

汇编入门笔记
一、进制与运算符介绍:
1.进制
二进制:遇2进1,00000001--1,00000010-2
八进制:遇8进1,00000001,00000002,00000003,00000004,00000005,00000006,00000007,000000010-8,00000011-9,00000012-10
十进制:
十六进制:遇到f进1,00000001,00000002,00000003,00000004,00000005,00000006,00000007,00000008,00000009,0000000a-10,0000000b-11,0000000c-12,0000000d-13,
在js中可以表示那些进制:
var num = 10;//十进制
var num2 = 012;//八进制,以0开头
var num3 = 0x1a;//十六进制,以0x开头,1a是17,1f是31,f是15,1是十六进一了
2、运算符:
算数运算符:+ - * / % , num%3--10/3的余数,就是1
一元运算符:只需要一个操作数就能运算的符号。 ++ --
二元运算符:需要两个操作数就能运算的符号。+ - * / %
三元运算符:需要三个操作数就能运算的符号。
复合运算符: += -= *= /= %= 。num+=10, 就是num=num+10
关系运算符:> < >= <= ==不严格的, ===严格的相同类型, !=不严格的不等, !==严格的等
逻辑运算符:&&并且,|| 或者,! 非,取反
运算符优先级:()
一元运算符(++ --)
算数运算符(先* / % 后+ -)
关系运算符(> >= < <=)
相等运算符(== != ==== !==)
逻辑运算符(先&& 后||)
赋值运算符
3、一元运算符扩展:
var num = 10;
num++; 自身加1
++num; 自身加1;
var sum = num++ +10; sum=20 如果++在后面,先参与运算,自身再加1
var sum = ++num +10; sum=21 如果++在前面,先自身再加1,再参与运算
二、数据宽度
1.数据宽度:
数学上的数学,是没有大小限制的,可以无限的大。但在计算机中,计算机只认识0 和 1,由于受硬件的制约,数据都是有长度限制的(我们称为数据宽度),超过限制宽度部分的数据会被丢失。
2.计算机中常见的数据宽度:
位(Bit) 1 位
字节(Byte) 8 位
字(Word) 16 位
双字(Doubleword) 32 位
如果是二进制,那么一个格子能够存储一个 0 或 1。要是换成十六进制将四个格子四个格子组合在一起的话
可知 字节(Byte)的存储范围为 0 ~ 0xFF
字(Word)的存储范围为 0 ~ 0xFFFF
双字(Doubleword)的存储范围为 0 ~ 0xFFFFFFFF
如果要存储的数据超过最大宽度,那么多余的数据将被丢弃!
三、有无符号类型理解,及原,反,补码
1、你自已决定是否需要有正负。
就像我们必须决定某个量使用整数还是实数,使用多大的范围数一样,我们必须自已决定某个量是否需要正负。如果这个量不会有负值,那么我们可以定它为带正负的类型。
在计算机中,可以区分正负的类型,称为有符类型(signed),无正负的类型(只有正值),称为无符类型。 (unsigned)数值类型分为整型或实型,其中整型又分为无符类型或有符类型,而实型则只有符类型。 字符类型也分为有符和无符类型。 比如有两个量,年龄和库存,我们可以定前者为无符的字符类型,后者定为有符的整数类型。
2、使用二制数中的最高位表示正负。
首先得知道最高位是哪一位?1个字节的类型,如字符类型,最高位是第7位,2个字节的数,最高位是第15位,4个字节的数,最高位是第31位。不同长度的数值类型,其最高位也就不同,但总是最左边的那位(如下示意)。字符类型固定是1个字节,所以最高位总是第7位。
(红色为最高位)
单字节数: 11111111
双字节数: 11111111 11111111
四字节数: 11111111 11111111 11111111 11111111
当我们指定一个数量是无符号类型时,那么其最高位的1或0,和其它位一样,用来表示该数的大小。
当我们指定一个数量是无符号类型时,此时,最高数称为“符号位”。为1时,表示该数为负值,为0时表示为正值。
3、无符号数和有符号数的范围区别。
无符号数中,所有的位都用于直接表示该值的大小。有符号数中最高位用于表示正负,所以,当为正值时,该数的最大值就会变小。我们举一个字节的数值对比:
无符号数: 11111111 值:255
1* 27 + 1* 26 + 1* 25 + 1* 24 + 1* 23 + 1* 22 + 1* 21 + 1* 20
有符号数: 01111111 值:127
1* 26 + 1* 25 + 1* 24 + 1* 23 + 1* 22 + 1* 21 + 1* 20
同样是一个字节,无符号数的最大值是255,而有符号数的最大值是127。原因是有符号数中的最高位被挪去表示符号了。并且,我们知道,最高位的权值也是最高的(对于1字节数来说是2的7次方=128),所以仅仅少于一位,最大值一下子减半。
不过,有符号数的长处是它可以表示负数。因此,虽然它的在最大值缩水了,却在负值的方向出现了伸展。我们仍一个字节的数值对比:
无符号数: 0 ----------------- 255
有符号数: -128 --------- 0 ---------- 127
同样是一个字节,无符号的最小值是 0 ,而有符号数的最小值是-128。所以二者能表达的不同的数值的个数都一样是256个。只不过前者表达的是0到255这256个数,后者表达的是-128到+127这256个数。
一个有符号的数据类型的最小值是如何计算出来的呢?
