

Java基础-学习笔记14
14 集合 Collection、Map
第一部分 Collection的框架体系
1) 可以动态保存任意多个对象,使用比较方便
2) 提供了一系列方便的操作对象的方法:add、remove、set、get等
3) 使用集合添加、删除新元素简单便捷。
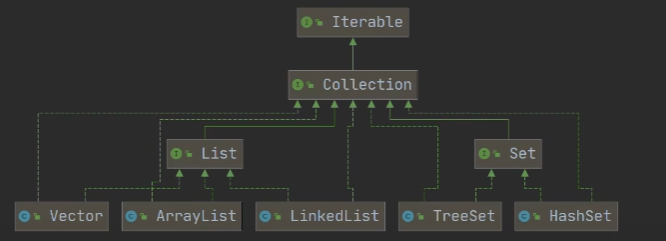
集合 Collection 主要是两组:单列集合, 双列集合
- List、Set是存储单列的数据集合,都继承与Collection接口。
- Map 接口的实现子类是双列集合,存放 K-V,是个独立接口。
1. List接口
1) List 集合类中元素有序,且可重复。
2) List 集合中的每个元素都有其对应的顺序索引,即支持索引。
3) List 容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
List 的三种遍历方式

1.1 ArrayList 底层结构和源码分析
1)ArrayList 中维护了一个 Object 类型的数组 elementData: transient Object[] elementData; // transient表示瞬间短暂的,表示该属性不会被序列化。
2)当创建 ArrayList 对象时,如果使用的是无参构造器,则初始 elementData容量为0,第1次添加,则扩容 elementData 为10,如需要再次扩容,则扩容 elementData 为1.5倍。( 0 -> 10 -> 15 -> 22 -> ...)
3)如果使用的是指定大小的构造器,则初始 elementData 容量为指定大小,如果需要扩容,则直接扩容 elementData 为1.5倍。
4) ArrayList 基本等同于 Vector,除了 ArrayList 是线程不安全(执行效率高),在多线程情况下,不建议使用 ArrayList。
1.2 Vector 底层结构和源码分析
1)Vector 底层也是一个对象数组, protected Object[] elementData;
2)Vector 是线程同步的,即线程安全,Vector 类的操作方法带有 synchronized。需要线程替补安全时,考虑使用 Vector。

1.3 LinkedList 底层结构和源码分析
1) LinkedList 底层实现了 双向链表和双端队列特点,可以添加任意元素(可成都),包括 null。
2) 线程不安全,没有实现替补。
3) 维护了一个双向链表。维护了两个属性 first 和 last 分别指向 首节点和尾节点。每个节点(Node对象),里面又维护了 prev、next、item三个属性,其中通过 prev指向前一个,next指向后一个节点。最终实现双向链表。
4)所以 LinkList 的元素的添加和删除,不是通过数组完成的,相对来说效率较高。

