PointNet++
Abstract
PointNet不能捕捉到度量空间(欧式和非欧但是只要有度量PointNet都可以用)点所产生的几何结构,从而限制了它识别细粒度模式的能力和对复杂场景的通用性。在这项工作当中,我们引入了一个分层神经网络,递归的将PointNet应用于输入点集的嵌套划分。通过利用度量空间距离,我们的网络可以在不断增加的上下文范围内学习局部特征。进一步的观察可以发现点集通常在不同的密度上进行采样,这导致在均匀密度上训练的网络性能大大降低,我们提出了新的set learning layers去自适应的组合来自多个尺度的特征。
- 分层神经网络
- 自适应采样以应对不同密度的点集
Introduction
我们感兴趣的是分析几何点集,它是欧几里德空间中点的集合。一种特别重要的几何点集类型是3D扫描仪获得的点云。作为一个集合,这样的数据必须对其成员的排列保持不变。此外,度量距离定义可能显示不同属性的局部邻域。例如,点的密度和其他属性在不同位置可能不一致---在3D扫描中,密度变化可能来自透视效果,运动等。
PointNet的基本思想是学习每个点的空间编码特征,然后将所有独立的点特征聚合到一个全局点云特征中。这样的设计导致PointNet不会捕获由度量带来的局部结构。然而局部结构已经被证明是卷积结构成功地重要因素。CNN把规则网络上的数据作为输入,能够在kernel size的结构上以越来越大的视野以逐步获取特征。Level低的时候,神经元的感受野较小,水平较高的时候,神经元的感受野较大。
我们引入了一个分层神经网络,named PointNet++,它以层次的方式处理度量空间中的一组采样点。PointNet++的思想很简单,首先我们将点集根据度量距离将其划分为重叠的局部区域。和CNN类似,我们先从小区域中提取局部特征,捕捉精细的几何结构;这些局部特征被进一步分组为更大的单元,并进行处理以生成更高级别的特征。重复这个过程直到获得整个点集的特征。
- 我们先从小区域中提取局部特征,捕捉精细的几何结构
- 局部特征被进一步分组为更大的单元,并进行处理以生成更高级别的特征
- 重复这个过程直到获得整个点集的特征
PointNet++必须解决两个问题:1、如何生成点集的分区;2、如何通过局部特征学习器提取点集或者是局部特征;这两个问题是相互关联的,因为点集的划分必须产生跨区域的公共结构,因此局部特征学习器的权重可以被共享,就像在卷积设置里一样。此处我们使用PointNet作为局部特征学习器。
仍然存在的一个问题是如何生成点集的重叠分区。每个分区都被定义为欧式空间的一个邻域的球,他的参数包含球心和半径。为了均匀的覆盖整个集合,通过最远点采样算法在输入点集中选择质心。以与固定步幅扫描空间的体积体素CNN相比,我们的感受野也依赖于输入数据和度量,因此更高效。
然而由于特征尺度的纠缠性和输入点集的非均匀性,确定合适的局部邻域球的尺度大小是一个更具有挑战性的问题。我们假设输入点集可能在不同的区域有不同的密度,这一点是很常见的,因此,我们的输入点集和CNN是很不相同的,CNN输入可以被视为在均匀恒定密度的规则网格上定义的数据。在CNN中,使用较小的kernel是一件很好的事情,但是在这里,由于采样的不足,小的邻域由更少的点组成,这可能不足以允许PointNet capture patterns robustly
- 可识别非刚性物体
- 和
CNN的kernel越小越好不同,由于点云的不均匀可能会导致,Feature extractor容易收到稀疏点云不稳定的影响。
Problem Statement
假设\(\mathcal{X}=(M,d)\)是一个离散的度量空间,其中的度量继承自欧几里德空间\(\mathbb{R}^n\),这里\(M\subseteq \mathbb{R}^n\)是点集,\(d\)是距离度量。此外,欧几里得空间中的\(M\)地密度可能并非处于均匀状态。
我们感兴趣的是学习集合函数\(f\),它将\(\mathcal{X}\)作为输入(和每个点的附加特征),并且生成我们感兴趣的语义信息。这样的\(f\)可以使将整体\(\mathcal{X}\)分配标签的分类函数,也可以是对其中每个点进行分类的分割函数。
Method
我们的工作可以看作为是PointNet的扩展,它增加了层次结构。
Review of PointNet : A Universal Continuous Set Function Approximator
给定一个无序的点集\(\{x_1,x_2,\dots,x_n\}\),可以定义一个集合函数\(f:\mathcal{X}\rightarrow\mathbb{R}\),他将一组点映射到一个向量:
此处的\(gamma\)和\(h\)一般用的都是MLP。
PointNet架构虽然非常的强,但是它在不同尺度上缺少捕获局部上下文的能力,此处会引入一个分层特征学习框架解决这个问题。
