
笔记:《linux就该这么学》-刘遄
 Linux就该这么学--刘遄 著
Linux就该这么学--刘遄 著
没看完,但会持续更新到本条随笔中,只记我个人认为有用的,尤其是在前言部分中
官网已经更新书籍第二版的电子书资源了,有兴趣的可以去官网linux就该这么学第2版 看看,(我第一版还没更看完呢...)
我了怎么生成目录了,使用[TOC]+一行空行即可生成(有没有人知道为什么在段落前加缩进或者加空格,结果都无效呢...是因为md语法不存在段落的概念吗...内容都放在了一行)
- 前言
- 第一章 部署虚拟环境安装Linux 系统
- 第二章 新手必须掌握的Linux 命令
- 第三章 管道符、重定向与环境变量(自行看第二版吧,不继续写笔记了)
- 第四章 Vim 编辑器与Shell 命令脚本(自行看第二版吧,不继续写笔记了)
- 第五章 用户身份与文件权限(自行看第二版吧,不继续写笔记了)
- 第六章 存储结构与磁盘划分
- 第七章 使用RAID 与LVM 磁盘阵列技术(自行看第二版吧,不继续写笔记了)
- 第八章 iptables 与firewalld 防火墙(自行看第二版吧,不继续写笔记了)
- 第九章 使用ssh 服务管理远程主机(自行看第二版吧,不继续写笔记了)
- 第十章 使用Apache 服务部署静态网站(自行看第二版吧,不继续写笔记了)
- 第十一章 使用vsftpd 服务传输文件(自行看第二版吧,不继续写笔记了)
- 第十二章 使用Samba 或NFS 实现文件共享(自行看第二版吧,不继续写笔记了)
- 第十三章 使用BIND 提供域名解析服务(自行看第二版吧,不继续写笔记了)
- 第十四章 使用DHCP 动态管理主机地址(自行看第二版吧,不继续写笔记了)
- 第十五章 使用Postifx 与Dovecot 部署邮件系统(自行看第二版吧,不继续写笔记了)
- 第十六章 使用Squid 部署代理缓存服务(自行看第二版吧,不继续写笔记了)
- 第十七章 使用iSCSI 服务部署网络存储(自行看第二版吧,不继续写笔记了)
- 第十八章 使用MariaDB 数据库管理系统(自行看第二版吧,不继续写笔记了)
- 第十九章 使用PXE+Kickstart 无人值守安装服务(自行看第二版吧,不继续写笔记了)
- 第二十章 使用LNMP 架构部署动态网站环境(自行看第二版吧,不继续写笔记了)
前言
开源许可协议
GUN GPL(GUN General Public License,GNU通用公共许可证)
"最开源"的协议.软件中使用了遵循GPL的产品或代码,则该软件也得遵循GPL,即必须开源、免费(但帮别人解决问题收服务费是可以的),不适合商用软件.遵循GPL的软件,允许自由复制、自由传播、收费传播(但必须让买家知道软件是可以免费获取的)、自由修改(修改后的软件也遵循GPL).
BSD(Berkeley Software Distribution,伯克利软件发布版)许可协议
自由修改、收费传播,如果修改后的软件中包含遵循BSD的源代码,则修改后的软件也当遵循BSD,即也允许修改,允许修改后商用,但是不能用原软件的名字,用原作者的名字,用原机构的名字做推广(所以我只说了收费传播没说自由传播).
Apache 许可证版本(Apache License Version)许可协议
自由修改、收费传播,修改后的软件也必须遵守Apache协议,修改了源码的话需要声明更改的地方,如果软件是基于他人的源码编写而成,需保留原始代码的协议、商标、专利声明及其他作者声明的内容信息(Apache与其他协议共存).
MPL(Mozilla Public License,Mozilla 公共许可)许可协议
相较于GPL许可协议,MPL更加注重对开发者的源代码需求和收益之间的平衡.
MIT(Massachusetts Institute of Technology)许可协议
目前限制最少的开源许可协议之一,自由修改、自由传播、收费传播、不必开源,只要程序的开发者在修改后的源代码中保留原作者的许可信息即可,因此普遍被商业软件所使用。
常见的linux系统版本
首先需要区分Linux 系统内核与Linux 发行套件系统的不同
- Linux 系统内核指的是一个由Linus Torvalds 负责维护,提供硬件抽象层、硬盘及文件系统控制及多任务功能的系统核心程序。
- Linux 发行套件系统是我们常说的Linux 操作系统,也即是由Linux 内核与各种常用软件的集合产品
我可不可以理解为Linux操作系统=Linux内核+定制的软件,封装在了一起?类似国内各种手机操作系统,是从安卓原生改UI、改内置软件而成。
热门的几个Linux操作系统
-
红帽企业版Linux(RedHat Enterprise Linux,RHEL):
红帽公司是全球最大的开源技术厂商,RHEL 是全世界内使用最广泛的Linux 系统。RHEL 系统具有极强的性能与稳定性,并且在全球范围内拥有完善的技术支持。RHEL 系统也是本书(即《Linux就该这么学》)、红帽认证以及众多生产环境中使用的系统。

-
社区企业操作系统(Community Enterprise Operating System,CentOS):
通过把RHEL 系统重新编译并发布给用户免费使用的Linux 系统,具有广泛的使用人群。CentOS 当前已被红帽公司“收编”。

-
Fedora:
由红帽公司发布的桌面版系统套件(目前已经不限于桌面版)。用户可免费体验到最新的技术或工具,这些技术或工具在成熟后会被加入到RHEL 系统中,因此Fedora 也称为RHEL系统的“试验田”。运维人员如果想时刻保持自己的技术领先,就应该多关注此类Linux 系统的发展变化及新特性,不断改变自己的学习方向。

-
openSUSE:
源自德国的一款著名的Linux 系统,在全球范围内有着不错的声誉及市场占有率。

-
Gentoo:
具有极高的自定制性,操作复杂,因此适合有经验的人员使用。读者可以在学习完本书后尝试一下该系统。

-
Debian:
稳定性、安全性强,提供了免费的基础支持,可以良好地支持各种硬件架构,以及提供近十万种不同的开源软件,在国外拥有很高的认可度和使用率。

-
Ubuntu:
是一款派生自Debian 的操作系统,对新款硬件具有极强的兼容能力。Ubuntu 与Fedora 都是极其出色的Linux 桌面系统,而且Ubuntu 也可用于服务器领域。

Ubuntu因为其类似windows桌面的原因是我第一个接触的Linux系统
现在国内大多数Linux 相关的图书都是围绕CentOS 系统编写的,作者大多也会给出围绕CentOS 进行写作的一系列理由,但是很多理由都站不住脚,根本没有剖析到CentOS系统与RHEL 系统的本质关系。CentOS 系统是通过把RHEL 系统释放出的程序源代码经过二次编译之后生成的一种Linux 系统,其命令操作和服务配置方法与RHEL 完全相同,但是去掉了很多收费的服务套件功能,而且还不提供任何形式的技术支持,出现问题后只能由运维人员自己解决。经过这般分析基本上可以判断出,选择CentOS 的理由只剩下—免费!当人们大举免费、开源、正义的旗帜来宣扬CentOS 系统的时候,殊不知CentOS 系统其实早在2014 年年初就已经被红帽公司“收编”,当前只是战略性的免费而已。再者说,根据GNU GPL 许可协议,我们同样也可以免费使用RHEL 系统,甚至是修改其代码创建衍生产品。开源系统在自由程度上没有任何差异,更无关道德问题。
本书是基于最新的RHEL 7 系统编写的,书中内容及实验完全通用于CentOS、Fedora 等系统。也就是说,当您学完本书后,即便公司内的生产环境部署的是CentOS 系统,也照样可以搞得定。更重要的是,本书配套资料中的ISO 镜像与红帽RHCSA 及RHCE 考试基本保持一致,因此更适合备考红帽认证的考生使用。
随书配备的 ISO 镜像文件下载地址:http://www.linuxprobe.com/tools
深度评解红帽 RHCSA、RHCE、RHCA 认证:http://www.linuxprobe.com/redhat-certificate
红帽认证资格
其认证主要包括红帽认证系统管理员(RHCSA)、红帽认证工程师(RHCE)与红帽认证架构师(RHCA)。且只有先通过红帽RHCSA 认证后才能考取红帽RHCE 认证。
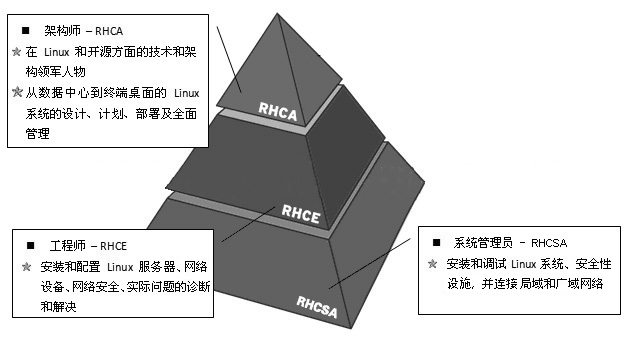
上图为红帽进阶等级图
红帽认证系统管理员(Red Hat Certified System Administrator,RHCSA)
属于Linux 系统的初级认证,比较适合Linux 爱好者。该认证要求考生对Linux 系统有一定的了解,并且能够熟练使用Linux 命令来完成以下任务:
- 管理文件、目录、文档以及命令行环境;
- 使用分区、LVM 逻辑卷管理本地存储;
- 安装、更新、维护、配置系统与核心服务;
- 熟练创建、修改、删除用户与用户组,并使用 LDAP 进行集中目录身份认证;
- 熟练配置防火墙以及 SELinux 来保障系统安全。
证书示意图如下(作者刘遄的证书):

红帽认证工程师(Red Hat Certified Engineer,RHCE)
属于Linux 系统的中级水平认证,难度相对RHCSA 认证来讲更大,而且要求考生必须已获得RHCSA 认证。该认证适合有基础的Linux 运维管理员,主要考察对下列服务的管理与配置能力:
- 熟练配置防火墙规则链与 SElinux 安全上下文;
- 配置 iSCSI(互联网小型计算机系统接口)服务;
- 编写 Shell 脚本来批量创建用户、自动完成系统的维护任务;
- 配置 HTTP/HTTPS 网络服务;
- 配置 FTP 服务;
- 配置 NFS 服务;
- 配置 SMB 服务;
- 配置 SMTP 服务;
- 配置 SSH 服务;
- 配置 NTP 服务。
证书示意图如下(作者刘遄的证书):

红帽认证架构师(Red Hat Certified Architect,RHCA)
属于Linux 系统的最高级别认证,是公认的Linux 操作系统顶级认证,目前中国仅有不到1000 人(2017 年更新数据)持有该认证。考生需要在获得RHCSA 与RHCE 认证后再完成5 门课程的考试才能获得RHCA 认证,因此难度最大,备考时间最长,费用也最高(考试费约在1.8 万元~2.1 万元人民币)。该认证考察的是考生对红帽卫星服务、红帽系统集群、红帽虚拟化、系统性能调优以及红帽云系统的安装搭建与维护能力。
证书示意图如下(作者刘遄的证书):

红帽RHEL 7 版本的RHCA 认证需要完成至少5 门考试。这5 门考试的时间不同,但均为210 分合格(70%)。而且红帽公司非常注重RHCA 架构师认证的实用性,所以课程总是在随行业趋势而不断调整。
下表为 2017 年最新版的考试课程。欲取得红帽RHCA 认证,您必须通过以下任意5 门认证考试。
考试代码 认证名称 EX210 红帽 OpenStack 认证系统管理员考试 EX220 红帽混合云管理专业技能证书考试 EX236 红帽混合云存储专业技能证书考试 EX248 红帽认证 JBoss 管理员考试 EX280 红帽平台即服务专业技能证书考试 EX318 红帽认证虚拟化管理员考试 EX401 红帽部署和系统管理专业技能证书考试 EX413 红帽服务器固化专业技能证书考试 EX436 红帽集群和存储管理专业技能证书考试 EX442 红帽性能调优专业技能证书考试
由于markdown会自动根据标题等级生成目录,故不专门记录书中目录部分
第一章 部署虚拟环境安装Linux 系统
1.1 准备您的工具
一台电脑
1.2 安装配置VM 虚拟机
VMware WorkStation,试用30天;
点击创建新的虚拟机,使用典型配置,选择稍后安装操作系统
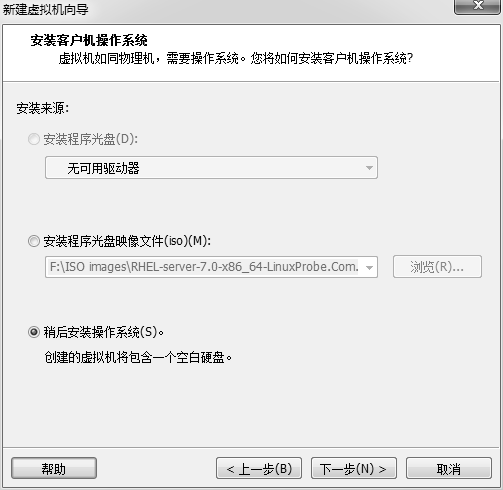
将客户机操作系统的类型选择为“Linux”,版本为“Red Hat Enterprise Linux7 64 位”,然后单击“下一步”
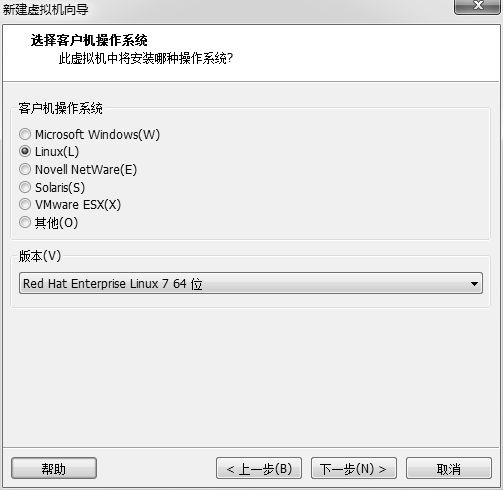
自定义配置(除了虚拟机安装位置都可以默认)
光驱设备此时应在“使用ISO 镜像文件”中选中了下载好的RHEL 系统镜像文件
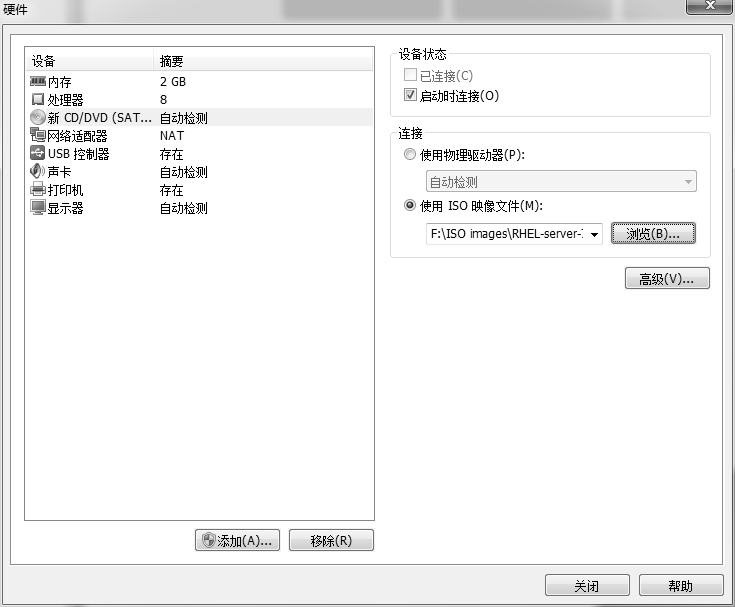
VM 虚拟机软件为用户提供了 3 种可选的网络模式,分别为桥接模式、NAT 模式与仅主机模式。这里选择“仅主机模式”
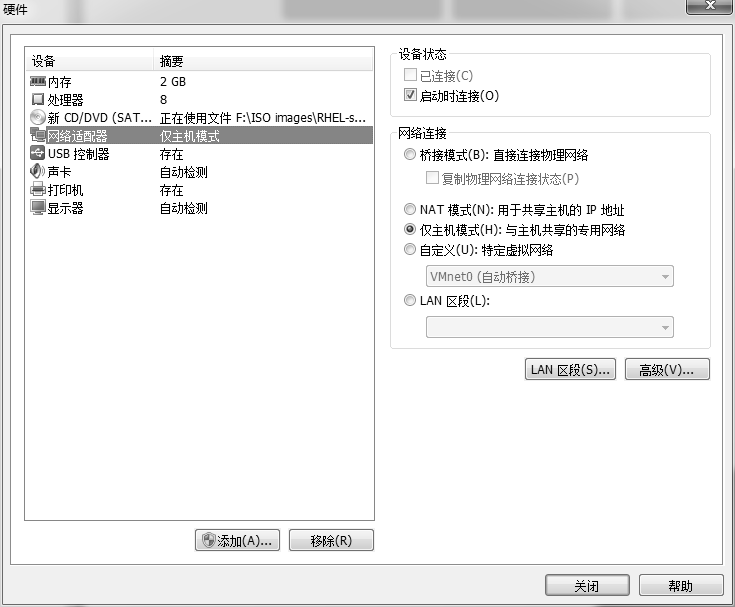
- 桥接模式:相当于在物理主机与虚拟机网卡之间架设了一座桥梁,从而可以通过物理主机的网卡访问外网。
- NAT模式:让 VM 虚拟机的网络服务发挥路由器的作用,使得通过虚拟机软件模拟的主机可以通过物理主机访问外网,在真机中 NAT 虚拟机网卡对应的物理网卡是VMnet8。
- 仅主机模式:仅让虚拟机内的主机与物理主机通信,不能访问外网,在真机中仅主机模式模拟网卡对应的物理网卡是 VMnet1。
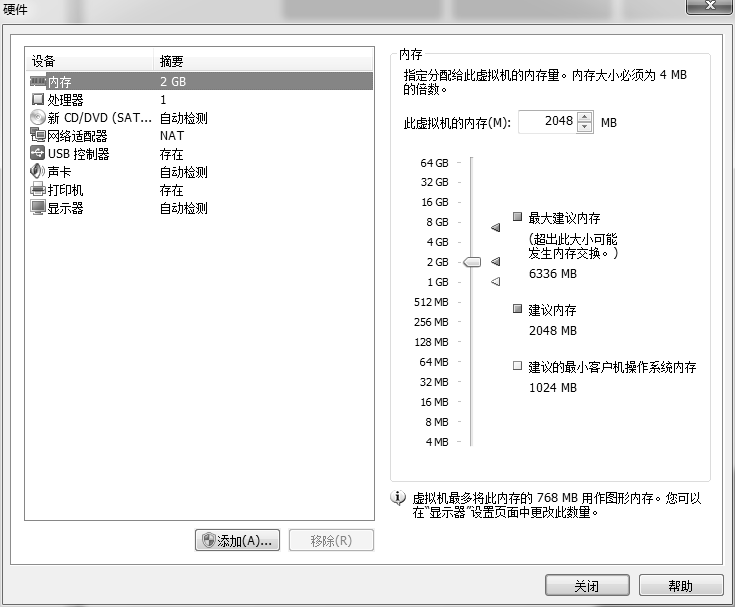
把 USB 控制器、声卡、打印机设备等不需要的设备统统移除掉。移掉声卡后可以避免在输入错误后发出提示声音,确保自己在今后实验中思绪不被打扰。然后单击“关闭”按钮,最终的虚拟机配置情况如下图:
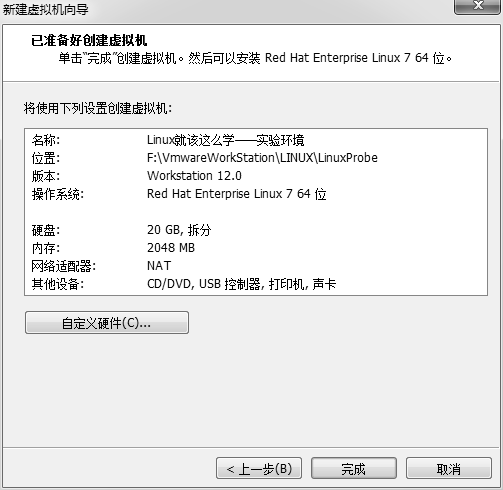
返回到虚拟机配置向导界面后单击“完成”按钮,如下图所示。虚拟机的安装和配置顺利完成。
当看到下图所示的虚拟机配置成功界面时,就说明您的虚拟机已经被配置成功了。接下来准备步入属于您的 Linux 系统之旅吧。
1.3 安装您的Linux 系统
这里教的是安装有图形化界面的RH7系统,不知道是否影响学习纯命令行的linux...