有符号的数据类型的最大值的计算方法完全和无符号一样,只不过它少了一个最高位(见第3点)。但在负值范围内,数值的计算方法不能直接使用1* 26 + 1* 25 的公式进行转换。在计算机中,负数除为最高位为1以外,还采用补码形式进行表达。所以在计算其值前,需要对补码进行还原。 这里,先直观地看一眼补码的形式:
在10进制中:1 表示正1,而加上负号:-1 表示和1相对的负值。
那么,我们会很容易认为在2进制中(1个字节): 0000 0001 表示正1,则高位为1后:1000 0001应该表示-1。
然而,事实上计算机中的规定有些相反,请看下表:
| 二进制值(1字节) | 十进制值 |
|---|---|
| 10000000 | -128 |
| 10000001 | -127 |
| 10000010 | -126 |
| 10000011 | -125 |
| …… | …… |
| 11111110 | -2 |
| 11111111 | -1 |
首先我们看到,从-1到-128,其二进制的最高位都是1,正如我们前面的学。 负数最高为为1
然后我们有些奇怪地发现,1000 0000 并没有拿来表示 -0;而1000 0001也不是拿来直观地表示-1。事实上,-1 用1111 1111来表示。
怎么理解这个问题呢?先得问一句是-1大还是-128大?
当然是 -1 大。-1是最大的负整数。以此对应,计算机中无论是字符类型,或者是整数类型,也无论这个整数是几个字节。它都用全1来表示 -1。比如一个字节的数值中:1111 1111表示-1,那么,1111 1111 - 1 是什么呢?和现实中的计算结果完全一致。1111 1111 - 1 = 1111 1110,而1111 1110就是-2。这样一直减下去,当减到只剩最高位用于表示符号的1以外,其它低位全为0时,就是最小的负值了,在一字节中,最小的负值是1000 0000,也就是-128。
我们以-1为例,来看看不同字节数的整数中,如何表达-1这个数:
| 字节数 | 二进制值 | 十进制值 |
|---|---|---|
| 单字节数 | 11111111 | -1 |
| 双字节数 | 11111111 11111111 | -1 |
| 四字节数 | 11111111 11111111 11111111 11111111 | -1 |
可能有同学这时会混了:为什么 1111 1111 有时表示255,有时又表示-1?所以我再强调一下前面所说的第2点:你自已决定一个数是有符号还是无符号的。写程序时,指定一个量是有符号的,那么当这个量的二进制各位上都是1时,它表示的数就是-1;相反,如果事选声明这个量是无符号的,此时它表示的就是该量允许的最大值,对于一个字节的数来说,最大值就是255。
我们已经知道计算机中,所有数据最终都是使用二进制数表达。 也已经学会如何将一个10进制数如何转换为二进制数。 不过,我们仍然没有学习一个负数如何用二进制表达。 比如,假设有一 int 类型的数,值为5,那么,我们知道它在计算机中表示为:
00000000 00000000 00000000 00000101
5转换成二制是101,不过int类型的数占用4字节(32位),所以前面填了一堆0。 现在想知道,-5在计算机中如何表示? 在计算机中,负数以其正值的补码形式表达。
什么叫补码呢?这得从原码,反码说起。
原码:一个整数,按照绝对值大小转换成的二进制数,最高为为符号位,称为原码。 红色为符号位
比如 00000000 00000000 00000000 00000101 是 5的 原码。 10000000 00000000 00000000 00000101 是-5的原码
反码:将二进制除符号位数按位取反,所得的新二进制数称为原二进制数的反码。 正数的反码为原码,负数的反码是原码符号位外按位取反。 取反操作指:原为1,得0;原为0,得1。(1变0; 0变1)
正数:正数的反码与原码相同。
负数:负数的反码,符号位为“1”,数值部分按位取反。
比如:将10000000 00000000 00000000 00000101除符号位每一位取反,
得11111111 11111111 11111111 11111010。
称:11111111 11111111 11111111 11111010 是 10000000 00000000 00000000 00000101 的反码。
反码是相互的,所以也可称:
11111111 11111111 11111111 11111010 和 10000000 00000000 00000000 00000101 互为反码。
补码:反码加1称为补码。 正数:正数的补码和原码相同。
负数:按照规则来 也就是说,要得到一个数的补码,先得到反码,然后将反码加上1,所得数称为补码。
11111111 11111111 11111111 11111010 是 10000000 00000000 00000000 00000101(-5) 的反码。 加1得11111111 11111111 11111111 11111011
所以,-5 在计算机中表达为:11111111 11111111 11111111 11111011。转换为十六进制:0xFFFFFFFB。
再举一例,我们来看整数-1在计算机中如何表示。
假设这也是一个int类型,那么:
1、先取-1的原码: 10000000 00000000 00000000 00000001
2、除符号位取反得反码:11111111 11111111 11111111 11111110
3、加1得补码: 11111111 11111111 11111111 11111111
可见,-1在计算机里用二进制表达就是全1。16进制为:0xFFFFFF。
计算机中的带符号数用补码表示的优点:
1、负数的补码与对应正数的补码之间的转换可以用同一种方法——求补运算完成,可以简化硬件; 2、可将减法变为加法,省去减法器; 3、无符号数及带符号数的加法运算可以用同一电路完成。
可得出一种心算求补的方法——从最低位开始至找到的第一个1均不变,符号位不变,这之间的各位“求反”(该方法仅用于做题)。
| 方法 | 例1 | 例2 |
|---|---|---|
| 1. 从右边开始,找到第一个'1' | 10101001 | 10101100 |
| 2. 反转从这个'1'之后开始到最左边(不包括符号位)的所有位 | 11010111 | 11010100 |
四:位运算理解
一、简介
程序中的所有数在计算机内存中都是以二进制的形式储存的。位运算就是直接对整数在内存中的二进制位进行操作。比如,and运算本来是一个逻辑运算符,但整数与整数之间也可以进行and运算。举个例子,6的二进制是110,11的二进制是1011,那么6 and 11的结果就是2,它是二进制对应位进行逻辑运算的结果(0表示False,1表示True,空位都当0处理)。
二、运算规则
1、运算符
| 名称 | 符号 | 实例 | 规律 |
|---|---|---|---|
| 按位与 | a & b | 00101&11100(5&28) -> 00100(4) | 相同位的两个数字都为1,则为1;若有一个不为1,则为0 |
| 按位或 | a | b | 00101|11100(5|28) -> 11101(29) | 相同位只要一个为1即为1 |
| 按位异或 | a ^ b | 00101^11100(5^28) -> 11001(25) | 相同位不同则为1,相同则为0 |