Hierarchical Point Set Feature Learning
PointNet++的层次结构由许多抽象层次组成。
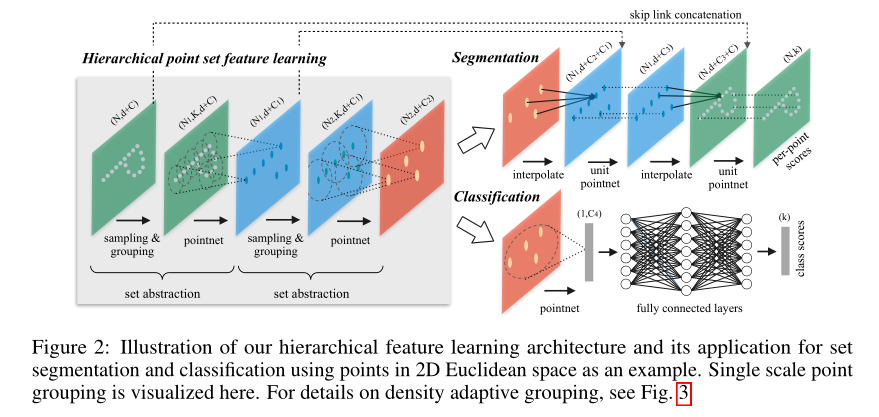
在每个层次上,对一组点进行处理和抽象产生一个新的更少元素的集合。集合抽样层由三个关键层组成:Sampling layer,Grouping layer,PointNet layer。
Sampling layer:从输入点中选择一组点(FPS),将其定义为局部区域的中心点。
Grouping layer:根据Sampling layer的中心点查找周围相邻的点去构造一个局部邻域集合。
PointNet layer:使用一个小的PointNet将Grouping layer区域编码为特征向量。
一个集合抽象层以\(N\times(d+C)\)的矩阵作为输入,其中的\(N\)是\(N\)个点,每个点有\(d\)维的坐标,和\(C\)维度的特征向量。他的输出是\(N'\times(d+C')\)的矩阵,\(N'\)是二次采样的点的个数,\(d\)是空间的维数,和之前的\(d\)是一样的,以及刚才区域的特征向量\(C'\)。
Sampling layer. 给输入点集\(\{x_1,x_2,\dots,x_n\}\),我们使用最远点采样算法来选择一个子集\(\{x_{i_1},x_{i_2},\dots,x_{i_m}\}\),该抽样算法和随机抽样相比,对于整个点集具有更好的覆盖率。和CNN的扫描不可知分布的向量空间,我们的采样策略以依赖数据的方式生成感受野。
Grouping layer. 该层的输入是一个大小为\(N\times(d+C)\)的点集,和一组大小为\(N'\times d\)。输出是大小为\(N'\times K\times (d+C)\),其中每一个分组\(N'\)对应一个局部区域,\(K\)是中心点相邻点的个数。需要注意的是这个参数\(K\)在不同的layer是可以变化的,但是后续的PointNet层能够将可变的点数量转化为固定长度的局部特征描述特征向量。
在卷积神经网络当中,像素的局部邻域有带由索引的像素数组组成,其大小为曼达顿距离(kernel size)。从度量空间采样的点集中,点的邻域由度量距离定义(也就是欧氏距离)。
ball query以所给点为中心,radius为半径做球,其内的所有点都是查询到的点(在实现上加了一个其内点不能超过\(K\)的限制)。另一种查询方法是kNN,他可以找到固定数量的领域点。
\(\color{red}{和kNN相比,ball query查询保证了局部领域的固定大小,从而使局部区域特征在空间上更具有通用性,这是局部模式识别任务的首选。}\)
- 以第一层为例,输入应该包含\(N\times(d+C)\),也就是原始的点集,和采样之后的点集\(N'\times d\)。
PointNet layer. 在这一层中,输入为\(N'\)个local regions,大小为\(N'\times K\times(d+C)\)。输出中的每个局部区域有中心和对中心邻域进行编码提取特征。输出数据大小为\(N'\times(d+C')\)。
具体操作:局部区域中的点的坐标,首先以中心点转化为局部坐标,\(x_i^{(j)}=x_i^{(j)}-\hat{x}^{(j)}\),其中的\(i=1,2,\dots,K\)和\(j=1,2,\dots,d\),其中的\(\hat{x}\)是中心点坐标。通过使用相对坐标和点特征,我们可以捕获局部区域中点和点之间的关系。
Robust Feature Learning under Non-Uniform Sampling Density
像之前讲的那样,点集在不同区域密度不均与这件事是非常常见的。这种非均匀性给点集特征学习带来这重大的挑战。在密集区域学习到特征可能无法generalize 带稀疏区域。因此,稀疏点云训练出来的模型可能不法识别细粒度的局部结构。
理想情况下,我们希望可以尽可能近的去检查一个点集,以获得在密集区域中的最佳细节信息。然而这种操作在低密度区域是行不通的,因为取样的不足会破坏local patterns给总体带来负面的影响。在这种情况下,我们应该在更大的尺度下寻找更大的邻域,以降低本次local feature extractor受到低密度的影响。为了实现这个目标,我们提出了密度自适应PointNet Layer,当输入采样密度变化的时候,该层学习组合来自不同尺度区域的特征。我们称具有密度自适应PointNet层的分层网络为PointNet++。
在PointNet++中,每个抽象层提取多个尺度的local patterns并且根据local point densities智能的对这些特征进行组合。在对局部区域进行分组和结合不同尺度的特征方面,我们提出了两种类型的密度自适应层,如下所示:
