1.介绍
问题:完全监督训练网络有效,虽然数据集的收集不是问题,但是数据集的标注(定label)是一个比较繁琐的事情。
本文就利用知识蒸馏方法来解决在没有类标签的情况下,如何利用已经训练好的一个模态的网络信息,来训练另外一个模态的网络。
这篇论文主要是利用知识蒸馏的方法进行跨模态蒸馏,经过完全监督训练好的rgb动作识别网络作为 teacher网络,一个没有类标签的数据集(骨架数据集没有lable)骨架动作识别网络作为 student网络,
通过知识蒸馏,将teacher网络输出的动作识别类概率作为student网络的监督(包括动作识别类别,此类别的概率),训练student网络,得到了和在完全监督(骨架数据集有lable)下的准确率。
贡献:1.提出了一个跨模态动作识别网络,可以在没有标签的情况下,通过teacher网络来进行训练达到和完全监督下的效果
2.提出了一个student进行相互学习,使得student训练的时候不仅会学习teacher网络的信息,而且还会参考“同行”的信息,进一步提高了跨模态信息转换的程度
3.用了cross-entropy损失来代替之前teacher-student知识蒸馏网络中用的KL损失,提高了准确率
2.思想
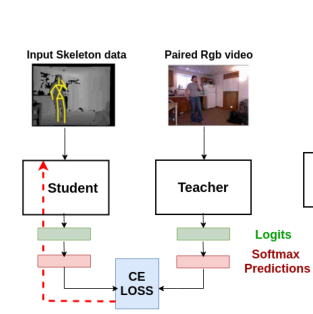
上图就是利用知识蒸馏网络来对student网络训练。
techer网络是一个已经训练好的rgb动作识别网络,student是一个没有训练的骨架动作识别网络
teacher网络输出的动作类别的概率作为student网络的label进行学习
利用一个损失函数(之前使用KL损失)来计算着两个损失,并对这个损失进行优化
2.1 损失函数优化
上图中之前的损失函数使用的是KL损失,
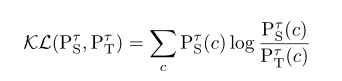
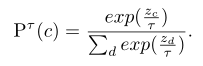
 表示student网络在T温度下的概率,
表示student网络在T温度下的概率,
 表示teacher网络在T温度下的概率,
表示teacher网络在T温度下的概率,
通过拟合这两个概率,使得student的概率和teacher的概率尽可能的相同,当student每个类别预测的概率和teahcer概率相同时,也就此时student网络也就学习到了相应的参数(神经元间权重等参数)可以预测骨架数据模态的动作识别了。
但是KL损失中的温度参数T,在不同模态数据的时候,T的选择十分的敏感,对不同的网络需要不通过的T,不易选择。
因此,作者提出了用cross-entropy损失来代替KL损失在teacher和studnet网络中的差异表示
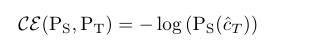

后续试验也表明了,使用cross-entropy损失效果更好。

2.2 student网络相互学习
student网络的学习不能只学习teacher的信息,还应该和“同行”交流,所以作者又提出了用多个student网络进行一起接收teacher网络的信息进行训练,然后每个studnet网络的时候又尽可能的学习“同行”的信息
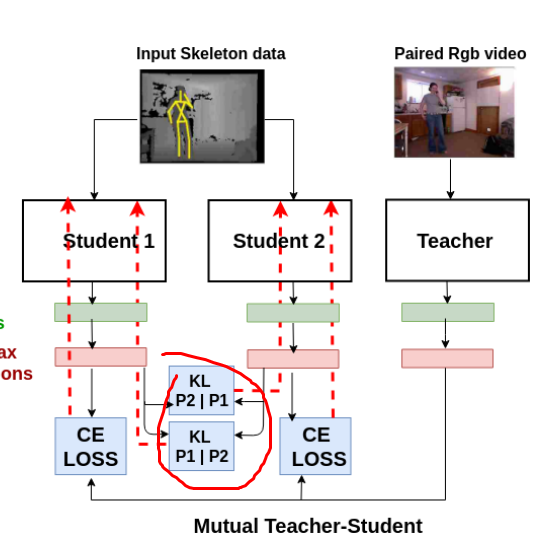
这里对于和“同行”的差异使用KL损失来度量,之所以可以用KL损失不用担心之前teacher-student网络的T参数问题是因为,studnet网络都是用于骨架数据的动作识别网络,而同一个模态经过试验发现,T参数不敏感,所以可以用KL损失
那么最后每个student网络的损失由两个部分构成:和其他student的差异+和teache网络的差异
若有两个student则为:

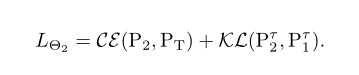
若有K个,则每个studnet的表达式为:
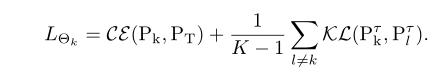
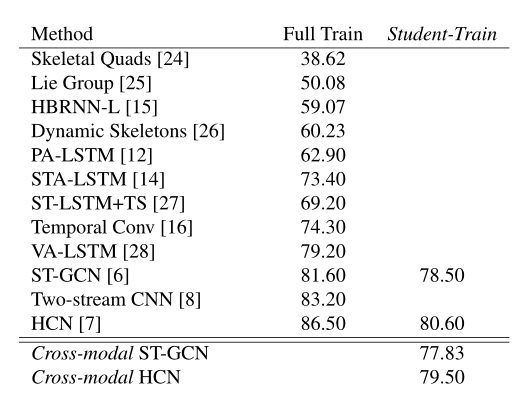
2.3实验
使用 TSN 作为teacher网络的结构,teacher网络的模态是rgb
使用 ST-GCN和 HCN 两个网路分别作为student网络结构来测试,模态是骨架数据
经过一系列实验发现,在student个数为2(k=2),使用cross-entropy作为teacher和studnet的损失,使用KL损失作为studnet和studnet的差异
效果如下:完全监督下ST_GCN准确率为78.5