安装 RHEL 7 或 CentOS 7 系统时,您的电脑的 CPU 需要支持 VT(VirtualizationTechnology,虚拟化技术)。所谓 VT,指的是让单台计算机能够分割出多个独立资源区,并让每个资源区按照需要模拟出系统的一项技术,其本质就是通过中间层实现计算机资源的管理和再分配,让系统资源的利用率最大化。其实只要您的电脑不是五六年前买的,价格不低于三千元,它的 CPU 就肯定会支持 VT 的。如果开启虚拟机后依然提示“CPU 不支持 VT 技术”等报错信息,请重启电脑并进入到 BIOS 中把 VT 虚拟化功能开启即可。
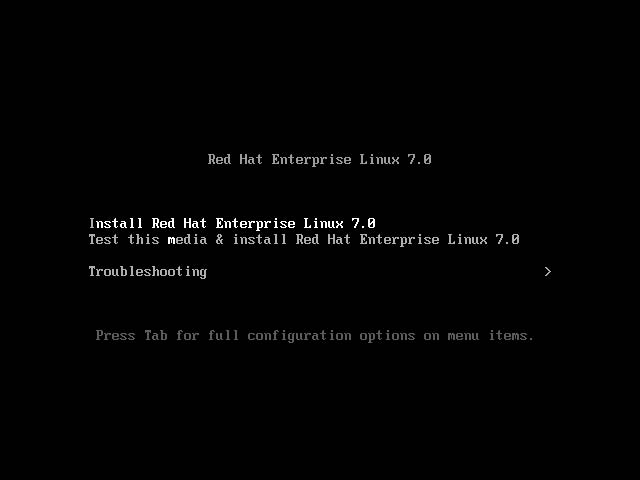
在虚拟机管理界面中单击“开启此虚拟机”按钮后数秒就看到 RHEL 7 系统安装界面,如图所示。在界面中,Test this media & install Red Hat Enterprise Linux 7.0 和Troubleshooting 的作用分别是校验光盘完整性后再安装以及启动救援模式。此时通过键盘的方向键选择 Install Red Hat Enterprise Linux 7.0 选项来直接安装 Linux 系统。
接下来按回车键后开始加载安装镜像,所需时间大约在 30~60 秒,请耐心等待,如图所示。
选择系统的安装语言后单击 Continue 按钮,如图所示。
在安装界面中单击 SOFTWARE SELECTION 选项,如图。
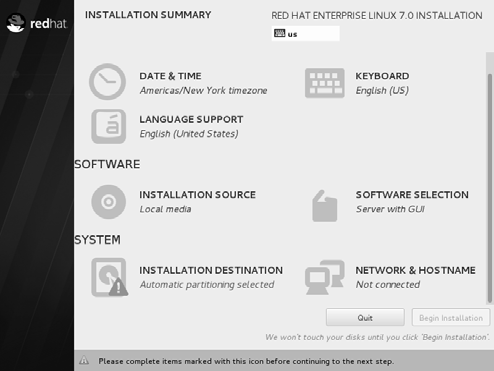
RHEL 7 系统的软件定制界面可以根据用户的需求来调整系统的基本环境,例如把 Linux系统用作基础服务器、文件服务器、Web 服务器或工作站等。此时您只需在界面中单击选中Server with GUI 单选按钮,然后单击左上角的 Done 按钮即可,如图。

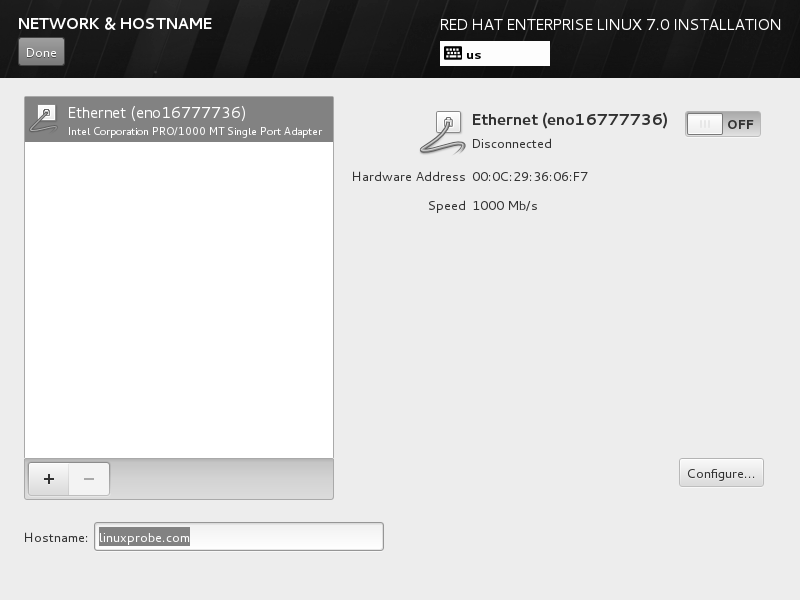
返回到 RHEL 7 系统安装主界面,单击 NETWORK & HOSTNAME 选项后,将 Hostname字段设置为 linuxprobe.com,然后单击左上角的 Done 按钮,如图。
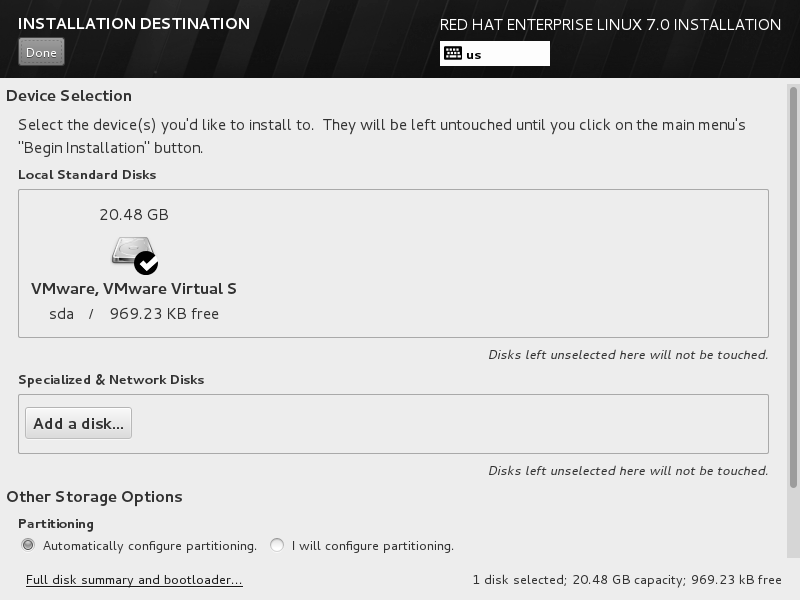
返回到安装主界面,单击 INSTALLATION DESTINATION 选项来选择安装媒介并设置分区。此时不需要进行任何修改,单击左上角的 Done 按钮即可,如图。
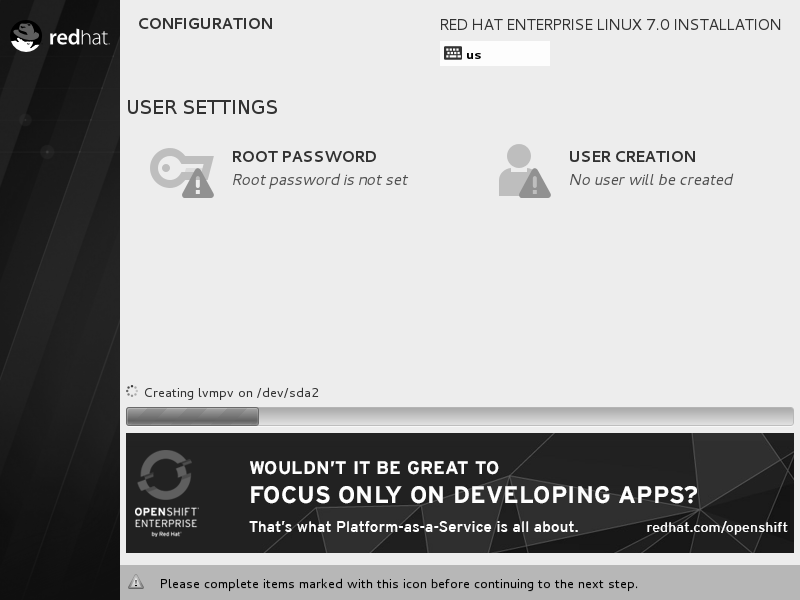
返回到安装主界面,单击 Begin Installation 按钮后即可看到安装进度,在此处选择 ROOTPASSWORD,如图。
然后设置 root 管理员的密码。若坚持用弱口令的密码则需要单击 2 次左上角的 Done 按钮才可以确认,如图。这里需要多说一句,当您在虚拟机中做实验的时候,密码无所谓强弱,但在生产环境中一定要让 root 管理员的密码足够复杂,否则系统将面临严重的安全问题。
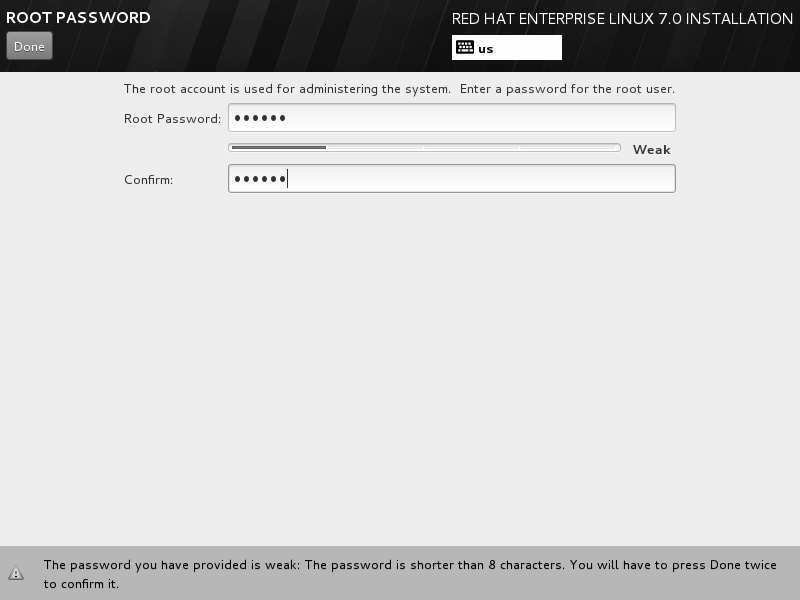
Linux 系统安装过程一般在 30~60 分钟,在安装过程期间耐心等待即可。安装完成后单击 Reboot 按钮,如图。
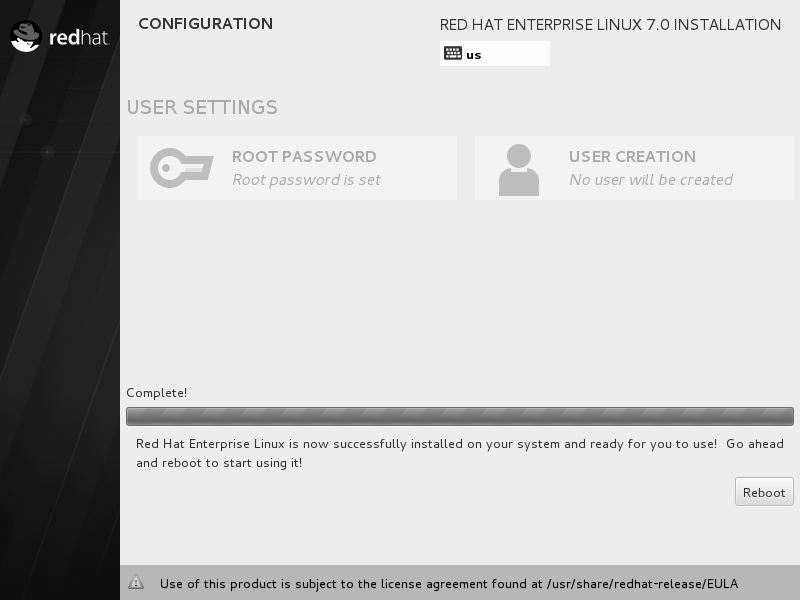
重启系统后将看到系统的初始化界面,单击 LICENSE INFORMATION 选项,如图。
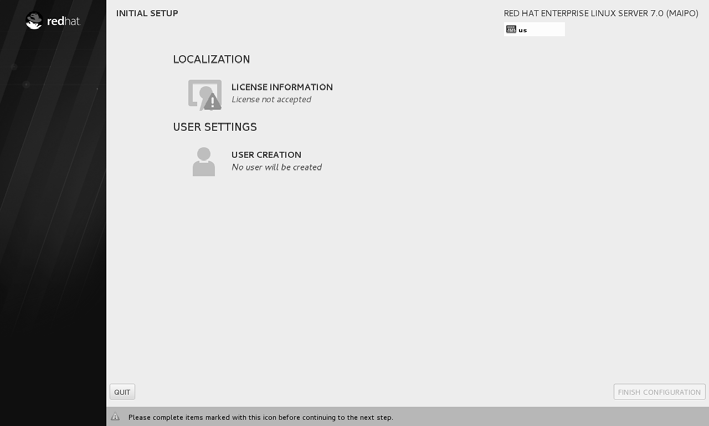
选中 I accept the license agreement 复选框,然后单击左上角的 Done 按钮,如图。
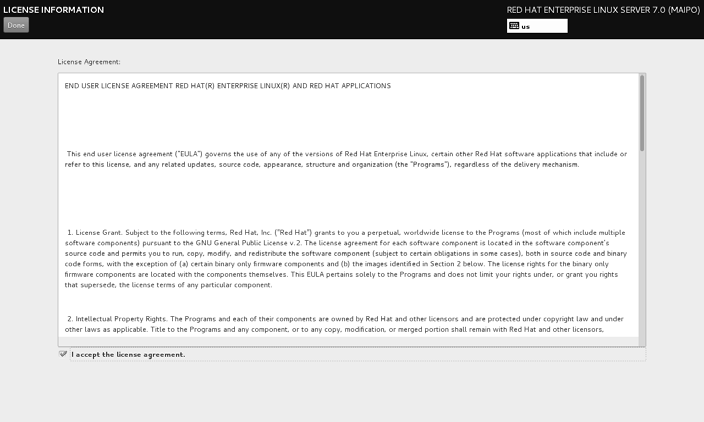
返回到初始化界面后单击 FINISH CONFIGURATION 选项,即可看到 Kdump 服务的设置界面。如果暂时不打算调试系统内核,也可以取消选中 Enable kdump 复选框,然后单击 Forward 按钮,如图。
在如下图所示的系统订阅界面中,选中 No, I prefer to register at a later time 单选按钮,然后单击 Finish 按钮。此处设置为不注册系统对后续的实验操作和生产工作均无影响。
虚拟机软件中的 RHEL 7 系统经过又一次的重启后,我们终于可以看到系统的欢迎界面,如下图所示。在界面中选择默认的语言 English (United States),然后单击 Next按钮。
将系统的输入来源类型选择为 English (US),然后单击 Next 按钮,如图。
为 RHEL 7 系统创建一个本地的普通用户,该账户的用户名为 linuxprobe,密码为 redhat,然后单击 Next 按钮,如图。
按照下图所示的设置来设置系统的时区,然后单击 Next 按钮。
在下图所示的界面中单击 Start using Red Hat Enterprise Linux Server 按钮,
出现如下图所示的界面。至此,RHEL 7 系统完成了全部的安装和部署工作。准备开始学习Linux 系统吧。
1.4 重置root 管理员密码
平日里让运维人员头疼的事情已经很多了,因此偶尔把 Linux 系统的密码忘记了并不用慌,只需简单几步就可以完成密码的重置工作。但是,如果您是第一次阅读本书,或者之前没有 Linux 系统的使用经验,请一定先跳过本节,等学习完 Linux 系统的命令后再来学习本节内容。如果您刚刚接手了一台 Linux 系统,要先确定是否为 RHEL 7 系统。如果是,然后再进行下面的操作。
[root@linuxprobe ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.0 (Maipo)
重启 Linux 系统主机并出现引导界面时,按下键盘上的 e 键进入内核编辑界面,如图所示。
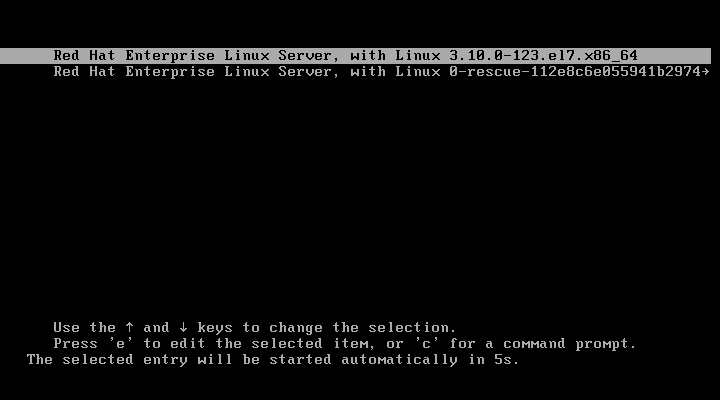
在 linux16 参数这行的最后面追加“rd.break”参数,然后按下 Ctrl + X 组合键来运行修改过的内核程序,如图所示。
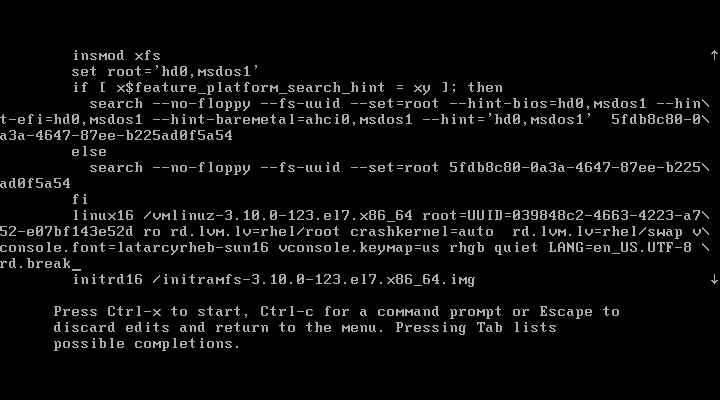
大约 30 秒过后,进入到系统的紧急求援模式,如图所示。
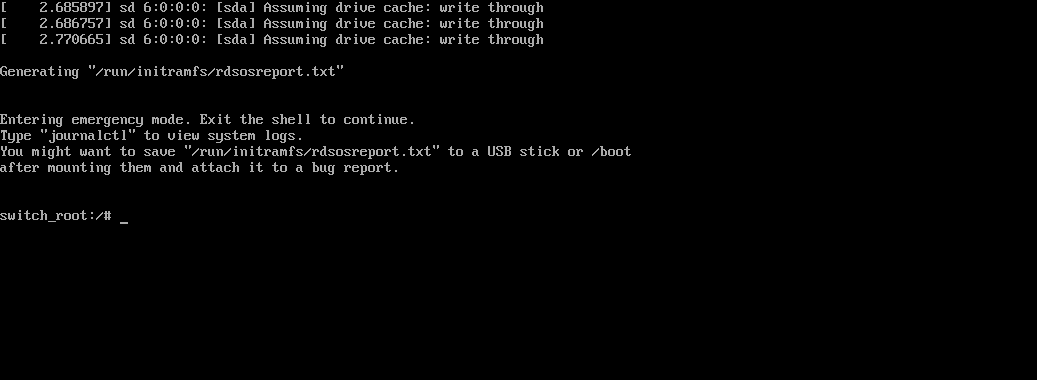
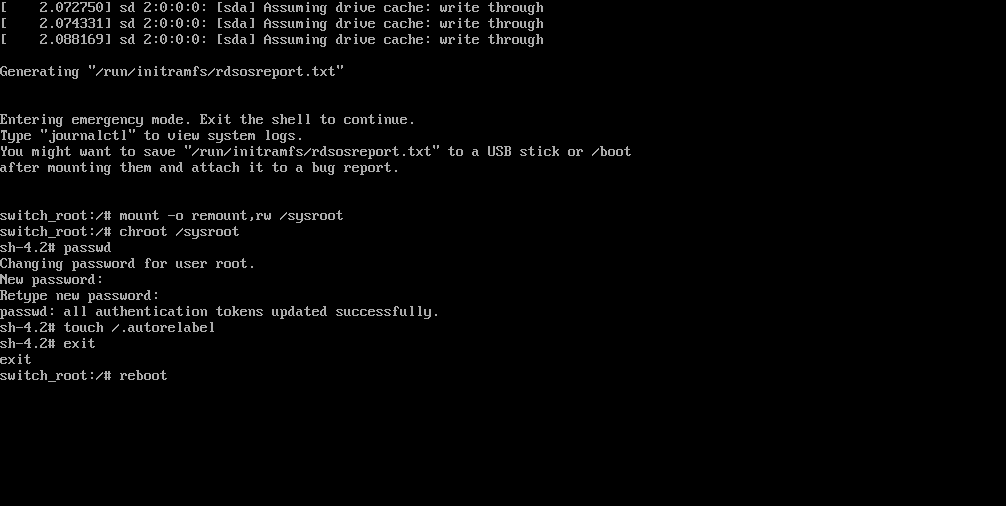
依次输入以下命令,(在执行passwd后会提示输入密码以及确认输入的密码,此处输入的密码就是重置之后的新密码)
mount -o remount,rw /sysroot
chroot /sysroot
passwd
touch /.autorelabel
exit
reboot
等待系统重启操作完毕,然后就可以使用新密码 linuxprobe 来登录Linux 系统了。命令行执行效果如图所示。
1.5 RPM(RedHat Packages Manager红帽软件包管理器)
在 RPM(红帽软件包管理器)公布之前,要想在 Linux 系统中安装软件只能采取源码包的方式安装。早期在 Linux 系统中安装程序是一件非常困难、耗费耐心的事情,而且大多数的服务程序仅仅提供源代码,需要运维人员自行编译代码并解决许多的软件依赖关系,因此要安装好一个服务程序,运维人员需要具备丰富知识、高超的技能,甚至良好的耐心。而且在安装、升级、卸载服务程序时还要考虑到其他程序、库的依赖关系,所以在进行校验、安装、卸载、查询、升级等管理软件操作时难度都非常大。(在我不懂的年纪,看着一堆软件开着源,源码包能下载,但不知道怎么用,怎么编译出来,真的很难受😫)
RPM 机制则为解决这些问题而设计的。RPM 有点像 Windows 系统中的控制面板,会建立统一的数据库文件,详细记录软件信息并能够自动分析依赖关系。目前 RPM 的优势已经被公众所认可,使用范围也已不局限在红帽系统中了。表 1-1 是一些常用的 RPM 软件包命令,当前不需要记住它们,大致混个“脸熟”就足够了。
| 表1-1 | 常用的RPM软件包命令 |
|---|---|
| 安装软件的命令格式 | rpm -ivh filename.rpm |
| 升级软件的命令格式 | rpm -Uvh filename.rpm |
| 卸载软件的命令格式 | rpm -e filename.rpm |
| 查询软件描述信息的命令格式 | rpm -qpi filename.rpm |
| 列出软件文件信息的命令格式 | rpm -qpl filename.rpm |
| 查询文件属于哪个RPM的命令格式 | rpm -qf filename |
1.6 Yum 软件仓库
尽管 RPM 能够帮助用户查询软件相关的依赖关系,但问题还是要运维人员自己来解决,而有些大型软件可能与数十个程序都有依赖关系,在这种情况下安装软件会是非常痛苦的。Yum 软件仓库便是为了进一步降低软件安装难度和复杂度而设计的技术。Yum 软件仓库可以根据用户的要求分析出所需软件包及其相关的依赖关系,然后自动从服务器下载软件包并安装到系统。Yum 软件仓库的技术拓扑如图所示。
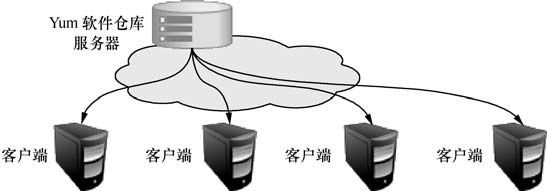
Yum 软件仓库中的 RPM 软件包可以是由红帽官方发布的,也可以是第三方发布的,当然也可以是自己编写的。《Linux 就该这么学》随书提供的镜像光盘内已经包含了大量可用的RPM 红帽软件包,后文中详细讲解这些软件包。表 1-2 所示为一些常见的 Yum 命令,当前只需对它们有一个简单印象即可。
| 表1-2 | 常见的Yum命令 |
|---|---|
| 命令 | 作用 |
| yum repolist all | 列出所有仓库 |
| yum list all | 列出仓库中所有软件包 |
| yum info 软件包名称 | 查看软件包信息 |
| yum install 软件包名称 | 安装软件包 |
| yum reinstall 软件包名称 | 重新安装软件包 |
| yum update 软件包名称 | 升级软件包 |
| yum remove 软件包 | 移除软件包 |
| yum clean all | 清除所有仓库缓存 |
| yum check-update | 检查可更新的软件包 |
| yum grouplist | 查看系统中已经安装的软件包组 |
| yum groupinstall 软件包组 | 安装指定的软件包组 |
| yum groupremove 软件包组 | 移除指定的软件包组 |
| yum groupinfo 软件包组 | 查询指定的软件包组信息 |
1.7 systemd 初始化进程
Linux 操作系统的开机过程是这样的,即从 BIOS 开始,然后进入 Boot Loader,再加载系统内核,然后内核进行初始化,最后启动初始化进程。初始化进程作为 Linux 系统的第一个进程,它需要完成 Linux 系统中相关的初始化工作,为用户提供合适的工作环境。红帽 RHEL 7 系统已经替换掉了熟悉的初始化进程服务 System V init,正式采用全新的systemd 初始化进程服务。如果您之前学习的是RHEL 5或RHEL 6系统,可能会不习惯。systemd 初始化进程服务采用了并发启动机制,开机速度得到了不小的提升。虽然 systemd初始化进程服务具有很多新特性和优势,但目前还是下面 4 个槽点。
- 槽点 1:systemd 初始化进程服务的开发人员 Lennart Poettering 就职于红帽公司,这让其他系统的粉丝很不爽。
- 槽点 2:systemd 初始化进程服务仅仅可在 Linux 系统下运行,“抛弃”了 UNIX 系统用户。
- 槽点 3:systemd 接管了诸如 syslogd、udev、cgroup 等服务的工作,不再甘心只做初始化进程服务。
- 槽点 4:使用 systemd 初始化进程服务后,RHEL 7 系统变化太大,而相关的参考文档不多,令用户着实为难。
无论怎样,RHEL 7 系统选择 systemd 初始化进程服务已经是一个既定事实,因此也没有了“运行级别”这个概念,Linux 系统在启动时要进行大量的初始化工作,比如挂载文件系统和交换分区、启动各类进程服务等,这些都可以看作是一个一个的单元(Unit),systemd 用目标(target)代替了 System V init 中运行级别的概念,这两者的区别如表 1-3 所示。(心酸,明明我md语法没问题为什么表格没生效,最后我在表格之前加了一行空行生效了,没错,就下面这个表格,明明之前的表格不需要加空行,如表1-1和表1-2,土拨鼠尖叫.gif)
| 表 | 1-3 | systemd与System V init的区别以及作用 |
|---|---|---|
| System V init运行级别 | systemd目标名称 | 作用 |
| 0 | runlevel0.target, poweroff.target | 关机 |
| 1 | runlevel1.target, rescue.target | 单用户模式 |
| 2 | runlevel2.target, multi-user.target | 等同于级别 3 |
| 3 | runlevel3.target, multi-user.target | 多用户的文本界面 |
| 4 | runlevel4.target, multi-user.target | 等同于级别 3 |
| 5 | runlevel5.target, graphical.target | 多用户的图形界面 |
| 6 | runlevel6.target, reboot.target | 重启 |
| emergency | emergency.target | 紧急 Shell |
如果想要将系统默认的运行目标修改为“多用户,无图形”模式,可直接用 ln 命令把多用户模式目标文件连接到/etc/systemd/system/目录:
[root@linuxprobe ~]# ln -sf /lib/systemd/system/multi-user.target /etc/systemd/system/default.target
如果有读者之前学习过 RHEL 6 系统,或者已经习惯使用 service、chkconfig 等命令来管理系统服务,那么现在就比较郁闷了,因为在 RHEL 7 系统中是使用 systemctl 命令来管理服务的。表 1-4 和表 1-5 所示 RHEL 6 系统中 System V init 命令与 RHEL 7 系统中 systemctl 命令的对比,您可以先大致了解一下,后续章节中会经常用到它们。
