

1.介绍
本文的创新主要是在讲GAN首次运用在了跨模态的re-id,并取得了较好的效果。(若不知道GAN,建议先看一会GAN简介)
2.思想
在跨模态的re-id中主要有以下方面困难:
1.intra-modality:相同模态的图片由于姿态、光照的等原因,同一个人的同一个模态差异性很大,这个差异有的甚至会大于不同的人在不同模态的差异。
2.cross-modality:同一人的不同模态的图片,由于模态不同,特征分布不同,所以差异较大。
要做好跨模态re-id,其中一部分任务就是要减小intra-modality和cross-modality。
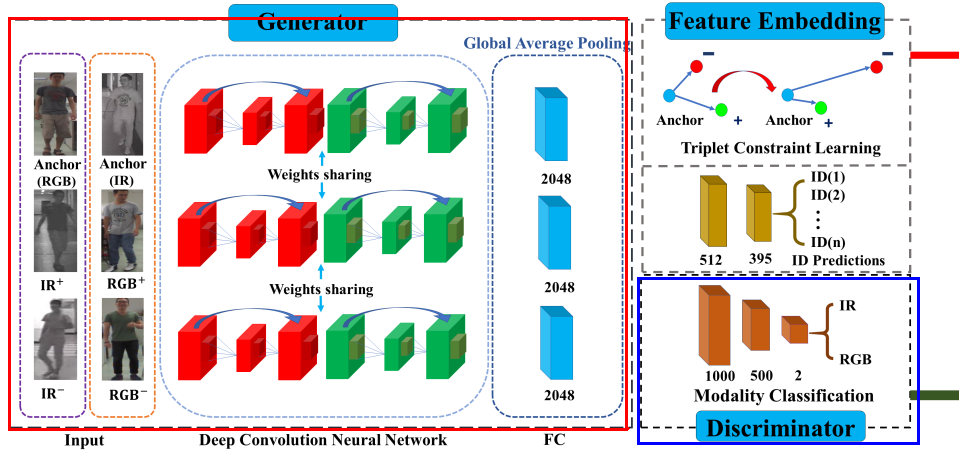
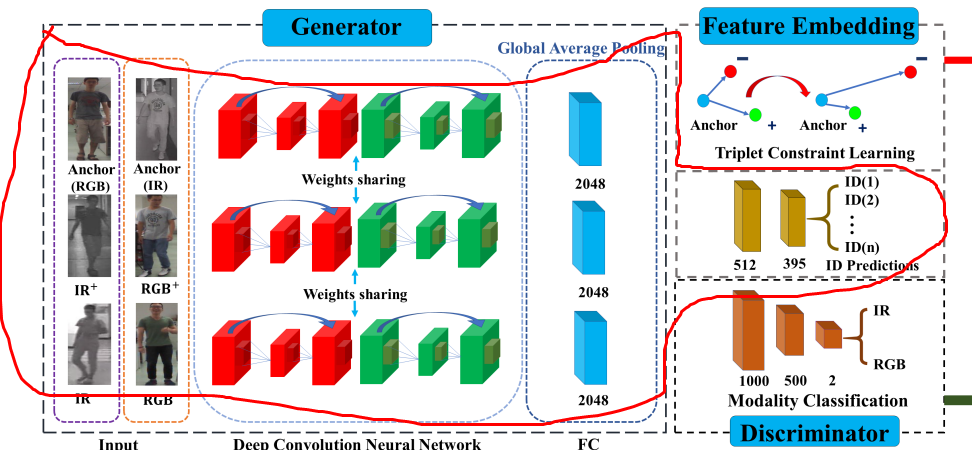
图中红框的是生成器,提取rgb和ir图片中的特征,篮筐是判别器
总的思路是:使用判别器对生成的特征进行训练,看特征是来自rgb还是ir模态。直到判别器无法判断来自rgb还是ir(即判别率为50%)。
此时再去训练生成器。
生成器:首先将rgb和ir图片输入特征提取器提取特征,利用identityloss和triplet loss优化提取的特征。
上面的判别->生成->判别 不断循环,直到得到一个比较好的identity loss
个人理解,其实就是寻找rgb和ir两个模态之间的共同可辨别特征

