6.1、列表
6.1.1、列表声明
在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。列表就是这样的一个数据结构。
列表会将所有元素都放在一对中括号[ ]里面,相邻元素之间用逗号,分隔,如下所示:
[element1, element2, element3, ..., elementn]
不同于C,java等语言的数组,python的列表可以存放不同的,任意的数据类型对象。
1
2
3
4
5
6
|
l = [123,"yuan",True]
print(l,type(l))
# 注意
a,b = [1,2]
print(a,b)
|
6.1.2、序列操作
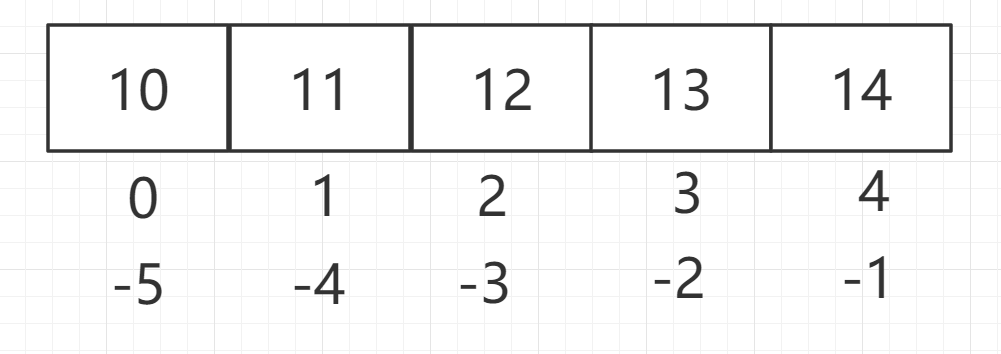
列表是 Python 序列的一种,我们可以使用索引(Index)访问列表中的某个元素(得到的是一个元素的值),也可以使用切片访问列表中的一组元素(得到的是一个新的子列表)。
![image-20210413163948909]()
1
2
3
|
l = [10,11,12,13,14]
print(l[2]) # 12
print(l[-1]) # 14
|
1
2
3
4
5
6
7
8
9
10
11
|
l = [10,11,12,13,14]
print(l[2:5])
print(l[-3:-1])
print(l[:3])
print(l[1:])
print(l[:])
print(l[2:4])
print(l[-3:-1])
print(l[-1:-3])
print(l[-1:-3:-1])
print(l[::2])
|
1、取出的元素数量为:结束位置 - 开始位置;
2、取出元素不包含结束位置对应的索引,列表最后一个元素使用 list[len(slice)] 获取;
3、当缺省开始位置时,表示从连续区域开头到结束位置;
4、当缺省结束位置时,表示从开始位置到整个连续区域末尾;
5、两者同时缺省时,与列表本身等效;
6、step为正,从左向右切,为负从右向左切。
in 关键字检查某元素是否为序列的成员
1
2
3
|
l = [10,11,12,13,14]
print(20 in l) # False
print(12 in l) # True
|
1
2
3
|
l1 = [1,2,3]
l2 = [4,5,6]
print(l1+l2) # [1, 2, 3, 4, 5, 6]
|
1
2
3
4
5
6
7
8
9
|
for name in ["张三",'李四',"王五"]:
print(name)
for i in range(10): # range函数: range(start,end,step)
print(i)
# 基于for循环从100打印到1
for i in range(100,0,-1):
print(i)
|
6.1.3、列表内置方法
| 方法 | 作用 | 示例 | 结果 |
|---|
append() |
向列表追加元素 |
l.append(4) |
l:[1, 2, 3, 4] |
insert() |
向列表任意位置添加元素 |
l.insert(0,100) |
l:[100, 1, 2, 3] |
extend() |
向列表合并一个列表 |
l.extend([4,5,6]) |
l:[1, 2, 3, 4, 5, 6] |
pop() |
根据索引删除列表元素(为空删除最后一个元素) |
l.pop(1) |
l:[1, 3] |
remove() |
根据元素值删除列表元素 |
l.remove(1) |
l:[2, 3] |
clear() |
清空列表元素 |
l.clear() |
l:[] |
sort() |
排序(升序) |
l.sort() |
l:[1,2,3] |
reverse() |
翻转列表 |
l.reverse() |
l:[3,2,1] |
count() |
元素重复的次数 |
l.count(2) |
返回值:1 |
index() |
查找元素对应索引 |
l.index(2) |
返回值:1 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
# 增删改查: [].方法()
# (1) ******************************** 增(append,insert,extend) ****************
l1 = [1, 2, 3]
# append方法:追加一个元素
l1.append(4)
print(l1) # [1, 2, 3, 4]
# insert(): 插入,即在任意位置添加元素
l1.insert(1, 100) # 在索引1的位置添加元素100
print(l1) # [1, 100, 2, 3, 4]
# 扩展一个列表:extend方法
l2 = [20, 21, 22, 23]
# l1.append(l2)
l1.extend(l2)
print(l1) # [1, 100, 2, 50, 3, 4,[20,21,22,23]]
# 打印列表元素个数python内置方法:
print(len(l1))
# (2) ******************************** 删(pop,remove,clear) **********************
l4 = [10, 20, 30, 40, 50]