2. Set接口
1) 无序、不能重复、可以添加 null。
2)Set 接口也是 Collection 的子接口,因此常用方法和 Collection 接口一样。
3)可以使用迭代器、增强for;不能使用索引的方式来获取。
2.1 HashSet 底层机制
-
在执行 HashMap实例.add 方法后,会返回一个 boolean 值,如果添加成功,返回 true,否则 false。
-
HashSet不能添加相同的元素:
HashSet set = new HashSet();
set.add("0Mike"); // true
set.add("0Mike"); // false
set.add(new Person("1Jack")); // true
set.add(new Person("1Jack")); // true
set.add(new String("2King")); // true
set.add(new String("2King")); // false
- HashSet 底层是 HashMap,HashMap 底层是 (数组 + 单向链表 + 红黑树)
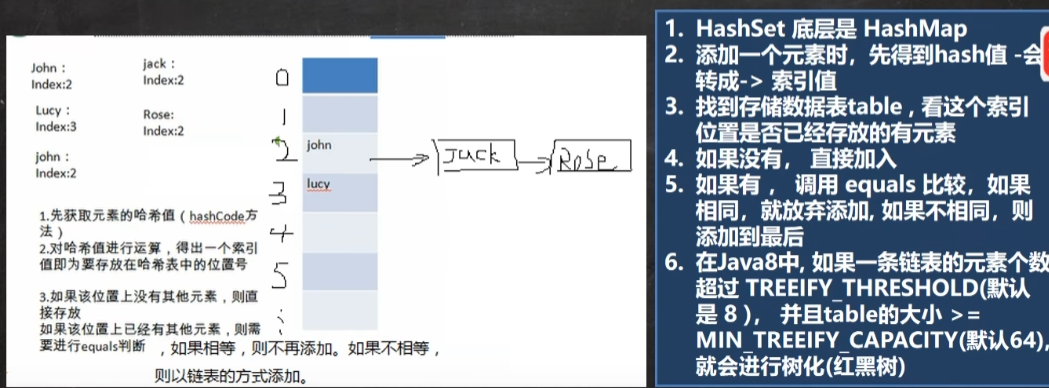
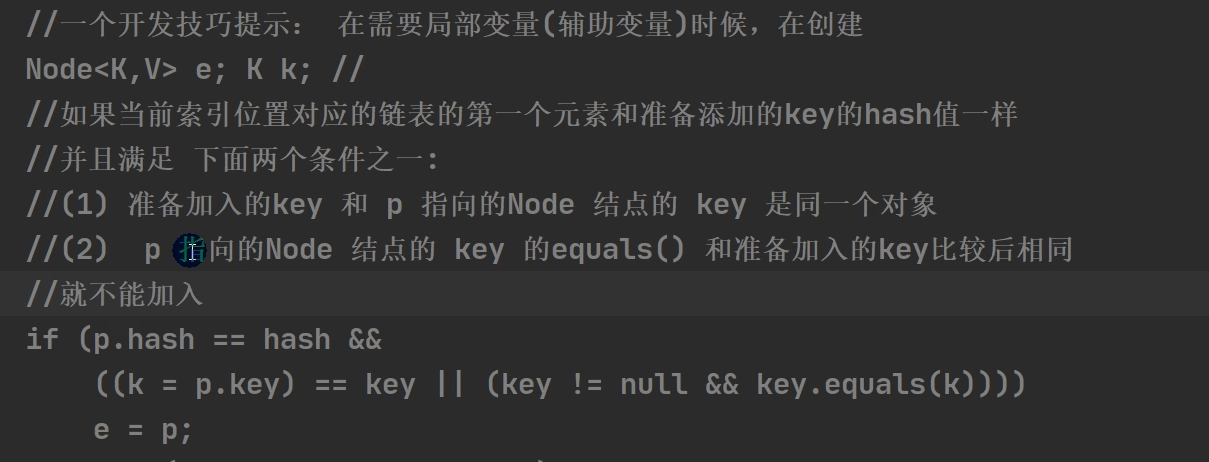
- 在上面添加字符对象为例,调用equals 方法,由于字符类改写了改方法,比较的是字符串内容,因此将两个 “2King” 识别为相同对象,不添加。注:该 equals 方法是可以由程序员自行定义更改的。

2.1.1 LinkedHashSet 底层机制
1) LinkedHashSet 是 HashSet 的子类,LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个 数组+双向链表
2)LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
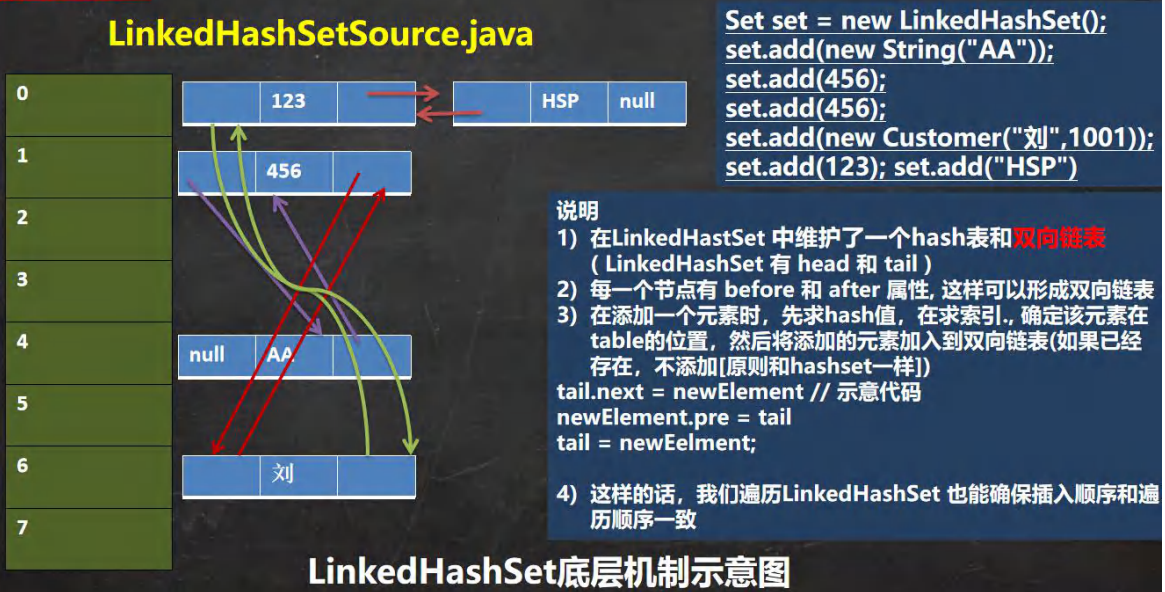
- LinkedHashSet底层是 HashMap+ 双向链表
- 添加第一次时,直接将数组扩容到 16,存放的结点类型是LinkedHashMap$Entry。
- 数组是 HashMap
Entry 类型。
3)LinkedHashSet 不允许添加重复元素。
第二部分 Map 接口
其实 Set 底层存放的也是 [K-V] 键值对形式,K 对应的就是存放的对象 Object,V 用多个是 PRESENT 这个常量替代,做占位作用。在 Map 里 K 也是存放的具体对象,V 则不再占位,由用户自己输入的具体对象。
- Map 接口实现类的特点(JDK8)
1) Map 与Collection并列存在。用于保存具有映射关系的数据:Key-Value(双列元素)。
2) Map 中的 key 和value 可以是任何引用类型的数据,会封装到 HashMap$Node 对象中。
3) Map 中的 key 不允许重复,原因和HashSet一样,不过,当重复时,会进行替换操作,而不是放弃添加操作。Map 中的 value可以为重复。 key 和 value 可以为 null(为null 的 key 只能有一个)。
4) 常用 String 类作为 Map的 key。
5) key 和 value 之间存在单向一对一关系,即通过指定的 key总能找到对应的 value。
6) Map 存放数据的 key-value 示意图。一对 k-v 是放在一个 Node中的,又因为 Node 实现了 Entry 接口,有些书上也说一对 k-v 就是一个 Entry(如图)