| 表 | 1-4 | systemctl 管理服务的启动、重启、停止、重载、查看状态等常用命令 |
|---|---|---|
| System V init命令(RHEL 6 系统) | systemctl命令(RHEL 7 系统) | 作用 |
| service foo start | systemctl start foo.service | 启动服务 |
| service foo restart | systemctl restart foo.service | 重启服务 |
| service foo stop | systemctl stop foo.service | 停止服务 |
| service foo reload | systemctl reload foo.service | 重新加载配置文件(不终止服务) |
| service foo status | systemctl status foo.service | 查看服务状态 |
| 表 | 1-5 | systemctl 设置服务开机启动、不启动、查看各级别下服务启动状态等常用命令 |
|---|---|---|
| System V init命令(RHEL 6 系统) | systemctl命令(RHEL 7 系统) | 作用 |
| chkconfig foo on | systemctl enable foo.service | 开机自动启动 |
| chkconfig foo off | systemctl disable foo.service | 开机不自动启动 |
| chkconfig foo | systemctl is-enabled foo.service | 查看特定服务是否为开机自动启动 |
| chkconfig --list | systemctl list-unit-files --type=service | 查看各个级别下服务的启动与禁用情况 |
1.8 复习题
1. 为什么建议读者校验下载的系统镜像或工具?
答:为了保证软件包的安全与完整性。
2. 使用虚拟机安装 Linux 系统时,为什么要先选择稍后安装操作系统,而不是去选择 RHEL 7系统镜像光盘?
答:在配置界面中若直接选择了 RHEL 7 系统镜像,则 VMware Workstation 虚拟机会使用内置的安装向导自动进行安装,最终安装出来的系统跟我们后续进行实验所需的系统环境会不一样。
3. RPM(红帽软件包管理器)只有红帽企业系统在使用,对吗?
答:RPM 已经被 CentOS、Fedora、openSUSE 等众多 Linux 系统采用,它真的很好用!
4. 简述 RPM 与 Yum 软件仓库的作用。
答:RPM 是为了简化安装的复杂度,而 Yum 软件仓库是为了解决软件包之间的依赖关系。
5. RHEL 7 系统采用了 systemd 作为初始化进程,那么如何查看某个服务的运行状态?
答:执行命令“systemctl status 服务名.service”可查看服务的运行状态,其中服务名后的.service 可以省略。(如systemctl status mysql,把systemctl看成system control的缩写比较好记,虽然我不确定ctl是不是control的缩写)
第二章 新手必须掌握的Linux 命令
2.1 强大好用的Shell
通常来讲,计算机硬件是由运算器、控制器、存储器、输入/输出设备等共同组成的,而让各种硬件设备各司其职且又能协同运行的东西就是系统内核。Linux 系统的内核负责完成对硬件资源的分配、调度等管理任务。由此可见,系统内核对计算机的正常运行来讲是太重要了,因此一般不建议直接去编辑内核中的参数,而是让用户通过基于系统调用接口开发出的程序或服务来管理计算机,以满足日常工作的需要,如图所示。
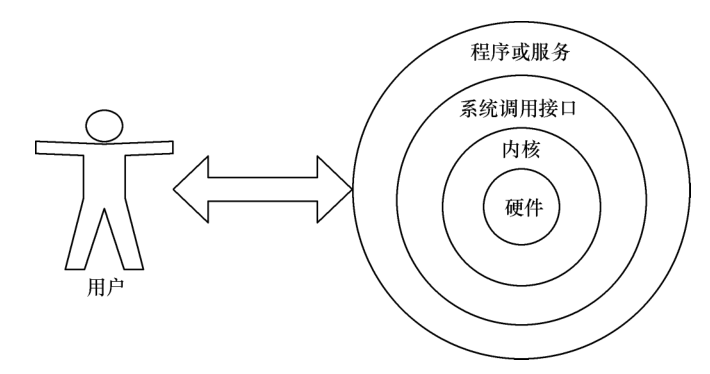
Shell 就是这样的一个命令行工具。Shell(也称为终端或壳)充当的是人与内核(硬件)之间的翻译官,用户把一些命令“告诉”终端,它就会调用相应的程序服务去完成某些工作。现在包括红帽系统在内的许多主流 Linux 系统默认使用的终端是 Bash(Bourne-Again SHell)解释器。主流 Linux 系统选择 Bash 解释器作为命令行终端主要有以下 4 项优势,读者可以在今后的学习和生产工作中细细体会 Linux 系统命令行的美妙之处,真正从心里爱上它们。
- 通过上下方向键来调取过往执行过的 Linux 命令;
- 命令或参数仅需输入前几位就可以用 Tab 键补全;
- 具有强大的批处理脚本;
- 具有实用的环境变量功能。
2.2 执行查看帮助命令
常见执行Linux命令的格式是这样的:
命令名称 [命令参数] [命令对象]
注意,命令名称、命令参数、命令对象之间请用空格键分隔。
命令对象一般是指要处理的文件、目录、用户等资源,而命令参数可以用长格式(完整的选项名称),也可以用短格式(单个字母的缩写),两者分别用--与-作为前缀(示例请见表 2-1)。Linux新手不会执行命令大多是因为参数比较复杂,参数值需要随不同的命令和需求情况而发生改变。因此,要想灵活搭配各种参数,执行自己想要的功能,则需要长时间的经验积累了。
| 表2-1 | 命令参数的长格式与短格式示例 |
|---|---|
| 长格式 | man --help |
| 短格式 | man -h |
有读者现在可能会想:“Linux 系统中有那么多命令,我怎么知道某个命令是干嘛用的?在日常工作中遇到了一个不熟悉的 Linux 命令,我又怎样才能知道它有哪些可用参数呢?”接下来,我们就拿 man 这个命令作为本书中第一个教给读者去学习的 Linux 命令了。
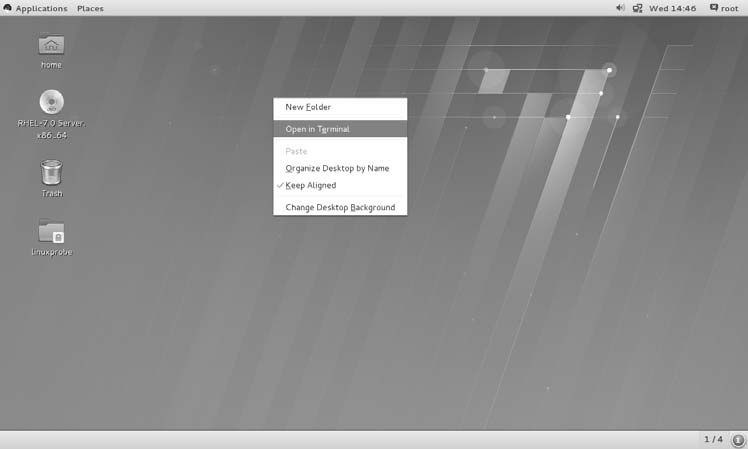
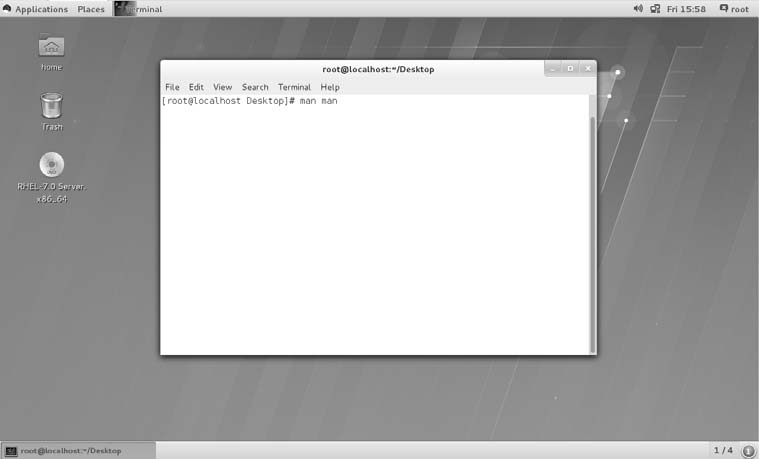
对于真正的零基础读者,您可以通过以下三张图来学习如何在 RHEL 7 系统中执行 Linux命令。
在 RHEL 7 系统的桌面上单击鼠标右键,在弹出的菜单中选择 Open in Terminal 命令,这将打开一个 Linux 系统命令行终端
在命令行终端中输入 man man 命令来查看 man 命令自身的帮助信息
敲击回车键后即可看到帮助信息
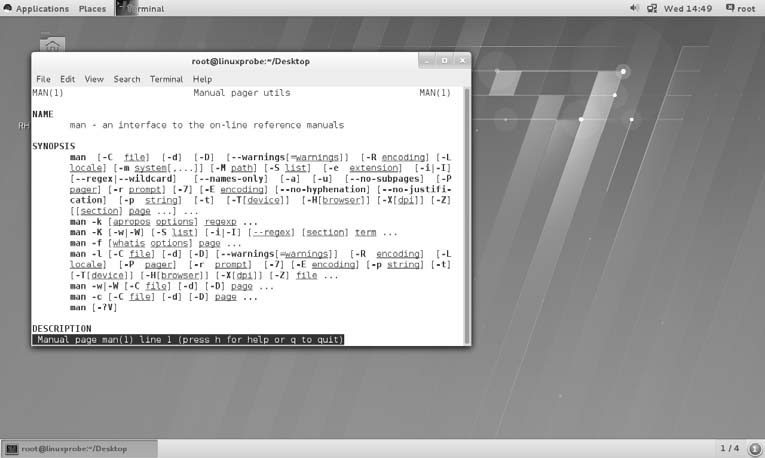
在 man 命令帮助信息的界面中,所包含的常用操作按键及其用途如表 2-2 所示。
| 表2-2 | man 命令中常用按键以及用途 |
|---|---|
| 按键 | 用途 |
| 空格键 | 向下翻一页 |
| Page Down | 向下翻一页 |
| Page Up | 向上翻一页 |
| home | 直接前往首页 |
| end | 直接前往尾页 |
| / | 从上至下搜索某个关键词,如“/linux” |
| ? | 从下至上搜索某个关键词,如“?linux” |
| n | 定位到下一个搜索到的关键词 |
| N | 定位到上一个搜索到的关键词 |
| q | 退出帮助文档 |
一般来讲,使用 man 命令查看到的帮助内容信息都会很长很多,如果读者不了解帮助文档信息的目录结构和操作方法,乍一看到这么多信息可能会感到相当困惑。man 命令的帮助信息的结构如表 2-3 所示。
| 表2-3 | man 命令帮助信息的结构以及意义 |
|---|---|
| 结构名称 | 代表意义 |
| NAME | 命令的名称 |
| SYNOPSIS | 参数的大致使用方法 |
| DESCRIPTION | 介绍说明 |
| EXAMPLES | 演示(附带简单说明) |
| OVERVIEW | 概述 |
| DEFAULTS | 默认的功能 |
| OPTIONS | 具体的可用选项(带介绍) |
| ENVIRONMNET | 环境变量 |
| FILES | 用到的文件 |
| SEE ALSO | 相关的资料 |
| HISTORY | 维护历史与联系方式 |
2.3 常用系统工作命令(从这里开始相对重要)
说实话我个人不太习惯把命令后的参数用[]括起来的参考格式,因为常常以为这个[]也要输入(TxT),所以之后的内容我就按个人习惯来了。
1. echo命令
echo 命令用于在终端输出字符串或变量提取后的值,格式为echo [字符串 | $变量]。(echo 字符串或echo $变量名,如环境变量是PATH,可以echo $PATH在终端打印环境变量值试试)。
比如我们使用$变量的方式提取变量 SHELL 的值,并将其输出到屏幕上:
[root@linuxprobe ~]# echo $SHELL
/bin/bash
2. date命令
date 命令用于显示及设置系统的时间或日期,格式为date 选项 +指定的格式。
只需在强大的 date 命令中输入以“+”号开头的参数,即可按照指定格式来输出系统的时间或日期。把打包后的文件自动按照“年-月-日”的格式打包成“backup-2017-9-1.tar.gz”,用户只需要看一眼文件名称就能大概了解到每个文件的备份时间,很直观。date 命令中常见的参数格式及作用如表 2-4 所示。
| 表2-4 | date命令中的参数及作用 |
|---|---|
| 参数 | 作用 |
| %t | 跳格(Tab 键) |
| %H | 小时(00~23) |
| %I | 小时(00~12) |
| %M | 分钟(00~59) |
| %S | 秒(00~59) |
| %j | 今年中的第几天 |
按照默认格式查看当前系统时间的 date 命令如下所示:
[root@linuxprobe ~]# date
Mon Aug 24 16:11:23 CST 2017
按照“年-月-日 小时:分钟:秒”的格式查看当前系统时间的 date 命令如下所示:
[root@linuxprobe ~]# date "+%Y-%m-%d %H:%M:%S"
2017-08-24 16:29:12
将系统的当前时间设置为 2017 年 9 月 1 日 8 点 30 分的 date 命令如下所示:
[root@linuxprobe ~]# date -s "20170901 8:30:00"
Fri Sep 1 08:30:00 CST 2017
再次使用 date 命令并按照默认的格式查看当前的系统时间,如下所示:
[root@linuxprobe ~]# date
Fri Sep 1 08:30:01 CST 2017
date 命令中的参数%j 可用来查看今天是当年中的第几天。这个参数能够很好地区分备份时间的新旧,即数字越大,越靠近当前时间。该参数的使用方式以及显示结果如下所示。
[root@linuxprobe ~]# date "+%j"
244
3. reboot命令
reboot 命令用于重启系统,其格式为 reboot。
由于重启计算机这种操作会涉及硬件资源的管理权限,因此默认只能使用 root 管理员来执行,其命令如下:
[root@linuxprobe ~]# reboot
4. poweroff命令
poweroff 命令用于关闭系统,其格式为 poweroff。
该命令与 reboot 命令相同,都会涉及硬件资源的管理权限,因此默认只有 root 管理员才可以关闭电脑,其命令如下:
[root@linuxprobe ~]# poweroff
5. wget命令
wget 命令用于在终端中下载网络文件,格式为“wget -参数 下载地址”。
如果您没有 Linux 系统的管理经验,当前只需了解一下 wget 命令的参数以及作用,然后看一下下面的演示实验即可。表 2-5 所示为 wget 命令的参数以及参数的作用。
| 表2-5 | wget命令的参数及作用 |
|---|---|
| 参数 | 作用 |
| -b | 后台下载模式 |
| -P | 下载到指定目录 |
| -t | 最大尝试次数 |
| -c | 断点续传 |
| -p | 下载页面内所有资源,包括图片、视频等 |
| -r | 递归下载 |
演示:使用wget下载《Linux就该这么学》,文件的完整路径为http://www.linuxprobe.com/docs/LinuxProbe.pdf,执行命令如下:
wget http://www.linuxprobe.com/docs/LinuxProbe.pdf
wget -b http://www.linuxprobe.com/docs/LinuxProbe.pdf
wget -P /root http://www.linuxprobe.com/docs/LinuxProbe.pdf
echo '如果途中网络中断可以断点续传'
wget -c http://www.linuxprobe.com/docs/LinuxProbe.pdf
echo '组合一下'
wget -b -P /root -t 5 -c http://www.linuxprobe.com/docs/LinuxProbe.pdf
接下来可以尝试使用-r递归下载参数来下载www.linuxprobe.com网站内所有页面数据及文件,下载完后会自动保存到当前路径之下名为www.linuxprobe.com的文件夹(目录)中,执行命令如下:
wget -r -p http://www.linuxprobe.com
echo '用-b后台下载可以方便干其他事,不用-b后台下载则方便监督下载是否完成'
6. ps 命令
ps 命令用于查看系统中的进程状态,格式为ps 参数。(我好像明白作者在参数周围加[]的原因了,[参数]表示参数可选可不输,但是我还是不想加...)
估计读者在第一次执行这个命令时都要惊呆一下—怎么会有这么多输出值,这可怎么看得过来?其实,刘遄老师通常会将 ps 命令与第 3 章的管道符技术搭配使用,用来抓取与某个指定服务进程相对应的 PID 号码。ps 命令的常见参数以及作用如表 2-6 所示。
| 表2-6 | ps命令的参数及作用 |
|---|---|
| 参数 | 作用 |
| -a | 显示所有进程(包括其他用户的进程) |
| -u | 用户及其他详细信息 |
| -x | 显示没有控制终端的进程 |
Linux 系统中时刻运行着许多进程,如果能够合理地管理它们,则可以优化系统的性能。在Linux 系统中,有 5 种常见的进程状态,分别为运行、中断、不可中断、僵死与停止,其各自含义如下所示:
- R(运行):进程正在运行或在运行队列中等待。running
- S(中断):进程处于休眠中,当某个条件形成后或者接收到信号时,则脱离该状态。sleepping
