
面部不变性的挖掘
Abstract
在本文提出了一种基于子监督方式的人脸关键点挖掘的方法。传统方法绝大多数使用原始配对后的面部特征和关键点数据,并假设他们是均匀分布的,然而这个假设在现实世界是hold不住的,而且会导致在浪费了大量训练资源的情况下依然失败。为了解决这个问题,我们的模型实现了对于面部偏移的不变性学习,通过学习特征点锚定分布。具体来讲就是,我们从这些分布中生成面孔,然后根据外貌来源和面部关键点将他们分组为内部身份和内部关键点类。因此,我们构造类内不变性损失来从表象中分离空间结构。此外,我们采用了重建损失,以产生更真实的面孔与关键点。
Introduction
传统的人脸对齐方法将其描述为坐标回归或热图匹配问题,以从粗到细的方式细化面部形状。然而大多数模型会受到数据集的人为注释带来的偏差的影响,往往在被遮挡的面孔上会失败,因为他们的知识建立在不同的面部特征上。主要还是因为训练数据太少了,并且无法cover到显示生活中的各种各样的例子。为了解决这个问题,自监督架构被设计用来学习面部特征的潜在结构。在没有标注标签的情况下推断面部特征的一些工作大致分为两部分:基于视频的训练方法和基于等变变换的方法。
在没有标注标签的情况下推断面部特征点的工作大致分为两类:基于视频的训练方法和基于等变变换的方法。例如SBR追踪关键点的光流,它假设关键点在连续帧中。为了更好的利用像素级别的信息,其他基于视频的方法试图从表象中分离图像表征。虽然这两种方法在性能上取得一些进展,但是这种方法很大程度上依赖于一个初步的假设,即预测对象必须在视频中以稳定的运动形式显示出来。在最后一种方法中,
在该论文中,我们感兴趣的是利用可变形的面部标志的不变性。
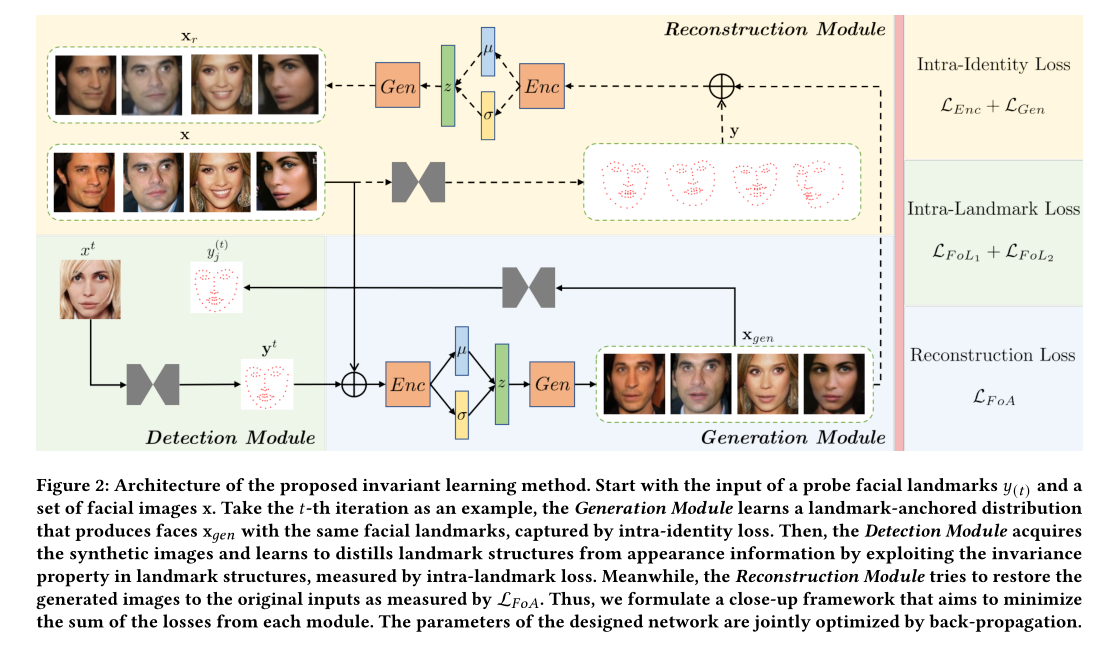