| 按位取反 | ~a | ~00101->11010(-6) | |
| 左移 | a << b | 6<<2(00000110左移2位)->00011000(24) | 右边空出的位上补0,左边的位将从字头挤掉,其值相当于乘2的n次方 |
| 带符号右移 | a >> b | 6>>2(00000110右移2位)->00000001(1) | 右边的位被挤掉。对于左边移出的空位,如果是正数则空位补0,若为负数,可能补0或补1,这取决于所用的计算机系统 |
| 无符号右移 | a>>> b | 6>>>2->1和-6>>>2->1073741822 |
其中,-6用二进制是6的二进制取反再加1表示11111111111111111111111111111010,右移两位,就变成00111111111111111111111111111110,在用十进制表示就是1073741822。注:这里以32位整数来计算的,如果是64位,其运算结果是不一样(此处理解不是很透彻)。 二进制位数多少是根据处理器的位宽定义的,不同的处理器能处理的位数多少不一样。
2、复合运算符
| 运算符号 | 实例 | 相当于 |
|---|---|---|
| &= | a &= b | a = a&b |
| |= | a |= b | a = a|b |
| >>= | a >>= b | a = a>>b |
| <<= | a <<= b | a = a<<b |
| ^= | a ^= b | a = a^b |
三、应用
1、奇数还是偶数
boolean isEvenNumber(int x) {
return (x & 1) == 0;//偶数
}
boolean isOddNumber(int x) {
return (x & 1) == 1;//奇数
}
123456
2、整数的平均值
int average(int x, int y) {
return (x&y)+((x^y)>>1);//返回X,Y 的平均值
}
123
3、交换两个整数
void swap(int x , int y) {
x ^= y;
y ^= x;
x ^= y;
}
12345
4、计算绝对值
int abs( int x ) {
int y ;
y = x >> 31 ;
return (x^y)-y ;
}
12345
5、位运算实现加法
// 递归写法
int add(int x, int y){
if(y == 0)
return x;
int sum = x ^ y;
int carry = (x & y) << 1;
return add(sum, carry);
}
// 迭代写法
int add(int x, int y){
int sum = x ^ y;
int carry = (x & y) << 1;
while(carry != 0){
int a = sum;
int b = carry;
sum = a ^ b;
carry = (a & b) << 1;
}
return sum;
}
123456789101112131415161718192021
6、取模
int takeSurplus(int x, int y) {
return x & (y - 1);
}
//前提:y为2的n次方
1. 加法运算
先来个我们最熟悉的十进制的加法运算:
13 + 9 = 221
我们像这样来拆分这个运算过程:
不考虑进位,分别对各位数进行相加,结果为sum: 个位数3加上9为2;十位数1加上0为1; 最终结果为12;
只考虑进位,结果为carry: 3 + 9 有进位,进位的值为10;
如果步骤2所得进位结果carry不为0,对步骤1所得sum,步骤2所得carry重复步骤1、 2、3;如果carry为0则结束,最终结果为步骤1所得sum: 这里即是对sum = 12 和carry = 10重复以上三个步骤,(a) 不考虑进位,分别对各位数进行相加:sum = 22; (b) 只考虑进位: 上一步没有进位,所以carry = 0; (c) 步骤2carry = 0,结束,结果为sum = 22. 我们发现这三板斧行得通!
那我们现在还使用上面的三板斧把十进制运算放在二进制中看看是不是也行的通。
13的二进制为0000 1101,9的二进制为0000 1001:
不考虑进位,分别对各位数进行相加: sum = 0000 1101 + 0000 1001 = 0000 0100
考虑进位: 有两处进位,第0位和第3位,只考虑进位的结果为: carry = 0001 0010
步骤2carry == 0 ?,不为0,重复步骤1 、2 、3;为0则结束,结果为sum: 本例中, (a)不考虑进位sum = 0001 0110; (b)只考虑进位carry = 0; (c)carry == 0,结束,结果为sum = 0001 0110 转换成十进制刚好是22.
我们发现,适用于十进制的三板斧同样适用于二进制!仔细观察者三板斧,大家能不能发现其实第一步不考虑进位的加法其实就是异或运算;而第二部只考虑进位就是与运算并左移一位–;第三步就是重复前面两步操作直到第二步进位结果为0。
这里关于第三步多说一点。为什么要循环步骤1、 2、 3直到步骤2所得进位carry等于0?其实这是因为有的数做加法时会出现连续进位的情况,举例:3 + 9,我们来走一遍上述逻辑:
a = 0011, b = 1001;
start;
first loop;
1.1 sum = 1010
1.2 carry = 0010
1.3 carry != 0 , go on;
second loop;
2.1 sum = 1000;
2.2 carry = 0100;
2.3 carry != 0, go on;
third loop;
3.1 sum = 1100;
3.2 carry = 0000;
3.3 carry == 0, stop; result = sum;
end12345678910111213141516171819
如上面的例子,有的加法操作是有连续进位的情况的,所以这里要在第三步检测carry是不是为0,如果为0则表示没有进位了,第一步的sum即为最终的结果。
有了上面的分析,我们不难写出如下代码:
// 递归写法
int add(int num1, int num2){
if(num2 == 0)
return num1;
int sum = num1 ^ num2;
int carry = (num1 & num2) << 1;
return add(sum, carry);
}
// 迭代写法
int add(int num1, int num2){
int sum = num1 ^ num2;
int carry = (num1 & num2) << 1;
while(carry != 0){
int a = sum;
int b = carry;
sum = a ^ b;
carry = (a & b) << 1;
}
return sum;
}123456789101112131415161718192021
我们的计算机其实就是通过上述的位运算实现加法运算的(通过加法器,加法器就是使用上述的方法实现加法的),而程序语言中的+ - * /运算符只不过是呈现给程序员的操作工具,计算机底层实际操作的永远是形如0101的位,所以说位运算真的很重要!