- D(不可中断):进程不响应系统异步信号,即便用 kill 命令也不能将其中断。disabled?
- Z(僵死):进程已经终止,但进程描述符依然存在, 直到父进程调用 wait4()系统函数后将进程释放。zombie
- T(停止):进程收到停止信号后停止运行。stopped
当执行ps aux命令后通常会看到如表 2-7 所示的进程状态,表 2-7 中只是列举了部分输出值,而且正常的输出值中不包括中文注释。(以后表的前表后我都加一行空行算了,出问题的原因摸不清)
表2-7
| USER | PID | %CPU | %MEM | VSZ | RSS | TTY | STAT | START | TIME | COMMAND |
|---|---|---|---|---|---|---|---|---|---|---|
| 进程的所有者 | 进程ID号 | 运算器占用率 | 内存占用率 | 虚拟内存使用量(单位KB) | 占用的固定内存量(单位KB) | 所在终端 | 进程状态 | 被启动的时间 | 实际使用CPU的时间 | 命令名称与参数 |
| root | 1 | 0.0 | 0.4 | 53684 | 7628 | ? | Ss | 07:22 | 0:02 | /usr/lib/systemd/systemd |
| root | 2 | 0.0 | 0.0 | 0 | 0 | ? | S | 07:22 | 0:00 | [kthreadd] |
| root | 3 | 0.0 | 0.0 | 0 | 0 | ? | S | 07:22 | 0:00 | [ksoftirqd/0] |
| root | 5 | 0.0 | 0.0 | 0 | 0 | ? | S< | 07:22 | 0:00 | [kworker/0:0H] |
| root | 7 | 0.0 | 0.0 | 0 | 0 | ? | S | 07:22 | 0:00 | [migration/0] |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
注:
如前面所提到的,在 Linux 系统中的命令参数有长短格式之分,长格式和长格式之间不能合并,长格式和短格式之间也不能合并,但短格式和短格式之间是可以合并的,合并后仅保留一个-(减号)即可。另外ps命令可允许参数不加减号(-),因此可直接写成ps aux的样子。
7. top命令
top 命令用于动态地监视进程活动与系统负载等信息,其格式为 top。
top 命令相当强大,能够动态地查看系统运维状态,完全将它看作 Linux 中的“强化版的Windows 任务管理器”。top 命令的运行界面如图所示。
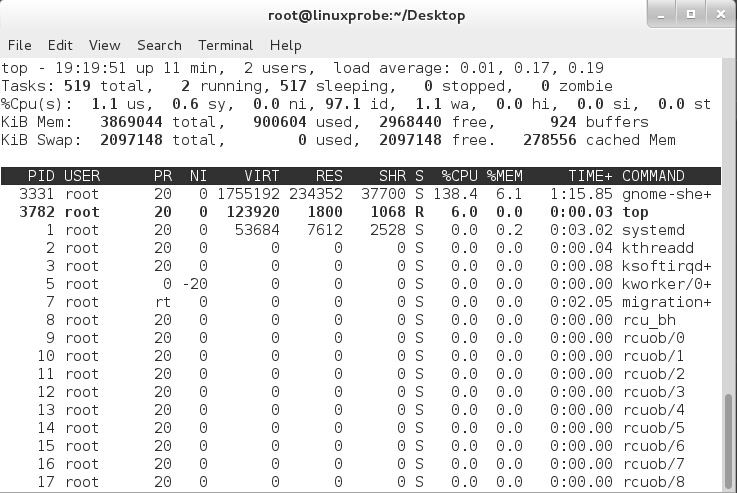
在图中,top 命令执行结果的前 5 行为系统整体的统计信息,其所代表的含义如下。
- 第 1 行:系统时间、运行时间、登录终端数、系统负载(三个数值分别为 1 分钟、5分钟、15 分钟内的平均值,数值越小意味着负载越低)。
- 第 2 行:进程总数、运行中的进程数、睡眠中的进程数、停止的进程数、僵死的进程数。
- 第 3 行:用户占用资源百分比、系统内核占用资源百分比、改变过优先级的进程资源百分比、空闲的资源百分比等。
注:
第 3 行中的数据均为 CPU 数据并以百分比格式显示,例如“97.1 id”意味着有 97.1%的 CPU 处理器资源处于空闲。
- 第 4 行:物理内存总量、内存使用量、内存空闲量、作为内核缓存的内存量。
- 第 5 行:虚拟内存总量、虚拟内存使用量、虚拟内存空闲量、已被提前加载的内存量。
8. pidof命令
pidof 命令用于查询某个指定服务进程的 PID 值,格式为“pidof 参数 服务名称”。(早知道,我当初就能直接自动化,起码大部分工作都能自动化)
每个进程的进程号码值(PID)是唯一的,因此可以通过 PID 来区分不同的进程。例如,可以使用如下命令来查询本机上 sshd 服务程序的 PID:
[root@linuxprobe ~]# pidof sshd
2156
9. kill命令
kill 命令用于终止某个指定 PID 的服务进程,格式为“kill 参数 进程的PID”。
接下来,我们使用 kill 命令把上面用 pidof 命令查询到的 PID 所代表的进程终止掉,其命令如下所示。这种操作的效果等同于强制停止 sshd 服务。
[root@linuxprobe ~]# kill 2156
此处占个位置,用于放展示kill的参数的表格,因为书中这里没写
10. killall命令
killall 命令用于终止某个指定名称的服务所对应的全部进程(即杀掉服务名中包含指定字符串的所有进程),格式为:“killall 参数 进程名称”。
通常来讲,复杂软件的服务程序会有多个进程协同为用户提供服务,如果逐个去结束这些进程会比较麻烦,此时可以使用 killall 命令来批量结束某个服务程序带有的全部进程。下面以 httpd 服务程序为例,来结束其全部进程。由于 RHEL7 系统默认没有安装 httpd 服务程序,因此大家此时只需看操作过程和输出结果即可,等学习了相关内容之后再来实践。
[root@linuxprobe ~]# pidof httpd
13581 13580 13579 13578 13577 13576
[root@linuxprobe ~]# killall httpd
[root@linuxprobe ~]# pidof httpd
[root@linuxprobe ~]#
注:
如果我们在系统终端中执行一个命令后想立即停止它,可以同时按下 Ctrl + C 组合键(生产环境中比较常用的一个快捷键),这样将立即终止该命令的进程。或者,如果有些命令在执行时不断地在屏幕上输出信息,影响到后续命令的输入,则可以在执行命令时在末尾添加上一个&符号,这样命令将进入系统后台来执行。
2.4 系统状态检测命令
作为一名合格的运维人员,想要更快、更好地了解 Linux 服务器,必须具备快速查看 Linux系统运行状态的能力,因此接下来会逐个讲解与网卡网络、系统内核、系统负载、内存使用情况、当前启用终端数量、历史登录记录、命令执行记录以及救援诊断等相关命令的使用方法。这些命令都超级实用,还请读者用心学习,加以掌握。
1. ifconfig命令
ifconfig 命令用于获取网卡配置与网络状态等信息,格式为“ifconfig 网络设备 参数”。
使用 ifconfig 命令来查看本机当前的网卡配置与网络状态等信息时,其实主要查看的就是网卡名称、inet 参数后面的 IP 地址、ether 参数后面的网卡物理地址(又称为 MAC 地址),以及 RX、TX 的接收数据包与发送数据包的个数及累计流量(即下面加粗的信息内容)(由于我不知道怎么在md中的代码块里进行加粗操作,故没有加粗):
[root@linuxprobe ~]# ifconfig
eno16777728: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.10 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::20c:29ff:fec4:a409 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:c4:a4:09 txqueuelen 1000 (Ethernet)
RX packets 36 bytes 3176 (3.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 38 bytes 4757 (4.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 0 (Local Loopback)
RX packets 386 bytes 32780 (32.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 386 bytes 32780 (32.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
2. uname命令
uname 命令用于查看系统内核与系统版本等信息,格式为“uname [-a]”。([-a]表示该参数可输可不输)
在使用 uname 命令时,一般会固定搭配上-a 参数来完整地查看当前系统的内核名称、主机名、内核发行版本、节点名、系统时间、硬件名称、硬件平台、处理器类型以及操作系统名称等信息。
[root@linuxprobe ~]# uname -a
Linux linuxprobe.com 3.10.0-123.el7.x86_64 #1 SMP Mon May 5 11:16:57 EDT 2017
x86_64 x86_64 x86_64 GNU/Linux
顺带一提,如果要查看当前系统版本的详细信息,则需要查看 redhat-release 文件,其命令以及相应的结果如下:
[root@linuxprobe ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.0 (Maipo)
3. uptime命令
uptime 用于查看系统的负载信息,格式为 uptime。
uptime 命令真的很棒,它可以显示当前系统时间、系统已运行时间、启用终端数量以及平均负载值等信息。平均负载值指的是系统在最近 1 分钟、5 分钟、15 分钟内的压力情况(下面加粗的信息部分);负载值越低越好,尽量不要长期超过 1,在生产环境中不要超过 5。(我输了一下,看到了17,18,18😨)
[root@vm-xxxxxxx ~]# uptime
17:13:01 up 38 days, 6 min, 7 users, load average: 17.87, 18.61, 18.82
4. free命令
free 用于显示当前系统中内存的使用量信息,格式为“free [-h]”。
为了保证 Linux 系统不会因资源耗尽而突然宕机,运维人员需要时刻关注内存的使用量。在使用 free 命令时,可以结合使用-h 参数以更人性化的方式输出当前内存的实时使用量信息。表 2-8 所示为在刘遄老师的电脑上执行 free -h 命令之后的输出信息。需要注意的是,输出信息中的中文注释是作者自行添加的内容,实际输出时没有相应的参数解释。
(以下为可能没有校验下载的系统镜像的md5值,安装内容可能不完整,然后执行free命令报找不到系统文件的示例)
[root@vm-xxxxxx ~]# free -h
free: error while loading shared libraries: libprocps.so.4: cannot open shared object file: No such file or directory
表2-8 执行free -h命令后的输出信息
| 内存用量 | 已用量 | 可用量 | 进程共享的内存量 | 磁盘缓存的内存量 | 缓存的内存量 | |
|---|---|---|---|---|---|---|
| total | used | free | shared | buffers | cached | |
| Mem | 1.8GB | 1.3GB | 542MB | 9.8MB | 1.6MB | 413MB |
| -/+ buffers/cache | 869MB | 957MB | ||||
| Swap | 2.0GB | 0 | 2.0GB |
5. who命令
who 用于查看当前登入主机的用户终端信息,格式为“who [参数]”。
这三个简单的字母可以快速显示出所有正在登录本机的用户的名称以及他们正在开启的终端信息。表 2-9 所示为执行 who 命令后的结果。
[root@linuxprobe ~]# who
表2-9 执行who命令的结果
| 登录的用户名 | 终端设备 | 登录到系统的时间 |
|---|---|---|
| root | :0 | 2017-08-24 17:52 (:0) |
| root | pts/0 | 2017-08-24 17:52 (:0) |
6. last命令
last 命令用于查看所有系统的登录记录,格式为“last [参数]”。
使用 last 命令可以查看本机的登录记录。但是,由于这些信息都是以日志文件的形式保存在系统中,因此黑客可以很容易地对内容进行篡改。千万不要单纯以该命令的输出信息而判断系统有无被恶意入侵!(那要怎么查看入侵者信息呢T_T)
7. history命令
history 命令用于显示历史执行过的命令,格式为“history [-c]”。
history 命令应该是作者最喜欢的命令。执行 history 命令能显示出当前用户在本地计算机中执行过的最近 1000 条命令记录。如果觉得 1000 不够用,还可以自定义/etc/profile 文件中的HISTSIZE 变量值。在使用 history 命令时,如果使用-c 参数则会清空所有的命令历史记录。还可以使用“!编码数字(无空格)”的方式来重复执行某一次的命令。总之,history 命令有很多有趣的玩法等待您去开发。
历史命令会被保存到用户家目录中的.bash_history 文件中。Linux 系统中以点(.)开头的文件均代表隐藏文件,这些文件大多数为系统服务文件,可以用 cat 命令查看其文件内容。
[root@linuxprobe ~]# cat ~/.bash_history
要清空当前用户在本机上执行的 Linux 命令历史记录信息,可执行如下命令:
[root@linuxprobe ~]# history -c
8. sosreport命令
sosreport 命令用于收集系统配置及架构信息并输出诊断文档,命令格式为 sosreport。
当 Linux 系统出现故障需要联系技术支持人员时,大多数时候都要先使用这个命令来简单收集系统的运行状态和服务配置信息,以便让技术支持人员能够远程解决一些小问题,亦或让他们能提前了解某些复杂问题。在下面的输出信息中,加粗的部分是收集好的资料压缩文件以及校验码,将其发送给技术支持人员即可:
[root@linuxprobe ~]# sosreport
sosreport (version 3.0)
This command will collect diagnostic and configuration information from
this Red Hat Enterprise Linux system and installed applications.
