
1.介绍
背景:以前的方法试图使用特征级约束同时减少外观和形态差异,但是仅仅依靠特征级的约束来处理跨模态数据是不够的。
创新:作者将跨模态差异(rgb和ir特征差异)和内模态差异(姿态、视角)分开处理。提出了 Dual-level Discrepancy Reduction Learning 框架。
在输入普通的跨模态re-id网络之前,作者对输入形式进行处理。先将rgb和ir图像特征映射到一个统一的空间。
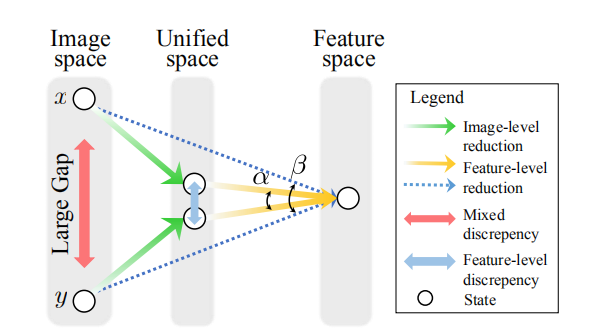
在统一图像表示的图像级模态约简后,图像的间隙比原图像空间的间隙小得多。 因此,后面的特征级re-id可以有效地减少剩余的外观差异
2.思想
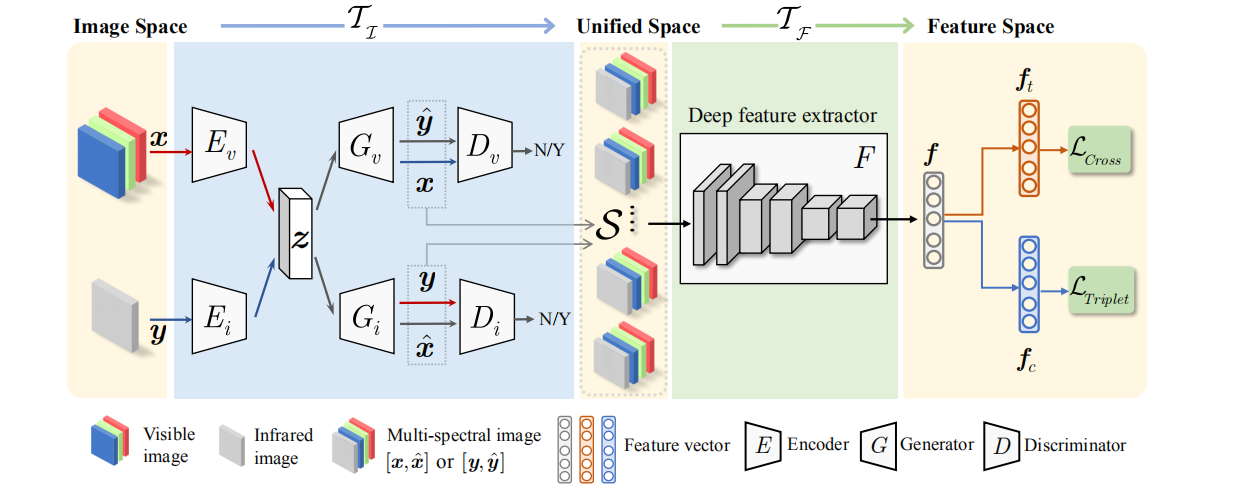
框架分为Image-level discrepancy reduction( TI)和Feature-level discrepancy reduction(TF)两个部分。
2.1 图像域分离
图像域:目前的理解是,对图片操作就是图像域。这里对rgb(ir)生成fake的ir(rgb)图片,最后得到一个四通道的图片。因为最后得到的是图片,所以是图像域的处理,而不是特征级处理
re-id网络主要都是一个目的,让同一行人不同模态下的特征变得更为相似。
既然是为了提高相似性,有一个非常简单明了的想法:
用rgb生成ir图像,同时ir图像也生成rgb图像
那么在提取rgb(或ir)图像的时候,可以首先把rgb(或ir)图像转换成ir(或rgb)图像
然后当提取rgb(或ir)图像特征的时候,就可以当成是单模态数据处理了
随后整体的框架就变成单模态下红外(RGB)的行人重识别
两个模态的数据统一成了一个模态下的数据,给人的感觉就已经很相似了(也就是有助于消除了模态间差异)
所以,基于这个思想。
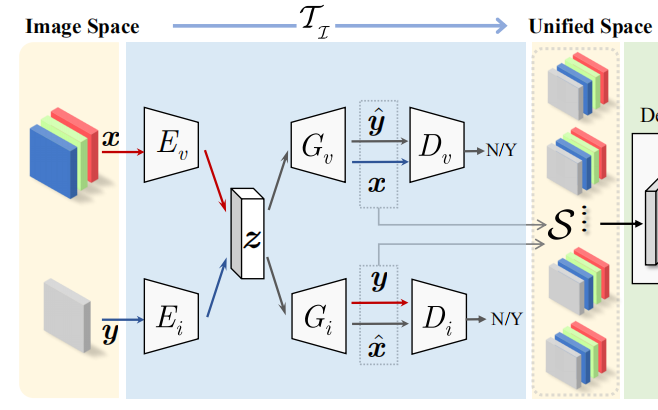
如图,作者先将rgb(ir)图像的信息通过编码器Ev(Ei)编码到一个统一空间,然后用生成器Gv(Gi)生成对应的fake(假的)ir(rgb)图片,和原来的rgb(ir)图片组成一个四通道数据(即生成多光谱图片)。
那么如何优化生成的fake图片? 用GAN思想,添加一个判别器Gv(Gi)来牵引学习生成更好的照片。(其实这是这么说不准确,因为最后的目的是为了学习到有利于后续re-id的fake图片,而不是说清晰度好的图片)
假设x为rgb输入,y为ir输入,x为x生成的fake的ir图片,y为y生成的fake的rgb图片
则经过Image-level discrepancy reduction结构的输出为【x,x】的四通道数据(或【y,y】四通道数据),
就是下图

其实在经过编码解码器后,生成了相应的fake图片,转换到一个统一空间可以是rgb统一空间,也可以是ir统一空间,那为什么最后是统一到rgb,ir统一空间呢?