2. 减法运算
我们知道了位运算实现加法运算,那减法运算就相对简单一些了。我们实现了加法运算,自然的,我们会想到把减法运算11 - 6变形为加法运算11 + (-6),即一个正数加上一个负数。是的,很聪明,其实我们的计算机也是这样操作的,那有的人会说为什么计算机不也像加法器一样实现一个减法器呢?对的,这样想当然是合理的,但是考虑到减法比加法来的复杂,实现起来比较困难。为什么呢?我们知道加法运算其实只有两个操作,加、 进位,而减法呢,减法会有借位操作,如果当前位不够减那就从高位借位来做减法,这里就会问题了,借位怎么表示呢?加法运算中,进位通过与运算并左移一位实现,而借位就真的不好表示了。所以我们自然的想到将减法运算转变成加法运算。
怎么实现呢?
刚刚我们说了减法运算可转变成一个正数加上一个负数,那首先就要来看看负数在计算机中是怎么表示的。
+8在计算机中表示为二进制的1000,那-8怎么表示呢?
很容易想到,可以将一个二进制位(bit)专门规定为符号位,它等于0时就表示正数,等于1时就表示负数。比如,在8位机中,规定每个字节的最高位为符号位。那么,+8就是00001000,而-8则是10001000。这只是直观的表示方法,其实计算机是通过2的补码来表示负数的,那什么是2的补码(同补码,英文是2’s complement,其实应该翻译为2的补码)呢?它是一种用二进制表示有号数的方法,也是一种将数字的正负号变号的方式,求取步骤:
-
第一步,每一个二进制位都取相反值,0变成1,1变成0(即反码)。
-
第二步,将上一步得到的值(反码)加1。
简单来说就是取反加一!
关于补码更详细的内容可参维基百科-补码,这里不再赘述。
其实我们利用的恰巧是补码的可以将数字的正负号变号的功能,这样我们就可以把减法运算转变成加法运算了,因为负数可以通过其对应正数求补码得到。计算机也是通过增加一个补码器配合加法器来做减法运算的,而不是再重新设计一个减法器。
以上,我们很容易写出了位运算做减法运算的代码:
/*
* num1: 减数
* num2: 被减数
*/
int substract(int num1, int num2){
int subtractor = add(~num2, 1);// 先求减数的补码(取反加一)
int result = add(num1, subtractor); // add()即上述加法运算
return result ;
}123456789
3. 乘法运算
我们知道了加法运算的位运算实现,那很容易想到乘法运算可以转换成加法运算,被乘数加上乘数倍的自己不就行了么。这里还有一个问题,就是乘数和被乘数的正负号问题,我们这样处理,先处理乘数和被乘数的绝对值的乘积,然后根据它们的符号确定最终结果的符号即可。步骤如下:
(1) 计算绝对值得乘积
(2) 确定乘积符号(同号为证,异号为负)12
有了这个思路,代码就不难写了:
/*
* a: 被乘数
* b: 乘数
*/
int multiply(int a, int b){
// 取绝对值
int multiplicand = a < 0 ? add(~a, 1) : a;
int multiplier = b < 0 ? add(~b , 1) : b;// 如果为负则取反加一得其补码,即正数
// 计算绝对值的乘积
int product = 0;
int count = 0;
while(count < multiplier) {
product = add(product, multiplicand);
count = add(count, 1);// 这里可别用count++,都说了这里是位运算实现加法
}
// 确定乘积的符号
if((a ^ b) < 0) {// 只考虑最高位,如果a,b异号,则异或后最高位为1;如果同号,则异或后最高位为0;
product = add(~product, 1);
}
return product;
}123456789101112131415161718192021
上面的思路在步骤上没有问题,但是第一步对绝对值作乘积运算我们是通过不断累加的方式来求乘积的,这在乘数比较小的情况下还是可以接受的,但在乘数比较大的时候,累加的次数也会增多,这样的效率不是最高的。我们可以思考,如何优化求绝对值的乘积这一步。
考虑我们现实生活中手动求乘积的过程,这种方式同样适用于二进制,下面我以13*14为例,向大家演示如何用手动计算的方式求乘数和被乘数绝对值的乘积。

整理成算法步骤:
(1) 判断乘数是否为0,为0跳转至步骤(4)
(2) 将乘数与1作与运算,确定末尾位为1还是为0,如果为1,则相加数为当前被乘数;如果为0,则相加数为0;将相加数加到最终结果中;
(3) 被乘数左移一位,乘数右移一位;回到步骤(1)
(4) 确定符号位,输出结果;1234
代码如下:
int multiply(int a, int b) {
//将乘数和被乘数都取绝对值
int multiplicand = a < 0 ? add(~a, 1) : a;
int multiplier = b < 0 ? add(~b , 1) : b;
//计算绝对值的乘积
int product = 0;
while(multiplier > 0) {
if((multiplier & 0x1) > 0) {// 每次考察乘数的最后一位
product = add(product, multiplicand);
}
multiplicand = multiplicand << 1;// 每运算一次,被乘数要左移一位
multiplier = multiplier >> 1;// 每运算一次,乘数要右移一位(可对照上图理解)
}
//计算乘积的符号
if((a ^ b) < 0) {
product = add(~product, 1);
}
return product;
}1234567891011121314151617181920
显而易见,第二种求乘积的方式明显要优于第一种。
4. 除法运算
除法运算很容易想到可以转换成减法运算,即不停的用除数去减被除数,直到被除数小于除数时,此时所减的次数就是我们需要的商,而此时的被除数就是余数。这里需要注意的是符号的确定,商的符号和乘法运算中乘积的符号确定一样,即取决于除数和被除数,同号为证,异号为负;余数的符号和被除数一样。 代码如下:
/*
* a : 被除数
* b : 除数
*/
int divide(int a, int b){
// 先取被除数和除数的绝对值
int dividend = a > 0 ? a : add(~a, 1);
int divisor = b > 0 ? a : add(~b, 1);
int quotient = 0;// 商
int remainder = 0;// 余数
// 不断用除数去减被除数,直到被除数小于被除数(即除不尽了)
while(dividend >= divisor){// 直到商小于被除数
quotient = add(quotient, 1);
dividend = substract(dividend, divisor);
}
// 确定商的符号
if((a ^ b) < 0){// 如果除数和被除数异号,则商为负数
quotient = add(~quotient, 1);
}
// 确定余数符号
remainder = b > 0 ? dividend : add(~dividend, 1);
return quotient;// 返回商
}123456789101112131415161718192021222324
这里有和简单版乘法运算一样的问题,如果被除数非常大,除数非常小,那就要进行很多次减法运算,有没有更简便的方法呢?
