论文中的一些具体函数的用法!!!
1.torch.spares_coo_tensor(indices, values, siez=None,*, dtype=None, requires_grad=False)->Tensor
- 此方法的意思是创建一个Coordinate(COO) 格式的稀疏矩阵,返回值也就h是一个tensor
- 稀疏矩阵指矩阵中的大多数元素的值都为0,由于其中非常多的元素都是0,使用常规方法进行存储非常的浪费空间,所以采用另外的方法存储稀疏矩阵。
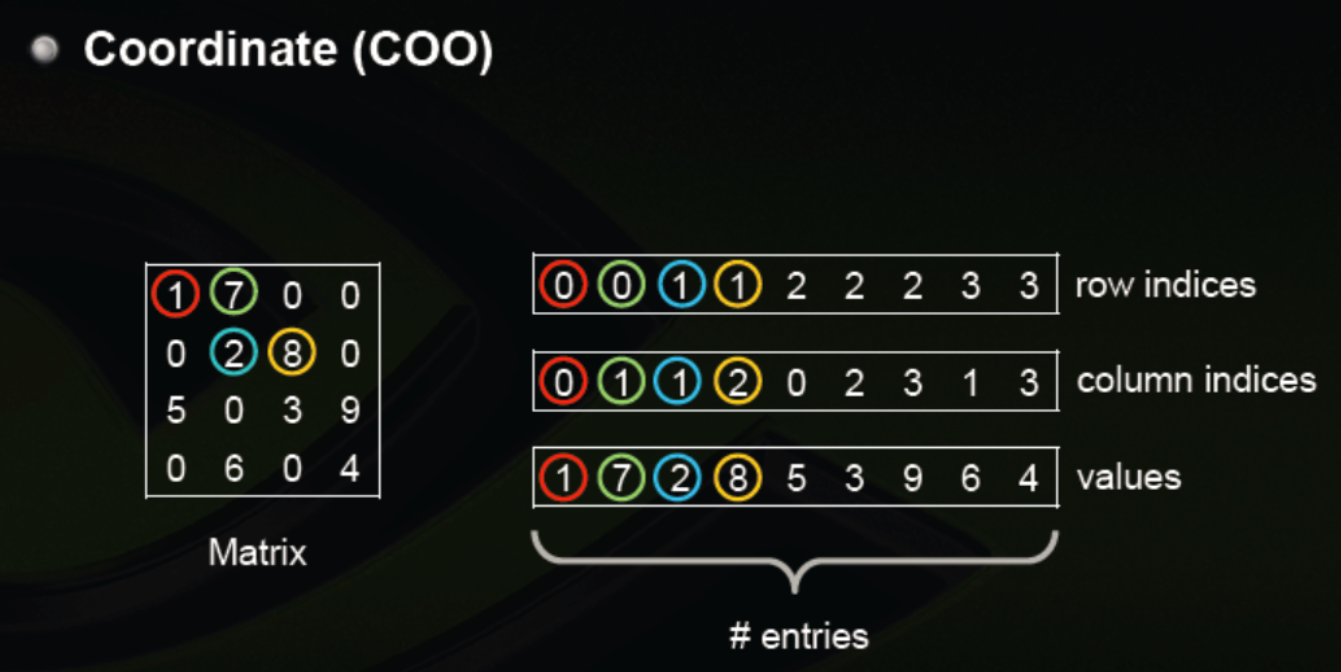
使用一个三元组来表示矩阵中的一个非0数,三元组分别表示元素(所在行,所在列,元素值),也就是上图中每一个竖的三元组就是表示了一个非零数,其余值都为0,这样就存储了一个稀疏矩阵。
indices:此参数是指定非零元素所在的位置,也就是行和列,所以此参数应该是一个二维的数组,当然它可以是很多格式(ist, tuple, NumPy ndarray, scalar, and other types. )第一维指定了所有非零数所在的行数,第二维指定了所有非零元素所在的列数。例如indices=[[1, 4, 6], [3, 6, 7]]表示我们稀疏矩阵中(1, 3),(4, 6), (6, 7)几个位置是非零的数所在的位置。
values:此参数指定了非零元素的值,所以此矩阵长度应该和上面的indices一样长也可以是很多格式(list, tuple, NumPy ndarray, scalar, and other types.)。例如``values=[1, 4, 5]表示上面的三个位置非零数分别为1, 4, 5。
size:指定了稀疏矩阵的大小,例如size=[10, 10]表示矩阵大小为10 × 10 10\times 1010×10,此大小最小应该足以覆盖上面非零元素所在的位置,如果不给定此值,那么默认是生成足以覆盖所有非零值的最小矩阵大小。
dtype:指定返回tensor中数据的类型,如果不指定,那么采取values中数据的类型。
