python scrapy入门(一)-通过xpath获取数据保存到json,csv,mysql
1.下载包
pip install scrapy
2.在使用路径终端上创建项目指令: scrapy startproject 项目名
爬虫文件名和爬虫名称不能相同,spiders目录内不能存在相同的爬虫名称的项目文件
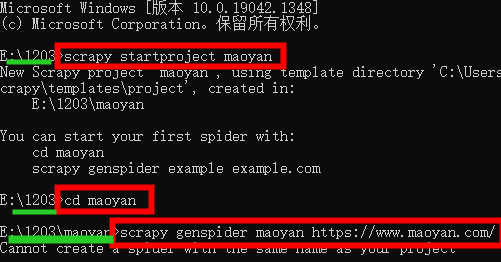
scrapy startproject maoyan
cd maoyan
scrapy genspider maoyan https://www.maoyan.com/
创建后目录大致页如下
|-ProjectName #项目文件夹
|-ProjectName #项目目录
|-items.py #定义数据结构
|-middlewares.py #中间件
|-pipelines.py #数据处理
|-settings.py #全局配置
|-spiders
|-__init__.py #爬虫文件
|-maoyan.py
|-scrapy.cfg #项目基本配置文件
3.settings设置如下:
# 项目名
BOT_NAME = 'maoyan'
SPIDER_MODULES = ['maoyan.spiders']
NEWSPIDER_MODULE = 'maoyan.spiders'
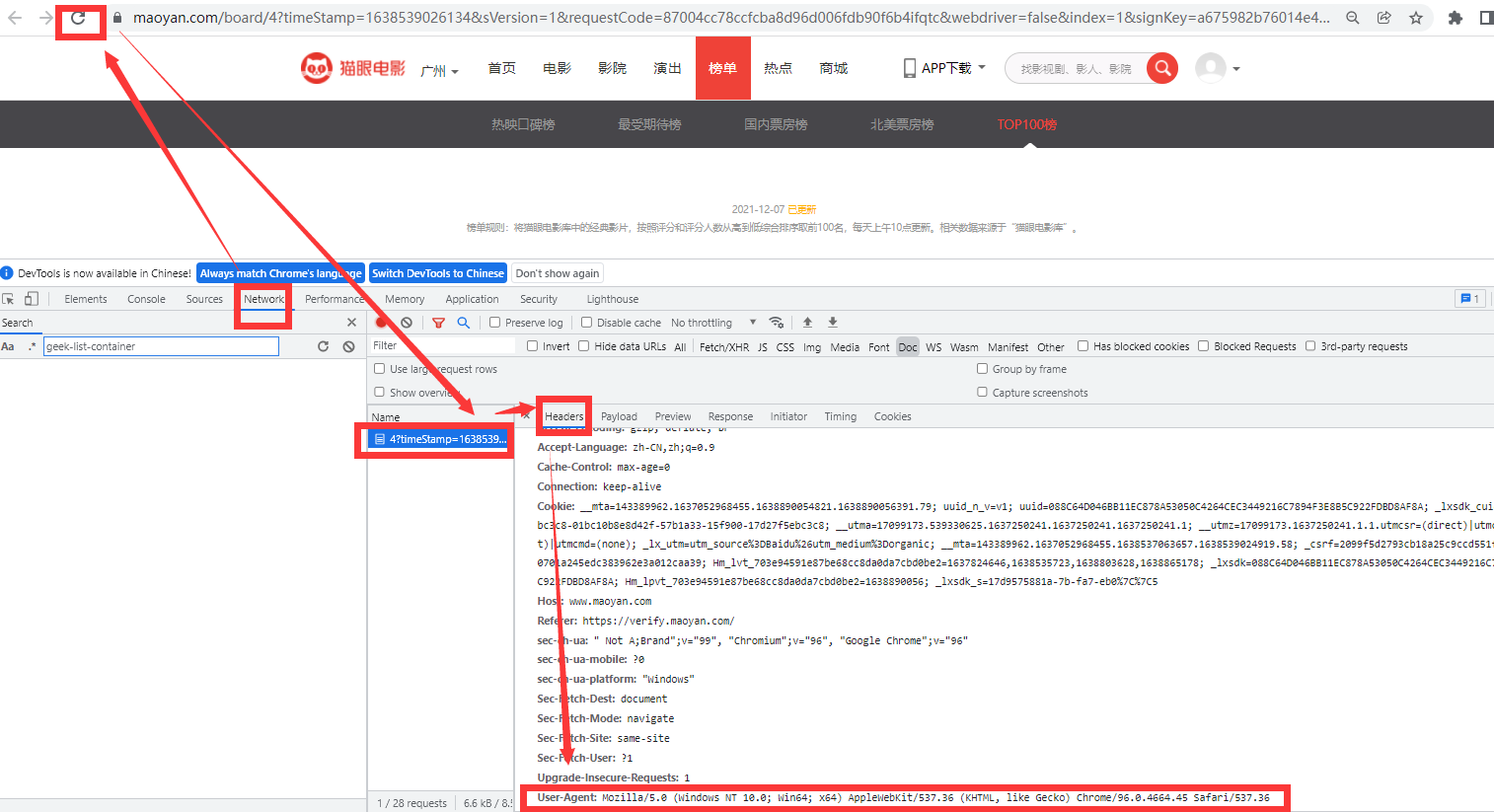
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
# ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true,需要改为false
ROBOTSTXT_OBEY = False
# CONCURRENT_REQUESTS:最大并发数,同时允许开启多少个爬虫线程
#CONCURRENT_REQUESTS = 32
# 下载延迟时间,单位是秒,控制爬虫爬取的频率
DOWNLOAD_DELAY = 3
# DEFAULT_REQUEST_HEADERS:默认请求头,上面写了一个USER_AGENT,这个东西就是放在请求头里面的,可以根据你爬取的内容做相应设置。
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