图2的体系结构由生成模块、检测模块和重构模块组成。其次,生成模块提取人脸的几何结构,利用关键点生成一个新的人脸去训练。最后面部关键点检测器获取的这些图像是锚定分布的,并且需要使检测到的关键点更接近真实关键点。最后,为了在没有人类注释的情况下实现更理想的合成结果,将重建模块设置为将原始姿势恢复到生成的人脸,因为我们注意到生成图像的质量至关重要。
相关工作
在这里我们分别简要的介绍了人脸对齐和人脸图像生成的相关工作。
使用DL进行人脸对齐:
人脸关键点挖掘:
脸部关键点图片生成
方法论
我们尝试了有监督和无监督的方法在人脸对齐上面的效果,并意识到学习机制本身依赖于人脸局部特征。然而以此种方法训练的模型必不可免的受到训练不足影响并且在具有挑战性的样本上表现不充分我们提出了一种解决该问题的方法,即在子监督方式下利用人脸关键点的空间结构中的不变信息。
下面会引入提出的方法和优化的目标在细节上。
提出的方法
\(\color{red}{可变的面部特征点结构信息的不变性依赖于不同的身份这一点 启示了我们如果外观不变的话,我们检测到的特征点也应该是不变的}\)换言之,我们的模型应该学习的是什么东西呢?应该学习的是关键点位置的潜在原因而不是脸部外貌。然而,我们在每一组数据集特征点中只能观察到一个面部(同landmark)特征样本,或者是极有限的。\(\color{green}{因为很少有相同的关键点集有不同的appearance\ identity}\)。为此,我们提出了一种新颖而合理的学习视角,利用可变型人脸标志的不变性。方法的体系结构在图2,其主要包含三个模块:1)一个编码网络和一个生成网络,作为生成模块的内容;2)一个沙漏形状的检测器作为关键点检测模块;3)一个预训练的VGG重建模块。Enc和Gen模块和CVAES的功能相同。在CVAE中除了K-L散度以外,我们不能对其输出做loss限制,并且由于潜变量分布的平滑性,合成结果会变得非常模糊。除此之外我们还将重建模块耦合到CVAE网络中,该网络对生成的人脸执行反转,以恢复其身份特征。因此,将重构的身份与输入身份进行比较会在SSL中添加第二个监督方程。因此,它进一步增强了合成图像的质量,然后关键点检测器对增强图像进行训练,以挖掘其不变性。