An archive containing the collected information will be generated in
/var/tmp and may be provided to a Red Hat support representative.
Any information provided to Red Hat will be treated in accordance with
the published support policies at:
https://access.redhat.com/support/
The generated archive may contain data considered sensitive and its
content should be reviewed by the originating organization before being
passed to any third party.
No changes will be made to system configuration.
Press ENTER to continue, or CTRL-C to quit. 此处敲击回车来确认收集信息
Please enter your first initial and last name [linuxprobe.com]: 此处敲击回车来确认主机编号
Please enter the case number that you are generating this report for: 此 处 敲 击 回
车来确认主机编号
Running plugins. Please wait ...
Running 70/70: yum...
Creating compressed archive...
Your sosreport has been generated and saved in:
/var/tmp/sosreport-linuxprobe.com-20170905230631.tar.xz这行应该加粗
The checksum is: 79436cdf791327040efde48c452c6322这行应该加粗
Please send this file to your support representative.
2.5 工作目录切换命令
工作目录指的是用户当前在系统中所处的位置。由于工作目录会牵涉系统存储结构相关的知识,因此第 6 章将详细讲解这部分内容。读者只需简单了解一下这里的操作实验即可,如果不能完全掌握也没有关系,毕竟 Linux 系统的知识体系太过庞大,每一位初学人员都需要经历这么一段时期。
1. pwd命令
pwd 命令用于显示用户当前所处的工作目录,格式为“pwd [选项]”。
[root@linuxprobe etc]# pwd
/etc
此处占位,有机会补充选项表格
2. cd命令
cd 命令用于切换工作路径,格式为“cd [目录名称]”。
这里直接上一个表格
| 命令 | 作用 |
|---|---|
| cd /路径 | 切换到根目录中存在的路径中 |
| cd - | 返回上一级目录(跳转前的目录,不是当前目录的上一级) |
| cd ~ | 跳转到当前用户目录(一般是/root) |
| cd ./路径 | 切换到相对路径为本级的一个路径 |
| cd .. | 切换到相对路径为本级的上一级路径 |
| cd ../路径 | 切换到上一级路径下的某个路径 |
| cd ../../../ | 切换到上三级路径(每一级对应一次..) |
3. ls命令
ls 命令用于显示目录中的文件信息,格式为“ls [选项] [文件] ”。
所处的工作目录不同,当前工作目录下的文件肯定也不同。使用 ls 命令的“-a”参数看到全部文件(包括隐藏文件),使用“-l”参数可以查看文件的属性、大小等详细信息(Unix系统以外使用ll命令相当于ls -l)。
将这两个参数整合之后,再执行 ls 命令即可查看当前目录中的所有文件(包含隐藏文件)并输出这些文件的属性信息,在有些情况下比较实用:
[root@linuxprobe ~]# ls -al
[root]echo '此处使用了短命令合并的格式,即将-a -l合并为-al'
如果想要查看目录属性信息,则需要额外添加一个-d参数。例如,可使用如下命令查看/etc 目录的权限与属性信息(相当于加了-d参数后可以指定一个目录):
[root@linuxprobe ~]# ls -ld /etc
drwxr-xr-x. 132 root root 8192 Jul 10 10:48 /etc
此处占位,有可能后续补一个ls命令的参数表(临时记录一下,看文件夹大小用du -h)
2.6 文本文件编辑命令
本节将讲解几条用于查看文本文件内容的命令。至于编辑器使用起来比较复杂,因此将放到第 4 章与 Shell脚本内容一起讲解。
1. cat命令
cat 命令用于查看纯文本文件(内容较少的),格式为“cat [选项] [文件]”。
Linux 系统中有多个用于查看文本内容的命令,每个命令都有自己的特点,比如这个 cat命令就是用于查看内容较少的纯文本文件的。cat 这个命令也很好记,因为 cat 在英语中是“猫”的意思,小猫咪是不是给您一种娇小、可爱的感觉呢?(以上为作者观点,个人仅看做catch的缩写)
如果在查看文本内容时还想顺便显示行号的话,不妨在 cat 命令后面追加一个-n 参数:
[root@linuxprobe ~]# cat -n initial-setup-ks.cfg
1 #version=RHEL7
2 # X Window System configuration information
3 xconfig --startxonboot
4
5 # License agreement
6 eula --agreed
7 # System authorization information
8 auth --enableshadow --passalgo=sha512
9 # Use CDROM installation media
10 cdrom
11 # Run the Setup Agent on first boot
12 firstboot --enable
13 # Keyboard layouts
14 keyboard --vckeymap=us --xlayouts='us'
15 # System language
16 lang en_US.UTF-8
………………省略部分输出信息………………
2. more命令
more 命令用于查看纯文本文件(内容较多的),格式为“more [选项]文件”。(选项用中括号括起来了,是非必输项)
如果需要阅读长篇小说或者非常长的配置文件,那么“小猫咪”cat可就真的不适合了。因为一旦使用cat命令阅读长篇的文本内容,信息就会在屏幕上快速翻滚,导致自己还没有来得及看到,内容就已经翻篇了。因此对于长篇的文本内容,推荐使用 more 命令来查看。more命令会在最下面使用百分比的形式来提示您已经阅读了多少内容(相对于vi命令,如果只查看不编辑,这个百分比显示还是挺人性化的)。您还可以使用空格键或回车键向下翻页:
# 由于就是一个看内容的命令,示例略
more test.txt
3. head命令
head 命令用于查看纯文本文档的前 N 行,格式为“head [选项] [文件]”。(选项和文件都用中括号括起来了,也就是选项和文件都是非必输项?)
在阅读文本内容时,谁也难以保证会按照从头到尾的顺序往下看完整个文件。如果只想查看文本中前 20 行的内容,该怎么办呢?head 命令可以派上用场了:
head -n 20 test.txt
4. tail命令
tail 命令用于查看纯文本文档的后 N 行或持续刷新内容,格式为“tail [选项] [文件]”。
我们可能还会遇到另外一种情况,比如需要查看文本内容的最后 20 行,这时就需要用到tail 命令了。tail 命令的操作方法与 head 命令非常相似,只需要执行“tail -n 20 文件名”命令就可以达到这样的效果。tail 命令最强悍的功能是可以持续刷新一个文件的内容,当想要实时查看最新日志文件时,这特别有用,此时的命令格式为“tail -f 文件名”:
# 先一次性查看末尾100行内容,之后动态刷新
tail -f test.txt -n100
5. tr命令
tr 命令用于替换文本文件中的字符,格式为“tr [原始字符] [目标字符]”。(我想用sed -i)
在很多时候,我们想要快速地替换文本中的一些词汇,又或者把整个文本内容都进行替换,如果进行手工替换,难免工作量太大,尤其是需要处理大批量的内容时,进行手工替换更是不现实。这时,就可以先使用 cat 命令读取待处理的文本,然后通过管道符(详见第 3 章)(😓管道符|?)把这些文本内容传递给 tr 命令进行替换操作即可。例如,把某个文本内容中的英文全部替换为大写:
[root@linuxprobe ~]# cat anaconda-ks.cfg | tr [a-z] [A-Z]
#VERSION=RHEL7
# SYSTEM AUTHORIZATION INFORMATION
AUTH --ENABLESHADOW --PASSALGO=SHA512
# USE CDROM INSTALLATION MEDIA
CDROM
# RUN THE SETUP AGENT ON FIRST BOOT
FIRSTBOOT --ENABLE
IGNOREDISK --ONLY-USE=SDA
# KEYBOARD LAYOUTS
KEYBOARD --VCKEYMAP=US --XLAYOUTS='US'
# SYSTEM LANGUAGE
LANG EN_US.UTF-8
# NETWORK INFORMATION
NETWORK --BOOTPROTO=DHCP --DEVICE=ENO16777728 --ONBOOT=OFF --IPV6=AUTO
NETWORK --HOSTNAME=LOCALHOST.LOCALDOMAIN
# ROOT PASSWORD
ROOTPW --ISCRYPTED $6$PDJJF42G8C6PL069$II.PX/YFAQPO0ENW2PA7MOMKJLYOAE2ZJMZ2UZJ7
BH3UO4OWTR1.WK/HXZ3XIGMZGJPCS/MGPYSSOI8HPCT8B/
# SYSTEM TIMEZONE
TIMEZONE AMERICA/NEW_YORK --ISUTC
USER --NAME=LINUXPROBE --PASSWORD=$6$A9V3INSTNBWEIR7D$JEGFYWBCDOOOKJ9SODECCDO.
ZLF4OSH2AZ2SS2R05B6LZ2A0V2K.RJWSBALL2FEKQVGF640OA/TOK6J.7GUTO/ --ISCRYPTED --
GECOS="LINUXPROBE"
# X WINDOW SYSTEM CONFIGURATION INFORMATION
XCONFIG --STARTXONBOOT
# SYSTEM BOOTLOADER CONFIGURATION
BOOTLOADER --LOCATION=MBR --BOOT-DRIVE=SDA
AUTOPART --TYPE=LVM
# PARTITION CLEARING INFORMATION
CLEARPART --NONE --INITLABEL
%PACKAGES
@BASE
@CORE
@DESKTOP-DEBUGGING
@DIAL-UP
@FONTS
@GNOME-DESKTOP
@GUEST-AGENTS
@GUEST-DESKTOP-AGENTS
@INPUT-METHODS
@INTERNET-BROWSER
@MULTIMEDIA
@PRINT-CLIENT
@X11
%END
6. wc命令
wc 命令用于统计指定文本的行数、字数、字节数,格式为“wc [参数] 文本”。
wc 的参数以及相应的作用如表 2-10 所示。
表 2-10 wc的参数以及作用
| 参数 | 作用 |
|---|---|
| -l | 只显示行数 |
| -w | 只显示单词数 |
| -c | 只显示字节数 |
在 Linux 系统中,passwd 是用于保存系统账户信息的文件,要统计当前系统中有多少个用户,可以使用下面的命令来进行查询,是不是很神奇:
[root@linuxprobe ~]# wc -l /etc/passwd
38 /etc/passwd
7. stat命令
stat 命令用于查看文件的具体存储信息和时间等信息,格式为“stat 文件名称”。
stat 命令可以用于查看文件的存储信息和时间等信息,命令 stat anaconda-ks.cfg 会显示出文件的三种时间状态(已加粗):Access、Modify、Change。这三种时间的区别将在下面的 touch命令中详细详解:
[root@linuxprobe ~]# stat anaconda-ks.cfg
File: ‘anaconda-ks.cfg’
Size: 1213 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 68912908 Links: 1
Access: (0600/-rw-------) Uid: ( 0/ root) Gid: ( 0/ root)
Context: system_u:object_r:admin_home_t:s0
Access: 2017-07-14 01:46:18.721255659 -0400
Modify: 2017-05-04 15:44:36.916027026 -0400
Change: 2017-05-04 15:44:36.916027026 -0400
Birth: -
8. cut命令
cut 命令用于按“列”提取文本字符,格式为“cut [参数] 文本”。例cut -d需要认定的分隔符 -f列序号 文件名
在 Linux 系统中,如何准确地提取出最想要的数据,这也是我们应该重点学习的内容。一般而言,按基于“行”的方式来提取数据是比较简单的,只需要设置好要搜索的关键词即可。但是如果按列搜索,不仅要使用-f 参数来设置需要看的列数,还需要使用-d 参数来设置间隔符号。passwd 在保存用户数据信息时,用户信息的每一项值之间是采用冒号来间隔的,接下来我们使用下述命令尝试提取出 passwd 文件中的用户名信息,即提取以冒号(:)为间隔符号的第一列内容:
[root@linuxprobe ~]# head -n 2 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@linuxprobe ~]# cut -d: -f1 /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
games
ftp
nobody
dbus
polkitd
unbound
colord
usbmuxd
avahi
avahi-autoipd
libstoragemgmt
saslauth
qemu
rpc
rpcuser
nfsnobody
rtkit
radvd
ntp
chrony
abrt
pulse
gdm
gnome-initial-setup
postfix
sshd
tcpdump
linuxprobe
9. diff命令
diff 命令用于比较多个文本文件的差异,格式为“diff [参数] 文件”。
在使用 diff 命令时,不仅可以使用--brief 参数来确认两个文件是否不同,还可以使用-c参数来详细比较出多个文件的差异之处,这绝对是判断文件是否被篡改的有力神器(也没那么神,别人注入病毒替换可执行文件,二进制的可执行文件怎么比?)。例如,先使用 cat 命令分别查看 diff_A.txt 和 diff_B.txt 文件的内容,然后进行比较:
[root@linuxprobe ~]# cat diff_A.txt
Welcome to linuxprobe.com
Red Hat certified
Free Linux Lessons
Professional guidance
Linux Course
[root@linuxprobe ~]# cat diff_B.txt
Welcome tooo linuxprobe.com
Red Hat certified
Free Linux LeSSonS
////////.....////////
Professional guidance
Linux Course
接下来使用 diff --brief 命令显示比较后的结果,判断文件是否相同:
[root@linuxprobe ~]# diff --brief diff_A.txt diff_B.txt
Files diff_A.txt and diff_B.txt differ
最后使用带有-c 参数的 diff 命令来描述文件内容具体的不同:
[root@linuxprobe ~]# diff -c diff_A.txt diff_B.txt
*** diff_A.txt 2017-08-30 18:07:45.230864626 +0800
--- diff_B.txt 2017-08-30 18:08:52.203860389 +0800
***************
*** 1,5 ****
! Welcome to linuxprobe.com
Red Hat certified
! Free Linux Lessons
Professional guidance
Linux Course
--- 1,7 ----
! Welcome tooo linuxprobe.com
!
Red Hat certified
! Free Linux LeSSonS
! ////////.....////////
Professional guidance
Linux Course
2.7 文件目录管理命令
目前为止,我们学习 Linux 命令就像是在夯实地基,虽然表面上暂时还看不到成果,但其实大家的内功已经相当雄厚了。在 Linux 系统的日常运维工作中,还需要掌握对文件的创建、修改、复制、剪切、更名与删除等操作。
1. touch命令
touch 命令用于创建空白文件或设置文件的时间,格式为“touch [选项] [文件]”。
在创建空白的文本文件方面,这个 touch 命令相当简捷,简捷到没有必要铺开去讲。比如,touch linuxprobe 命令可以创建出一个名为 linuxprobe 的空白文本文件。对 touch 命令来讲,有难度的操作主要是体现在设置文件内容的修改时间(mtime)、文件权限或属性的更改时间(ctime)与文件的读取时间(atime)上面。touch 命令的参数及其作用如表 2-11所示。
表 2-11 touch 命令的参数及其作用
| 参数 | 作用 |
|---|---|
| -a | 仅修改"读取时间"(atime) |
| -m | 仅修改"修改时间"(mtime) |
| -d | 同时修改atime与mtime |
接下来,我们先使用ls命令查看一个文件的修改时间,然后修改这个文件,最后再通过touch命令把修改后的文件时间设置成修改之前的时间(很多黑客就是这样做的呢):
[root@linuxprobe ~]# ls -l anaconda-ks.cfg
-rw-------. 1 root root 1213 May 4 15:44 anaconda-ks.cfg
[root@linuxprobe ~]# echo "Visit the LinuxProbe.com to learn linux skills" >>
anaconda-ks.cfg
[root@linuxprobe ~]# ls -l anaconda-ks.cfg
-rw-------. 1 root root 1260 Aug 2 01:26 anaconda-ks.cfg
[root@linuxprobe ~]# touch -d "2017-05-04 15:44" anaconda-ks.cfg
[root@linuxprobe ~]# ls -l anaconda-ks.cfg
-rw-------. 1 root root 1260 May 4 15:44 anaconda-ks.cfg
2. mkdir命令
mkdir 命令用于创建空白的目录,格式为“mkdir [选项] 目录”。在 Linux 系统中,文件夹是最常见的文件类型之一。除了能创建单个空白目录外,mkdir命令还可以结合-p 参数来递归创建出具有嵌套叠层关系的文件目录。(很简单的一个命令)
[root@linuxprobe ~]# mkdir linuxprobe
[root@linuxprobe ~]# cd linuxprobe
[root@linuxprobe linuxprobe]# mkdir -p a/b/c/d/e
[root@linuxprobe linuxprobe]# cd a
[root@linuxprobe a]# cd b
[root@linuxprobe b]#
3. cp命令
cp 命令用于复制文件或目录,格式为“cp [选项] 源文件 目标文件”。
大家对文件复制操作应该不陌生,在 Linux 系统中,复制操作具体分为 3 种情况:
- 如果目标文件是目录,则会把源文件复制到该目录中;
- 如果目标文件也是普通文件,则会询问是否要覆盖它;
- 如果目标文件不存在,则执行正常的复制操作。
- (源文件为目录,且是不为空的目录,直接使用cp不带参数会复制失败,至少带个-r,或者-a)
cp命令的参数及其作用如表2-12所示。
表2-12 cp命令的参数及其作用
| 参数 | 作用 |
| :--| :--|
| -p | 保留原始文件的属性 |
| -d | 若对象为"链接文件",则保留该"链接文件"的属性 |
| -r | 递归持续复制(用于目录) |
| -i | 若目标文件存在则询问是否覆盖 |
| -a | 相当于-pdr(p、d、r为上述参数) |
接下来,使用 touch 创建一个名为 install.log 的普通空白文件,然后将其复制为一份名为x.log 的备份文件,最后再使用 ls 命令查看目录中的文件:
[root@linuxprobe ~]# touch install.log
[root@linuxprobe ~]# cp install.log x.log
[root@linuxprobe ~]# ls
install.log x.log
4. mv命令
mv 命令用于剪切文件或将文件重命名,格式为“mv [选项] 源文件 [目标路径|目标文件名]”。
剪切操作不同于复制操作,因为它会默认把源文件删除掉,只保留剪切后的文件。如果在同一个目录中对一个文件进行剪切操作,其实也就是对其进行重命名:(那么是否等价于手工cp一次再rm一次呢?)
[root@linuxprobe ~]# mv x.log linux.log
[root@linuxprobe ~]# ls
install.log linux.log
5. rm命令
rm 命令用于删除文件或目录,格式为“rm [选项] 文件”。
在 Linux 系统中删除文件时,系统会默认向您询问是否要执行删除操作,如果不想总是看到这种反复的确认信息,可在 rm 命令后跟上-f 参数(force强制)来强制删除。另外,想要删除一个目录,需要在 rm 命令后面一个-r 参数(recursion递归)才可以,否则删除不掉(所以我一般偷懒就记rm -rf)。我们来尝试删除前面创建的 install.log和 linux.log 文件:
[root@linuxprobe ~]# rm install.log
rm: remove regular empty file ‘install.log’? y
[root@linuxprobe ~]# rm -f linux.log
[root@linuxprobe ~]# ls
[root@linuxprobe ~]#
6. dd命令
dd 命令用于按照指定大小和个数的数据块来复制文件或转换文件,格式为“dd [参数]”
dd 命令是一个比较重要而且比较有特色的一个命令,它能够让用户按照指定大小和个数的数据块来复制文件的内容。当然如果愿意的话,还可以在复制过程中转换其中的数据。Linux系统中有一个名为/dev/zero 的设备文件,每次在课堂上解释它时都充满哲学理论的色彩。因为这个文件不会占用系统存储空间,但却可以提供无穷无尽的数据,因此可以使用它作为 dd命令的输入文件,来生成一个指定大小的文件。dd 命令的参数及其作用如表 2-13 所示。
表2-13 dd命令的参数及其作用
| 参数 | 作用 |
|---|---|
| if | 输入的文件名称 |
| of | 输出的文件名称 |
| bs | 设置每个"块"的大小 |
| count | 设置要复制"块"的个数 |
例如我们可以用 dd 命令从/dev/zero 设备文件中取出一个大小为 560MB 的数据块,然后保存成名为 560_file 的文件。在理解了这个命令后,以后就能随意创建任意大小的文件了:
[root@linuxprobe ~]# dd if=/dev/zero of=560_file count=1 bs=560M
1+0 records in
1+0 records out
587202560 bytes (587 MB) copied, 27.1755 s, 21.6 MB/s
dd 命令的功能也绝不仅限于复制文件这么简单。如果您想把光驱设备中的光盘制作成 iso 格式的镜像文件,在 Windows 系统中需要借助于第三方软件才能做到,但在 Linux 系统中可以直接使用 dd 命令来压制出光盘镜像文件,将它编程一个可立即使用的 iso 镜像:(知识盲区.jpg,我能直接把可执行二进制文件制作成windows的exe可执行程序吗?)