#ITEM_PIPELINES:项目管道,300为优先级,越低越爬取的优先度越高
ITEM_PIPELINES = {
'myfirstPj.pipelines.MyfirstpjPipeline': 300,
}
#比如pipelines.py里面写了两个管道,一个爬取网页的管道,一个存数据库的管道,调整他们的优先级,如果有爬虫数据,优先执行存库操作。
#编码格式 , 不设置的话json就会乱码
FEED_EXPORT_ENCODING = 'utf-8'
USER_AGENT 在浏览器中可看到:
4.在items.py上编写需要抓取的内容
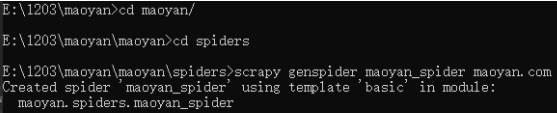
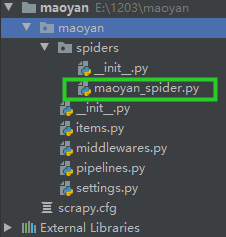
5.创建一个maoyan_spider.py文件
![]()

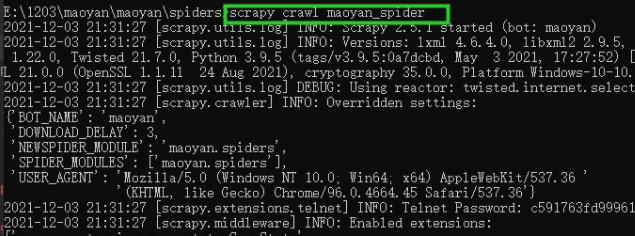
6.在 maoyan_spider.py上编写
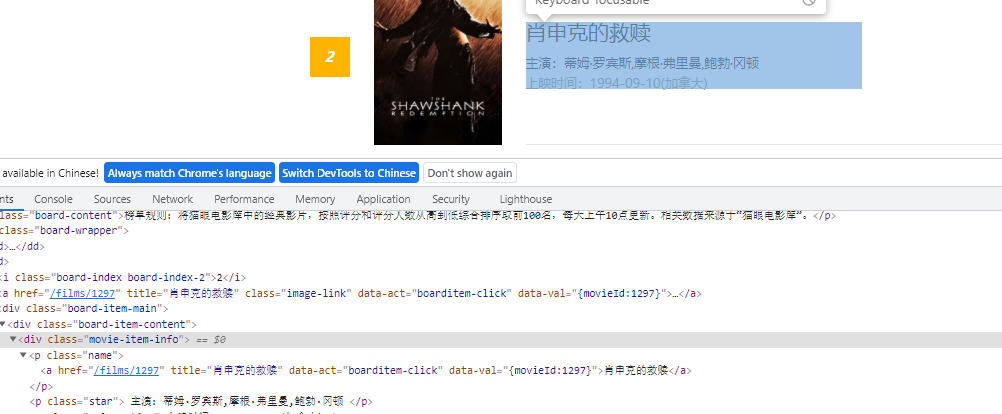
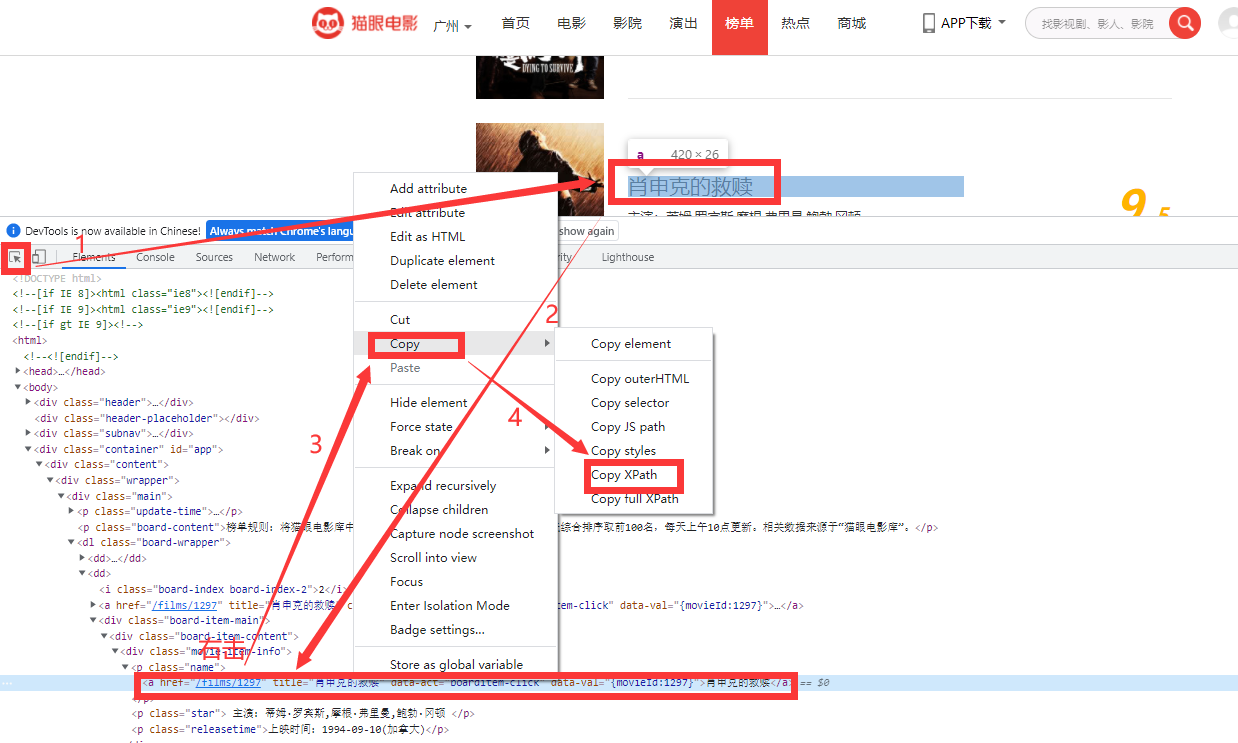
将复制出来的一大行的(包括电影名人名时间的)xpath先写起来,再复制下一行的xpath,再写起来,对比就可以发现规律了,通过循环每一大行,再细定位就可以了,细定位同样的单独复制两个电影名就可以发现其中的区别了
这是一大行的定位: //*[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1],//*[@id="app"]/div/div/div[1]/dl/dd[2]/div/div/div[1]可以看出dd[]是变量,所以在它前面的都是固定的,用//替换dd[],就可以得到一整页的行了,move_list=//*[@id='app']/div/div/div[1]/dl//div/div/div[1]
电影名为//*[@id="app"]/div/div/div[1]/dl/dd[3]/div/div/div[1]/p[1]/a ,时间为://*[@id="app"]/div/div/div[1]/dl/dd[3]/div/div/div[1]/p[3],可以看出在for循环每一行里面共用的开头那部分就是刚刚定位的一大行move_list的可以用" . "表示,".//p[1]/a",".//p[3]"