- k-v 最后是 HashMap$Node node = new Node(hash key, value, null)
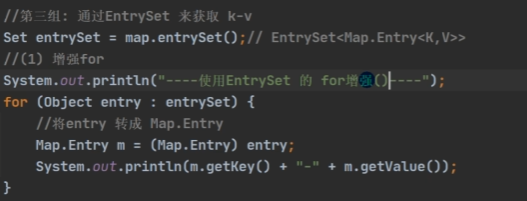
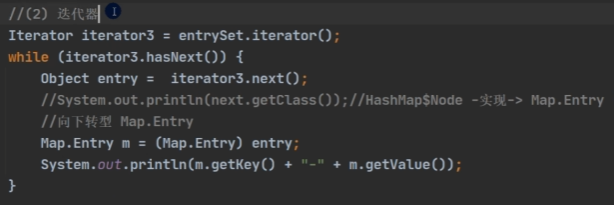
- k-v 为了方便程序员的遍历,还会创建 EntrySet 集合,该集合存放的元素类型 Entry, 而一个 Entry对象就有 k,v EntrySet<K, V>,即:transient Set<Map.Entry<K, V>> entrySet;
(在entrySet里,只是让 K 指向了 Node 节点里的 key,V 指向了 Node节点里的 value;只是一个指向,并没有存放新的东西。这么做是为了遍历方便 )- 在 enterSet 中,定义的类型是 Map.Entry,但是实际上存放的还是 HashMap
Node implements Map.Enter接口,这里是向上转型(多态)。 - 当把 HashMap$Node 对象存放到 enterSet 就方便我们的遍历,因为 Map.Entry 提供了重要方法 K getKey(); V getValue();
-
Map 接口和常用方法
遍历方式:① 增强for ② 迭代器 ③ 通过 entrySet
-
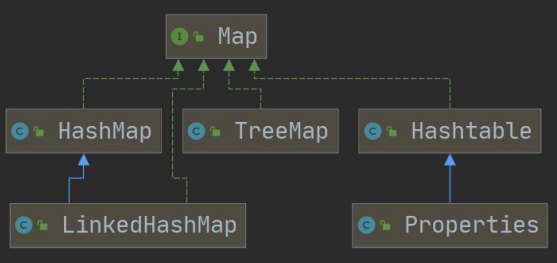
Map 接口的常用实现类
HashMap、Hashtable、Properties
1. HashMap底层机制及源码剖析
HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有 synchronized。

