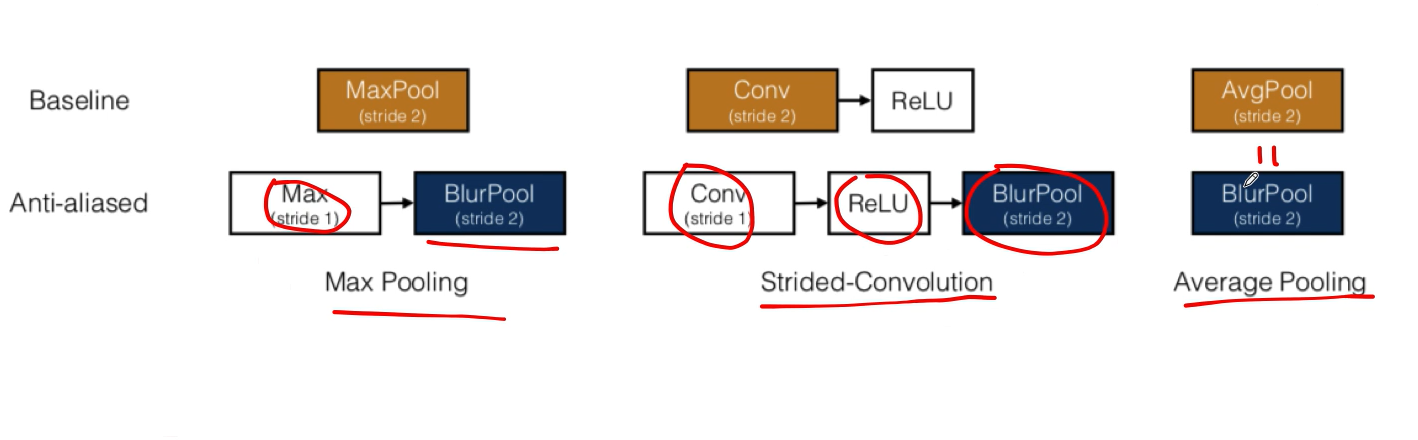
上面这个图片是各种卷积池化是怎样抗锯齿的,可以看到平均池化与blurpool是相等的,平均池化天生就具有抗锯齿的能力
冲量梯度下降
梯度下降法有什么缺点?
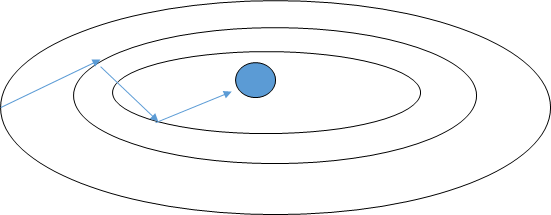
如上图梯度下降法,如果步长设置的很大就会造成很大的摆动,因为步子偏离目标,而且当步子设置很大就会造成震荡现象,是以折线前进,这样每次只是很小的靠近目标,而动量梯度下降,减小了摆动,可以使用大的步长前进,加快了收敛的速度
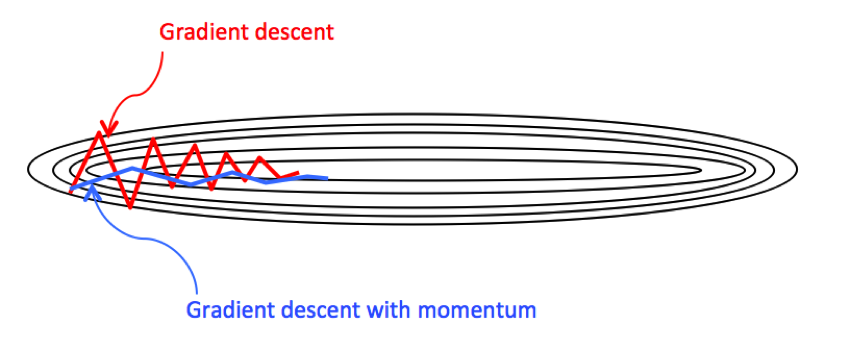
要理解冲量梯度下降就要首先知道指数加权平均
指数加权平均
假设有一些数据Q1...QN,要对数据进行拟合
\({v_0=0\\
v1=v0*\beta+(1-\beta)Q1\\
v2=v1*\beta+(1-\beta)Q2\\
...........