当然你也可以直接看网页中的标签自己写出来,方法不唯一
aaa=d.xpath(".//p[1]/a").extract_first() # 这是输出的第一个数据
输出之后接下来就是字符串的处理了。
这里没有下一页的功能,这里没有下一页的功能,大部分网页翻页功能一般方法:看网址是否有变量比如10,20,或者点击下一页按钮,同样也可以看request请求的变量。
7.手动创建一个main.py,用来运行的,也可以用指令
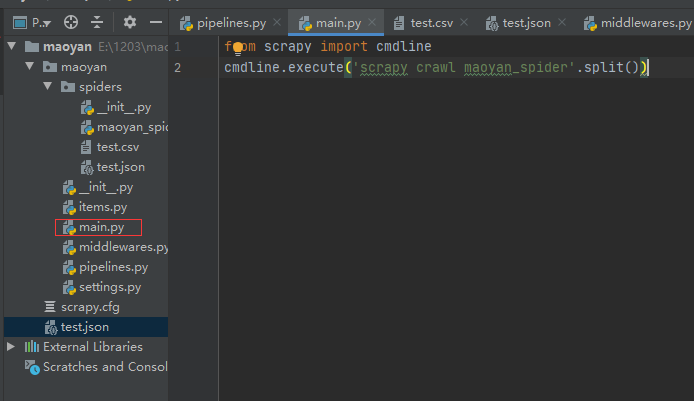
8.运行main.py
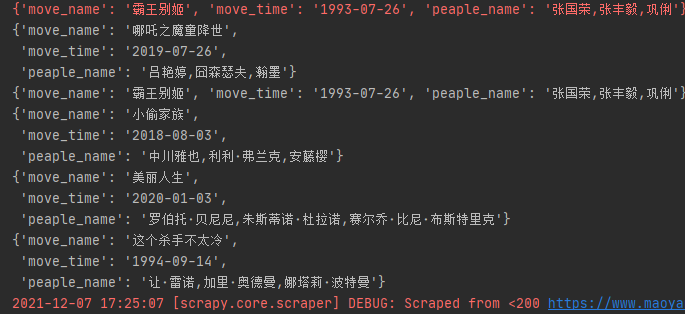
9.存储方式:json,csv,mysql
1)保存到json——注意路径
scrapy crawl maoyan_spider -o test.json

![]()
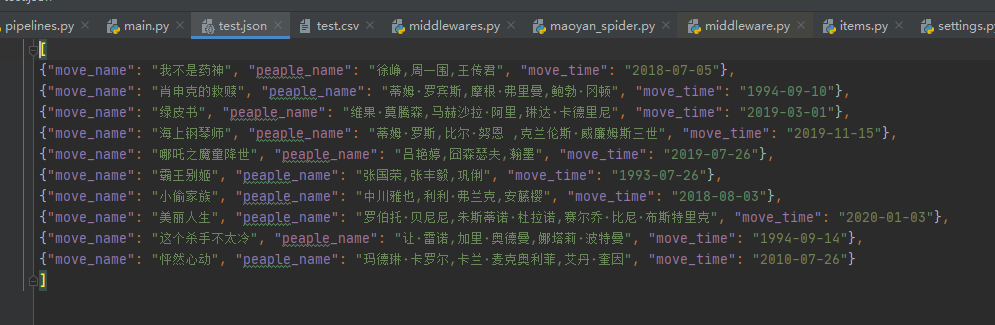
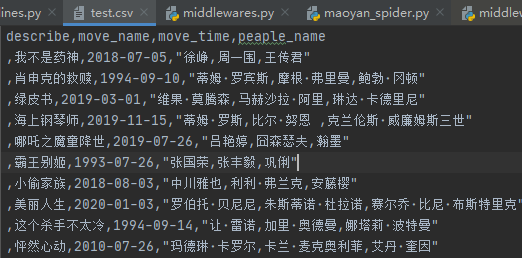
2)保存到csv——注意路径
scrapy crawl maoyan_spider -o test.csv

3)保存到数据库mysql
数据库自己先建好表和字段,这里是直接插入数据的
#settings.py # mongo_host='192.168.x.xxx' # mongo_post=27017 # mongo_db_name='maoyan' # mongo_db_collection='maoyan_movie' MYSQL_HOST = 'localhost' MYSQL_DBNAME = 'maoyan_sql' MYSQL_USER = 'root' MYSQL_PASSWD = '1234'