# 按索引删除:pop,返回删除的元素
# ret = l4.pop(2)
# print(ret)
# print(l4) # [10, 20, 40, 50]
# 按着元素值删除
l4.remove(30)
print(l4) # [10, 20, 40, 50]
# 清空列表
l4.clear()
print(l4) # []
# (3) ******************************** 修改(没有内置方法实现修改,只能基于索引赋值) ********
l5 = [10, 20, 30, 40, 50]
# 将索引为1的值改为200
l5[1] = 200
print(l5) # [10, 200, 30, 40, 50]
# 将l5中的40改为400 ,step1:查询40的索引 step2:将索引为i的值改为400
i = l5.index(40) # 3
l5[i] = 400
print(l5) # [10, 20, 30, 400, 50]
# (4) ******************************** 查(index,sort) *******************************
l6 = [10, 50, 30, 20,40 ]
l6.reverse() # 只是翻转 [40, 20, 30, 50, 10]
print(l6) # []
# # 查询某个元素的索引,比如30的索引
# print(l6.index(30)) # 2
# 排序
# l6.sort(reverse=True)
# print(l6) # [50, 40, 30, 20, 10]
|
6.1.4、可变和不可变数据类型
Python的数据类型可以分为可变数据类型(列表和字典)和不可变数据类型(整型、浮点型、字符串、布尔类型以及元组)。
可变类型:在id(内存地址)不变的情况下,value(值)可以变,则称为可变类型
不可变类型:value(值)一旦改变,id(内存地址)也改变,则称为不可变类型(id变,意味着创建了新的内存空间)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# (1)
x = 10
print(id(x))
x = 100
print(id(x))
s = "yuan"
print(id(s))
s= "alvin"
print(id(s))
# (2)
# l = [1,2,3]
# print(id(l))
# l = [1,2,3,4]
# print(id(l))
# (3)
l = [1,2,3]
print(id(l))
l[0] = 10
print(id(l))
print(l)
l.append(4)
print(l)
|
6.1.5、深浅拷贝
深浅拷贝是python中经常涉及到一个面试,也是同学们经常出错的地方,那么什么是深浅拷贝呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 案例1:变量赋值
l1 = [1,2,3]
l2 = l1 # 不是拷贝,完全指向一块内存空间
print(id(l1))
print(id(l2))
l2[1] = 200
print(l1)
# 案例2
l1 = [1, 2, 3]
l2 = [4, 5, l1]
l1[0] = 100
print(l2)
# 案例3:浅拷贝:两种方式:切片和copy方法
l1 = [1,2,3,["yuan","alvin"]]
l2 = l1.copy() # 等同于l2 = l1[:]
print(id(l1))
print(id(l2))
l2[1] = 200
print(l1)
l2[3][0] = "张三"
print(l1)
#案例4: 深拷贝
import copy
l1 = [1,2,3,["yuan","alvin"]]
l2 = copy.deepcopy(l1)
l2[3][0] = "张三"
print(l1)
|
6.1.6、列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
1
|
variable = [表达式 for 迭代变量 in 可迭代对象 [if 条件表达式] ]
|
[if 条件表达式] 不是必须的,可以使用,也可以省略。
例如: 计算1-100中所有偶数的平方
1
2
3
|
# 计算1-100中所有偶数的平方
new_l = [i * i for i in range(100) if i % 2 == 0]
print(new_l)
|
以上所看到的列表推导式都只有一个循环,实际上它可使用多个循环,就像嵌套循环一样。
练习1:
1
2
3
4
|
old = [[1, 2], [3, 4], [5, 6]]
# 从old中一个一个取出值,对取出的值(i)再进行一次遍历取值操作(也可以进行判断或者运算)
new = [j for i in old for j in i]
print(new)
|
练习2:
1
2
3
4
|
l1 = [1, 2, 3]
l2 = [4, 5, 6]
ret = [[i,j] for i in l1 for j in l2]
print(ret) # [[1, 4], [1, 5], [1, 6], [2, 4], [2, 5], [2, 6], [3, 4], [3, 5], [3, 6]]
|
6.2、元组
6.2.1、声明元组
Python的元组与列表类似,不同之处在于元组的元素只能读,不能修改。通常情况下,元组用于保存无需修改的内容。