[root@linuxprobe ~]# dd if=/dev/cdrom of=RHEL-server-7.0-x86_64-LinuxProbe.Com.iso
7311360+0 records in
7311360+0 records out
3743416320 bytes (3.7 GB) copied, 370.758 s, 10.1 MB/s
考虑到有些读者会纠结 bs 块大小与 count 块个数的关系,下面举一个吃货的例子进行解释。假设小明的饭量(即需求)是一个固定的值,用来盛饭的勺子的大小即 bs 块大小,而用勺子盛饭的次数即 count 块个数。小明要想吃饱(满足需求),则需要在勺子大小(bs块大小)与用勺子盛饭的次数(count 块个数)之间进行平衡。勺子越大,用勺子盛饭的次数就越少。有上可见,bs 与 count 都是用来指定容量的大小,只要能满足需求,可随意组合搭配方式。
7. file命令
file 命令用于查看文件的类型,格式为“file 文件名”。
在 Linux 系统中,由于文本、目录、设备等所有这些一切都统称为文件,而我们又不能单凭后缀就知道具体的文件类型,这时就需要使用 file 命令来查看文件类型了。(感觉这个命令还不错)
[root@linuxprobe ~]# file anaconda-ks.cfg
anaconda-ks.cfg: ASCII text
[root@linuxprobe ~]# file /dev/sda
/dev/sda: block special
2.8 打包压缩与搜索命令
在网络上,人们越来越倾向于传输压缩格式的文件,原因是压缩文件体积小,在网速相同的情况下,传输时间短。下面将学习如何在 Linux 系统中对文件进行打包压缩与解压,以及让用户基于关键词在文本文件中搜索相匹配的信息、在整个文件系统中基于指定的名称或属性搜索特定文件。本节虽然只有 3 条命令,但是其功能都比较复杂而且参数很多,因此放到了本章最后讲解。
1. tar命令(zip/unzip命令需自行安装,自带的为tar)
tar 命令用于对文件进行打包压缩或解压,格式为“tar [选项] [文件]”。
在 Linux 系统中,常见的文件格式比较多,其中主要使用的是.tar 或.tar.gz 或.tar.bz2 格式,我们不用担心格式太多而记不住,其实这些格式大部分都是由 tar 命令来生成的。刘遄老师将讲解最重要的几个参数,以方便大家理解。tar 命令的参数及其作用如表 2-14 所示。
表2-14 tar命令的参数及其作用
| 参数 | 作用 |
|---|---|
| -c | 创建压缩文件 |
| -x | 解开压缩文件 |
| -t | 查看压缩包内有哪些文件 |
| -z | 用Gzip压缩或解压 |
| -j | 用bzip2压缩或解压 |
| -v | 显示压缩或解压的过程 |
| -f | 目标文件名 |
| -p | 保留原始的权限与属性 |
| -P | 使用绝对路径来压缩 |
| -C | 指定解压到的目录 |
首先,-c 参数用于创建压缩文件,-x 参数用于解压文件,因此这两个参数不能同时使用。其次,-z 参数指定使用 Gzip 格式来压缩或解压文件,-j 参数指定使用 bzip2 格式来压缩或解压文件。用户使用时则是根据文件的后缀来决定应使用何种格式参数进行解压。在执行某些压缩或解压操作时,可能需要花费数个小时,如果屏幕一直没有输出,您一方面不好判断打包的进度情况,另一方面也会怀疑电脑死机了,因此非常推荐使用-v 参数向用户不断显示压缩或解压的过程。-C 参数用于指定要解压到哪个指定的目录。-f 参数特别重要,它必须放到参数的最后一位,代表要压缩或解压的软件包名称。刘遄老师一般使用“tar -czvf 压缩包名称.tar.gz 要打包的目录”命令把指定的文件进行打包压缩;相应的解压命令为“tar -xzvf 压缩包名称.tar.gz”。
一般都带-vf参数.
压缩tar -cvf 指定压缩包名 源文件或目录 ,解压tar -xvf 源压缩包名 -C 指定目录名.
下面我们来逐个演示下打包压缩与解压的操作。先使用 tar 命令把/etc 目录通过 gzip 格式进行打包压缩,并把文件命名为 etc.tar.gz:
[root@linuxprobe ~]# tar -czvf etc.tar.gz /etc
tar: Removing leading '/' from member names
/etc/
/etc/fstab
/etc/crypttab
/etc/mtab
/etc/fonts/
/etc/fonts/conf.d/
/etc/fonts/conf.d/65-0-madan.conf
/etc/fonts/conf.d/59-liberation-sans.conf
/etc/fonts/conf.d/90-ttf-arphic-uming-embolden.conf
/etc/fonts/conf.d/59-liberation-mono.conf
/etc/fonts/conf.d/66-sil-nuosu.conf
………………省略部分压缩过程信息………………
接下来将打包后的压缩包文件指定解压到/root/etc 目录中(先使用 mkdir 命令来创建/root/etc 目录)(对于连续参数可以省略-符号):
[root@linuxprobe ~]# mkdir /root/etc
[root@linuxprobe ~]# tar xzvf etc.tar.gz -C /root/etc
etc/
etc/fstab
etc/crypttab
etc/mtab
etc/fonts/
etc/fonts/conf.d/
etc/fonts/conf.d/65-0-madan.conf
etc/fonts/conf.d/59-liberation-sans.conf
etc/fonts/conf.d/90-ttf-arphic-uming-embolden.conf
etc/fonts/conf.d/59-liberation-mono.conf
etc/fonts/conf.d/66-sil-nuosu.conf
etc/fonts/conf.d/65-1-vlgothic-gothic.conf
etc/fonts/conf.d/65-0-lohit-bengali.conf
etc/fonts/conf.d/20-unhint-small-dejavu-sans.conf
………………省略部分解压过程信息………………
2. grep命令
grep 命令用于在文本中执行关键词搜索,并显示匹配的结果,格式为“grep [选项] [文件]”。
grep 命令的参数及其作用如表 2-15 所示。
表2-15 grep命令的参数及其作用
| 参数 | 命令 |
|---|---|
| -b | 将可执行文件(binary)当作文本文件(text)来搜索 |
| -c | 仅显示找到的行数 |
| -i | 忽略大小写 |
| -n | 显示行号 |
| -v | 反向选择—仅列出没有“关键词”的行 |
grep 命令是用途最广泛的文本搜索匹配工具,虽然有很多参数,但是大多数基本上都用不到。刘遄老师在总结了近 10 年的运维工作和培训教学的经验后,提出的本书的写作理念“去掉不实用”绝对不是信口开河。如果一名 IT 培训讲师的水平只能停留在“技术的搬运工”层面,而不能对优质技术知识进行提炼总结,那对他的学生来讲绝非好事。我们在这里只讲两个最最常用的参数:-n 参数用来显示搜索到信息的行号;-v 参数用于反选信息(即没有包含关键词的所有信息行)(确实比较好用)。这两个参数几乎能完成您日后 80%的工作需要,至于其他上百个参数,即使以后在工作期间遇到了,再使用 man grep 命令查询也来得及。
在 Linux 系统中,/etc/passwd 文件是保存着所有的用户信息,而一旦用户的登录终端被设置成/sbin/nologin,则不再允许登录系统,因此可以使用 grep 命令来查找出当前系统中不允许登录系统的所有用户信息:
[root@linuxprobe ~]# grep /sbin/nologin /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
………………省略部分输出过程信息………………
3. find命令
find 命令用于按照指定条件来查找文件,格式为“find [查找路径] 寻找条件 操作”。
本书中曾经多次提到“Linux 系统中的一切都是文件”,接下来就要见证这句话的分量了。在 Linux 系统中,搜索工作一般都是通过 find 命令来完成的,它可以使用不同的文件特性作为寻找条件(如文件名、大小、修改时间、权限等信息),一旦匹配成功则默认将信息显示到屏幕上。find 命令的参数以及作用如表 2-16 所示。
表2-16 find命令的参数及其作用
| 参数 | 作用 |
|---|---|
| -name | 匹配名称 |
| -perm | 匹配权限(mode为完全匹配,-mode为包含即可) |
| -user | 匹配所有者 |
| -group | 匹配所有组 |
| -mtime -n +n | 匹配修改内容的时间(-n 指 n 天以内,+n 指 n 天以前) |
| -atime -n +n | 匹配访问文件的时间(-n 指 n 天以内,+n 指 n 天以前) |
| -ctime -n +n | 匹配修改文件权限的时间(-n 指 n 天以内,+n 指 n 天以前) |
| -nouser | 匹配无所有者的文件 |
| -nogroup | 匹配无所有组的文件 |
| -newer f1 !f2 | 匹配比文件 f1 新但比 f2 旧的文件 |
| --type b/d/c/p/l/f | 匹配文件类型(后面的字幕参数依次表示块设备、目录、字符设备、管道、链接文件、文本文件) |
| -size | 匹配文件的大小(+50KB 为查找超过 50KB 的文件,而-50KB 为查找小于50KB 的文件) |
| -prune | 忽略某个目录 |
| -exec ..... {} ; | 后面可跟用于进一步处理搜索结果的命令(下文会有演示) |
这里需要重点讲解一下-exec 参数重要的作用。这个参数用于把 find 命令搜索到的结果交由紧随其后的命令作进一步处理,它十分类似于第 3 章将要讲解的管道符技术,并且由于 find命令对参数的特殊要求,因此虽然 exec 是长格式形式,但依然只需要一个减号(-)。
根据文件系统层次标准(Filesystem Hierarchy Standard)协议,Linux 系统中的配置文件会保存到/etc 目录中(详见第 6 章)。如果要想获取到该目录中所有以 host 开头的文件列表,可以执行如下命令:
[root@linuxprobe ~]# find /etc -name "host*" -print
/etc/avahi/hosts
/etc/host.conf
/etc/hosts
/etc/hosts.allow
/etc/hosts.deny
/etc/selinux/targeted/modules/active/modules/hostname.pp
/etc/hostname
如果要在整个系统中搜索权限中包括 SUID 权限的所有文件(详见第 5 章),只需使用-4000 即可:
[root@linuxprobe ~]# find / -perm -4000 -print
/usr/bin/fusermount
/usr/bin/su
/usr/bin/umount
/usr/bin/passwd
/usr/sbin/userhelper
/usr/sbin/usernetctl
………………省略部分输出信息………………
进阶实验:在整个文件系统中找出所有归属于 linuxprobe 用户的文件并复制到/root/findresults 目录。
该实验的重点是“-exec {} ;”参数,其中的{}表示 find 命令搜索出的每一个文件,并且命令的结尾必须是“;”。完成该实验的具体命令如下:
[root@linuxprobe ~]# find / -user linuxprobe -exec cp -a {} /root/findresults/ \;
第三章 管道符、重定向与环境变量(自行看第二版吧,不继续写笔记了)
3.1 输入输出重定向
3.2 管道命令符
3.3 命令行的通配符
3.4 常用的转义字符
3.5 重要的环境变量
第四章 Vim 编辑器与Shell 命令脚本(自行看第二版吧,不继续写笔记了)
4.1 Vim 文本编辑器
4.2 编写Shell 脚本
4.3 流程控制语句
4.4 计划任务服务程序
第五章 用户身份与文件权限(自行看第二版吧,不继续写笔记了)
5.1 用户身份与能力
5.2 文件权限与归属
5.3 文件的特殊权限
5.4 文件的隐藏属性
5.5 文件访问控制列表
5.6 su 命令与sudo 服务
第六章 存储结构与磁盘划分
6.1 一切从“/”开始
在 Linux 系统中,目录、字符设备、块设备、套接字、打印机等都被抽象成了文件,即刘遄老师所一直强调的“Linux 系统中一切都是文件”。既然平时我们打交道的都是文件,那么又应该如何找到它们呢?
在 Windows 操作系统中,想要找到一个文件,我们要依次进入该文件所在的磁盘分区(假设这里是 D 盘),然后在进入该分区下的具体目录,最终找到这个文件。
但是在 Linux系统中并不存在 C/D/E/F 等盘符,Linux 系统中的一切文件都是从“根(/)”目录开始的,并按照文件系统层次化标准(FHS,Filesystem Hierarchy Standard)采用树形结构来存放文件,以及定义了常见目录的用途。
另外,Linux系统中的文件和目录名称是严格区分大小写的。例如,root、rOOt、Root、rooT 均代表不同的目录,并且文件名称中不得包含斜杠(/)。
Linux 系统中的文件存储结构如图:
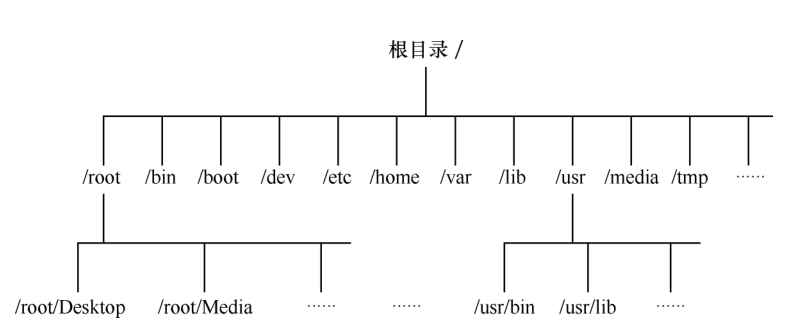
前文提到的 FHS 是根据以往无数 Linux 系统用户和开发者的经验而总结出来的,是用户在 Linux 系统中存储文件时需要遵守的规则,用于指导我们应该把文件保存到什么位置,以及告诉用户应该在何处找到所需的文件。但是,FHS 对于用户来讲只能算是一种道德上的约束,有些用户就是懒得遵守,依然会把文件到处乱放,有些甚至从来没有听说过它。这里并不是号召各位读者去谴责他们,而是建议大家要灵活运用所学的知识,千万不要认准这个 FHS协定只讲死道理,不然吃亏的可就是自己了。在 Linux 系统中,最常见的目录以及所对应的存放内容如表6-1所示。
表6-1 Linux系统中常见的目录名称及相应内容
| 目录名称 | 应放置文件的内容 |
|---|---|
| /boot | 开机所需文件—内核、开机菜单以及所需配置文件等 |
| /dev | 以文件形式存放任何设备与接口 |
| /etc | 配置文件 |
| /home | 用户家目录 |
| /bin | 存放单用户模式下还可以操作的命令 |
| /lib | 开机时用到的函数库,以及/bin 与/sbin 下面的命令要调用的函数 |
| /sbin | 开机过程中需要的命令 |
| /media | 用于挂载设备文件的目录 |
| /opt | 放置第三方的软件 |
| /root | 系统管理员的家目录 |
| /srv | 一些网络服务的数据文件目录 |
| /tmp | 任何人均可使用的"共享"临时目录 |
| /proc | 虚拟文件系统,例如系统内核、进程、外部设备及网络状态等 |
| /usr/local | 用户自行安装的软件 |
| /usr/sbin | Linux 系统开机时不会使用到的软件/命令/脚本 |
| /usr/share | 帮助与说明文件,也可放置共享文件 |
| /var | 主要存放经常变化的文件,如日志 |
| /lost+found | 当文件系统发生错误时,将一些丢失的文件片段存放在这里 |
在 Linux 系统中另外还有一个重要的概念—路径。路径指的是如何定位到某个文件,分为绝对路径与相对路径。绝对路径指的是从根目录(/)开始写起的文件或目录名称,而相对路径则指的是相对于当前路径的写法。我们来看下面这个例子,以帮助大家理解。假如有位外国游客来到中国潘家园旅游,当前内急但是找不到洗手间,特意向您问路,那么您有两种正确的指路方法。
- 绝对路径(absolute path):首先坐飞机来到中国,到了北京出首都机场坐机场快轨到三元桥,然后换乘 10 号线到潘家园站,出站后坐 34 路公交车到农光里,下车后路口左转。
- 相对路径(relative path):前面路口左转。
这两种方法都正确。如果您说的是绝对路径,那么任何一位外国游客都可以按照这个提示找到潘家园的洗手间,但是太繁琐了。如果您说的是相对路径,虽然表达很简练,但是这位外国游客只能从当前位置(不见得是潘家园)出发找到洗手间,因此并不能保证在前面的路口左转后可以找到洗手间,由此可见,相对路径不具备普适性。
个人发言:出于安全性考虑,是不允许网页通过浏览器直接访问主机绝对路径的文件资源的,该用相对路径时还得用
6.2 物理设备的命名规则
在 Linux 系统中一切都是文件,硬件设备也不例外。既然是文件,就必须有文件名称。系统内核中的 udev 设备管理器会自动把硬件名称规范起来,目的是让用户通过设备文件的名字可以猜出设备大致的属性以及分区信息等;这对于陌生的设备来说特别方便。另外,udev设备管理器的服务会一直以守护进程的形式运行并侦听内核发出的信号来管理/dev 目录下的设备文件。Linux 系统中常见的硬件设备的文件名称如表 6-2 所示。
表6-2 常见的硬件设备及其文件名称
| 硬件设备 | 文件名称 |
|---|---|