我们将来自相同面部外观身份和面部特征带你的类分别定义为intra-identity和intra-landmarks。如下图3.这两类约束对关键点检测器的优化具有复合效应。让\(x=\{x^{(j)}\}^N_{j=1}\)表示原始数据集,\(y=\{y^{(j)}\}^M_{j=1}\)是由预训练的关键点检测器检测到的相应的关键点。然后将一组合成的人脸图像表示为\(x_t=\{x_t^{(j)}\}^M_{j=1}\),其中\(1\leq M \leq N\)。最后,\(x_{gen}=\{x_t\}^N_{t=1}\)代表从\(N\)组面部关键点中生成的数据。优化目标如下:
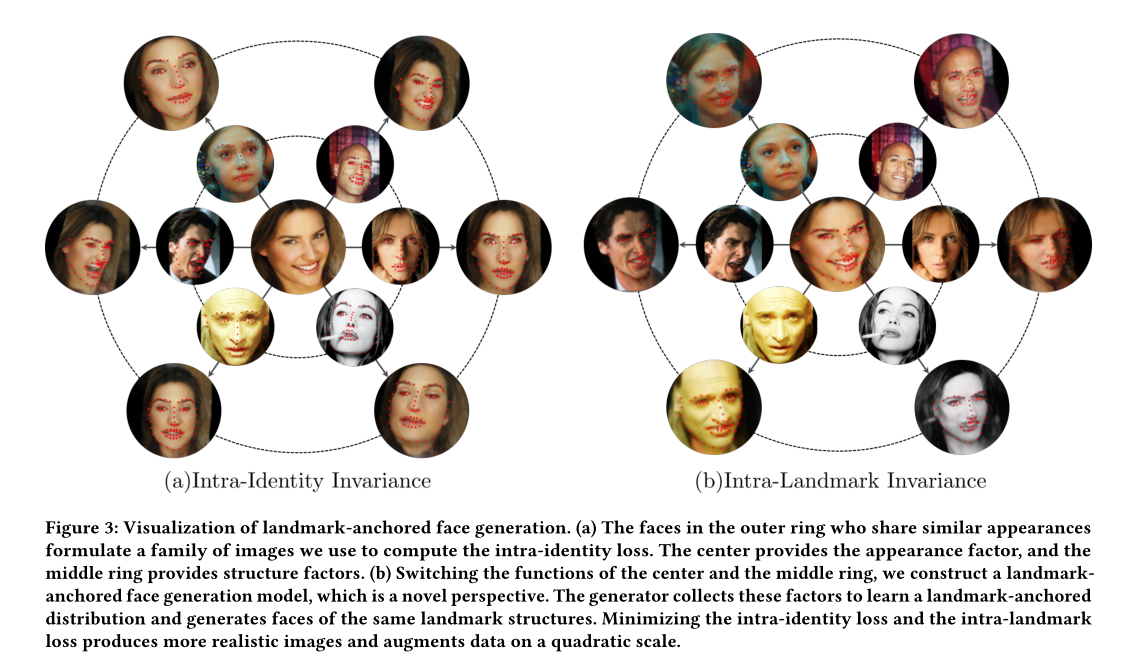
面部外观不变性损失
首先我们生成一系列的\(x_{gen}\),并且他们每个\(x_t\)都有不同的FAI,并且特征点是相同的\(y^{(t)}\)。其中\(x_t\)中第\(j\)个样本\(x_t^{(j)}\)的FAI由\(x\)中的\(x^{(j)}\)提供。
更具体地说,如图2所示,enc通过由\(\phi\)参数化的学习分布\(q_{\phi}(z|x,y)\)将输入x映射到以\(y\)为条件的潜在表示\(z\),而gen将x的外观与关键点\(y^{(t)}\)进行合成生成一个增强的训练数据\(x_{gen}\)。然后采用K-L散度去缩小先验分布和建议分布之间的差距。
关键点不变性损失
以前的面部特征点检测工作主要依赖于局部外观特征去定位特征点\,它很容易可以被指出一个误区就是,忽略了因果理论中提出的一个基本问题。即如果没有观察到外观识别物,面部特征点是依然存在的
\(\color{red}{意思是对于那些遮挡之类的有奇效?}\)。
换言之就是,我们可能只是碰巧观察到了相互纠缠的因素,
[========]
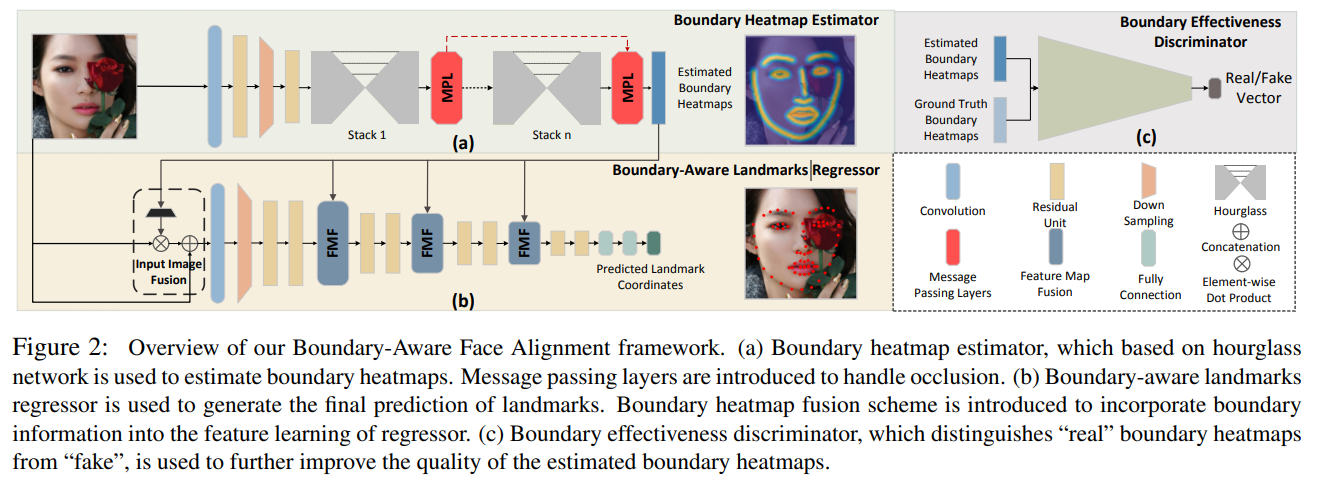
