个人项目
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-12 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-12/homework/13220 |
| 这个作业的目标 | 完整地做一次项目、掌握测试工具、掌握处理异常方法 |
1.Github仓库中新建学号为名的文件夹
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 1h | 1h |
| Estimate | 估计这个任务需要多少时间 | 48h | 36h |
| Development | 开发 | 20h | 15h |
| Analysis | 需求分析 (包括学习新技术) | 5h | 4h |
| Design Spec | 生成设计文档 | 1h | 1h |
| Design Review | 设计复审 | 3h | 4h |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 2h | 3h |
| Design | 具体设计 | 3h | 3h |
| Coding | 具体编码 | 4h | 4h |
| Code Review | 代码复审 | 2h | 1h |
| Test | 测试(自我测试,修改代码,提交修改) | 2h | 1h |
| Reporting | 报告 | 2h | 1h |
| Test Repor | 测试报告 | 3h | 2h |
| Size Measurement | 计算工作量 | 3h | 1h |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 1h | 1h |
| 合计 | 48h | 36h |
3. 计算模块接口的设计与实现过程
类和函数的设计
代码包含三个类:
TextProcessor类:负责文本的预处理工作。
SimilarityCalculator类:负责计算两个文本之间的相似度。
TextSimilarityAnalyzer类:使用 TextProcessor 和 SimilarityCalculator 来执行整个分析流程。
代码包含个函数:
preprocess_text:对输入的文本进行预处理,包括分词、去除停用词和非字母数字字符。
calculate_similarity:计算两个预处理后的文本之间的相似度。
analyze_similarity:执行整个文本相似度分析流程,包括读取文本文件、预处理文本、计算相似度,并将结果写入输出文件。
