

2020年实习面试问题总结
1.spring、springMVC、springboot有什么区别?
Spring 一般代指Spring Framework,它是一个开源的应用程序框架,提供了一个简易的开发方式,让框架来帮你管理业务/工具对象,包括他的创建,销毁等,*比如Spring项目中的*Bean,它代表了Spring管辖的对象。Spring 的官方原则就是有好的解决方案的时候只需要通过Spring集成即可,而不需要自己再重复造一份(轮子)。Spring Freamework 使代码据有个更好的灵活性和扩展性。(可以集成Mybatis,hibernate等等)
什么是Spring MVC?
Spring MVC(Model view Control)是Spring的一部分,Spring出来以后,大家使用后觉得不错,就按照这种模式设计了一种MVC的框架,主要用于开发WEB应用和网络接口,他是Spring的一个模块,通过Dispatcher(转发器),Servlet(服务连接器),ModelandView(模型视图)和View Resolver(视图解析),让应用开发更加轻松,
什么是Spring Boot?
初期的Spring需要通过代码加配置的方式来为项目提供了良好的扩展性和灵活性,但是随着Spring越来越庞大,配置文件也越来越复杂,比如说首先通过配置文件来声明Dispatcher Servlet,然后通过配置文件来声明servlet的详情,如data source,bean等等若要添加其他功能,如security则需要添加相应的配置,最后增加代码,如controller,servicr,model等,最后生成war包,通过容器进行启动。这样看起来似乎过于复杂了,于是乎,Spring社区推出了Spring Boot,它的目的在于 实现自动配置,降低项目搭建的复杂度,*甚至不需要额外的WEB容器,直接生成jar包执行即可,spring-boot-dtarter-web模块中有一个内置的tomcat,可以直接提供容器使用,Spring Boot用默认的配置来代替spring的人工配置,同时 Spring Boot也是遵循*约定优于配置的原则。
简而言之,SpringBoot就是一个轻量级,简化配置和开发流程的web整合框架,我们可以说是因为SpringBoot才有了Spring这么火。
在Spring Boot中,所有的包都是starter的形式,Spring的官方解释如下:
Starters是一系列及其方便的依赖描述,通过在你的项目中包含这些starte,你可以一站式获得你所需要的服务,则无需像以往那样copy各种实例配置及代码,然后调试,真正做到开箱即用;比如你想用Spring JPA进行数据操作,只需要在你的项目依赖中引入spring-boot-starter-data-jps即可
那么SpringBoot和Spring有什么区别呢?
-
Spring Boot可以建立独立的Spring应用程序;
-
内嵌了如Tomcat,Jetty和Undertow这样的容器,也就是说可以直接跑起来,用不着再做部署工作了;
-
无需再像Spring那样搞一堆繁琐的xml文件的配置;
-
可以自动配置(核心)Spring。SpringBoot将原有的XML配置改为Java配置,将bean注入改为使用注解注入的方式(@Autowire),并将多个xml、properties配置浓缩在一个appliaction.yml配置文件中。
-
提供了一些现有的功能,如量度工具,表单数据验证以及一些外部配置这样的一些第三方功能;
-
整合常用依赖(开发库,例如spring-webmvc、jackson-json、validation-api和tomcat等),提供的POM可以简化Maven的配置。当我们引入核心依赖时,SpringBoot会自引入其他依赖。
2.什么是关系型数据库和非关系型数据库?
一 关系型数据库 有  我们只需要 记住常用的几个:mysql /oracle/sql server/sqlite 几个即可 我还有一篇文章 介绍了 关系型数据库和非关系型数据的数据结构 –红黑树-二叉树-B树
我们只需要 记住常用的几个:mysql /oracle/sql server/sqlite 几个即可 我还有一篇文章 介绍了 关系型数据库和非关系型数据的数据结构 –红黑树-二叉树-B树
1.首先了解一下 什么是关系型数据库? 关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组 织。 优点: 1、易于维护:都是使用表结构,格式一致; 2、使用方便:SQL语言通用,可用于复杂查询; 3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。 缺点: 1、读写性能比较差,尤其是海量数据的高效率读写; 2、固定的表结构,灵活度稍欠; 3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。用户通过查询来检索数据库中的数据,而查询是一个用于限定数据库中某些区域的执行代码。关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
二 非关系型数据库  我们只需要 记住常用的:redis / hbase /mongoDB /CouchDB /Neo4J 【注意:hive 不是数据库,是数据仓库 不是一个概念】
我们只需要 记住常用的:redis / hbase /mongoDB /CouchDB /Neo4J 【注意:hive 不是数据库,是数据仓库 不是一个概念】
什么非关系型数据库呢?