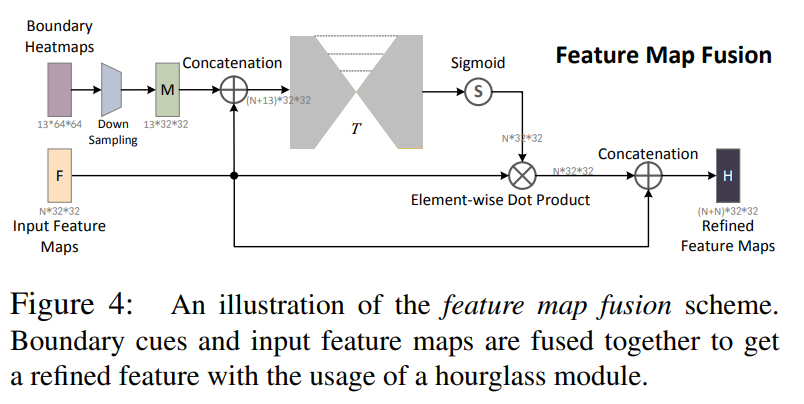
作者之所以提出利用Facial Boundary Heatmap是因为,任何人脸关键点数据集都可以转换到统一的一个数据格式(即Facial Boundary Heatmap),而且通过FBH可以预测任意个数的人脸关键点,还能解决人脸关键点检测中所存在的遮挡、旋转问题。
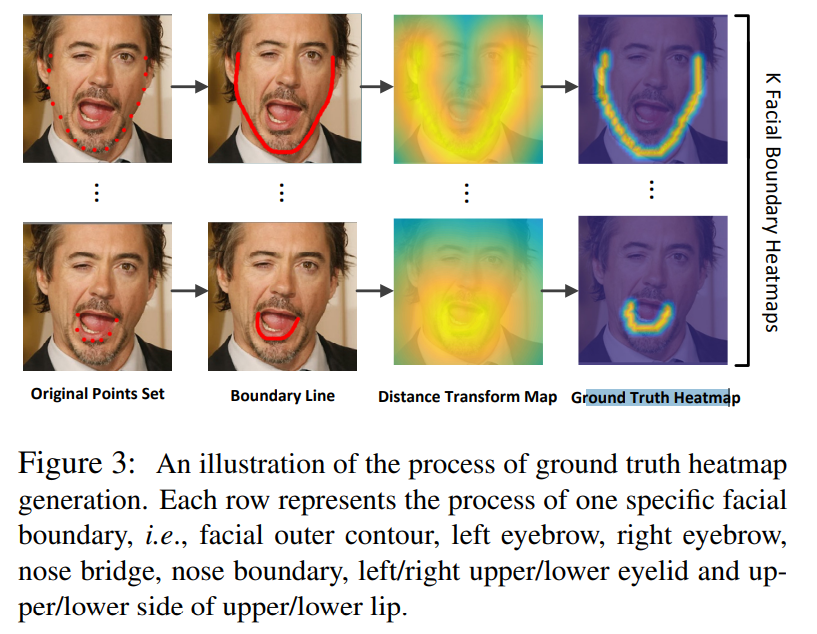
- 由常见的人脸关键点数据生成
Boundary Heatmap。 - 将人脸关键点按照所属
BH进行划分,通过插值的方式生成相应的Boundary Line - 计算图中各点到
Boundary Line的距离以此构造Distance Transform Map - 最后通过高斯分布得到
Ground Truth Heatmap
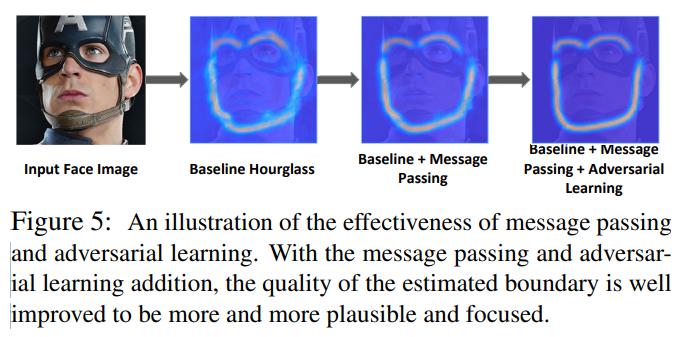
接着在预测Boundary Heatmap的过程中,作者引入了Stacked Hourglass Network和Message Passing。其中Message Passing 分为 Intra-level message passing (即同层中各个 Boundary 相互传递信息) 和 Inter-level message passing(即相邻两层中对应 Boundary 相互传递信息)。
最后,作者为了提高所预测的Boundary Heatmap的质量,便引入Adversarial Learning的思想进行对抗学习,即设计了Boundary Effectiveness Discriminator。
在预测人脸关键点的过程中,作者将所预测的Boundary Heatmap与Orininal Image融合作为输入

 浙公网安备 33010602011771号
浙公网安备 33010602011771号