main:设置命令行参数解析,创建 TextSimilarityAnalyzer 实例,并调用 analyze_similarity 方法。
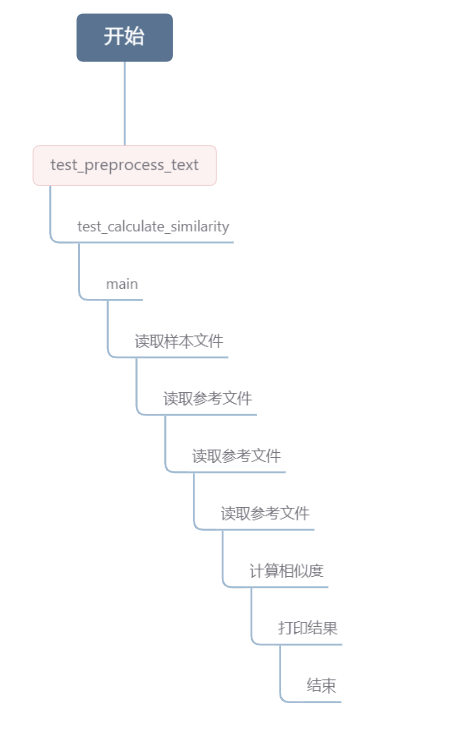
函数流程图
算法关键
(1)预处理文本:标准化格式、去除标点和特殊字符、分词、去除停用词和词干还原。
(2)向量化文本:采用词袋模型、TF-IDF和词嵌入。
(3)计算相似度:余弦相似度、Jaccard相似度和欧式距离。
4. 代码质量分析
采用Pylint进行检测代码质量,结果如图。

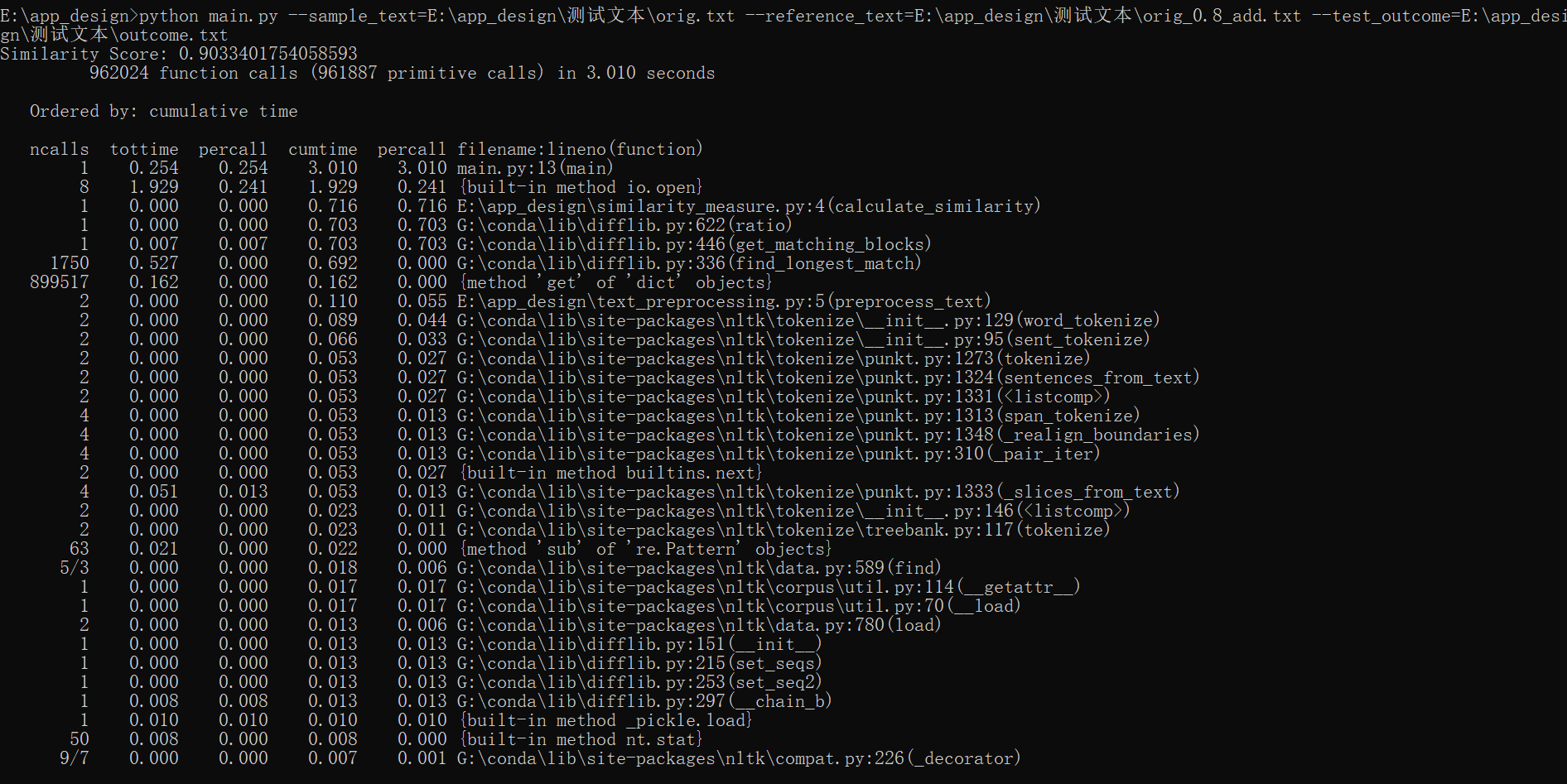
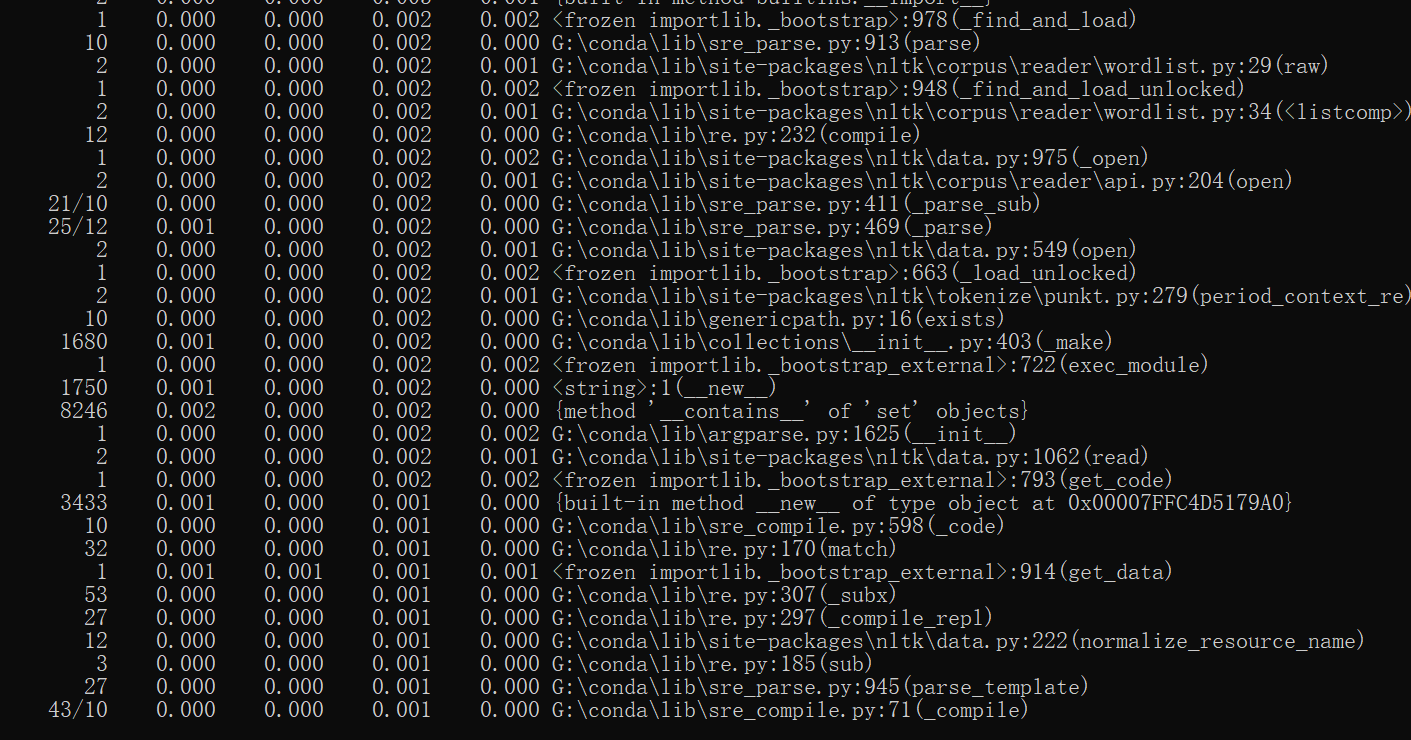
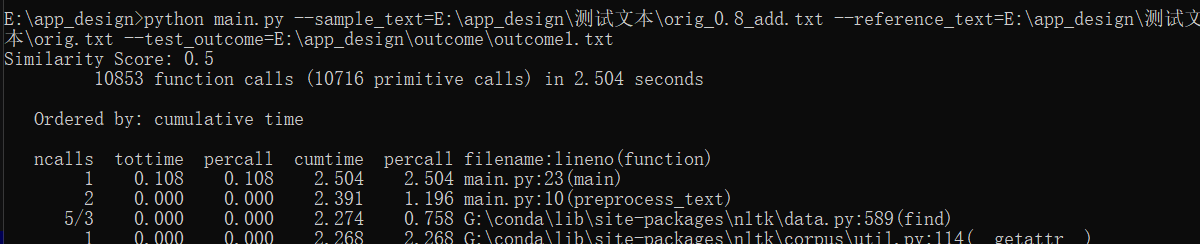
5. 计算模块接口部分的性能改进
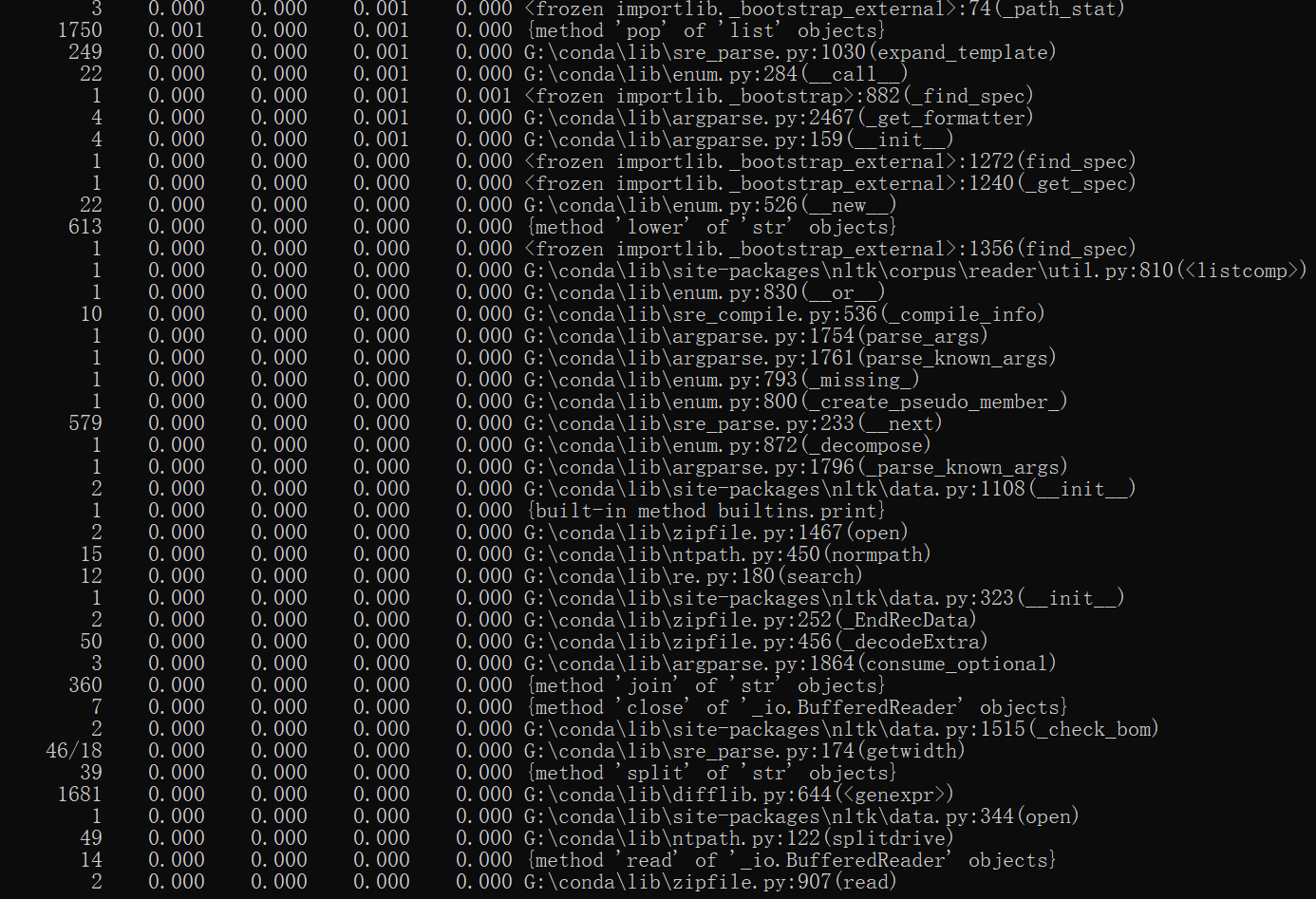
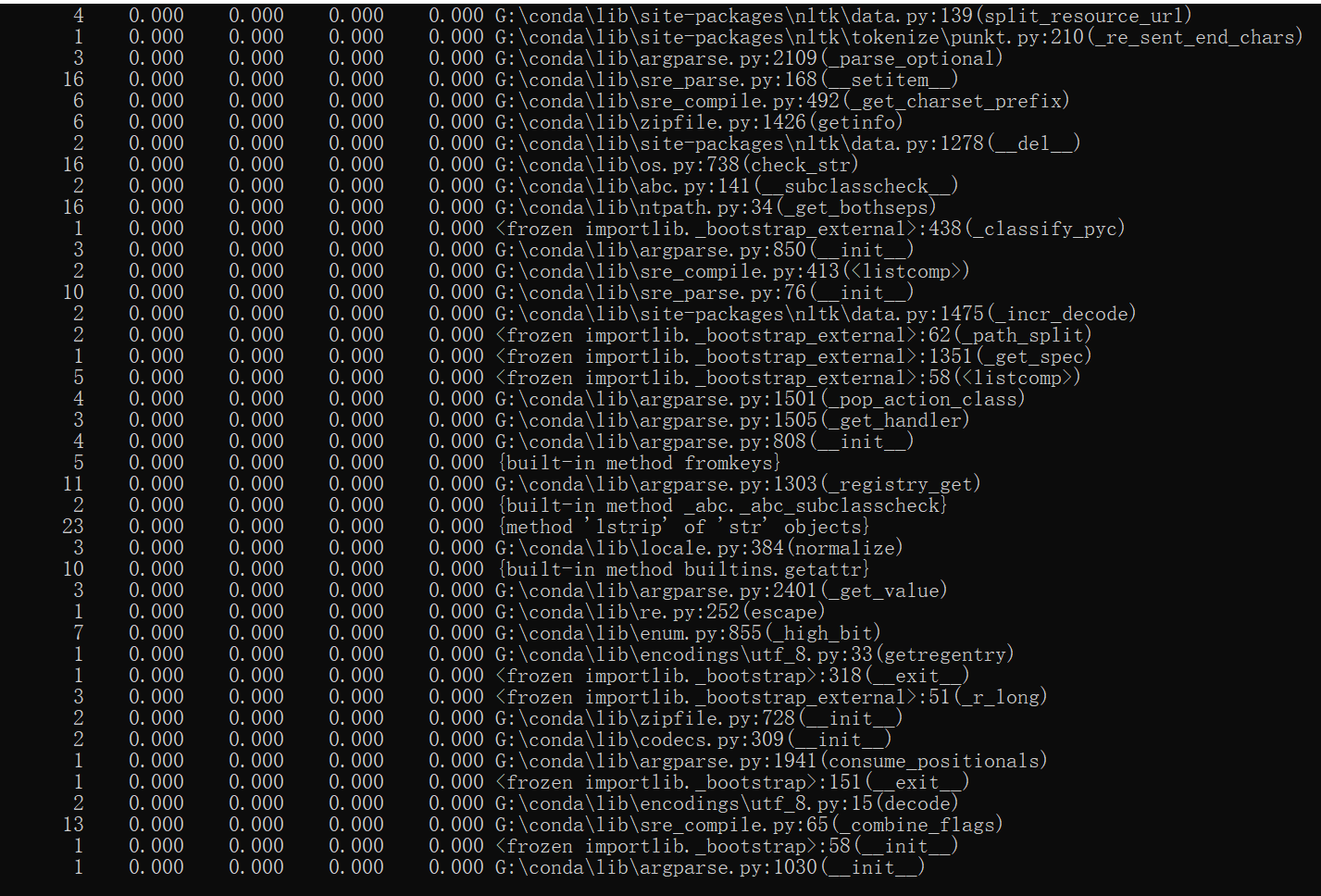
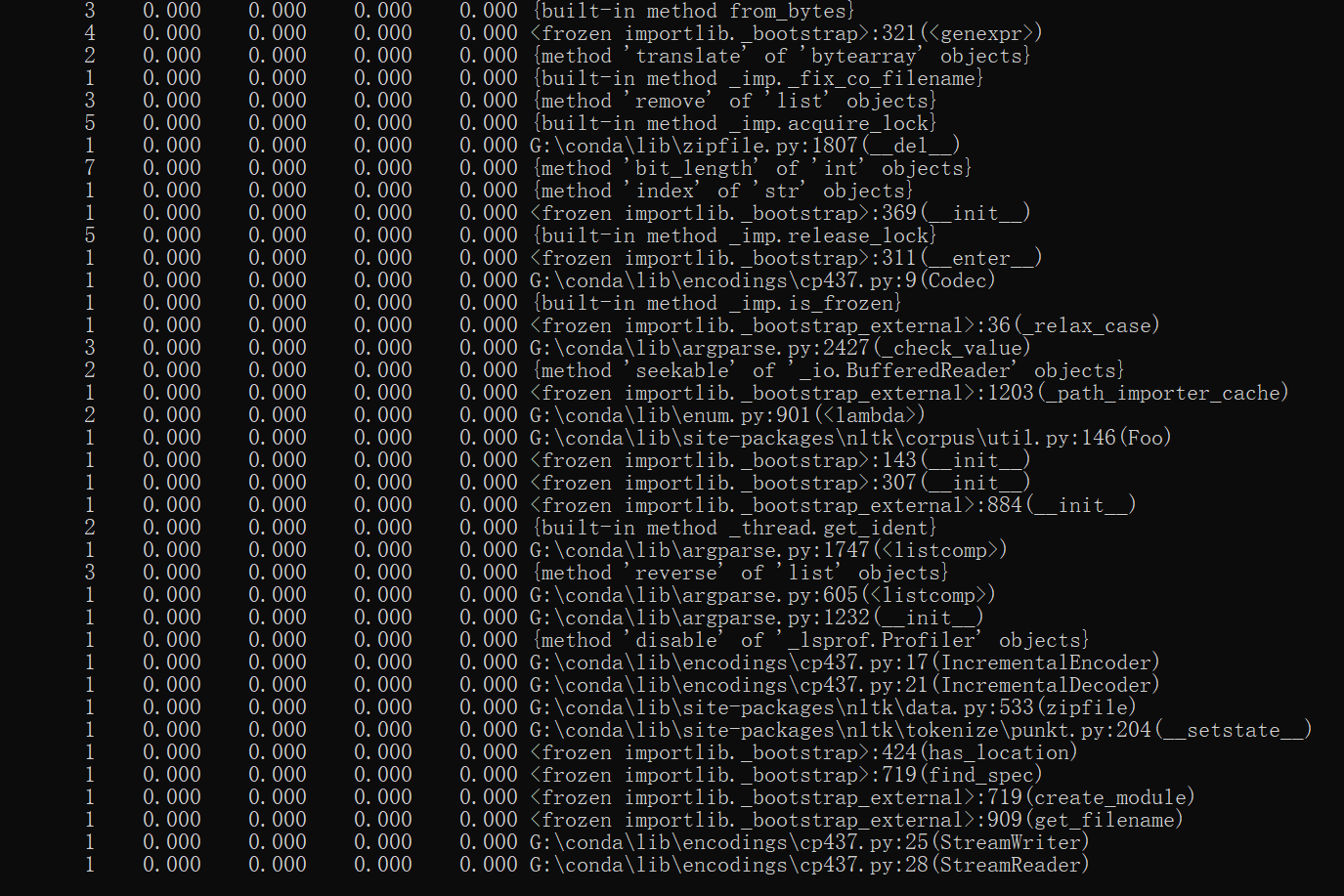
采用cProfile进行性能分析,情况如下图所示,花费时间为2h,在性能上,为了提高程序的健壮性,在代码中耗时最多的函数为calculate_similarity,平均调用耗时为0.716s,函数展示如下:
def calculate_similarity(text1, text2):
"""
计算两个文本之间的相似度。
参数:
text1 (str): 第一个要比较的文本。
text2 (str): 第二个要比较的文本。
返回:
float: 两个文本之间的相似度,范围从0(完全不同)到1(完全相同)。
"""
# 创建SequenceMatcher对象,用于比较两个文本
# None表示不使用过滤函数,text1和text2是要比较的文本
matcher = SequenceMatcher(None, text1, text2)
# 调用ratio()方法计算相似度比率
similarity = matcher.ratio()
return similarity # 返回计算出的相似度比率
PARSER.add_argument('--sample_text', type=str, required=True)添加了required=True,确保了用户必须提供这些参数,否则程序会报错并提示用户。
6.计算模块部分单元测试展示
单元测试代码
import unittest
from main import preprocess_text, calculate_similarity # 替换your_module_name为你的模块名
class TestTextProcessing(unittest.TestCase):
def test_preprocess_text(self):
sample_text = "This is a sample text. It includes some stopwords, such as the, and."
expected_output = "sample text includes stopwords" # 更新期望输出
self.assertEqual(preprocess_text(sample_text), expected_output)
def test_calculate_similarity(self):
# 测试计算相似度功能
text1 = "This is a test text."
text2 = "This is a test."
similarity_score = calculate_similarity(text1, text2)
# 相似度应该接近1,但不一定完全等于1,因为文本不完全相同
self.assertGreater(similarity_score, 0.8) # 调整期望值
# 测试两个完全不同的文本
text3 = "This is a completely different text."