元组使用小括号表示,声明一个元组:
1
|
(element1, element2, element3, ..., elementn)
|
需要注意的一点是,当创建的元组中只有一个字符串类型的元素时,该元素后面必须要加一个逗号,,否则 Python 解释器会将它视为字符串。
1
2
|
l = (1,2,3)
print(l,type(l)) # (1, 2, 3) <class 'tuple'>
|
6.2.2、序列操作
和列表一样,支持索引和切片操作。
1
2
3
4
5
|
l = (1,2,3,4,5)
print(l[2]) # 3
print(l[2:4]) # (3, 4)
print(l[:4]) # (1, 2, 3, 4)
print(2 in l)
|
6.2.3、内置方法
1
2
3
|
l = (1,2,3,4,5)
print(l.count(3))
print(l.index(2))
|
6.3、字典
字典是Python提供的唯一内建的映射(Mapping Type)数据类型。
6.3.1、声明字典
python使用 { } 创建字典,由于字典中每个元素都包含键(key)和值(value)两部分,因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。
使用{ }创建字典的语法格式如下:
1
|
dictname = {'key':'value1', 'key2':'value2', ...}
|
1、同一字典中的各个键必须唯一,不能重复。
2、字典是键值对是无序的,但在3.6版本后,字典默认做成有序的了,这是新的版本特征。
6.3.2、字典的基本操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# (1) 查键值
print(book["title"]) # 返回字符串 西游记
print(book["authors"]) # 返回列表 ['rain', 'yuan']
# (2) 添加或修改键值对,注意:如果键存在,则是修改,否则是添加
book["price"] = 299 # 修改键的值
book["publish"] = "北京出版社" # 添加键值对
# (3) 删除键值对 del 删除命令
print(book)
del book["publish"]
print(book)
del book
print(book)
# (4) 判断键是否存在某字典中
print("price" in book)
# (5) 循环
for key in book:
print(key,book[key])
|
6.3.3、字典的内置方法
1
|
d = {"name":"yuan","age":18}
|
| 方法 | 作用 | 示例 | 结果 |
|---|
get() |
查询字典某键的值,取不到返回默认值 |
d.get("name",None) |
"yuan" |
setdefault() |
查询字典某键的值,取不到给字典设置键值,同时返回设置的值 |
d.setdefault("age",20) |
18 |
keys() |
查询字典中所有的键 |
d.keys() |
['name','age'] |
values() |
查询字典中所有的值 |
d.values() |
['yuan', 18] |
items() |
查询字典中所有的键和值 |
d.items() |
[('name','yuan'), ('age', 18)] |
pop() |
删除字典指定的键值对 |
d.pop(“age”) |
{'name':'yuan'} |
popitem() |
删除字典最后的键值对 |
d.popitem() |
{'name':'yuan'} |
clear() |
清空字典 |
d.clear() |
{} |
update() |
更新字典 |
t={"gender":"male","age":20}d.update(t) |
{'name':'yuan','age': 20, 'gender': 'male'} |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
dic = {"name": "yuan", "age": 22, "sex": "male"}
# (1)查字典的键的值
print(dic["names"]) # 会报错
name = dic.get("names")
sex = dic.get("sexs", "female")
print(sex)
print(dic.keys()) # 返回值:['name', 'age', 'sex']
print(dic.values()) # 返回值:['yuan', 22, 'male']
print(dic.items()) # [('name', 'yuan'), ('age', 22), ('sex', 'male')]
# setdefault取某键的值,如果能取到,则返回该键的值,如果没有改键,则会设置键值对
print(dic.setdefault("name")) # get()不会添加键值对 ,setdefault会添加
print(dic.setdefault("height", "180cm"))
print(dic)
# (2)删除键值对 pop popitem
sex = dic.pop("sex") # male