device:指定创建的tensor在cpu还是cuda上。
requires_grad:指定创建的tensor需不需要梯度信息,默认为False
import torch t = torch.tensor(data=[2, 2], dtype=torch.float32, device=torch.device('cpu')) print(t) # 创建稀疏张量 # 指定坐标 i = torch.tensor([[0,1,2], [0,1,2]]) # 指定坐标上的值 v = torch.tensor([1,2,3]) a = torch.sparse_coo_tensor(indices=i, values=v, size=[5, 5]) print(a) # 稀疏转为稠密 a = torch.sparse_coo_tensor(indices=i, values=v, size=[5, 5], dtype=torch.float32).to_dense() print(a)
运行结果:

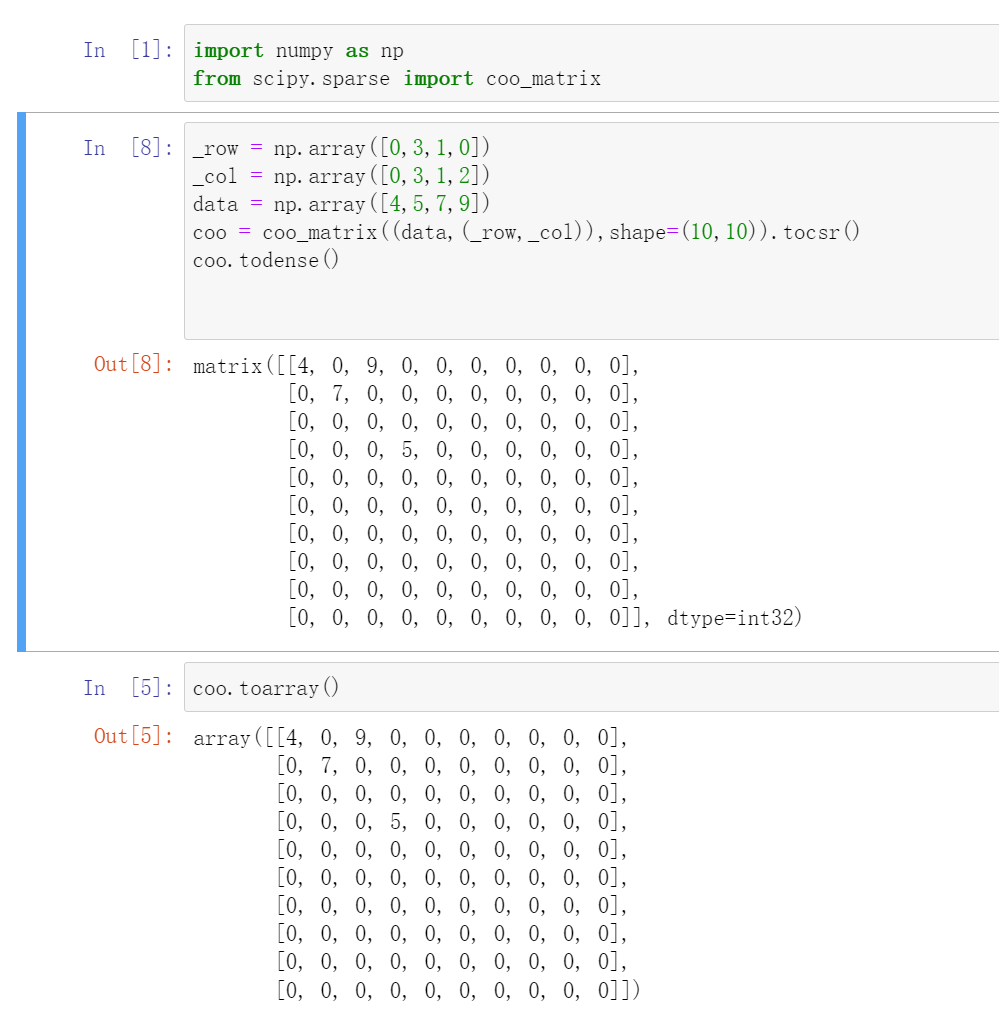
coo_matrix是最简单的稀疏矩阵存储方式,采用三元组(row, col, data)(或称为ijv format)的形式来存储矩阵中非零元素的信息。在实际使用中,一般coo_matrix用来创建矩阵,因为coo_matrix无法对矩阵的元素进行增删改操作;创建成功之后可以转化成其他格式的稀疏矩阵(如csr_matrix、csc_matrix)进行转置、矩阵乘法等操作。
2,stack()沿着一个新维度对输入张量序列进行连接。 序列中所有的张量都应该为相同形状
t1 = torch.Tensor([1,2,3]) t2 = torch.Tensor([2,4,6]) print(torch.stack((t1,t2),dim=0)) print(torch.stack((t1,t2),dim=1))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号