| IDE设备 | /dev/hd[a-d] |
| SCSI/SATA/U 盘 | /dev/sd[a-p] |
| 软驱 | /dev/fd[0-1] |
| 打印机 | /dev/lp[0-15] |
| 光驱 | /dev/cdrom |
| 鼠标 | /dev/mouse |
| 磁带机 | /dev/st0 或/dev/ht0 |
由于现在的 IDE 设备已经很少见了,所以一般的硬盘设备都会是以“/dev/sd”开头的。而一台主机上可以有多块硬盘,因此系统采用 a~p 来代表 16 块不同的硬盘(默认从 a 开始分配),而且硬盘的分区编号也很有讲究:
-
主分区或扩展分区的编号从 1 开始,到 4 结束;
-
逻辑分区从编号 5 开始。
国内很多 Linux 培训讲师以及很多知名 Linux 图书在讲到设备和分区名称时,总会讲错两个知识点。第一个知识点是设备名称的理解错误。很多培训讲师和 Linux 技术图书中会提到,比如/dev/sda 表示主板上第一个插槽上的存储设备,学员或读者在实践操作的时候会发现果然如此,因此也就对这条理论知识更加深信不疑。但真相不是这样的,/dev 目录中 sda 设备之所以是 a,并不是由插槽决定的,而是由系统内核的识别顺序来决定的,而恰巧很多主板的插槽顺序就是系统内核的识别顺序,因此才会被命名为/dev/sda。大家以后在使用 iSCSI 网络存储设备时就会发现,明明主板上第二个插槽是空着的,但系统却能识别到/dev/sdb 这个设备就是这个道理。
第二个知识点是对分区名称的理解错误。很多 Linux 培训讲师会告诉学员,分区的编号代表分区的个数。比如 sda3 表示这是设备上的第三个分区,而学员在做实验的时候确实也会得出这样的结果,但是这个理论知识是错误的,因为分区的数字编码不一定是强制顺延下来的,也有可能是手工指定的。因此 sda3 只能表示是编号为 3 的分区,而不能判断 sda 设备上已经存在了 3 个分区。
在填了这两个“坑”之后,刘遄老师再来分析一下/dev/sda5 这个设备文件名称包含哪些信息,如图所示。
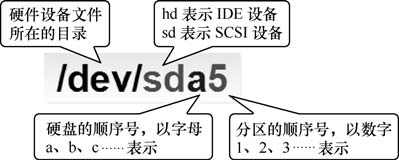
首先,/dev/目录中保存的应当是硬件设备文件;其次,sd 表示是存储设备;然后,a 表示系统中同类接口中第一个被识别到的设备,最后,5 表示这个设备是一个逻辑分区。一言以蔽之,“/dev/sda5”表示的就是“这是系统中第一块被识别到的硬件设备中分区编号为 5 的逻辑分区的设备文件”。
考虑到我们的很多读者完全没有 Linux 基础,不太容易理解前面所说的主分区、扩展分区和逻辑分区的概念,因此接下来简单科普一下硬盘相关的知识。
正是因为计算机有了硬盘设备,我们才可以在玩游戏的过程中或游戏通关之后随时存档,而不用每次重头开始。硬盘设备是由大量的扇区组成的,每个扇区的容量为 512 字节。其中第一个扇区最重要,它里面保存着主引导记录与分区表信息。就第一个扇区来讲,主引导记录需要占用 446 字节,分区表为 64 字节,结束符占用 2 字节;其中分区表中每记录一个分区信息就需要 16 字节,这样一来最多只有 4 个分区信息可以写到第一个扇区中,这 4 个分区就是 4 个主分区。第一个扇区中的数据信息如图所示。
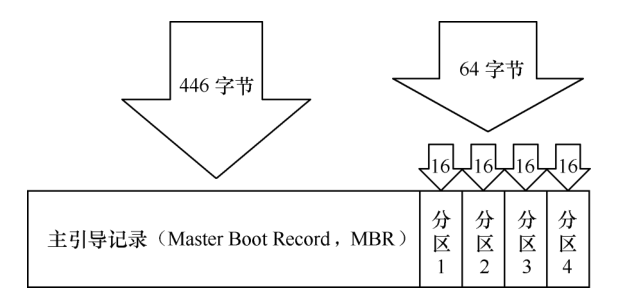
现在,问题来了—第一个扇区最多只能创建出 4 个分区?于是为了解决分区个数不够的问题,可以将第一个扇区的分区表中 16 字节(原本要写入主分区信息)的空间(称之为扩展分区)拿出来指向另外一个分区。也就是说,扩展分区其实并不是一个真正的分区,而更像是一个占用 16 字节分区表空间的指针—一个指向另外一个分区的指针。这样一来,用户一般会选择使用 3 个主分区加 1 个扩展分区的方法,然后在扩展分区中创建出数个逻辑分区,从而来满足多分区(大于 4 个)的需求。当然,就目前来讲大家只要明白为什么主分区不能超过 4 个就足够了。主分区、扩展分区、逻辑分区可以像下图这样来规划。
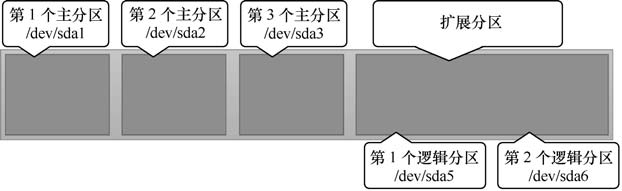
注:所谓扩展分区,严格地讲它不是一个实际意义的分区,它仅仅是一个指向下一个分区的指针,这种指针结构将形成一个单向链表。
注:读者可以试着解读一下/dev/sdb8 的意思。
6.3 文件系统与数据资料
用户在硬件存储设备中执行的文件建立、写入、读取、修改、转存与控制等操作都是依靠文件系统来完成的。文件系统的作用是合理规划硬盘,以保证用户正常的使用需求。Linux系统支持数十种的文件系统,而最常见的文件系统如下所示。
- Ext3:是一款日志文件系统,能够在系统异常宕机时避免文件系统资料丢失,并能自动修复数据的不一致与错误。然而,当硬盘容量较大时,所需的修复时间也会很长,而且也不能百分之百地保证资料不会丢失。它会把整个磁盘的每个写入动作的细节都预先记录下来,以便在发生异常宕机后能回溯追踪到被中断的部分,然后尝试进行修复。
- Ext4:Ext3 的改进版本,作为 RHEL 6 系统中的默认文件管理系统,它支持的存储容量高达 1EB(1EB=1024PB=1048576TB=1,073,741,824GB),且能够有无限多的子目录。另外,Ext4 文件系统能够批量分配 block 块,从而极大地提高了读写效率。
- XFS:是一种高性能的日志文件系统,而且是 RHEL 7 中默认的文件管理系统,它的优势在发生意外宕机后尤其明显,即可以快速地恢复可能被破坏的文件,而且强大的日志功能只用花费极低的计算和存储性能。并且它最大可支持的存储容量为 18EB,这几乎满足了所有需求。
RHEL 7 系统中一个比较大的变化就是使用了 XFS 作为文件系统,这不同于 RHEL 6 使用的 Ext4。从红帽公司官方发布的说明来看,这确实是一个不小的进步,但是刘遄老师在实测中发现并不完全属实。因为单纯就测试一款文件系统的“读取”性能来说,到底要读取多少个文件,每个文件的大小是多少,读取文件时的 CPU、内存等系统资源的占用率如何,以及不同的硬件配置是否会有不同的影响,因此在充分考虑到这些不确定因素后,实在不敢直接照抄红帽官方的介绍。我个人认为 XFS 虽然在性能方面比 Ext4 有所提升,但绝不是压倒性的,因此 XFS 文件系统最卓越的亮点应该当属可支持高达 18EB 的存储容量吧。(个人见解:实力非常雄厚的企业才用得到吧,1PB就很贵了,不敢想象.jpg)
就像拿到了一张未裁切的完整纸张那样,我们首先要进行裁切以方便使用,然后在裁切后的纸张上画格以便能书写工整。在拿到了一块新的硬盘存储设备后,也需要先分区,然后再格式化文件系统,最后才能挂载并正常使用。硬盘的分区操作取决于您的需求和硬盘大小;您也可以选择不进行分区,但是必须对硬盘进行格式化处理。接下来刘遄老师再向大家简单地科普一下硬盘在格式化后发生的事情。再次强调,不用刻意去记住,只要能看懂就行了。
日常在硬盘需要保存的数据实在太多了,因此 Linux 系统中有一个名为 super block 的“硬盘地图”。Linux 并不是把文件内容直接写入到这个“硬盘地图”里面,而是在里面记录着整个文件系统的信息。因为如果把所有的文件内容都写入到这里面,它的体积将变得非常大,而且文件内容的查询与写入速度也会变得很慢。Linux 只是把每个文件的权限与属性记录在inode 中,而且每个文件占用一个独立的 inode 表格,该表格的大小默认为 128 字节,里面记录着如下信息:
- 该文件的访问权限(read、write、execute);
- 该文件的所有者与所属组(owner、group);
- 该文件的大小(size);
- 该文件的创建或内容修改时间(ctime);
- 该文件的最后一次访问时间(atime);
- 该文件的修改时间(mtime);
- 文件的特殊权限(SUID、SGID、SBIT);
- 该文件的真实数据地址(point)。
而文件的实际内容则保存在 block 块中(大小可以是 1KB、2KB 或 4KB),一个 inode 的默认大小仅为 128B(Ext3),记录一个 block 则消耗 4B。当文件的 inode 被写满后,Linux 系统会自动分配出一个 block 块,专门用于像 inode 那样记录其他 block 块的信息,这样把各个block 块的内容串到一起,就能够让用户读到完整的文件内容了。对于存储文件内容的 block块,有下面两种常见情况(以 4KB 的 block 大小为例进行说明)。
- 情况 1:文件很小(1KB),但依然会占用一个 block,因此会潜在地浪费 3KB。
- 情况 2:文件很大(5KB),那么会占用两个 block(5KB-4KB 后剩下的 1KB 也要占用一个 block)。
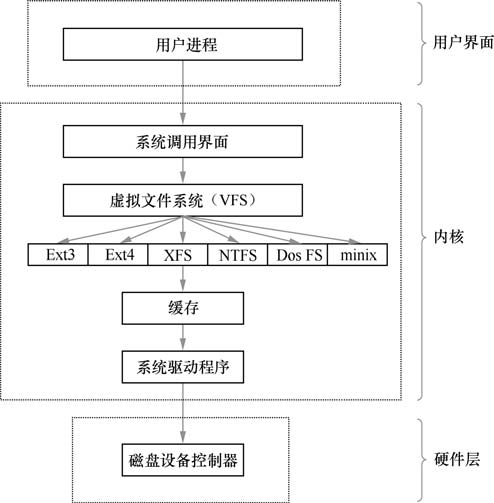
计算机系统在发展过程中产生了众多的文件系统,为了使用户在读取或写入文件时不用关心底层的硬盘结构,Linux 内核中的软件层为用户程序提供了一个 VFS(Virtual File System,虚拟文件系统)接口,这样用户实际上在操作文件时就是统一对这个虚拟文件系统进行操作了。下图所示为 VFS 的架构示意图。从中可见,实际文件系统在 VFS 下隐藏了自己的特性和细节,这样用户在日常使用时会觉得“文件系统都是一样的”,也就可以随意使用各种命令在任何文件系统中进行各种操作了(比如使用 cp 命令来复制文件)。
6.4 挂载硬件设备
我们在用惯了 Windows 系统后总觉得一切都是理所当然的,平时把 U 盘插入到电脑后也从来没有考虑过 Windows 系统做了哪些事情,才使得我们可以访问这个 U 盘的。接下来我们会逐一学习在 Linux 系统中挂载和卸载存储设备的方法,以便大家更好地了解 Linux 系统添加硬件设备的工作原理和流程。前面讲到,在拿到一块全新的硬盘存储设备后要先分区,然后格式化,最后才能挂载并正常使用。“分区”和“格式化”大家以前经常听到,但“挂载”又是什么呢?刘遄老师在这里给您一个最简单、最贴切的解释—当用户需要使用硬盘设备或分区中的数据时,需要先将其与一个已存在的目录文件进行关联,而这个关联动作就是“挂载”。下文将向读者逐步讲解如何使用硬盘设备,但是鉴于与挂载相关的理论知识比较复杂,而且很重要,因此决定再拿出一个小节单独讲解,这次希望大家不仅要看懂,而且还要记住。
6.4.1 mount命令
mount 命令用于挂载文件系统,格式为“mount 文件系统 挂载目录”。mount 命令中可用的参数及作用如表 6-3 所示。挂载是在使用硬件设备前所执行的最后一步操作。只需使用mount 命令把硬盘设备或分区与一个目录文件进行关联,然后就能在这个目录中看到硬件设备中的数据了。对于比较新的 Linux 系统来讲,一般不需要使用-t 参数来指定文件系统的类型,Linux 系统会自动进行判断。而 mount 中的-a 参数则厉害了,它会在执行后自动检查/etc/fstab文件中有无疏漏被挂载的设备文件,如果有,则进行自动挂载操作。
表6-3 mount命令中的参数及作用
| 参数 | 作用 |
|---|---|
| -a | 挂载所有在/etc/fstab 中定义的文件系统 |
| -t | 指定文件系统的类型 |
例如,要把设备/dev/sdb2 挂载到/backup 目录(那允许/backup目录原本是不为空的状态进行挂载吗?),只需要在 mount 命令中填写设备与挂载目录参数就行,系统会自动去判断要挂载文件的类型,因此只需要执行下述命令即可:
[root@linuxprobe ~]# mount /dev/sdb2 /backup
虽然按照上面的方法执行 mount 命令后就能立即使用文件系统了,但系统在重启后挂载就会失效,也就是说我们需要每次开机后都手动挂载一下。这肯定不是我们想要的效果,如果想让硬件设备和目录永久地进行自动关联,就必须把挂载信息按照指定的填写格式“设备文件 挂载目录 格式类型 权限选项 自检 优先级”(各字段的意义见表 6-4)写入到/etc/fstab 文件中。这个文件中包含着挂载所需的诸多信息项目,一旦配置好之后就能一劳永逸了。
表6-4 用于挂载信息的指定填写格式中,各字段所表示的意义
| 字段 | 意义 |
|---|---|
| 设备文件 | 一般为设备的路径+设备名称,也可以写唯一识别码(UUID,Universally Unique Identifier) |
| 挂载目录 | 指定要挂载到的目录,需在挂载前创建好(可以在挂载前存在一些文件吗?有没有必须为空目录的要求?) |
| 格式类型 | 指定文件系统的格式,比如 Ext3、Ext4、XFS、SWAP、iso9660(此为光盘设备)等(怎样看文件系统类型?) |
| 权限选项 | 若设置为 defaults,则默认权限为:rw, suid, dev, exec, auto, nouser, async |
| 自检 | 若为 1 则开机后进行磁盘自检,为 0 则不自检 |
| 优先级 | 若“自检”字段为 1,则可对多块硬盘进行自检优先级设置 |
如果想将文件系统为 ext4 的硬件设备/dev/sdb2 在开机后自动挂载到/backup 目录上,并保持默认权限且无需开机自检,就需要在/etc/fstab 文件中写入下面的信息,这样在系统重启后也会成功挂载。
[root@linuxprobe ~]# vim /etc/fstab
#
# /etc/fstab
# Created by anaconda on Wed May 4 19:26:23 2017
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 1 1
UUID=812b1f7c-8b5b-43da-8c06-b9999e0fe48b /boot xfs defaults 1 2
/dev/mapper /rhel-swap swap swap defaults 0 0
/dev/cdrom /media/cdrom iso9660 defaults 0 0
/dev/sdb2 /backup ext4 defaults 0 0
6.4.2 umount命令
umount 命令用于撤销已经挂载的设备文件,格式为“umount [挂载点/设备文件]”。我们挂载文件系统的目的是为了使用硬件资源,而卸载文件系统就意味不再使用硬件的设备资源;相对应地,挂载操作就是把硬件设备与目录进行关联的动作,因此卸载操作只需要说明想要取消关联的设备文件或挂载目录的其中一项即可,一般不需要加其他额外的参数。我们来尝试手动卸载掉/dev/sdb2 设备文件(那卸载掉后,原本被挂载了的目录,里面的文件是会消失,还是会将文件划分到/根目录的容量下):
[root@linuxprobe ~]# umount /dev/sdb2
6.5 添加硬盘设备
根据前文讲解的与管理硬件设备相关的理论知识,我们先来理清一下添加硬盘设备的操作思路:首先需要在虚拟机中模拟添加入一块新的硬盘存储设备,然后再进行分区、格式化、挂载等操作,最后通过检查系统的挂载状态并真实地使用硬盘来验证硬盘设备是否成功添加。
鉴于我们不需要为了做这个实验而特意买一块真实的硬盘,而是通过虚拟机软件进行硬件模拟,因此这再次体现出了使用虚拟机软件的好处。具体的操作步骤如下。首先把虚拟机系统关机,稍等几分钟会自动返回到虚拟机管理主界面,然后单击“编辑虚拟机设置”选项,在弹出的界面中单击“添加”按钮,新增一块硬件设备,如下图所示。
选择想要添加的硬件类型为“硬盘”,然后单击“下一步”按钮就可以了,这确实没有什么需要进一步解释的,如图所示。
选择虚拟硬盘的类型为 SCSI(默认推荐),并单击“下一步”按钮,这样虚拟机中的设备名称过一会儿后应该为/dev/sdb,如图所示。
选中“创建新虚拟磁盘”单选按钮,而不是其他选项,再次单击“下一步”按钮,如图所示。
将“最大磁盘大小”设置为默认的 20GB。这个数值是限制这台虚拟机所使用的最大硬盘空间,而不是立即将其填满,因此默认 20GB 就很合适了。单击“下一步”按钮,如图所示。
设置磁盘文件的文件名和保存位置(这里采用默认设置即可,无需修改),直接单击“完成”按钮,如图所示。
将新硬盘添加好后就可以看到设备信息了。这里不需要做任何修改,直接单击“确认”按钮后就可以开启虚拟机了,如图所示。
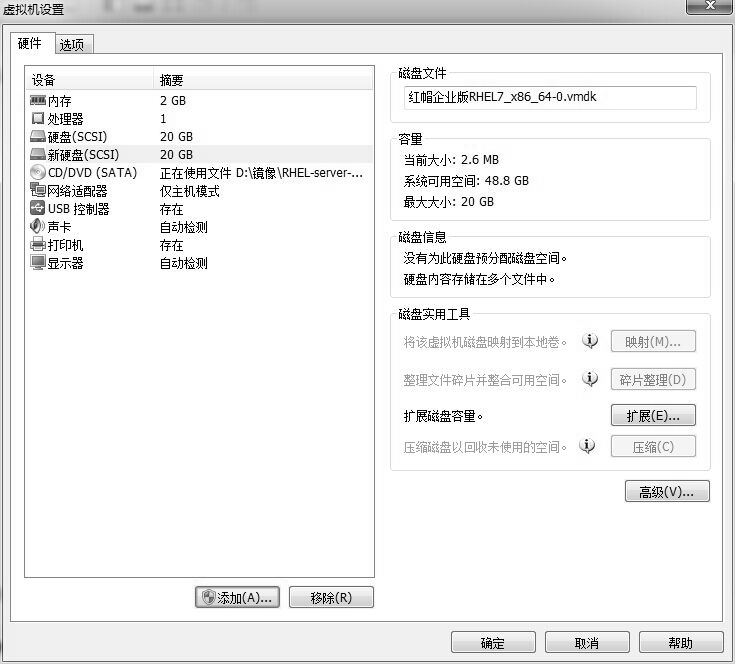
在虚拟机中模拟添加了硬盘设备后就应该能看到抽象成的硬盘设备文件了。按照前文讲解的 udev 服务命名规则,第二个被识别的 SCSI 设备应该会被保存为/dev/sdb,这个就是硬盘设备文件了。但在开始使用该硬盘之前还需要进行分区操作,例如从中取出一个 2GB 的分区设备以供后面的操作使用。
6.5.1 fdisk命令
在 Linux 系统中,管理硬盘设备最常用的方法就当属 fdisk 命令了。fdisk 命令用于管理磁盘分区,格式为“fdisk [磁盘名称]”,它提供了集添加、删除、转换分区等功能于一身的“一站式分区服务”。不过与前面讲解的直接写到命令后面的参数不同,这条命令的参数(见表 6-5)是交互式的,因此在管理硬盘设备时特别方便,可以根据需求动态调整。
表6-5 fdisk 命令中的参数以及作用
| 参数 | 作用 |
|---|---|
| m | 查看全部可用的参数 |
| n | 添加新的分区 |
| d | 删除某个分区信息 |
| l | 列出所有可用的分区类型 |
| t | 改变某个分区的类型 |
| p | 查看分区信息 |
| w | 保存并退出 |
| q | 不保存直接退出 |
我们首先使用 fdisk 命令来尝试管理/dev/sdb 硬盘设备。在看到提示信息后输入参数 p 来查看硬盘设备内已有的分区信息,其中包括了硬盘的容量大小、扇区个数等信息:
[root@linuxprobe ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x47d24a34.