\\
v_n=v_{n-1}*\beta(1-\beta)Q_n
}\)
上面的每一步当中v1....vn都是我们的拟合点,分析一下式子,其中假设v100存在,v100的值是由v99*B+当前数据Q100得来的,在考虑v99怎么来的就会发现v100其实考虑了前面的数据,这样表现在图表上就是拟合曲线较为平滑,不会有较大的上下波动,其实就是平滑数据的作用。那么问题来了,这个数据是用了之前所有的数据进行平滑,但是越靠近当前数据的数据影响会越大,当之前的数据影响在1/e以下的时候就可以忽略掉这个之前数据的影响,也就是之前数据对现在数据的影响有一个窗口,这个窗口多大呢?大约是1/(1-B),也就是当B=0.9的时候考虑之前9个数据,当B增大的时候,考虑的窗口将会更大
1/e怎么来的
\(lim_{\beta->1}=(\beta)^{\frac{1}{1-\beta}}\)
由此看出指数加权平均会平滑数据,但是当开始的时候数据很少,计算当前值考虑的数据也很少就会造成拟合点的不准确误差较大,这个时候就要对偏差进行校正
上面的v2变为
\(\frac{v_2}{1-B^2}=\frac{\beta*(1-\beta)Q_1+(1-\beta)Q_2}{1-\beta^2}\)
其实分母来自于分子系数之和,由此修正误差可以在开始的所有位置上\(\frac{v_i}{1-B^t}\),t表示正在计算第几个数据,当度过开始阶段后t变大,B <1 这样分母接近1,将会与不修正偏差的拟合点极度接近,从而拟合曲线重合,也就是刚开始的时候会有一点点区别
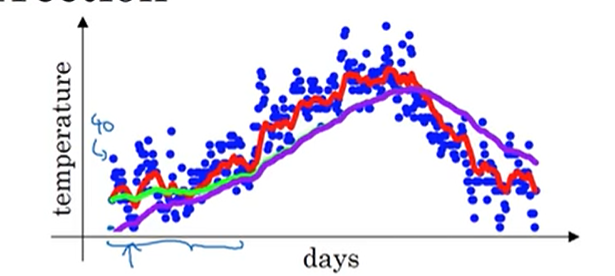
就像上面图,绿色与紫色,紫色为修正后曲线,绿色为未修正。
回到冲量梯度下降,冲量梯度下降的计算为
\(V_{d_w}^i=\beta*V_{d_w}^{i-1}+(1-\beta)*d_w\)其中i表示迭代的步,不是幂次,dw指代当前梯度,通过上述的指数加权平均能够看到具有平滑数据的作用,同样这里就会使得摆动的幅度减小,从而可以使用大的学习率进行学习,收敛速度也就更快
卷积神经网络
卷积神经网络有很多种,但都是卷积后池化,然后经过一个全连接层
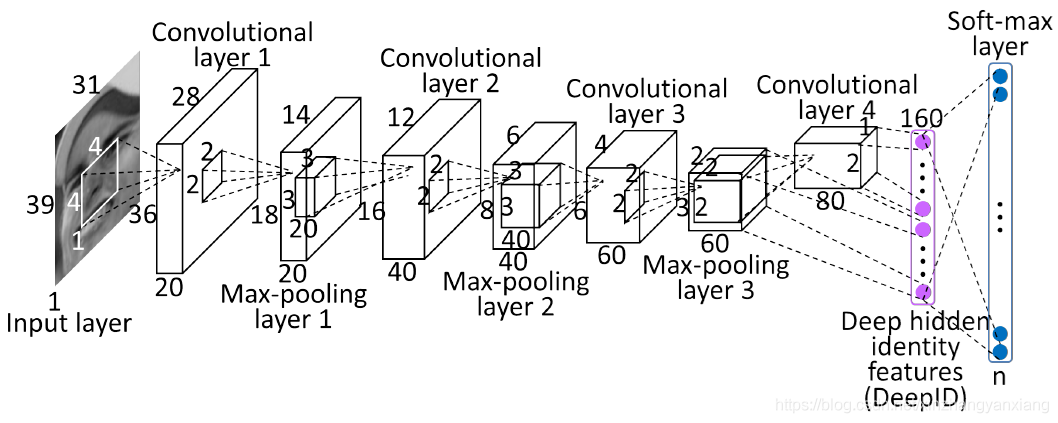
具体结构可以自己去设计,经典的网络以后VGG,CNN,LeNet,AlexNet
为什么使用卷积
1.减少参数
如果我们输入一个图片放入一个全连接层中会怎么样,假设图片25251全连接层输入有5个节点,那么参数总共25255,当输入的图片再大呢,参数就会非常的多,而使用卷积,参数只有卷积核的参数需要学习
2. 参数共享
全连接网络每一个像素都会有一个权值,而卷积神经网络,通过卷积,在一幅图片上仅仅使用卷积核大小的参数,一幅图片共享卷积核参数,不需要针对每个像素去学习参数,
3.稀疏连接
卷积后每一个值只是局部数据的计算,与卷积核之外的数据没有关系,因此具有防止过拟合的作用,从物理意义上看,现实中很多数据具有局部特性,卷积操作可以先学习数据的局部特征,然后将局部特征组合成复杂和抽象的特征。
深度学习在进行之前要对数据做均值和标准差处理
为什么?
- 卷积中有很多的通道,可以防止某个或者多个维度数据过大而掩盖其他的维度。
2.同时对于一些噪声数据可以减少它们的影响。
实现卷积神经网络
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def run():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
if __name__ == '__main__':
run()
参考
sobel https://www.zhihu.com/question/266037140/answer/302331745
scharr https://zhuanlan.zhihu.com/p/332493443
l ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号