上面的代码之所以比较慢是因为步长太小,每次只能用1倍的除数去减被除数,所以速度比较慢。那能不能增大步长呢?如果能,应该怎么增大步长呢?
计算机是一个二元的世界,所有的int型数据都可以用[2^0, 2^1,…,2^31]这样一组基来表示(int型最高31位)。不难想到用除数的2^31,2^30,…,2^2,2^1,2^0倍尝试去减被除数,如果减得动,则把相应的倍数加到商中;如果减不动,则依次尝试更小的倍数。这样就可以快速逼近最终的结果。
2的i次方其实就相当于左移i位,为什么从31位开始呢?因为int型数据最大值就是2^31啊。
代码如下:
int divide_v2(int a,int b) {
// 先取被除数和除数的绝对值
int dividend = a > 0 ? a : add(~a, 1);
int divisor = b > 0 ? a : add(~b, 1);
int quotient = 0;// 商
int remainder = 0;// 余数
for(int i = 31; i >= 0; i--) {
//比较dividend是否大于divisor的(1<<i)次方,不要将dividend与(divisor<<i)比较,而是用(dividend>>i)与divisor比较,
//效果一样,但是可以避免因(divisor<<i)操作可能导致的溢出,如果溢出则会可能dividend本身小于divisor,但是溢出导致dividend大于divisor
if((dividend >> i) >= divisor) {
quotient = add(quotient, 1 << i);
dividend = substract(dividend, divisor << i);
}
}
// 确定商的符号
if((a ^ b) < 0){
// 如果除数和被除数异号,则商为负数
quotient = add(~quotient, 1);
}
// 确定余数符号
remainder = b > 0 ? dividend : add(~dividend, 1);
return quotient;// 返回商
}
五:汇编中的寄存器详解
1、寄存器
32位寄存器有16个,分别是:
4个数据寄存器(EAX、EBX、ECX、EDX)。
2个变址和指针寄存器(ESI和EDI);
2个指针寄存器(ESP和EBP)。
6个段寄存器(ES、CS、SS、DS、FS、GS)。
1个指令指针寄存器(EIP);1个标志寄存器(EFlags)。
2、数据寄存器
数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。
32位CPU有4个32位通用寄存器:EAX、EBX、ECX和EDX。对低16位数据的取存,不会影响高16
位的数据,这些低16位寄存器分别命名为AX、BX、CX和DX,它和先前的CPU中的寄存器相一致。
4个16位寄存器又可分割成8个独立的8位寄存器(AX:ah~al、BX:bh~bl、CX:ch~cl:DX:dh~dl)。
每个寄存器都有自己的名称,可独立存取。程序员可利用数据寄存器的这种“可合可分”的特性,灵活地处理字/
字节的信息。
AX和al通常称为累加器,用累加器进行的操作可能需要更少时间,累加器可用于乘、除、输入/输出等操作,
它们的使用频率很高。
BX称为基地址寄存器,它可作为存储器指针来使用。
CX称为计数寄存器,在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用cl来
指明位移的位数。
DX称为数据寄存器,在进行乘、除运算时,它可以为默认的操作数参与运算,也可用于存放I/O的端口地址。
在16位CPU中,AX、BX、CX和DX不能作为基址和变址寄存器来存放存储单元的地址,但在32位CPU
中,其32位寄存器EAX、EBX、ECX和EDX不仅可传送数据、暂存数据、保存算术逻辑运算结果,而且也可
作为指针寄存器,所以,这些32位寄存器更具有通用性。
3、变址寄存器
32位CPU有2个32位通用寄存器ESI和EDI,其低16位对应先前CPU中的SI和DI,对低16位数据的
存取,不影响高16位的数据。
ESI、EDI、SI和DI称为变址寄存器,它们主要用于存放存储单元在段内的偏移量,用它们可实现多种存储器
操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。
变址寄存器不可分割成8位寄存器,作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。