非关系型数据库严格上不是一加粗样式种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等
非关系型数据库,又被称为NoSQL(Not Only SQL ),意为不仅仅是SQL( Structured QueryLanguage,结构化查询语言),据维基百科介绍,NoSQL最早出现于1998 年,是由Carlo Storzzi最早开发的个轻量、开源、不兼容SQL 功能的关系型数据库,2009 年,在一次分布式开源数据库的讨论会上,再次提出了NoSQL 的概念,此时NoSQL主要是指非关系型、分布式、不提供ACID (数据库事务处理的四个基本要素)的数据库设计模式。同年,在亚特兰大举行的“NoSQL(east)”讨论会上,对NoSQL 最普遍的定义是“非关联型的”,强调Key-Value 存储和文档数据库的优点,而不是单纯地反对RDBMS,至此,NoSQL 开始正式出现在世人面前
不遵循ACID原则
使用范围:分布式数据库,近几年分布式数据库用的比较火的是redis
优点: 1、格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。 2、速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘; 3、高扩展性; 4、成本低:nosql数据库部署简单,基本都是开源软件。
缺点: 1、不提供sql支持,学习和使用成本较高; 2、无事务处理; 3、数据结构相对复杂,复杂查询方面稍欠。
非关系型数据库的分类和比较:
1、文档型 2、key-value型 3、列式数据库 4、图形数据库 

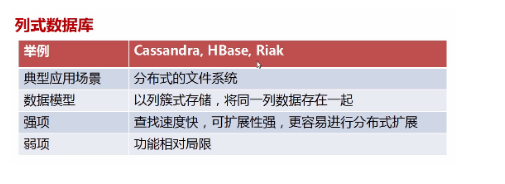
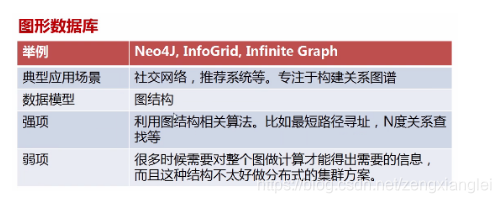
3.MVC是指什么?
优点:
缺点:没有明确的定义、不适合小型,中等规模的应用程序、增加系统结构和实现的复杂性、视图与控制器间的过于紧密的连接、视图对模型数据的低效率访问、一般高级的界面工具或构造器不支持模式
-
模型表示应用程序中处理业务数据和业务逻辑的部分,模型可以是一个单个对象,或是它也可以是由多个对象组成的某些结构。
-
视图是用于将信息展现给用户的一个模型的表示。它通常充当一个表现过滤器,只是将一个模型中包含的某些方面的数据展现出来,而隐藏另外一些数据。视图向模型请求,以获取需要表现的数据。它也可以通过发送相应的命令,来修改模型中的数据。这样的查询和命令,都必须在模型中由语义定义。
-
控制器充当用户和应用程序之间的连接,它安排视图在屏幕上显示,或者通过显示菜单,输入字段,按钮或其他的页面元素来读取用户输入。控制器先解释用户输入,然后将其传递给一个或多个视图。
4.数据库和数据仓库有什么区别?
数据仓库是面向分析的,数据库是面向事务处理. 数据仓库的数据是基本不变得,而数据库的数据是由日常的业务产生的,常更新 数据仓库的数据一般有数据库的数据经过一定的规则转换得到得 数据仓库主要用来分析数据,一般是tb级的的数据,比如决策支持系统,数据挖掘等.