#pipelines.py # mongo_host='192.168.x.xxx' # mongo_post=27017 # mongo_db_name='maoyan' # mongo_db_collection='maoyan_movie' MYSQL_HOST = 'localhost' MYSQL_DBNAME = 'maoyan_sql' MYSQL_USER = 'root' MYSQL_PASSWD = '1234'#pipelines.py from itemadapter import ItemAdapter import pymysql from sqlalchemy import * from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base from datetime import datetime #连接数据库 from maoyan import settings def dbHandle(): conn = pymysql.connect( host = "localhost", user = "root", passwd = "1234", charset = "utf8mp4", use_unicode = False ) return conn class MaoyanPipeline: def __init__(self): # 连接数据库 self.connect = pymysql.connect( host=settings.MYSQL_HOST, db=settings.MYSQL_DBNAME, user=settings.MYSQL_USER, passwd=settings.MYSQL_PASSWD, charset='utf8', use_unicode=True) # 通过cursor执行增删查改 self.cursor = self.connect.cursor() def process_item(self, item, spider): try: # 插入数据 self.cursor.execute( """insert into move(move_name,peaple_name,move_time) value (%s, %s, %s)""", (item['move_name'], item['peaple_name'], item['move_time'])) # 提交sql语句 self.connect.commit() except BaseException as e: # 出现错误时打印错误日志 