它们可作一般的存储器指针使用,在字符串操作指令的执行过程中,对它们有特定的要求,而且还具有特殊的
功能。
4、指针寄存器
32位CPU有2个32位通用寄存器EBP和ESP,其低16位对应先前CPU中的BP和SP,对低16位数
据的存取,不影响高16位的数据。
EBP、ESP、BP和SP称为指针寄存器,主要用于存放堆栈内存储单元的偏移量,用它们可实现多种存储器
操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。
指针寄存器不可分割成8位寄存器,作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。
它们主要用于访问堆栈内的存储单元,并且规定:
BP为基指针寄存器,用它可直接存取堆栈中的数据。
SP为堆栈指针寄存器,用它只可访问栈顶。
5、段寄存器
段寄存器是根据内存分段的管理模式而设置的。内存单元的物理地址由段寄存器的值和一个偏移量组合而成
的,这样可用两个较少位数的值组合成一个可访问较大物理空间的内存地址。
32位CPU有6个段寄存器,分别如下:
CS:代码段寄存器 ES:附加段寄存器
DS:数据段寄存器 FS:附加段寄存器
SS:堆栈段寄存器 GS:附件段寄存器
在16位CPU系统中,只有4个段寄存器,所以,程序在任何时刻至多有4个正在使用的段可直接访问,在
32位微机系统中,它有6个段寄存器,所以在此环境下开发的程序最多可同时访问6个段。
32位CPU有两个不同的工作方式:实方式和保护方式。在每种方式下,段寄存器的作用是不同的,有关规定
简单描述如下:
实方式:段寄存器CS、DS、ES和SS与先前CPU中的所对应的段寄存器的含义完全一致,内存单元的逻辑
地址仍为“段地址:偏移地址”的形式,为访问某内存段内的数据,必须使用该段寄存器和存储单元的偏移地址。
保护方式:在此方式下,情况要复杂得多,装入段寄存器的不再是段值,而是称为“选择子”的某个值。
6、指令指针寄存器
32位CPU把指令指针扩展到32位,并记作EIP,EIP的低16位与先前CPU中的IP作用相同。
指令指针EIP、IP是存放下次将要执行的指令在代码段的偏移地址,在具有预取指令功能的系统中,下次要执
行的指令通常已被预取到指令队列中,除非发生转移情况,所以,在理解它们的功能时不考虑存在指令队列的情
况。
在实方式下,由于每个段的最大范围为64KB,所以,EIP的高16位肯定都为0,此时,相当于只用其低16
位的IP来反映程序中的指令的执行次序。
7、标志寄存器
1.运算结果标志位。一共6个,包括:CF进位标志位、PF奇偶标志位、AF辅助进位标志位、ZF零标志位、
SF符号标志位、OF溢出标志位。
2.状态控制标志位。一共3个,包括:TF追踪标志位、IF中断允许标志位、DF方向标志位。
以上标志位在第7章里都讲过了,在这里就不再解释了,现在讲讲32位标志寄存器增加的4个标志位。
\1. I/O特权标志IOPL。
IOPL用两位二进制位来表示,也称为I/O特权级字段,该字段指定了要求执行I/O指令的特权级,如果当前
的特权级别在数值上小于等于IOPL的值,那么,该I/O指令可执行,否则将发生一个保护异常。
\2. 嵌套任务标志NT。
NT用来控制中断返回指令IRET的执行。具体规定如下:
(1) 当NT=0,用堆栈中保存的值恢复EFlags、CS和EIP,执行常规的中断返回操作。
(2) 当NT=1,通过任务转换实现中断返回。
\3. 重启动标志RF。
RF用来控制是否接受调试故障。规定:RF=0时,表示接受,否则拒绝。
\4. 虚拟8086方式标志VM。
如果VM=1,表示处理机处于虚拟的8086方式下的工作状态,否则,处理机处于一般保护方式下的工作状态。
8、32位地址的寻址方式
最后说一下32位地址的寻址方式。在前面我们学习了16位地址的寻址方式,一共有5种,在32位微机系统
中,又提供了一种更灵活、方便但也更复杂的内存寻址方式,从而使内存地址的寻址范围得到了进一步扩大。
在用16位寄存器来访问存储单元时,只能使用基地址寄存器(BX和BP)和变址寄存器(SI和DI)来作为
偏移地址的一部分,但在用32位寄存器寻址时,不存在上述限制,所有32位寄存器(EAX、EBX、ECX、
EDX、ESI、EDI、EBP、和ESP)都可以是偏移地址的一个组成部分。
当用32位地址偏移量进行寻址时,偏移地址可分为3部分:
\1. 一个32位基址寄存器(EAX、EBX、ECX、EDX、ESI、EDI、EBP、ESP)。