数据库:传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
数据仓库:数据仓库系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
我尝试着再补充些具体的事例来说明,这样更可以帮助大家更好理解一些。
举个最常见的例子,拿电商行业来说好了。
基本每家电商公司都会经历,从只需要业务数据库到要数据仓库的阶段。
-
电商早期启动非常容易,入行门槛低。找个外包团队,做了一个可以下单的网页前端 + 几台服务器 + 一个MySQL,就能开门迎客了。这好比手工作坊时期。
-
第二阶段,流量来了,客户和订单都多起来了,普通查询已经有压力了,这个时候就需要升级架构变成多台服务器和多个业务数据库(量大+分库分表),这个阶段的业务数字和指标还可以勉强从业务数据库里查询。初步进入工业化。
-
第三个阶段,一般需要 3-5 年左右的时间,随着业务指数级的增长,数据量的会陡增,公司角色也开始多了起来,开始有了 CEO、CMO、CIO,大家需要面临的问题越来越复杂,越来越深入。高管们关心的问题,从最初非常粗放的:“昨天的收入是多少”、“上个月的 PV、UV 是多少”,逐渐演化到非常精细化和具体的用户的集群分析,特定用户在某种使用场景中,例如“20~30岁女性用户在过去五年的第一季度化妆品类商品的购买行为与公司进行的促销活动方案之间的关系”。
这类非常具体,且能够对公司决策起到关键性作用的问题,基本很难从业务数据库从调取出来。原因在于:
-
业务数据库中的数据结构是为了完成交易而设计的,不是为了而查询和分析的便利设计的。
-
业务数据库大多是读写优化的,即又要读(查看商品信息),也要写(产生订单,完成支付)。因此对于大量数据的读(查询指标,一般是复杂的只读类型查询)是支持不足的。
而怎么解决这个问题,此时我们就需要建立一个数据仓库了,公司也算开始进入信息化阶段了。数据仓库的作用在于:
-
数据结构为了分析和查询的便利;
-
只读优化的数据库,即不需要它写入速度多么快,只要做大量数据的复杂查询的速度足够快就行了。
那么在这里前一种业务数据库(读写都优化)的是业务性数据库,后一种是分析性数据库,即数据仓库。
最后总结一下:
数据库 比较流行的有:MySQL, Oracle, SqlServer等 数据仓库 比较流行的有:AWS Redshift, Greenplum, Hive等
这样把数据从业务性的数据库中提取、加工、导入分析性的数据库就是传统的 ETL 工作
5.MyBatis与MyBatisPlus区别?
Mybatis Plus
Mybatis-Plus是一个Mybatis的增强工具,只是在Mybatis的基础上做了增强却不做改变,MyBatis-Plus支持所有Mybatis原生的特性,所以引入Mybatis-Plus不会对现有的Mybatis构架产生任何影响。
Mybatis 和 Mybatis Plus 的区别
MyBatis:
-
所有SQL语句全部自己写
-
手动解析实体关系映射转换为MyBatis内部对象注入容器
-
不支持Lambda形式调用
Mybatis Plus:
-
强大的条件构造器,满足各类使用需求
-
内置的Mapper,通用的Service,少量配置即可实现单表大部分CRUD操作
-
支持Lambda形式调用
-
提供了基本的CRUD功能,连SQL语句都不需要编写
-
自动解析实体关系映射转换为MyBatis内部对象注入容器
MyBatis的优缺点
优点
-
MyBatis封装了JBDC底层访问数据库的细节,使我们程序猿不需要与JDBC API打交道,就可以访问数据库
-
MyBatis简单易学,程序猿直接编写SQL语句,适合于对SQL语句性能要求比较高的项目
-
SQL语句封装在配置文件中,便于统一管理与维护,降低了程序的耦合度
-
SQL代码从程序代码中彻底分离出来,可重用
-
提供了动态SQL标签,支持编写动态SQL
-
提供映射标签,支持对象与数据库的ORM字段关系映射 缺点
-
过于依赖数据库SQL语句,导致数据库移植性差,更换数据库,如果SQL语句有差异,SQL语句工作量大
-
由于xml里标签id必须唯一,导致DAO中方法不支持方法重载
MyBatis-Plus 优点
-
依赖少:仅仅依赖 Mybatis 以及 Mybatis-Spring 。
-
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作 。
-
预防Sql注入:内置 Sql 注入剥离器,有效预防Sql注入攻击 。
-
通用CRUD操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求 。
5、多种主键策略:支持多达4种主键策略(内含分布式唯一ID生成器),可自由配置,完美解决主键问题 。
-
支持热加载:Mapper 对应的 XML 支持热加载,对于简单的 CRUD 操作,甚至可以无 XML 启动
-
支持ActiveRecord:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可实现基本 CRUD 操作
-
支持代码生成:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码(生成自定义文件,避免开发重复代码),支持模板引擎、有超多自定义配置等。
-
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )。
-
支持关键词自动转义:支持数据库关键词(order、key…)自动转义,还可自定义关键词 。