对于这个问题,作者给出了两个理由,并且也设计实验分别测试了统一到rgb,ir,rgb和ir统一空间,计算了它们的性能,最后也确实是统一到rgb和ir空间更加有效。
第一,红外和可见光图像是由于不同的成像过程而对同一人的同一反射光的两种表示。 它们可能是相关的,它们很可能相互重建。
第二,如果将图像统一为可见光或红外模式,则可能会丢失可见光或红外模式中的一些独特信息
转换到统一空间查询图像和图库图像以相同的方式表示,大大减少了跨模态特征差异。
2.1.1 损失函数
2.1.1.1 VAE 损失
由于模态分离是对rgb和ir处理的,所以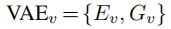 和
和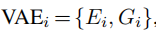 分别表示它们的VAE损失。
分别表示它们的VAE损失。
对rgb来说,
编码器Ev首先将x映射到潜在向量z,然后解码器Gv从潜在向量z重建输入。重建输出为
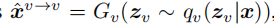
VAE损失为
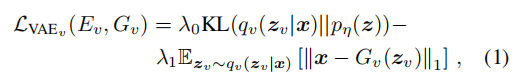
ir类似。
2.1.1.2 特定域图像生成损失
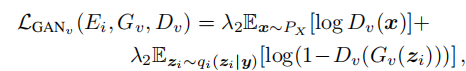
2.1.1.3循环一致性####
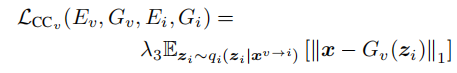
2.1.1.4 总损失
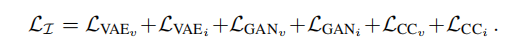
2.2 特征级分离
在通过了2.1图像域处理后后得到一个四通道的包含rgb和ir的图片,这样我们就可以用对单模态的方式来对这个四通道图片做分类了。
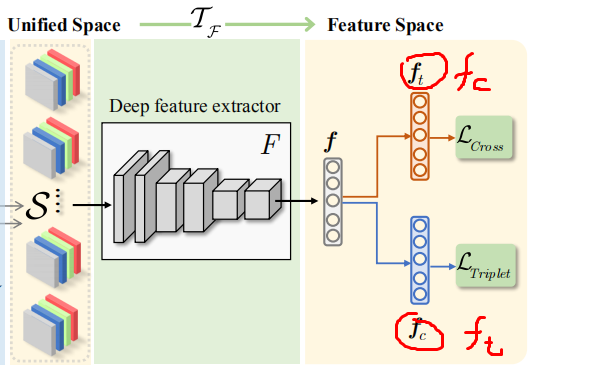
感觉它这个图ft和fc位置反了
利用一个特征提取器(resnet50等)提取特征,得到的特征输入两个FC层Ht和Hc。
其中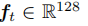 这个128暂时没懂是为什么
这个128暂时没懂是为什么
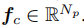 Np是personid的总数,即有多少种类别
Np是personid的总数,即有多少种类别
2.2.1 tripletloss
tripletloss用来学习身份id信息
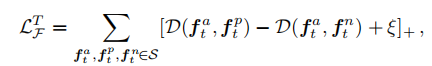
2.1.2 Cross-entropy loss
Cross-entropy loss用来相似性学习
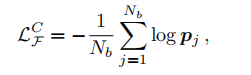
2.1.3 特征层总损失
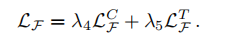
2.3 整个网络训练
整个网络通过级联训练,总的loss为
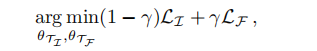
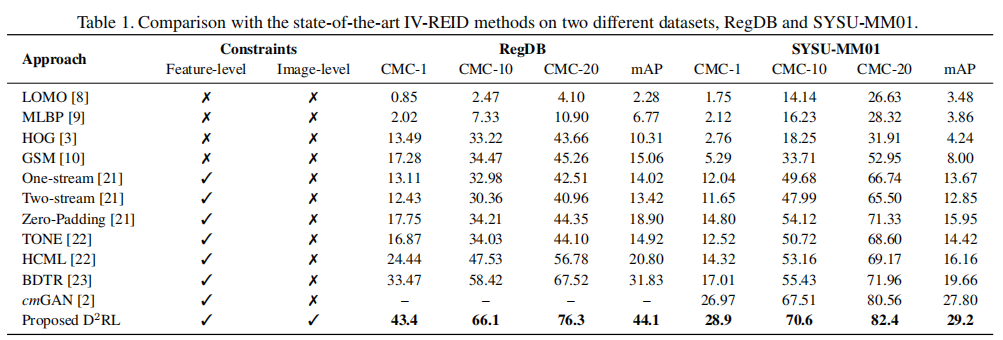
2.4 结果
消融实验看各个部件的重要性



 浙公网安备 33010602011771号
浙公网安备 33010602011771号