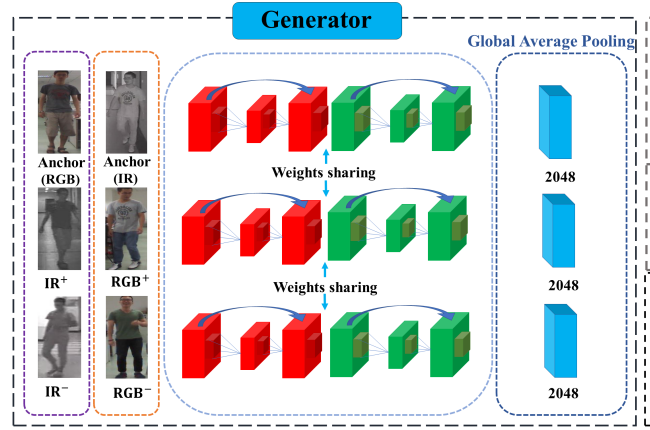
2.1 生成器
2.1.1 特征提取
将rgb和ir图片分为如下6类,即anchor_rgb, positive_rgb, negative_rgb, anchor_ir, positive_ir, negative_ir。
把这6类数据输入特征提取器(本文实验用的是resnet50),得到6个类别的特征anchor_rgb_features,positive_rgb_features,,negative_rgb_features,anchor_ir_features,positive_ir_features,negative_ir_features
也就是下图部分:
2.2 判别器
为了理解,这里先介绍判别器。
结构是什么?
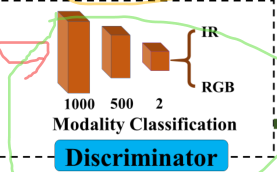
就是利用上面这个结构:三个全连接,1000->500->2
用来判断特征提取器(2.1.1部分)提取的特征来自rgb还是ir模态。
为什么要这么做呢?
个人理解,判别器的功能主要是为了 寻找特征提取器提取的特征是否是rgb和ir的公共特征,就是这个
那什么时候判别器算是达到目标呢?
当判别器无法判断这个特征是来自rgb还是ir的时候(正确率为50%左右)。也就是找到了。
2.3 模型的训练
GAN的思想是,
1.固定生成器不训练,让判别器先判别生成器生成的特征是来自rgb还是ir模态,直到判别器判别准确率很高
2.判别器能轻松判别后,固定判别器不训练,再去训练生成器,使得生成器生成的特征更加符合rgb和ir模态的公共特征。其实就是找下面这个
2.3.1 生成器的训练
但是如果只是这样的话(下图的红框和篮筐部分),得到的特征很可能只是rgb和ir模态的公共特征,这些特征无法对person id的分类起很大作用,因此除了用判别器对生成器进行"牵引"外,还需要其他的约束。
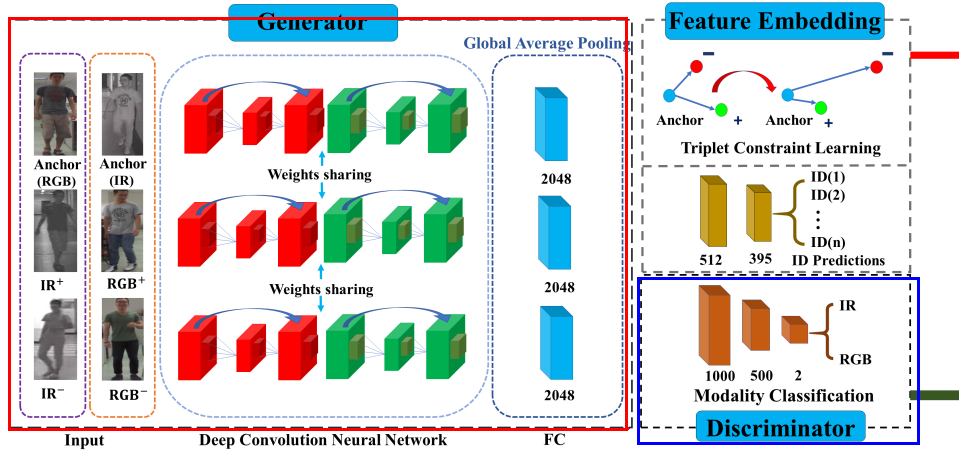
也就是:identity loss和triplet loss
利用这两个loss函数来使得特征提取器(2.1.1)提取的特征,具有id判别性。
其中:
identity loss是为了使特征具有id判别性
而triplet loss是将特征之间的距离,使得同一个人的(相同模态图片之间的距离和不同模态图片之间的距离)缩小,不同人的(相同模态图片之间的距离和不同模态图片之间的距离)加大
2.3.1.1 identity loss(行人id识别损失)####
为了使特征可以用于id判别,将所得特征(anchor_rgb_features,anchor_ir_features)两个特征输入三层全连接层(512->395->n)进行训练,通过这两个部分一起优化,得到更好的可鉴别的特征。
也就是下图的红色部分:
损失函数如下:
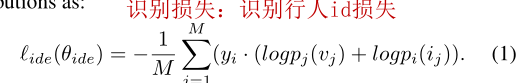
2.3.1.2 triplet loss
triplet loss 是用来将同一id人的不同模态距离和同一id人同一模态距离共同减小,算的是相对距离,使特征分离开易于切分。

那么因为有两个模态,需要对两个模态分别求triplet loss。则rgb和ir图片则对应两个tripletloss ,输入形式为(rgb,ir+,ir-),(ir,rgb+,rgb-),两者之和即为总的triplet loss
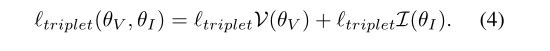
其实就是将特征提取器的特征放入triplet loss 函数中,优化这个函数,使得达到距离处理的效果。
2.3.1.3 生成器总损失
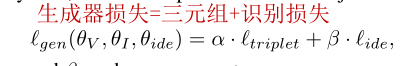
2.3.2 判别器训练
判别损失:
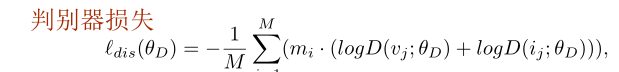
总的训练
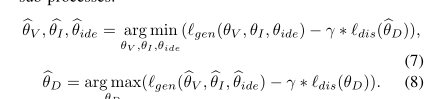

由于生成器和判别器收敛时间不一样,所以用一个k来调节生成器好判别器交替训练。
epoch=0,固定生成器,训练判别器
0<epoch<k,固定判别器,训练生成器