-
内置分页插件:基于 Mybatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通List查询。
-
内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能有效解决慢查询 。
-
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,预防误操作。
-
默认将实体类的类名查找数据库中的表,使用@TableName(value=“table1”)注解指定表名,@TableId指定表主键,若字段与表中字段名保持一致可不加注解。
6.Java内存分配详解(堆内存、栈内存、常量池)
Java程序是运行在JVM(Java虚拟机)上的,因此Java的内存分配是在JVM中进行的,JVM是内存分配的基础和前提。Java程序的运行会涉及以下的内存区域: 1. 寄存器:JVM内部虚拟寄存器,存取速度非常快,程序不可控制。 2. 栈:存放基本类型的数据和对象的引用,但对象本身不存放在栈中,而是存放在堆中。 3. 堆:存放new出来的对象,注意创建出来的对象只包含各自的成员变量,不包括成员方法。 4. 常量池:存放常量,如基本类型的包装类(Integer、Short)和String,注意常量池位于堆中。 5. 代码段:用来存放从硬盘上读取的源程序代码。 6. 数据段:用来存放static修饰的静态成员。
下图表示了程序大致的内存分配情况: 










从以上的Java程序运行时内存的分配我们可以得出以下结论: 1. Java中有两种类型,分别是基本类型和引用类型。如果是基本类型则直接在栈中保存值,如果是引用类型,则真正new出来的对象会存放在堆内存中,栈内存中会保存指向该对象的引用,即对象在堆内存中的地址。 2. 栈中的数据和堆中的数据销毁并不是同步的。每个方法在执行时都会建立自己的栈区,方法一旦结束,栈中的局部变量立即销毁,但是堆中对象不一定销毁。因为可能有其他变量也指向了这个对象,直到栈中没有变量指向堆中的对象时,它才销毁,而且还不是马上销毁,要等垃圾回收才可以被销毁,这个是由JVM决定的。 3. 类中定义的实例成员变量在不同对象中各不相同,都有自己的存储空间(成员变量在堆中的对象中)。而类中定义的方法却是该类的所有对象共享的,只有一套,对象使用方法的时候方法才被压入栈,方法不使用则不占用内存。、
常量池
java中的常量池技术,是为了方便快捷地创建某些对象而出现的,当需要一个对象时,就可以从池中取一个出来(如果池中没有则创建一个),则在需要重复创建相等变量时节省了很多时间。常量池其实也就是一块内存空间,不同于使用new关键字创建的对象所在的堆空间。 java中的基本类型有:byte、short、char、int、long、boolean。其对应的包装类分别是:Byte、Short、Character、Integer、Long、Boolean。上边提到的这些包装类都实现了常量池技术,而两种浮点数类型的包装类则没有实现。另外,String类型也实现了常量池技术。
1. 基本类型和包装类
我们先来看一个例子:
public class Test {
public static void main(String[] args) {
int i = 40;
int i0 = 40;
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
Double d1 = 1.0;
Double d2 = 1.0;
// 在java中对于引用变量来说“==”就是判断这两个引用变量所引用的是不是同一个对象
System.out.println("i==i0\t" + (i == i0));
System.out.println("i1==i2\t" + (i1 == i2));
System.out.println("i1==i2+i3\t" + (i1 == i2 + i3));
System.out.println("i4==i5\t" + (i4 == i5));
System.out.println("i4==i5+i6\t" + (i4 == i5 + i6));
System.out.println("d1==d2\t" + (d1 == d2));
System.out.println();
}
}12345678910111213141516171819202122
输出结果如下: i==i0 true i1==i2 true i1==i2+i3 true i4==i5 false i4==i5+i6 true d1==d2 false
分析: 1. i和i0均是普通类型(int)的变量,所以数据直接存储在栈中,而栈有一个很重要的特性:栈中的数据可以共享。当我们定义了int i = 40;,再定义int i0 = 40;这时候会自动检查栈中是否有40这个数据,如果有,i0会直接指向i的40,不会再添加一个新的40。 2. i1和i2均是引用类型,在栈中存储对象地址,因为Integer是包装类。由于Integer包装类实现了常量池技术,因此i1、i2的40均是从常量池中获取的,均指向同一个地址,因此i1==12。 3. 很明显这是一个加法运算,Java的数学运算都是在栈中进行的,Java会自动对i1、i2进行拆箱操作转化成整型,因此i1在数值上等于i2+i3。 4. .i4和i5均是引用类型,在栈中存储地址,因为Integer是包装类。但是由于他们各自都是new出来的,因此不再从常量池寻找数据,而是从堆中各自new一个对象,然后各自保存指向对象的地址,所以i4和i5不相等,因为他们所存地址不同,所引用到的对象不同。 5. 这也是一个加法运算,和3同理。 6. d1和d2均是引用类型,在栈中存储对象地址,因为Double是包装类。但Double包装类没有实现常量池技术,因此Doubled1=1.0;相当于Double d1=new Double(1.0);,是从堆new一个对象,d2同理。因此d1和d2存放的地址不同,指向的对象不同,所以不相等。
