Datawhale 吃瓜教程 Task01打卡
Datawhale 吃瓜教程 Task01打卡
感觉西瓜书蛮新手友好的,前两章都是在不厌其烦的介绍基础概念。
数据集就是我们要让机器学习的东西,希望机器能从中学习到“经验”,产生模型,从而在面对新情况(数据集以外的数据)也能做出有效的判断与决策。
- 特征(属性):反应事物或对象在某方面的表现或性质的事项,例如“色泽”,“根蒂”,“敲声”
- 属性值:属性上的值,比如说色泽可分为“青绿”,“乌黑”等,这些就可称为属性值
- 属性空间,样本空间,输入空间都指的是属性张成的空间
- 特征向量:假如把“色泽”,“根蒂”,“敲声”作为三个坐标轴,在这个三维空间中,每个西瓜都有一个坐标位置(x,y,z),而空间中的每个点对应一个坐标向量,这样向量就叫特征向量
- 维数:有多少个属性描述数据集中的单个样本,就说数据集样本的维数是多少
过拟合与欠拟合
机器学习学到的其实是数据中的某种潜在规律,也就是说对于训练模型使用的训练集越大越好,越全越好。并且训练得到的模型并不是说在训练样本上效果好就代表我们得到了一个效果非常好的模型了,因为这可能意味着过拟合。
当模型在训练集表现的特别好时,需要注意是否有过拟合问题
过拟合的意思是说模型的学习能力过于强大,以至于把训练样本中所包含的不太一般的特性都学到了。比如因为训练样本全是锯齿状树叶,导致模型错误的认为所有的树叶都得是锯齿形状,其他形状的树叶都一律判断为非树叶。
所以我们的测试样本要尽可能的不出现在训练集中,这样能够测试模型的泛化能力。
泛化指的是训练好的模型在前所未见的数据上的效果的好坏

与过拟合相反的是欠拟合——学习能力过于低下,连样本的一般特性都无法学到。
相较于过拟合而言,欠拟合的问题比较容易解决,例如在神经网络学习中增加训练轮数,在决策树学习中扩展分支。而过拟合无法被彻底避免,因为我们无法完全控制模型学习到的特征。
模型评估方法
评估模型通常需要一个测试集来测试模型对新样本的判别能力。并且测试样本要尽可能的不出现在训练集中,因为再去考机器它之前做过的“题”,无法反应出它的泛化能力。
测试集的划分
流出法
- 将数据集 D 划分成两份互斥的数据集,一份作为训练集 S,一份作为测试集 T,在 S 上训练模型,在 T 上评估模型效果
- 训练集与测试集的划分要尽可能保持数据分布的一致性,避免引入额外偏差对结果造成影响。
- 单次使用留出法往往不够稳定可靠,在使用留出法时,一般要采用若干次所及划分、重复进行实验评估后取平均值作为留出法的估计结果。
- 缺点:划分数据集时,测试集小时,评估结果的方差较大;训练集小时,评估结果的偏差较大。所有一般是将大约2/3~4/5的样本用于训练,剩余样本用于测试
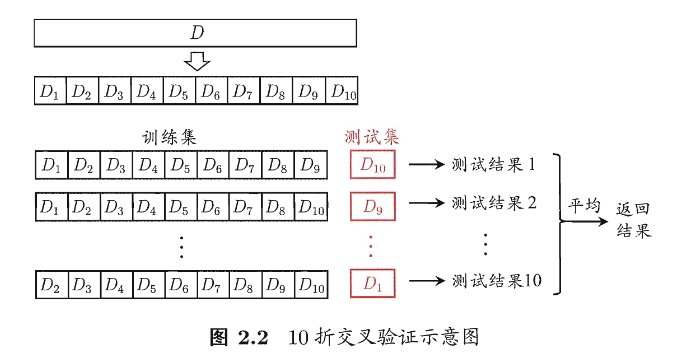
交差验证法
-
先将数据集D划分为k个大小相似的互斥子集,每个子集Di都是通过分层采样得到,然后每次用k-1个子集的病机作为训练集,余下的那个子集作为测试集,从而可以获得k组训练/测试集,进行k次训练和测试,最终返回k个测试结果的均值。
-
k折交叉验证通常要随机使用不同的划分重复p次,最终的评估结果是这p次k折交叉验证结果的均值
-
缺点:数据量大时比较耗时
自助法
- 以自主采样为基础,使用有放回的重复采样的方式进行训练集、测试集的构建。比如为了构建 m 条样本的训练集,每次从数据集 D 中采样放入训练集,然后有放回重新采样,重复 m 次得到 m 条样本的训练集,然后将将没有出现过的样本作为测试集
- 包外估计:这样实际评估的模型与期望评估的模型都使用m个训练样本,仍有数据总量月1/3的、没在训练集中出现过的样本用于测试。
- 优点:
- 减少训练样本不同造成的影响
- 在数据集较小、难以有效划分训练/测试数据集时很有用
- 从初始训练集中产生多个不同的训练集,对集成学习等方法有很大好处。
- 缺点:改变了原始数据集的分布,会引入估计偏差
性能度量
-
回归任务最常用的性能度量是“均方误差”
-
分类任务中常用的性能度量则有:错误率、精度、查准率、查全率、F1、ROC与AUC
-
错误率:
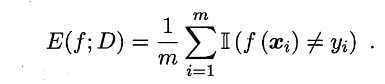
-
精度:
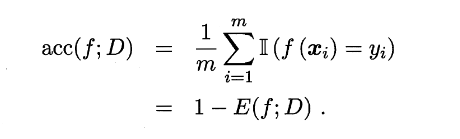
- 查准率与查全率不可兼得,因为如果希望将好瓜尽可能选出来,则可以通过添加选瓜的数量来实现,但如果把所有的西瓜都选上,那么虽然所有好瓜被选上了,但查准率就会降低。