print(sex) # male
print(dic) # {'name': 'yuan', 'age': 22}
dic.popitem() # 删除最后一个键值对
print(dic) # {'name': 'yuan'}
dic.clear() # 删除键值对
# (3) 添加或修改 update
add_dic = {"height": "180cm", "weight": "60kg"}
dic.update(add_dic)
print(dic) # {'name': 'yuan', 'age': 22, 'sex': 'male', 'height': '180cm', 'weight': '60kg'}
update_dic = {"age": 33, "height": "180cm", "weight": "60kg"}
dic.update(update_dic)
print(dic) # {'name': 'yuan', 'age': 33, 'sex': 'male', 'height': '180cm', 'weight': '60kg'}
# (4) 字典的循环
dic = {"name": "yuan", "age": 22, "sex": "male"}
# 遍历键值对方式1
# for key in dic: # 将每个键分别赋值给key
# print(key, dic.get(key))
# 遍历键值对方式2
# for i in dic.items(): # [('name', 'yuan'), ('age', 22), ('sex', 'male')]
# print(i[0],i[1])
# 关于变量补充
# x = (10, 20)
# print(x, type(x)) # (10, 20) <class 'tuple'>
# x, y = (10, 20)
# print(x, y)
for key, value in dic.items():
print(key, value)
|
6.3.4、字典的进阶使用
字典属于可变数据类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# 案例1
stu01 = {"name": "rain"}
stus = {1001: stu01}
print(stus)
stu01["name"] = "alvin"
print(stus)
print(id(stus[1001]))
stus[1001] = {"name": "eric"}
print(stu01)
print(id(stus[1001]))
# 案例2
students_dict= {}
scores_dict = {
"chinese": 100,
"math": 90,
"english": 50,
}
stu_dic = {
"name": "rain",
"scores": scores_dict
}
students_dict[1002] = stu_dic
print(students_dict)
scores_dict["math"] = 0
print(students_dict)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
# 案例1:列表存放字典
data = [
{"name": "rain", "age": 22},
{"name": "eric", "age": 32},
{"name": "alvin", "age": 24},
]
# 循环data,每行按着格式『姓名:rain,年龄:22』将每个学生的信息逐行打印
for stu_dic in data: # data是一个列表
# print(stu_dic) #
print("『姓名:%s,年龄:%s』" % (stu_dic.get("name"), stu_dic.get("age")))
# 将data中第二个学生的年龄查询出来
print(data[1].get("age"))
# 案例2:
data2 = {
1001: {"name": "rain", "age": 22},
1002: {"name": "eric", "age": 32},
1003: {"name": "alvin", "age": 24},
}
# 循环data2,每行按着格式『学号1001, 姓名:rain,年龄:22』将每个学生的信息逐行打印
for stu_id, stu_dic in data2.items():
# print(stu_id,stu_dic)
name = stu_dic.get("name")
age = stu_dic.get("age")
print("『学号: %s, 姓名 %s,年龄:%s』" % (stu_id, name, age))
# name = "yuan"
# age = 22
# sex = "male"
#
# print("『姓名:", name, "年龄:", age, "性别:", sex, "』")
# print("『姓名: %s 年龄: %s 性别: %s 』" % (name, age, sex))
# print("姓名:name")
|
6.3.5、字典生成式
同列表生成式一样,字典生成式是用来快速生成字典的。通过直接使用一句代码来指定要生成字典的条件及内容,替换了使用多行条件或者是多行循环代码的传统方式。
格式:
{字典内容+循环条件+判断条件}