similarity_score = calculate_similarity(text1, text3)
print("Preprocessed text1:", preprocess_text(text1))
print("Preprocessed text3:", preprocess_text(text3))
print("Similarity score:", similarity_score)
# 相似度应该接近0
self.assertLess(similarity_score, 0.7) # 调整期望值
if __name__ == '__main__':
unittest.main()
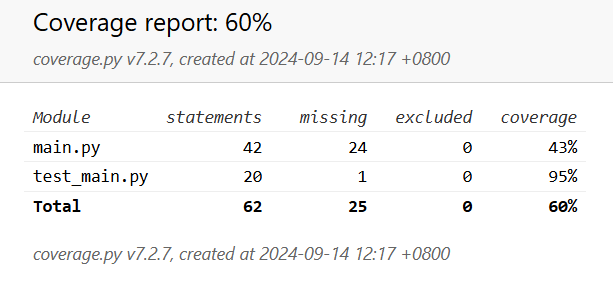
单元测试覆盖率如图所示。
7.计算模块部分异常处理说明
打开不存在的文件时的错误
单元测试样例
class TestFileNotFoundError(unittest.TestCase):
def test_nonexistent_file(self):
with self.assertRaises(FileNotFoundError):
main(['--sample_text', 'nonexistent.txt', '--reference_text', 'reference.txt', '--test_outcome', 'result.txt'])
if __name__ == '__main__':
unittest.main()
文件读写过程中发生的输入输出错误
单元测试样例
class TestIOError(unittest.TestCase):
def test_permission_denied(self):
with tempfile.NamedTemporaryFile(delete=False) as tmpfile:
filename = tmpfile.name
os.chmod(filename, 0o000) # 设置文件权限为不可读不可写
with self.assertRaises(IOError):
main(['--sample_text', filename, '--reference_text', 'reference.txt', '--test_outcome', 'result.txt'])
os.chmod(filename, 0o644) # 恢复文件权限
os.remove(filename)
if __name__ == '__main__':
unittest.main()
8.测试结果





 浙公网安备 33010602011771号
浙公网安备 33010602011771号