注意:以上提到的几种基本类型包装类均实现了常量池技术,但他们维护的常量仅仅是【-128至127】这个范围内的常量,如果常量值超过这个范围,就会从堆中创建对象,不再从常量池中取。比如,把上边例子改成Integer i1 = 400; Integer i2 = 400;,很明显超过了127,无法从常量池获取常量,就要从堆中new新的Integer对象,这时i1和i2就不相等了。
2. String类型
对于字符串,其对象的引用都是存储在栈中的,如果是编译期已经创建好(直接用双引号定义的)的就存储在常量池中,如果是运行期(new出来的)才能确定的就存储在堆中。对于equals相等的字符串,在常量池中永远只有一份,在堆中有多份。 如以下代码:
String s1 = "china";
String s2 = "china";
String s3 = "china";
String ss1 = new String("china");
String ss2 = new String("china");
String ss3 = new String("china");
12345678

从这里可以看出,使用双引号直接定义的String对象会指向常量池中的同一个对象,通过new产生一个字符串(假设为“china”)时,会先去常量池中查找是否已经有了“china”对象,如果没有则在常量池中创建一个此字符串对象,然后堆中再创建一个常量池中此”china”对象的拷贝对象。
下面看两个关于String常量池的例子: String中有一个扩充常量池的intern()方法。当调用 intern 方法时,如果常量池中已经包含一个等于此 String 对象的字符串(该对象由 equals(Object) 方法确定),则返回常量池中的字符串引用。否则,将此 String 对象添加到池中,并且返回此 String 对象的引用。
public class Test {
public static void main(String[] args) {
String s0= "java";
String s1=new String("java");
String s2=new String("java");
String s3=new String("java");
s1.intern(); //intern返回的引用没有引用变量接收~ s1.intern();等于废代码.
s3=s3.intern(); //把常量池中“kvill”的引用赋给s2
System.out.println( s0==s1);//false s0引用指向常量池中对象,s1引用指向堆中对象
System.out.println( s1==s2);//false s1、s2引用分别指向堆中两个不同对象
System.out.println( s0==s1.intern() );//true
System.out.println( s0==s3 );//true s0、s3引用均指向常量池中对象
}
}1234567891011121314
public class Test {
public static void main(String[] args) {
//(1)
String a = "ab";
String bb = "b";
String b = "a" + bb;
System.out.println((a == b)); //result = false
//(2)
String a1 = "ab";
final String bb1 = "b";
String b1 = "a" + bb1;
System.out.println((a1 == b1)); //result = true
//(3)
String a2 = "ab";
final String bb2 = getBB();
String b2 = "a" + bb2;
System.out.println((a2 == b2)); //result = false
}
private static String getBB(){
return "b";
}
}123456789101112131415161718192021222324
分析:
-
JVM对于字符串引用,由于在字符串的”+”连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即”a” + bb无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给b。所以上面程序的结果也就为false。
-
(2)和(1)中唯一不同的是bb1字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的”a” + bb1和”a” + “b”效果是一样的。故上面程序的结果为true。
-
JVM对于字符串引用bb2,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和”a”来动态连接并分配地址为b2,故上面程序的结果为false。
-