\2. 一个可乘以1、2、4、8的32位变址寄存器(EAX、EBX、ECX、EDX、ESI、EDI和EBP)。
\3. 一个8位~32位的偏移常量。
比如,指令:mov ebx, [eax+edx*2+300]
Eax就是基址寄存器,edx就是变址寄存器,300H就是偏移常量。
上面那3部分可进行任意组合,省去其中之一或之二。
下面列举几个32位地址寻址指令:
Mov ax, [123456]
Mov eax, [ebx]
Mov ebx, [ecx*2]
Mov ebx, [eax+100]
Mov ebx, [eax*4+200]
Mov ebx, [eax+edx*2]
Mov ebx, [eax+edx*4+300]
Mov ax, [esp]
由于32位寻址方式能使用所有的通用寄存器,所以,和该有效地址相组合的段寄存器也就有新的规定,具体
规定如下:
\1. 地址中寄存器的书写顺序决定该寄存器是基址寄存器还是变址寄存器。
如:[ebx+ebp]中的ebx是基址寄存器,ebp是变址寄存器,而[ebp+ebx]中的ebp是基址寄存器,ebx是变
址寄存器,可以看出,左边那个是基址寄存器,另一个是变址寄存器。
\2. 默认段寄存器的选用取决于基址寄存器。
\3. 基址寄存器是ebp或esp时,默认的段寄存器是SS,否则,默认的段寄存器是DS。
\4. 在指令中,如果显式地给出段寄存器,那么显式段寄存器优先。
下面列举几个32位地址寻址指令及其内存操作数的段寄存器。
指令列举: 访问内存单元所用的段寄存器
mov ax, [123456] ;默认段寄存器为DS。
mov ax, [ebx+ebp] ;默认段寄存器为DS。
mov ebx, [ebp+ebx] ;默认段寄存器为SS。
mov ebx, [eax+100] ;默认段寄存器为DS。
mov edx, ES:[eax*4+200] ;显式段寄存器为ES。
mov [esp+edx*2], ax ;默认段寄存器为SS。
mov ebx, GS:[eax+edx*8+300] ;显式段寄存器为GS。
mov ax, [esp] ;默认段寄存器为SS。
六:内存的理解
1、机器语言和汇编语言
机器语言是机器指令的集合。机器指令展开来说就是一个可以正确执行的命令,电子计算机的机器指令是一列二进制数字,计算机将之转变为一列高低电平,以使计算机的电子器件受到驱动,进行计算。
在我们通常的PC中,有一个芯片来完成上面的计算机的功能。这个芯片就是我们常说的CPU(Central Processing Unit,中央处理单元)。
每一种微处理器,由于硬件设计和内部结构的不同,就需要用不同的电平脉冲来控制,使它工作。所以每一种微处理器都有自己的机器指令集,也就是机器语言。
由于机器语言书写和记忆都比较麻烦,所以产生了汇编语言。汇编语言的主体是汇编指令。汇编指令和机器指令的差别在于指令的表示方法上。汇编指令是机器指令便于记忆的书写格式。
//操作:寄存器BX的内容送到AX中``机器指令: ``1000100111011000``汇编指令: mov ax,bx
汇编语言出现以后,程序员使用汇编指令编写程序。但是计算机能读懂的只有机器指令,所以需要有一个能够将汇编指令转换成机器指令的翻译程序,我们称之为编译器。程序员用汇编语言写出源程序,再用汇编编译器将其编译为机器码,由计算机最终执行。过程如下图。

那么,汇编语言的指令有哪些呢?一共有三类:
(1)汇编指令: 机器码的助记符,有对应的机器码。
(2)伪指令: 没有对应的机器码,由编译器执行,计算机并不执行。
(3)其他符号: 如+、-、*、/等,由编译器识别,没有对应的机器码。
汇编语言的核心是汇编指令,它决定了汇编语言的特性。
2、CPU是怎么工作的
CPU是计算机的核心部件,控制整个计算机的运作并进行运算。要想让一个CPU工作,就必须向它提供指令和数据。指令和数据在存储器中存放,也就是常说的内存,离开了内存,性能再好的CPU也无法工作。磁盘不同于内存,磁盘上的数据或程序如果不读到内存,就无法被CPU使用。所以我们首先需要了解CPU如何从内存中读取信息和写入信息。
存储器被划分为若干个存储单元,每个存储单元从0开始顺序编号。一个存储单元是一个Byte,一个Byte是8个bit,就是8位,也就是8个0/1值,例如10001111就是一个Byte。
在内存和磁盘上,数据和指令没有任何区别,都是0/1二进制信息,关键是CPU在工作的时候把有的信息看作指令,有的信息看作数据,为同样的信息赋予了不同的意义。
CPU要想进行数据的读写,必须和外部部件(标准的说法是芯片)进行下面3类信息的交互。
