第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | 计科22级12班软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 完成一个论文查重算法,同时对代码进行性能分析,了解并对代码进行单元测试,学会PSP表格的使用 |
Github链接:https://github.com/AAA-Lin/AAA-Lin.git
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 160 |
| Estimate | 估计这个任务需要多少时间 | 440 | 666 |
| Development | 开发 | 300 | 560 |
| Analysis | 需求分析(包括学习新技术) | 100 | 120 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计审核 | 30 | 35 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 50 | 60 |
| Design | 具体设计 | 30 | 60 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码审核 | 50 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 60 | 80 |
| Test Report | 测试报告 | 25 | 25 |
| Size Measurement | 计算工作量 | 30 | 40 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 30 | 30 |
| 合计 | 1475 | 2136 |
计算模块接口的设计与实现
函数功能
get_file(path):获取指定的文本文件
filter(str1):将获取到的文本先进行预处理:将文本分词,再将标点符号、换行等等特殊符号过滤
convert_corpus(text1, text2):将文本的语法等等去除,把文本只看成一个个词汇的集合
file_similarity(text1, text2):将经过预处理的数据,利用gensim.similarities.Similarity计算余弦相似度
算法关键
- ieba库
jieba是优秀的中文分词第三方库,由于中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫做分词,通过jieba库可以完成这个过程。
# 将获取到的文本先进行预处理:将文本分词,再将标点符号、换行等等特殊符号过滤
def filter(str1):