1
2
3
|
stu = {"id": "1001", "name": "alvin", "age": 22, "score": 100, "weight": "50kg"}
stu = {k: v for k, v in stu.items() if k == "score" or k == "name"}
print(stu)
|
练习:将一个字典中的键值倒换
1
2
3
|
dic = {"1": 1001, "2": 1002, "3": 1003}
new_dic = {v: k for k, v in dic.items()}
print(new_dic)
|
练习:将所有的key值变为大写
1
|
print({k.upper():v for k,v in d.items()})
|
6.3.5、字典的hash存储
hash:百度百科
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
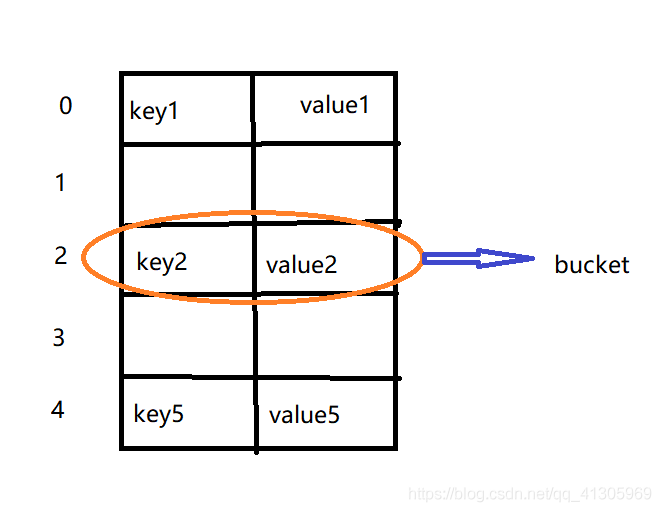
字典对象的核心其实是个散列表,而散列表是一个稀疏数组(不是每个位置都有值),每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用,由于,所有bucket结构和大小一致,我们可以通过偏移量来指定bucket的位置
![img]()
将一对键值放入字典的过程:
先定义一个字典,再写入值
1
2
|
d = {}
d["name"] = "yuan"
|
在执行第二行时,第一步就是计算"name"的散列值,python中可以用hash函数得到hash值,再将得到的值放入bin函数,返回int类型的二进制
1
|
print(bin(hash("name")))
|
结果为:
0b111111010001111101010011011000111110111101101110101100100101100
假设数组长度为10,我们取出计算出的散列值,最右边3位数作为偏移量,即100,十进制是数字4,我们查看偏移量为4对应的bucket的位置是否为空,如果为空,则将键值放进去,如果不为空,依次取右边3位作为偏移量101,十进制是数字5,再查看偏移量5的bucket是否为空,直到单元为空的bucket将键值放进去。以上就是字典的存储原理
当进行字典的查询时:
1
2
|
d["name"]
d.get("name")
|
第一步与存储一样,先计算键的散列值,取出后三位111,十进制为4的偏移量,找到对应的bucket的位置,查看是否为空,如果为空就返回None,不为空就获取键并计算键的散列值,计算后将刚计算的散列值与要查询的键的散列值比较,相同就返回对应bucket位置的value,不同就往前再取三位重新计算偏移量,依次取完后还是没有结果就返回None
参考文章
6.4、集合
Python 中的集合,和数学中的集合概念一样。由不同可hash的不重复的元素组成的集合。
6.4.1、声明集合
Python 集合会将所有元素放在一对大括号 {} 中,相邻元素之间用“,”分隔,如下所示:
1
|
{element1,element2,...}
|
其中,elementn 表示集合中的元素,个数没有限制。
从内容上看,同一集合中,只能存储不可变的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变的数据类型,否则 Python 解释器会抛出 TypeError 错误。
由于集合中的元素是无序的,因此无法向列表那样使用下标访问元素。Python 中,访问集合元素最常用的方法是使用循环结构,将集合中的数据逐一读取出来。
1
2
3
|
s = {"zhangsan",18,"male"}
for item in s:
print(item)
|
6.4.2、内置方法
1
2
|
a = {1,2,3}
b = {3,4,5}
|
| 方法 | 作用 | 示例 | 结果 |
|---|
add() |
向集合添加元素 |
a.add(4) |
{1, 2, 3, 4} |
update() |
向集合更新一个集合 |
a.update({3,4,5}) | {1, 2, 3, 4, 5}` | |
|
remove() |
删除集合中的元素 |
a.remove(2) |
{1, 3} |
discard() |
删除集合中的元素 |
a.discard(2) |
{1, 3} |
pop() |
随机删除集合一个元素 |
a.pop() |
{2,3} |
clear() |
清空集合 |
a.clear() |
{} |
intersection() |
返回两个集合的交集 |
a.intersection(b) |
{3} |
difference() |
返回两个集合的差集 |
a.difference(b)b.difference(a) |
{1,2}{4,5} |
symmetric_difference() |
返回两个集合的对称差集 |
a.symmetric_difference(b) |
{1, 2, 4, 5} |
union() |
返回两个集合的并集 |
a.union(b) |
{1, 2, 3, 4, 5} |
6.5、章节练习题
6.5.1、列表练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 1. l1 = [1, 2, 3, 4, 5]