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x47d24a34
Device Boot Start End Blocks Id System
输入参数 n 尝试添加新的分区。系统会要求您是选择继续输入参数 p 来创建主分区,还是输入参数 e 来创建扩展分区。这里输入参数 p 来创建一个主分区:
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
在确认创建一个主分区后,系统要求您先输入主分区的编号。我们在前文得知,主分区的编号范围是 1~4,因此这里输入默认的 1 就可以了。接下来系统会提示定义起始的扇区位置,这不需要改动,我们敲击回车键保留默认设置即可,系统会自动计算出最靠前的空闲扇区的位置。最后,系统会要求定义分区的结束扇区位置,这其实就是要去定义整个分区的大小是多少。我们不用去计算扇区的个数,只需要输入+2G 即可创建出一个容量为 2GB 的硬盘分区。
Partition number (1-4, default 1): 1
First sector (2048-41943039, default 2048):此处敲击回车
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-41943039, default 41943039): +2G
Partition 1 of type Linux and of size 2 GiB is set
再次使用参数 p 来查看硬盘设备中的分区信息。果然就能看到一个名称为/dev/sdb1、起始扇区位置为 2048、结束扇区位置为 4196351 的主分区了。这时候千万不要直接关闭窗口,而应该敲击参数 w 后回车,这样分区信息才是真正的写入成功啦。
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x47d24a34
Device Boot Start End Blocks Id System
/dev/sdb1 2048 4196351 2097152 83 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
在上述步骤执行完毕之后,Linux 系统会自动把这个硬盘主分区抽象成/dev/sdb1 设备文件。我们可以使用 file 命令查看该文件的属性,但是刘遄老师在讲课和工作中发现,有些时候系统并没有自动把分区信息同步给 Linux 内核,而且这种情况似乎还比较常见(但不能算作是严重的 bug)。我们可以输入 partprobe 命令手动将分区信息同步到内核,而且一般推荐连续两次执行该命令,效果会更好。如果使用这个命令都无法解决问题,那么就重启计算机吧,这个杀手锏百试百灵,一定会有用的。
[root@linuxprobe ]# file /dev/sdb1
/dev/sdb1: cannot open (No such file or directory)
[root@linuxprobe ]# partprobe
[root@linuxprobe ]# partprobe
[root@linuxprobe ]# file /dev/sdb1
/dev/sdb1: block special
如果硬件存储设备没有进行格式化,则 Linux 系统无法得知怎么在其上写入数据。因此,在对存储设备进行分区后还需要进行格式化操作。在 Linux 系统中用于格式化操作的命令是mkfs。这条命令很有意思,因为在 Shell 终端中输入 mkfs 名后再敲击两下用于补齐命令的 Tab键,会有如下所示的效果:
[root@linuxprobe ~]# mkfs
mkfs mkfs.cramfs mkfs.ext3 mkfs.fat mkfs.msdos mkfs.xfs
mkfs.btrfs mkfs.ext2 mkfs.ext4 mkfs.minix mkfs.vfat
对!这个 mkfs 命令很贴心地把常用的文件系统名称用后缀的方式保存成了多个命令文件,用起来也非常简单—mkfs.文件类型名称。例如要格式分区为 XFS 的文件系统,则命令应为 mkfs.xfs /dev/sdb1。
[root@linuxprobe ~]# mkfs.xfs /dev/sdb1
meta-data=/dev/sdb1 isize=256 agcount=4, agsize=131072 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0
data = bsize=4096 blocks=524288, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
终于完成了存储设备的分区和格式化操作,接下来就是要来挂载并使用存储设备了。与之相关的步骤也非常简单:首先是创建一个用于挂载设备的挂载点目录;然后使用 mount 命令将存储设备与挂载点进行关联;最后使用 df -h 命令来查看挂载状态和硬盘使用量信息(通过这个命令没有展示出来的,是不是就是还没有进行挂载的硬盘,还没挂载的想要挂载需不需要格式化)。
[root@linuxprobe ~]# mkdir /newFS
[root@linuxprobe ~]# mount /dev/sdb1 /newFS/
[root@linuxprobe ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 18G 3.5G 15G 20% /
devtmpfs 905M 0 905M 0% /dev
tmpfs 914M 140K 914M 1% /dev/shm
tmpfs 914M 8.8M 905M 1% /run
tmpfs 914M 0 914M 0% /sys/fs/cgroup
/dev/sr0 3.5G 3.5G 0 100% /media/cdrom
/dev/sda1 497M 119M 379M 24% /boot
/dev/sdb1 2.0G 33M 2.0G 2% /newFS
6.5.2 du命令
既然存储设备已经顺利挂载,接下来就可以尝试通过挂载点目录向存储设备中写入文件了。在写入文件之前,先介绍一个用于查看文件数据占用量的 du 命令,其格式为“du [选项][文件]”。简单来说,该命令就是用来查看一个或多个文件占用了多大的硬盘空间。我们还可以使用 du -sh /*命令来查看在 Linux 系统根目录下所有一级目录分别占用的空间大小。下面,我们先从某些目录中复制过来一批文件,然后查看这些文件总共占用了多大的容量:
[root@linuxprobe ~]# cp -rf /etc/* /newFS/
[root@linuxprobe ~]# ls /newFS/
abrt hosts pulse
adjtime hosts.allow purple
aliases hosts.deny qemu-ga
aliases.db hp qemu-kvm
alsa idmapd.conf radvd.conf
alternatives init.d rc0.d
anacrontab inittab rc1.d
………………省略部分输入信息………………
[root@linuxprobe ~]# du -sh /newFS/
33M /newFS/
细心的读者一定还记得,前面在讲解 mount 命令时提到,使用 mount 命令挂载的设备文件会在系统下一次重启的时候失效。如果想让这个设备文件的挂载永久有效,则需要把挂载的信息写入到配置文件中:
[root@linuxprobe ~]# vim /etc/fstab
#
# /etc/fstab
# Created by anaconda on Wed May 4 19:26:23 2017
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 1 1
UUID=812b1f7c-8b5b-43da-8c06-b9999e0fe48b /boot xfs defaults 1 2
/dev/mapper /rhel-swap swap swap defaults 0 0
/dev/cdrom /media/cdrom iso9660 defaults 0 0
/dev/sdb1 /newFS xfs defaults 0 0
6.6 添加交换分区
SWAP(交换)分区是一种通过在硬盘中预先划分一定的空间,然后将把内存中暂时不常用的数据临时存放到硬盘中,以便腾出物理内存空间让更活跃的程序服务来使用的技术,其设计目的是为了解决真实物理内存不足的问题。但由于交换分区毕竟是通过硬盘设备读写数据的,速度肯定要比物理内存慢,所以只有当真实的物理内存耗尽后才会调用交换分区的资源。
交换分区的创建过程与前文讲到的挂载并使用存储设备的过程非常相似。在对/dev/sdb存储设备进行分区操作前,有必要先说一下交换分区的划分建议:在生产环境中,交换分区的大小一般为真实物理内存的 1.5~2 倍,为了让大家更明显地感受交换分区空间的变化,这里取出一个大小为 5GB 的主分区作为交换分区资源。在分区创建完毕后保存并退出即可:
[root@linuxprobe ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0xb3d27ce1.
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extendedSelect (default p): p
Partition number (2-4, default 2):
First sector (4196352-41943039, default 4196352): 此处敲击回车
Using default value 4196352
Last sector, +sectors or +size{K,M,G} (4196352-41943039, default 41943039): +5G
Partition 2 of type Linux and of size 5 GiB is set
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xb0ced57f
Device Boot Start End Blocks Id System
/dev/sdb1 2048 4196351 2097152 83 Linux
/dev/sdb2 4196352 14682111 5242880 83 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
使用 SWAP 分区专用的格式化命令 mkswap,对新建的主分区进行格式化操作:
[root@linuxprobe ~]# mkswap /dev/sdb2
Setting up swapspace version 1, size = 5242876 KiB
no label, UUID=2972f9cb-17f0-4113-84c6-c64b97c40c75
使用 swapon 命令把准备好的 SWAP 分区设备正式挂载到系统中。我们可以使用 free -m 命令查看交换分区的大小变化(由 2047MB 增加到 7167MB):
[root@linuxprobe ~]# free -m
total used free shared buffers cached
Mem: 1483 782 701 9 0 254
-/+ buffers/cache: 526 957
Swap: 2047 0 2047
[root@linuxprobe ~]# swapon /dev/sdb2
[root@linuxprobe ~]# free -m
total used free shared buffers cached
Mem: 1483 785 697 9 0 254
-/+ buffers/cache: 530 953
Swap: 7167 0 7167
为了能够让新的交换分区设备在重启后依然生效,需要按照下面的格式将相关信息写入到配置文件中,并记得保存:
[root@linuxprobe ~]# vim /etc/fstab
#
# /etc/fstab
# Created by anaconda on Wed May 4 19:26:23 2017
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 1 1
UUID=812b1f7c-8b5b-43da-8c06-b9999e0fe48b /boot xfs defaults 1 2
/dev/mapper /rhel-swap swap swap defaults 0 0
/dev/cdrom /media/cdrom iso9660 defaults 0 0
/dev/sdb1 /newFS xfs defaults 0 0
/dev/sdb2 swap swap defaults 0 0
6.7 磁盘容量配额
本书在前面曾经讲到,Linux 系统的设计初衷就是让许多人一起使用并执行各自的任务,从而成为多用户、多任务的操作系统。但是,硬件资源是固定且有限的,如果某些用户不断地在 Linux 系统上创建文件或者存放电影,硬盘空间总有一天会被占满。针对这种情况,root管理员就需要使用磁盘容量配额服务来限制某位用户或某个用户组针对特定文件夹可以使用的最大硬盘空间或最大文件个数,一旦达到这个最大值就不再允许继续使用。可以使用 quota命令进行磁盘容量配额管理,从而限制用户的硬盘可用容量或所能创建的最大文件个数。quota命令还有软限制和硬限制的功能。
- 软限制:当达到软限制时会提示用户,但仍允许用户在限定的额度内继续使用。
- 硬限制:当达到硬限制时会提示用户,且强制终止用户的操作。
RHEL 7 系统中已经安装了 quota 磁盘容量配额服务程序包,但存储设备却默认没有开启对 quota 的支持,此时需要手动编辑配置文件,让 RHEL 7 系统中的/boot 目录能够支持 quota磁盘配额技术。另外,对于学习过早期的 Linux 系统,或者具有 RHEL 6 系统使用经验的读者来说,这里需要特别注意。早期的 Linux 系统要想让硬盘设备支持 quota 磁盘容量配额服务,使用的是 usrquota 参数,而 RHEL 7 系统使用的则是 uquota 参数。在重启系统后使用 mount命令查看,即可发现/boot 目录已经支持 quota 磁盘配额技术了:
[root@linuxprobe ~]# vim /etc/fstab
#
# /etc/fstab
# Created by anaconda on Wed May 4 19:26:23 2017
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 1 1
UUID=812b1f7c-8b5b-43da-8c06-b9999e0fe48b /boot xfs defaults,uquota 1 2
/dev/mapper /rhel-swap swap swap defaults 0 0
/dev/cdrom /media/cdrom iso9660 defaults 0 0
/dev/sdb1 /newFS xfs defaults 0 0
/dev/sdb2 swap swap defaults 0 0
[root@linuxprobe ~]# reboot
[root@linuxprobe ~]# mount | grep boot
/dev/sda1 on /boot type xfs (rw,relatime,seclabel,attr2,inode64,usrquota)
接下来创建一个用于检查 quota 磁盘容量配额效果的用户 tom,并针对/boot 目录增加其他人的写权限,保证用户能够正常写入数据:
[root@linuxprobe ~]# useradd tom
[root@linuxprobe ~]# chmod -Rf o+w /boot
6.7.1 xfs_quota命令
xfs_quota 命令是一个专门针对 XFS 文件系统来管理 quota 磁盘容量配额服务而设计的命令,格式为“quota [参数] 配额 文件系统”。其中,-c 参数用于以参数的形式设置要执行的命令;-x参数是专家模式,让运维人员能够对 quota 服务进行更多复杂的配置。接下来我们使用 xfs_quota命令来设置用户 tom 对/boot 目录的 quota 磁盘容量配额。具体的限额控制包括:硬盘使用量的软限制和硬限制分别为 3MB 和 6MB;创建文件数量的软限制和硬限制分别为 3 个和 6 个。
[root@linuxprobe ~]# xfs_quota -x -c 'limit bsoft=3m bhard=6m isoft=3 ihard=6
tom' /boot
6.8 软硬方式链接
131
[root@linuxprobe ~]# xfs_quota -x -c report /boot
User quota on /boot (/dev/sda1) Blocks
User ID Used Soft Hard Warn/Grace
---------- --------------------------------------------------
root 95084 0 0 00 [--------]
tom 0 3072 6144 00 [--------]
当配置好上述的各种软硬限制后,尝试切换到这个普通用户,然后分别尝试创建一个体积为 5MB 和 8MB 的文件。可以发现,在创建 8MB 的文件时受到了系统限制:
[root@linuxprobe ~]# su - tom
[tom@linuxprobe ~]$ dd if=/dev/zero of=/boot/tom bs=5M count=1
1+0 records in
1+0 records out
5242880 bytes (5.2 MB) copied, 0.123966 s, 42.3 MB/s
[tom@linuxprobe ~]$ dd if=/dev/zero of=/boot/tom bs=8M count=1
dd: error writing ‘/boot/tom’: Disk quota exceeded
1+0 records in
0+0 records out
6291456 bytes (6.3 MB) copied, 0.0201593 s, 312 MB/s
6.7.2 edquota命令
edquota 命令用于编辑用户的 quota 配额限制,格式为“edquota [参数] [用户] ”。在为用户设置了 quota 磁盘容量配额限制后,可以使用 edquota 命令按需修改限额的数值。其中,-u参数表示要针对哪个用户进行设置;-g 参数表示要针对哪个用户组进行设置。edquota 命令会调用 Vi 或 Vim 编辑器来让 root 管理员修改要限制的具体细节。下面把用户 tom 的硬盘使用量的硬限额从 5MB 提升到 8MB:
[root@linuxprobe ~]# edquota -u tom
Disk quotas for user tom (uid 1001):
Filesystem blocks soft hard inodes soft hard
/dev/sda 6144 3072 8192 1 3 6
[root@linuxprobe ~]# su - tom
Last login: Mon Sep 7 16:43:12 CST 2017 on pts/0
[tom@linuxprobe ~]$ dd if=/dev/zero of=/boot/tom bs=8M count=1
1+0 records in
1+0 records out
8388608 bytes (8.4 MB) copied, 0.0268044 s, 313 MB/s
[tom@linuxprobe ~]$ dd if=/dev/zero of=/boot/tom bs=10M count=1
dd: error writing ‘/boot/tom’: Disk quota exceeded
1+0 records in
0+0 records out
8388608 bytes (8.4 MB) copied, 0.167529 s, 50.1 MB/s
6.8 软硬方式链接
当引领大家学习完本章所有的硬盘管理知识之后,刘遄老师终于可以放心大胆地讲解Linux 系统中的“快捷方式”了。在 Windows 系统中,快捷方式就是指向原始文件的一个链接文件,可以让用户从不同的位置来访问原始的文件;原文件一旦被删除或剪切到其他地方后,会导致链接文件失效。但是,这个看似简单的东西在 Linux 系统中可不太一样。
在 Linux 系统中存在硬链接和软连接两种文件。
- 硬链接(hard link):可以将它理解为一个“指向原始文件 inode 的指针”,系统不为它分配独立的 inode 和文件。所以,硬链接文件与原始文件其实是同一个文件,只是名字不同。我们每添加一个硬链接,该文件的 inode 连接数就会增加 1;而且只有当该文件的 inode 连接数为 0 时,才算彻底将它删除。换言之,由于硬链接实际上是指向原文件 inode 的指针,因此即便原始文件被删除,依然可以通过硬链接文件来访问。需要注意的是,由于技术的局限性,我们不能跨分区对目录文件进行链接。
- 软链接(也称为符号链接[symbolic link]):仅仅包含所链接文件的路径名,因此能链接目录文件,也可以跨越文件系统进行链接。但是,当原始文件被删除后,链接文件也将失效,从这一点上来说与 Windows 系统中的“快捷方式”具有一样的性质。
ln命令
ln 命令用于创建链接文件,格式为“ln [选项] 目标”,其可用的参数以及作用如表 6-6 所示。在使用 ln 命令时,是否添加-s 参数,将创建出性质不同的两种“快捷方式”。因此如果没有扎实的理论知识和实践经验做铺垫,尽管能够成功完成实验,但永远不会明白为什么会成功。
表6-6 ln 命令中可用的参数以及作用
| 参数 | 作用 |
|---|---|
| -s | 创建“符号链接”(如果不带-s 参数,则默认创建硬链接) |
| -f | 强制创建文件或目录的链接(那如果同时加了i参数,还会询问吗) |
| -i | 覆盖前先询问 |
| -v | 显示创建链接的过程 |
为了更好地理解软链接、硬链接的不同性质,接下来创建一个类似于 Windows 系统中快捷方式的软链接。这样,当原始文件被删除后,就无法读取新建的链接文件了。
[root@linuxprobe ~]# echo "Welcome to linuxprobe.com" > readme.txt
[root@linuxprobe ~]# ln -s readme.txt readit.txt
[root@linuxprobe ~]# cat readme.txt
Welcome to linuxprobe.com
[root@linuxprobe ~]# cat readit.txt
Welcome to linuxprobe.com
[root@linuxprobe ~]# ls -l readme.txt
-rw-r--r-- 1 root root 26 Jan 11 00:08 readme.txt
[root@linuxprobe ~]# rm -f readme.txt
[root@linuxprobe ~]# cat readit.txt
cat: readit.txt: No such file or directory
接下来针对一个原始文件创建一个硬链接,即相当于针对原始文件的硬盘存储位置创建了一个指针,这样一来,新创建的这个硬链接就不再依赖于原始文件的名称等信息,也不会因为原始文件的删除而导致无法读取。同时可以看到创建硬链接后,原始文件的硬盘链接数量增加到了 2。
[root@linuxprobe ~]# echo "Welcome to linuxprobe.com" > readme.txt
[root@linuxprobe ~]# ln readme.txt readit.txt
[root@linuxprobe ~]# cat readme.txt
Welcome to linuxprobe.com
[root@linuxprobe ~]# cat readit.txt
Welcome to linuxprobe.com
[root@linuxprobe ~]# ls -l readme.txt
-rw-r--r-- 2 root root 26 Jan 11 00:13 readme.txt
[root@linuxprobe ~]# rm -f readme.txt
[root@linuxprobe ~]# cat readit.txt
Welcome to linuxprobe.com
复习题
- /home 目录与/root 目录内存放的文件有何相同点以及不同点?
答:这两个目录都是用来存放用户的家目录数据的,但是,/root 目录存放的是 root 管理员的家目录数据。 - 假如一个设备的文件名称为/dev/sdb,可以确认它是主板第二个插槽上的设备吗?
答:不一定,因为设备的文件名称是由系统的识别顺序来决定的。 - 如果硬盘中需要 5 个分区,至少需要几个逻辑分区?
答:可以选用创建 3 个主分区+1 个扩展分区的方法,然后把扩展分区再分成 2 个逻辑分区,即有了 5 个分区。 - /dev/sda5 是主分区还是逻辑分区?
答:逻辑分区。 - 哪个服务决定了设备在/dev 目录中的名称?
答:udev 设备管理器服务。 - 用一句话来描述挂载操作。
答:当用户需要使用硬盘设备或分区中的数据时,需要先将其与一个已存在的目录文件进行关联,而这个关联动作就是“挂载”。 - 在配置 quota 磁盘容量配额服务时,软限制数值必须小于硬限制数值么?
答:不一定,软限制数值可以小于等于硬限制数值。 - 若原始文件被改名,那么之前创建的硬链接还能访问到这个原始文件么?
答:可以。