a) 存储单元的地址(地址信息)
b) 器件的选择,读或写的命令(控制信息)
c) 读或写的数据(数据信息)
CPU从内存中读取数据,就要将地址、数据和控制信息传到内存芯片中。在计算机中专门有连接CPU和其他芯片的导线,通常称为总线,根据传送信息的不同,从逻辑上分为地址总线、控制总线和数据总线3类。
例如CPU从3号单元中读取数据的过程如下。
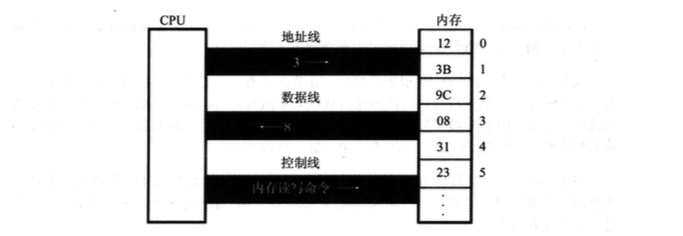
1) CPU通过地址线将地址信息3发出。
2) CPU通过控制线发出内存读命令,选中存储区芯片,并通知它,将要从中读取数据。
3) 存储器将3号单元中的数据8通过数据线送入CPU。
写操作与读操作类似,例如向3号单元写入数据26。
1)CPU通过地址线将地址信息3发出。
2)CPU通过控制线发出内存读命令,选中存储区芯片,并通知它,将要从中写入数据。
3)CPU通过数据线将数据26送入内存的3号单元中。
到此我们知道了CPU是如何进行数据读写的,那么如何命令计算机进行数据读写呢?答案就是向CPU输入能够驱动它进行工作的电平信息(机器码)。
例如对于8086CPU,下面的机器码能够完成从3号单元读数据
机器码: ``101000010000001100000000``<br>对应的汇编指令 MOV AX,[``3``]``含义: 从``3``号单元读取数据送入寄存器AX
一个CPU有N根地址线,则可以说这个CPU的地址总线的宽度为N。这样的CPU最多可以寻找2的N次方个内存单元。
数据总线的宽度决定了CPU和外界的数据传送速度。8根数据总线一次可传送一个8位二进制数据,16根数据总线一次可传送两个字节。
控制总线是一些不同控制线的集合,有多少根控制总线,就意味着CPU提供了对外部器件的多少种控制。所以控制总线的宽度决定了CPU对外部器件的控制能力。
计算机系统中,所有可以用程序控制其工作的设备,必须受到CPU的控制。CPU对外部设备不能直接控制,直接控制这些设备进行工作的是插在扩展插槽上的接口卡。扩展插槽通过总线和CPU相连,所以接口卡也通过总线同CPU相连。CPU可以直接控制这些接口卡,从而实现CPU对外设的间接控制。简言之,就是CPU通过总线向接口卡发送命令,接口卡根据CPU的命令控制外设进行工作。
一台PC机装有多个存储器芯片,它们从读写属性上分为随机存储器(RAM)和只读存储器(ROM),RAM可读可写,但必须带电存储,关机后存储的内容丢失,ROM只能读取不能写入,关机后其中的内容不丢失。这些存储器从功能和连接上可分为以下几类。
1)随机存储器
用于存放供CPU使用的绝大部分程序和数据,主随机存储器一般由两个位置上的RAM组成,装在主板上RAM和插在扩展插槽上的RAM。
2)装有BIOS(Basic Input/Output System,基本输入输出系统)的ROM
BIOS是由主板和各类接口卡厂商提供的软件系统,可以通过它利用该硬件设备进行最基本的输入输出。
3)接口卡上的RAM
某些接口卡需要对大批量输入输出数据进行暂时存储,在其上装有RAM。最典型的是显示卡上的RAM,一般称为显存。
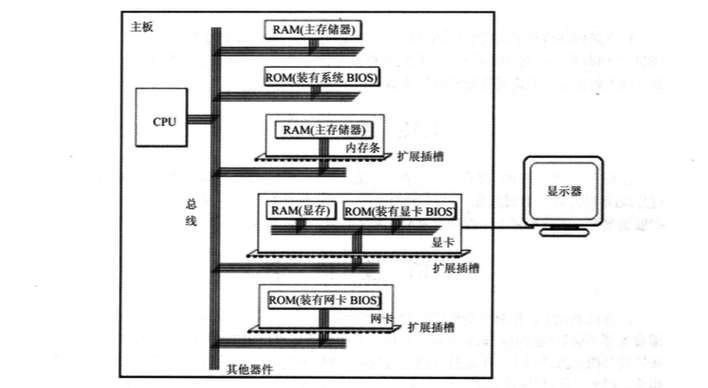
PC机中各类存储器的逻辑连接
上述的存储器,在物理上是独立的器件,但是都是和CPU的总线相连,CPU对它们进行读写的时候都通过控制线发出内存读写命令。也就是说,CPU在操控它们的时候,把它们都当作内存对待。也就是说,对于CPU而言,系统中的所有存储器中的存储单元处于一个统一的逻辑存储器中,它的容量受CPU寻址能力的限制。如下图所示。
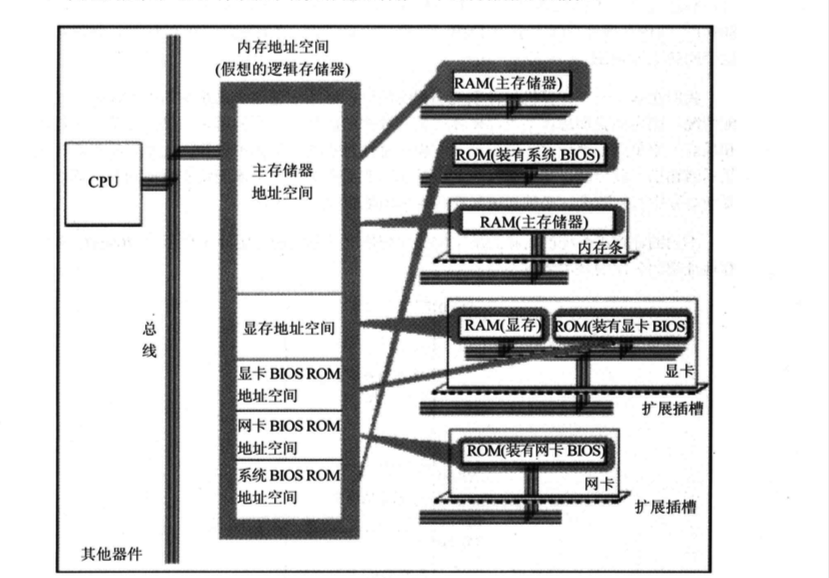
所以,我们在基于一个计算机硬件系统编程的时候,必须知道这个系统中的内存地址空间分配情况。因为当我们想在某类存储器中读写数据的时候,必须知道它的第一个单元的地址和最后一个单元的地址,才能保证读写操作是在预期的存储器中进行。
不同计算机系统的内存地址空间的分配情况是不同的,下图展示了8086PC机内存地址空间分配的基本情况。
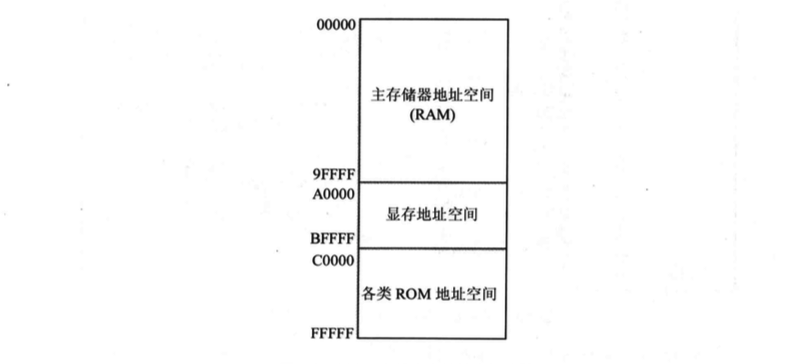
上图表示,从地址0~9FFFF的内存单元读取数据,实际上就是在读取主随机存储器中的数据;向地址A0000~BFFFF的内存单元写数据,就是想显存中写入数据,这些数据会被显示卡输出到显示器上;向地址C0000~FFFFF的内存单元中写入数据的操作是无效的,因为这等于改写只读存储器中的内容。
这是我从各大博主那里摘录的知识点,有点杂!见谅!