# (1)在l1的元素3后面插入300
# (2)删除元素2
# (3)将5更改为500
# (4)将2,3,4切片出来
# (5)l1[-3:-5]的结果
# (6)l1[-3:]的结果
# 2. 通过input引导用户输入一个姓名,判断该姓名是否存在于列表names中
# names = ["yuan","eric","alvin","george"]
# 3. l = [1,2,3,[4,5]]
# (1)将4修改为400
# (2)在l的[4,5]列表中追加一个6,即使l变为[1,2,3,[4,5,6]]
# 4. 数一下字符串"天津 北京 上海 深圳 大连"中的城市个数
# 5. 将字符串"56,45,6,7,2,88,12,100"转换为按顺序显示的"2 6 7 12 45 56 88 100"
|
6.5.2、字典练习
学生成绩管理系统
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
# 确定数据以什么数据类型和格式进行存储
students_dict = {
1001: {
"name": "yuan",
"scores": {
"chinese": 100,
"math": 89,
"english": 100,
}
},
1002: {
"name": "rain",
"scores": {
"chinese": 100,
"math": 100,
"english": 100,
}
},
}
while 1:
print('''
1. 查看所有学生成绩
2. 添加一个学生成绩
3. 修改一个学生成绩
4. 删除一个学生成绩
5. 退出程序
''')
choice = input("请输入您的选择:")
if choice == "1":
# 查看所有学生信息
print("*" * 60)
for sid, stu_dic in students_dict.items():
# print(sid,stu_dic)
name = stu_dic.get("name")
chinese = stu_dic.get("scores").get("chinese")
math = stu_dic.get("scores").get("math")
english = stu_dic.get("scores").get("english")
print("学号:%4s 姓名:%4s 语文成绩:%4s 数学成绩%4s 英文成绩:%4s" % (sid, name, chinese, math, english))
print("*" * 60)
elif choice == "2":
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if int(sid) in students_dict: # 该学号已经存在!
print("该学号已经存在!")
else: # # 该学号不存在!
break
name = input("请输入学生姓名>>>")
chinese_score = input("请输入学生语文成绩>>>")
math_score = input("请输入学生数学成绩>>>")
english_score = input("请输入学生英语成绩>>>")
# 构建学生字典
scores_dict = {
"chinese": chinese_score,
"math": math_score,
"english": english_score,
}
stu_dic = {
"name": name,
"scores": scores_dict
}
print("stu_dic", stu_dic)
students_dict[int(sid)] = stu_dic
elif choice == "3":
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if int(sid) in students_dict: # 该学号已经存在!
break
else: # # 该学号不存在!
print("该修改学号不存在!")
chinese_score = input("请输入学生语文成绩>>>")
math_score = input("请输入学生数学成绩>>>")
english_score = input("请输入学生英语成绩>>>")
# 修改学生成绩
scores_dict = {
"chinese": chinese_score,
"math": math_score,
"english": english_score,
}
students_dict.get(int(sid)).update({"scores": scores_dict})
print("修改成功")
elif choice == "4":
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if int(sid) in students_dict: # 该学号已经存在!
break
else: # # 该学号不存在!
print("该修改学号不存在!")
students_dict.pop(int(sid))
print("删除成功")
elif choice == "5":
# 退出程序
break
else:
print("输入有误!")
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号