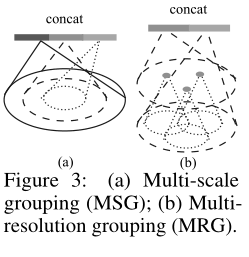
Multi-scale grouping (MSG). 如上图a所示,捕捉多尺度模式的一种简单但有效的方法是,应用具有不同尺度的分组层,然后根据PointNet提取每个尺度的特征,然后将不同比例的特征连接起来以形成多比例特征。
此处我们训练网络学习一种优化策略,以combine多尺度特征。这是通过对每个实例以随机概率随机删除输入点来实现的,我们称之为随机输入删除。具体来说,针对每个训练数据集,我们从均匀分布的\([0,p]\)中随机采样一个\(\theta\),其中\(p\leq 1\),这个\(\theta\)就是对于每个训练点集的随机丢弃比率。对于每一个点,我们丢弃它的概率为\(\theta\)。在实践过程中,为了防止\(p\)太小导致采样到的\(\theta\)过小的情况,从而导致随机丢弃几率太高,生成空集的情况。
在训练过程中,有着不同的稀疏性(\(\theta\)的大小不同)和不同的均匀性(丢弃点是随机的)训练集网络。\(\color{red}{更像一个数据增广}\)。在test中我们使用所有的可用点,不做dropout。
Multi-resolution grouping (MRG). :上面的多尺度方法计算开销很大,因为他在大规模邻域中以每个中心点为准去运行PointNet。特别的是,在较低level的时候中心点的数量非常多,因此时间的成本很大。
此处提出一种替代方案,避免了昂贵的计算开销,但仍然保留了根据点的分布特性自适应聚合信息的能力。在上图的(b)中,某一级别的\(L_i\)的区域特征是由两个特征向量串联起来的。图中左边的向量是由集合抽象级别从较低级别\(L_{i-1}\)汇总每个子区域的特征而获得的。另一个向量(右边),是由单个PointNet直接处理局部区域中所有点获得的。
当局部区域密度比较低的时候,上面的第一个向量的可靠性就不如第二个向量了。因为计算第一个向量的时候包含的点更为稀疏,并且特别容易受到采样不足的影响。在这种情况下,第二个向量的权重就应该更高。换言之,当点的密度很高的时候,第一个向量可以提供更加精确的局部细节信息,因为他在具有较低级别以较高分辨率递归检查的能力。
相比之下MRG的计算效率更高。
Point Feature Propagation for Set Segmentation
在几何抽象层,其中的“原始点”已经是被采样过得点了。然而在于一点标注等集合分割任务当中,我们需要获取所有原始点的点特征。一种解决方案是在所有几何抽象级别中始终将所有店作为质心进行采样,但是这样计算成本很高。另一种方法是将特征从子采样点传播到原始点。
此处我们采用基于距离的插值和跨级别跳过链接的分层传播策略\(\color{red}{实质上就是Hierarchical\ point\ set\ feature\ learning的逆操作,将之前被采样掉的点,一个个放上去并给予特征}\)。在特征传播级别,我们将特征点从\(N_{l}\)拓展到\(N_{l-1}\)其中(\(N_{l}\leq N_{l-1}\)),具体是利用其原有的点的特征矩阵\(\color{red}{也就是右边的红框框}\),\(N_l\times(d+C)\)。我们通过在\(N_{l-1}\)的坐标处通过skip link concatenation找到这次补上的点,并插入\(N_l\)的特征值,实现特征值传播。在众多的插值选择中,基于kNN的反向距离加权平均(如下式2,此处我们使用\(p=2,k=3\))。在使用下面公式进行插值完毕之后,使用PointNet对特征进行归一化。
Experiments
Datasets 此处使用了四个数据集进行评估,从2D对象数据集(MNIST),3D对象(ModelNet40,这种刚性物体),SHREC15这种非刚性对象,真实3D环境(ScanNet)
MNIST:60k训练集10k测试数据集的手写数字图像。ModelNet40: 40个类别的CAD模型(大部分是人造的),使用官方给我分割比例,9843用于训练,2468用于测试。SHREC15:来自50个类别的1200个形状,每个类别包含24个形状,这些形状大部分是具有各种姿势的有机形状。如马、猫等。此处使用五折交叉验证来获得精度。ScanNet:1513个扫描和重建的室内场景。此处使用1201个场景进行训练,312个场景进行测试。
Point Set Classification in Euclidean Metric Space
将MNIST转化为二维点云,ModelNet40为三维点云。默认情况下MNIST使用512个点,ModelNet40使用1024个点。在下面表2的最后一行,我们使用发现发现和5000个点作为额外的特征。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号