

sklearn.neighbors.KNeighborsClassifier
(1)fit(X, y) : Fit the model using X as training data and y as target values(把X当做训练数据,把y当做真值来训练我们的模型)
其中,X 和y的类型如下:如果看不懂也没关系,就把X和y都看作是矩阵

(2)predict(X) :Predict the class labels for the provided data(预测数据究竟属于哪一类)
X的类型和返回值为:

(3) predict_proba(X):Return probability estimates for the test data X.(返回预测数据针对属于各个类别的可能性)

举例:
import numpy as ny from sklearn import neighbors x_train = ny.array([[1,2], [1,3], [2,2], [2,4]]) y_target = ny.array([0,0,1,1]) x_test = ny.array([[1,1], [1,4], [2,1], [5,6]]) knn=neighbors.KNeighborsClassifier(algorithm='kd_tree',n_neighbors=3) knn.fit(x_train,y_target) pre_result = knn.predict(x_test) pre_proba = knn.predict_proba(x_test) print "The pre_result is",pre_result print "The pre_proba is:\n",pre_proba
运行结果:
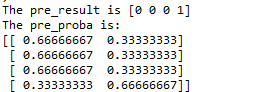
对x_test中的四组数据的测试结果分别为[0,0,0,1]
pre_proba中的每一行代表x_test中每一个测试数据取0和1的概率。
未完待续。。。