print("error:------------", e, "-----------------") return item #dbmongo部分参考 # def __init__(self): # host=mongo_host # post=mongo_post # dbname=mongo_db_name # sheetname=mongo_db_collection # client=pymongo.MongoClient(host=host,post=post) # mydb=client[dbname] # self.post=mydb[sheetname]#读写操作 # def process_item(self, item, spider): # data=dict(item)#先转字典,再数据插入 # self.post.insert(data) # return item # # class HellospiderPipeline(object): # def process_item(self, item, spider): # dbObject = dbHandle() # cursor = dbObject.cursor() # cursor.execute("USE maoyan_sql") # #插入数据库 # sql = "INSERT INTO move(move_name,peaple_name,move_time) VALUES(%s,%s,%s)" # try: # cursor.execute(sql, # ( item['move_name'], item['peaple_name'], item['move_time'])) # cursor.connection.commit() # except BaseException as e: # print("错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<") # dbObject.rollback() # return item
数据库中查看如下:
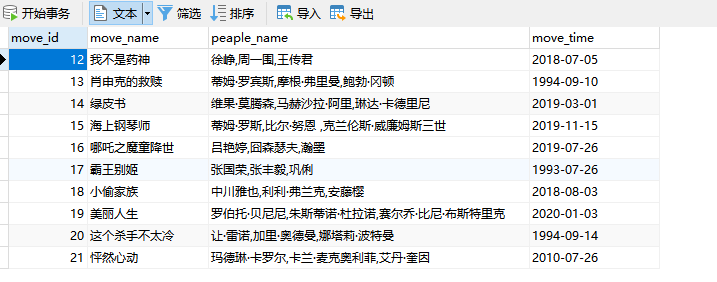
![]()
结尾:#以下仅供参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号