str1 = jieba.lcut(str1)
result = []
for tags in str1:
if re.match(u"[a-zA-Z0-9\u4e00-\u9fa5]", tags):
result.append(tags)
else:
pass
return result
- gensim库
Gensim在诸如获取单词的词向量等任务中非常有用。本次作业选择先利用gensim.corpora.Dictionary模块生成词典,再利用gensim..similarities.Similarity来计算文本相似度。
# 将经过预处理的数据,利用gensim.similarities.Similarity计算余弦相似度
def file_similarity(text1, text2) -> object:
texts = [text1, text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
计算模块接口的性能
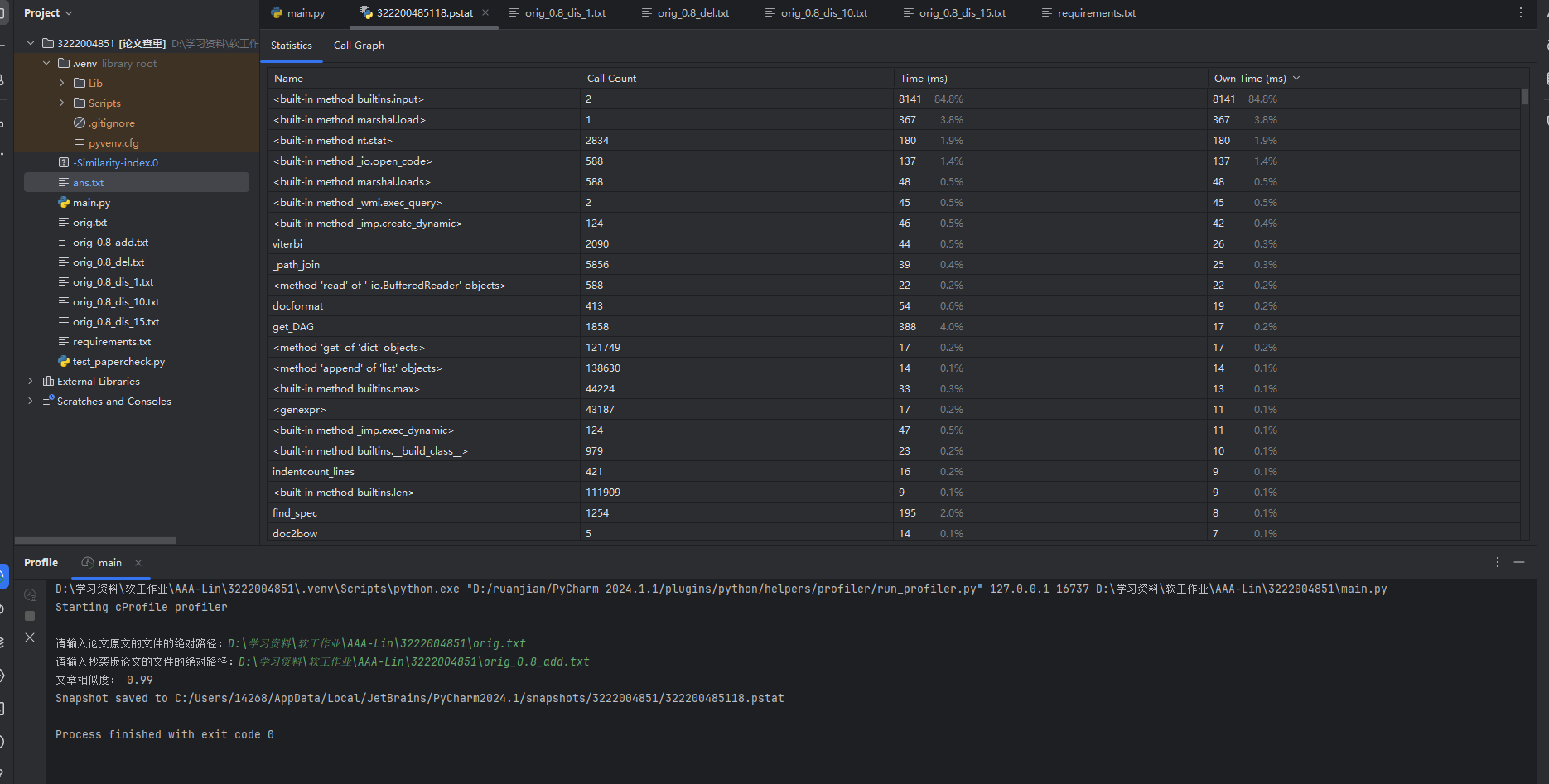
- 利用Profile对程序进行性能分析
![性能分析]()
- 代码覆盖率分析
![代码覆盖率]()
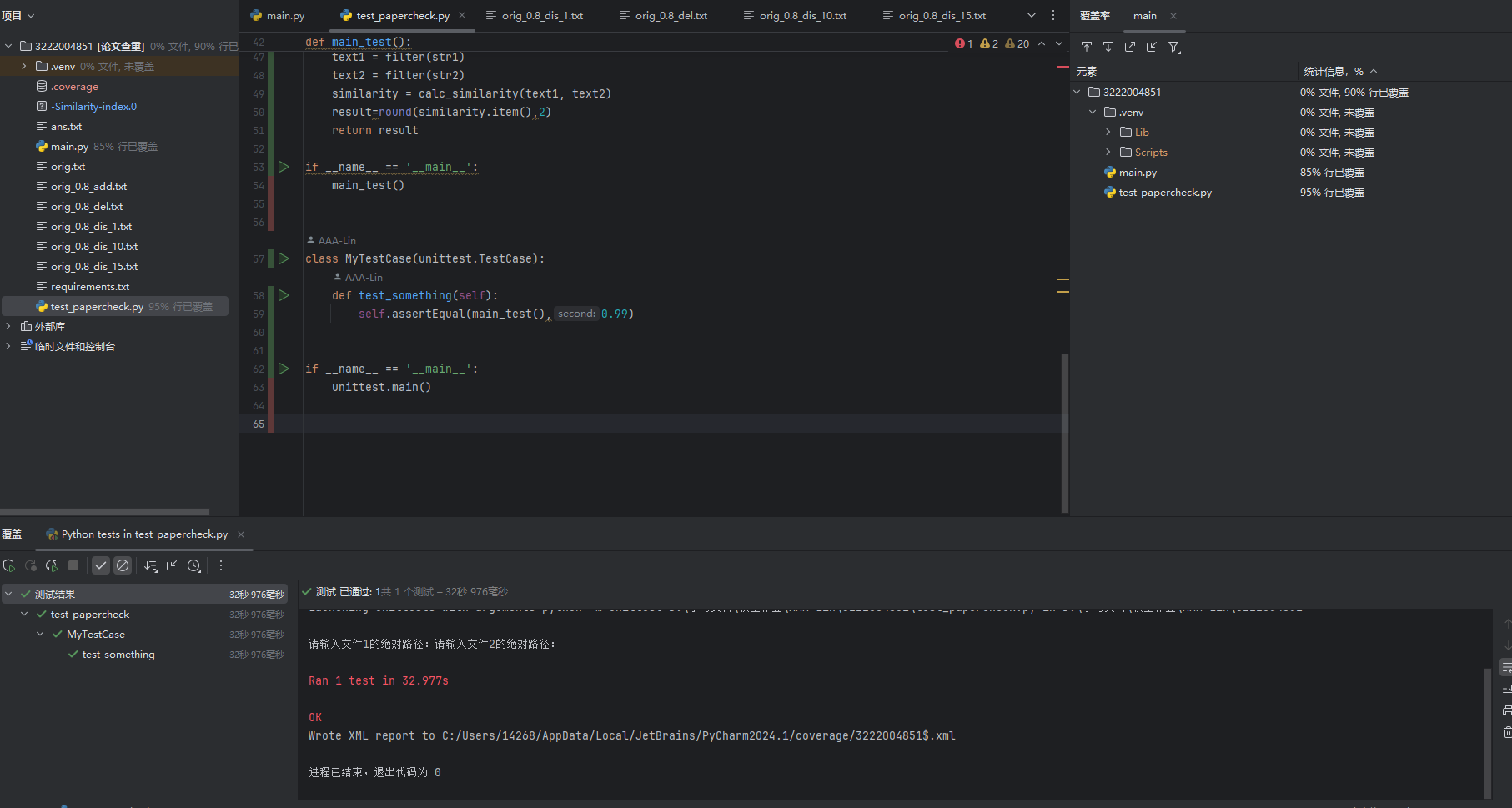
部分单元测试展示
- 利用python自带的一种单元测试框架——unittest
import unittest
import jieba
import gensim
import re
jieba.setLogLevel(jieba.logging.INFO)
# 获取指定的原文
def get_file(path):
str = ''
f = open(path, 'r', encoding='UTF-8')
line = f.readline()
while line:
str = str + line
line = f.readline()
f.close()
return str
#将读取到的文件内容先进行jieba分词,然后再把标点符号、转义符号等特殊符号过滤掉
def filter(str):
str = jieba.lcut(str)
result = []
for tags in str:
if (re.match(u"[a-zA-Z0-9\u4e00-\u9fa5]", tags)):
result.append(tags)
else:
pass
return result
#传入过滤之后的数据,通过调用gensim.similarities.Similarity计算余弦相似度
def calc_similarity(text1: object, text2: object) -> object:
texts=[text1,text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
def main_test():
path1 = input("请输入文件1的绝对路径:")
path2 = input("请输入文件2的绝对路径:")
str1 = get_file(path1)
str2 = get_file(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = calc_similarity(text1, text2)
result=round(similarity.item(),2)
return result
if __name__ == '__main__':
main_test()
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(main_test(),0.99)
if __name__ == '__main__':
unittest.main()
- 测试覆盖率
![代码覆盖率]()
异常处理
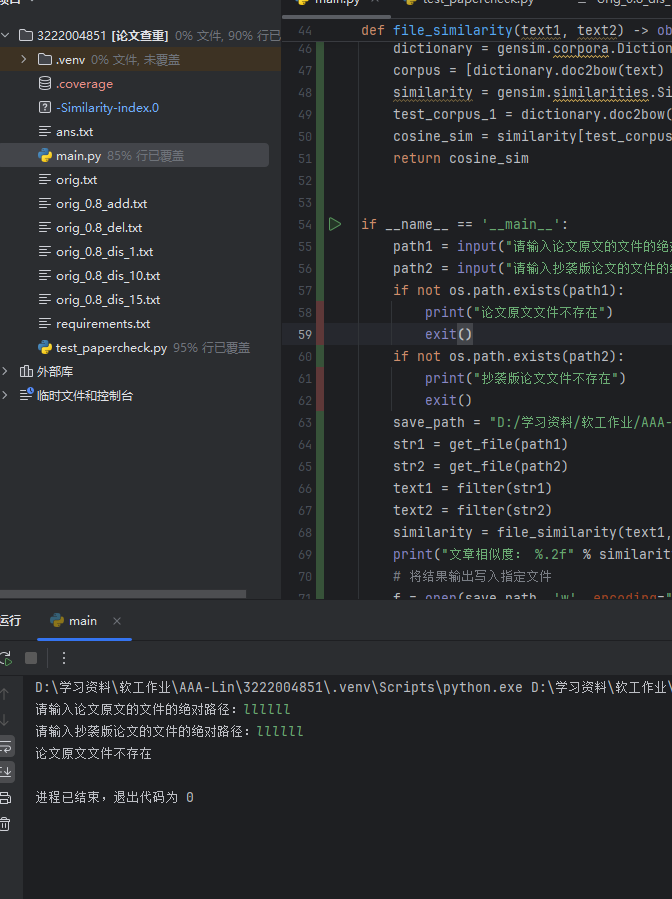
- 对输入的文本的路径判断是否存在,若不存在,将打印文件不存在并自动结束程序
if __name__ == '__main__':
path1 = input("请输入论文原文的文件的绝对路径:")
path2 = input("请输入抄袭版论文的文件的绝对路径:")
if not os.path.exists(path1):
print("论文原文文件不存在")
exit()
if not os.path.exists(path2):
print("抄袭版论文文件不存在")
exit()
save_path = "D:/学习资料/软工作业/AAA-Lin/3222004851/ans.txt" # 输出结果绝对路径
str1 = get_file(path1)
str2 = get_file(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = file_similarity(text1, text2)
print("文章相似度: %.2f" % similarity)
# 将结果输出写入指定文件
f = open(save_path, 'w', encoding="utf-8")
f.write( "文章相似度: %.2f" % similarity)
f.close()
- 测试情况
![路径不存在]()
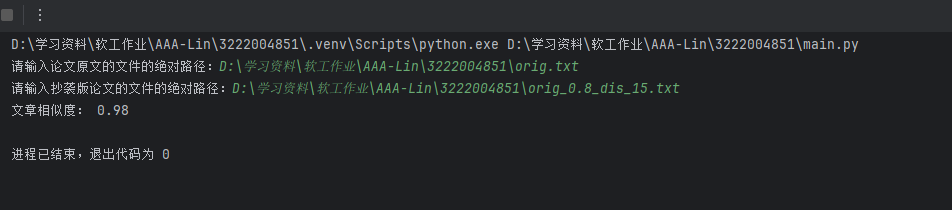
测试输出结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号