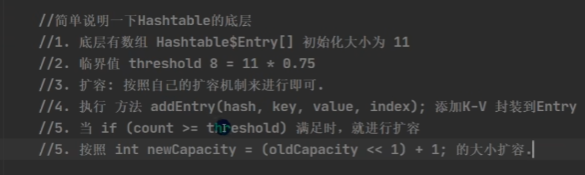
2. HashTable
HashTable 是线程安全的。

2. Properties
1)Properties 类继承自 HashTable类并且实现了 Map接口,也是使用一种键值对的形式来保存数据。使用特点和HashTable类似。
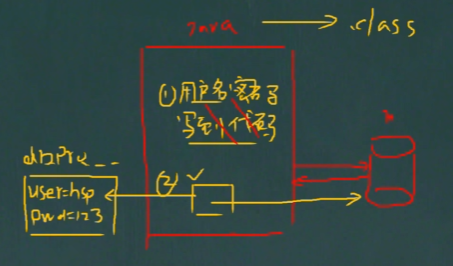
2)pROPERRIES 还可用于从 xxx.properties 文件中,加载数据到 Properties 类对象,并进行读取和修改。
xxx.Properties 文件通常作为配置文件。
总结——开发中如何选择集合实现类

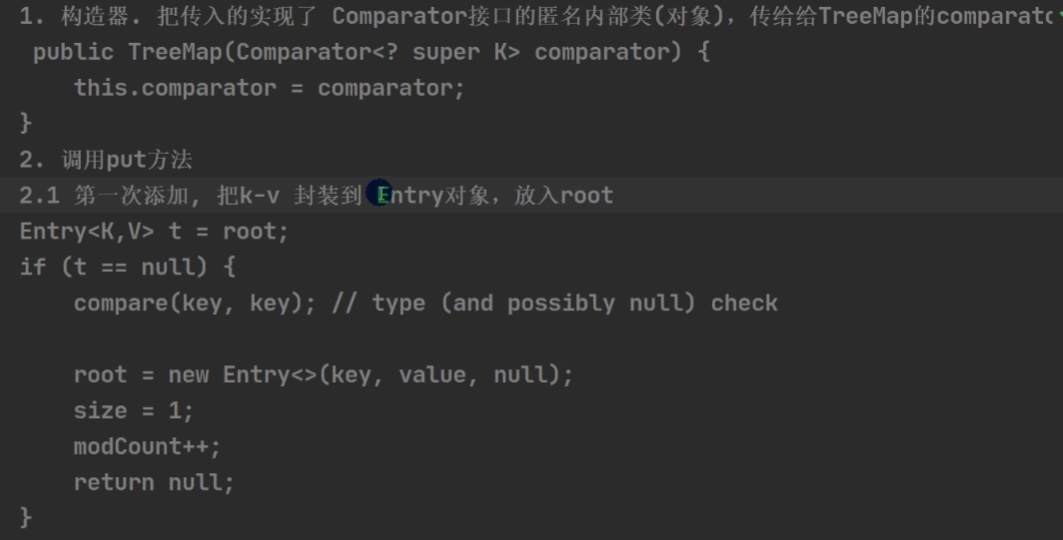
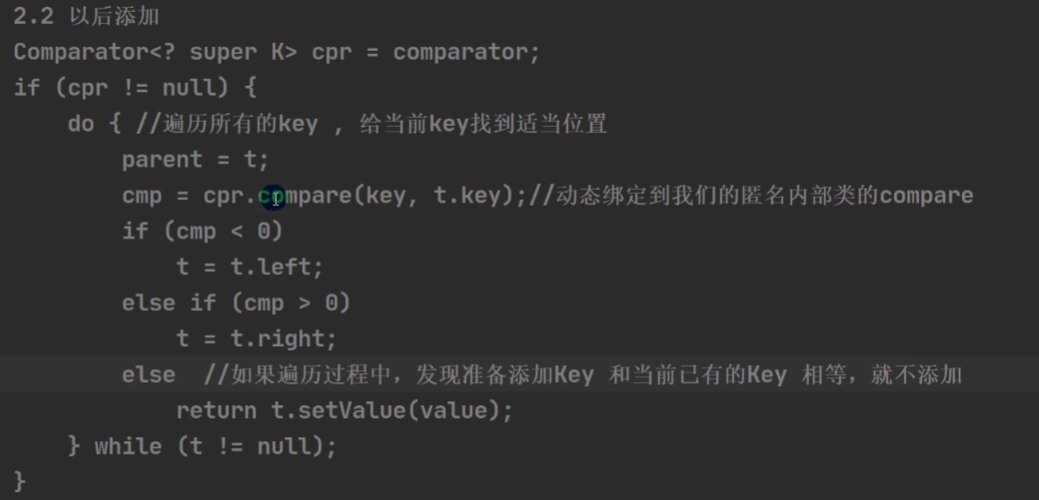
TreeMap 和 TreeSet 如果使用默认构造器,是无序的;如果使用有参构造里的传入一个实现的比较器,可以实现排序。TreeSet 的底层是 TreeMap。
TreeMap 底层源码:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)