6月16日 Django作业 文件解压缩统计行数
作业要求:
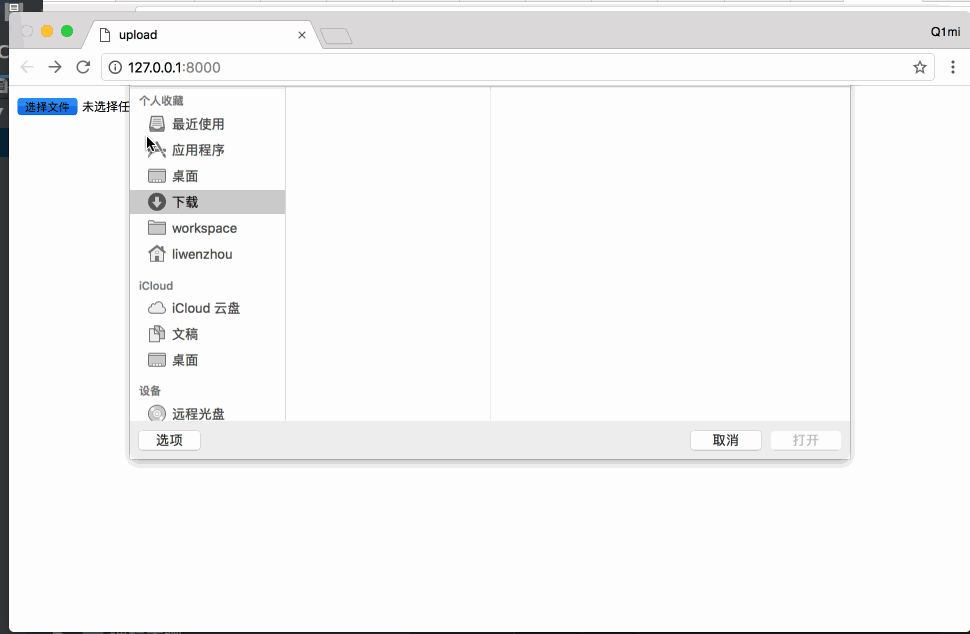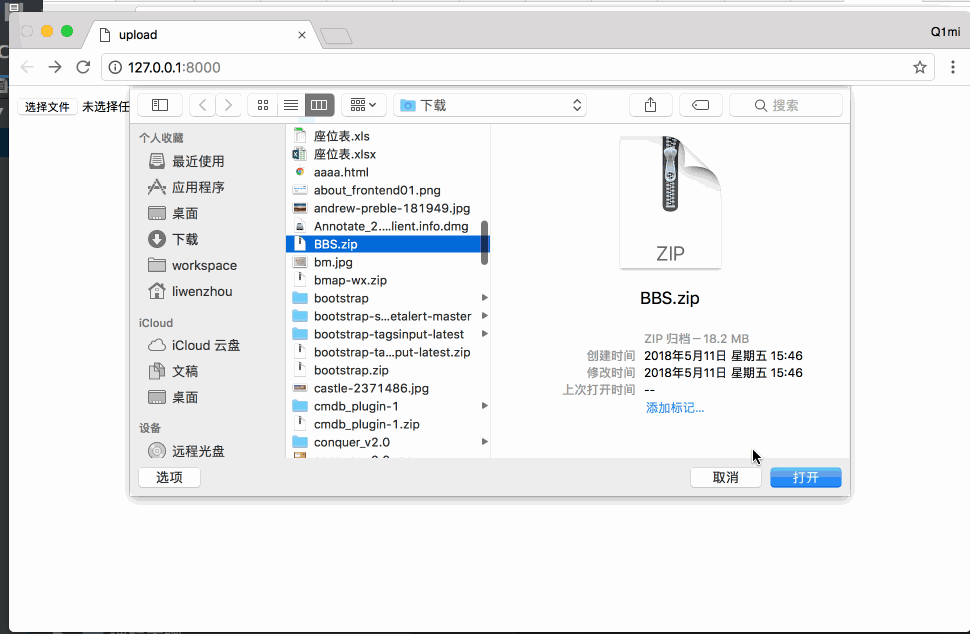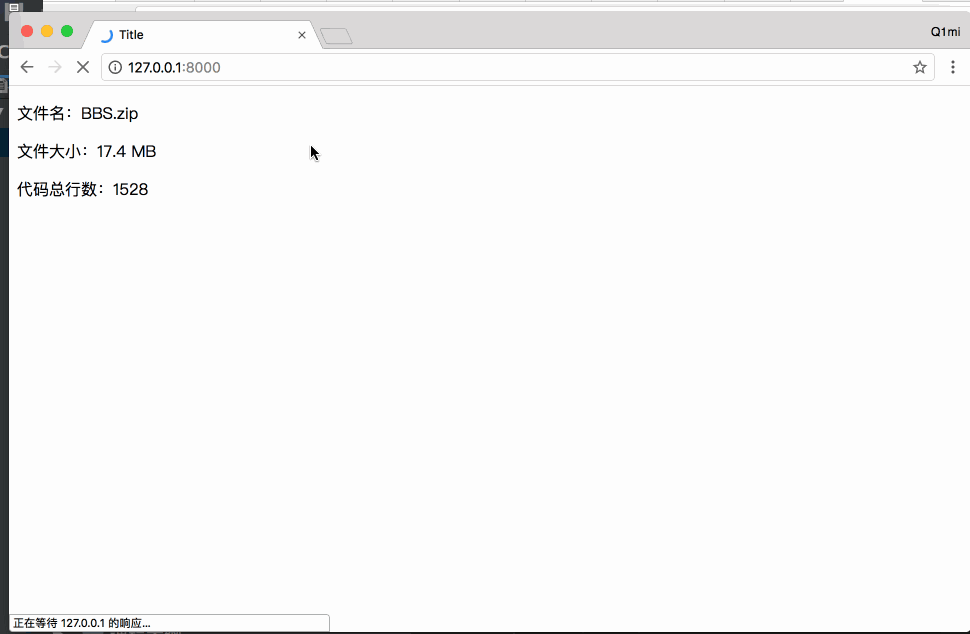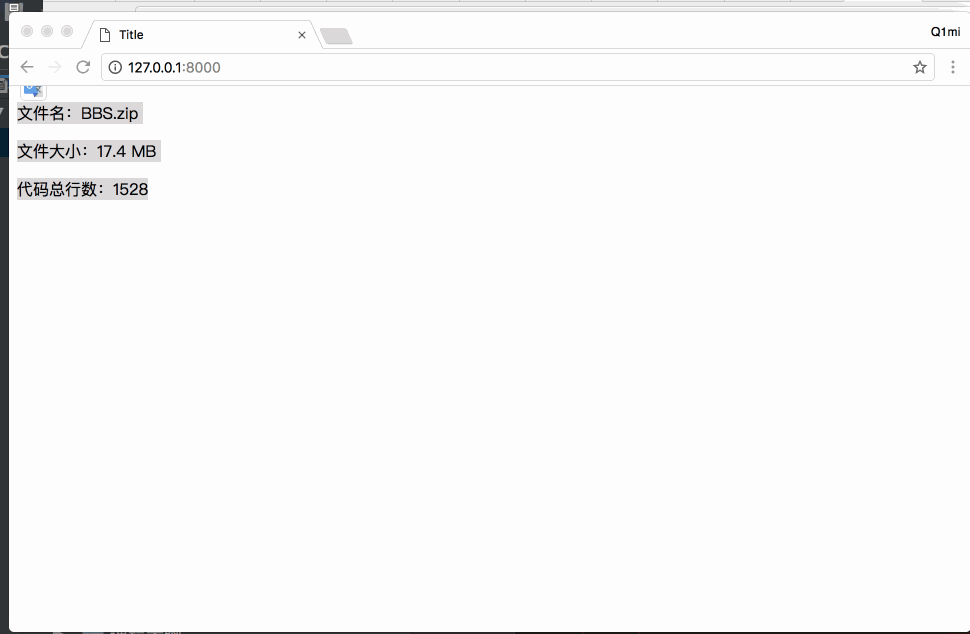
前端页面注意:
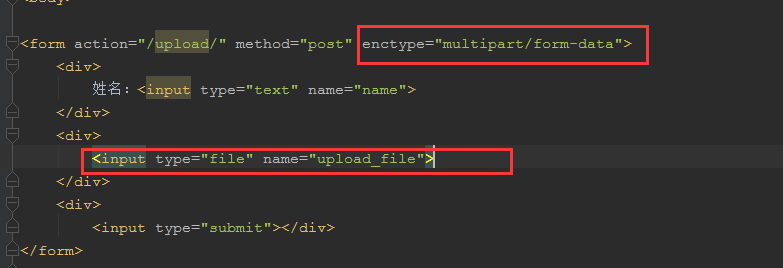
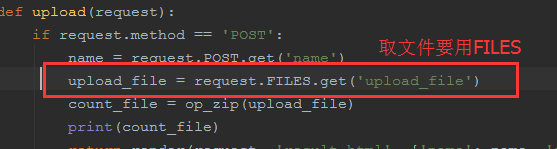
自己写的:
from django.shortcuts import render, HttpResponse import zipfile import re # Create your views here. def op_zip(zip_file): zfile = zipfile.ZipFile(zip_file, 'r') zfile_name_list = zfile.namelist() # zfile_name_list = list(filter(lambda x: re.findall('\.[a-z]+$', x), zfile_name_list)) # print(zfile_name_list) # html_files = filter(lambda x: x.endswith('.html'), zfile_name_list) # py_files = filter(lambda x: x.endswith('.py'), zfile_name_list) # css_files = filter(lambda x: x.endswith('.css'), zfile_name_list) # js_files = filter(lambda x: x.endswith('.js'), zfile_name_list) count_file = {'html': 0, 'py': 0, 'css': 0, 'js': 0} for file_name in zfile.namelist(): # if file_name.endswith('.zip'): # child_zip_file = zfile.getinfo(file_name) # print(zipfile.is_zipfile(file_name)) # # data = zfile.read(file_name) # print(data) # res = op_zip(child_zip_file) # for k in res: # count_file[k] += res[k] if file_name.endswith('.html'): data = zfile.read(file_name) data_list = data.decode('utf8').split('\r\n') zhu = 0 html_count = 0 for line in data_list: if line.startswith('//'): continue if line.startswith('<!--') or line.startswith('/*'): zhu += 1 if line.endswith('-->') or line.endswith('*/'): zhu -= 1 if zhu == 0: html_count += 1 count_file['html'] += html_count elif file_name.endswith('.py'): data = zfile.read(file_name) data_list = data.decode('utf8').split('\r\n') zhu = 0 py_count = 0 for line in data_list: if line.startswith('#'): continue if line.startswith("\'\'\'") or line.startswith('\"\"\"'): zhu += 1 if line.endswith("\'\'\'") or line.endswith('\"\"\"'): zhu -= 1 if zhu == 0 and line: py_count += 1 count_file['py'] = py_count elif file_name.endswith('.css'): data = zfile.read(file_name) data_list = data.decode('utf8').split('\r\n') zhu = 0 css_count = 0 for line in data_list: if line.startswith('//'): continue if line.startswith('/*'): zhu += 1 if line.endswith('*/'): zhu -= 1 if zhu == 0: css_count += 1 count_file['css'] += css_count elif file_name.endswith('.js'): data = zfile.read(file_name) data_list = data.decode('utf8').split('\r\n') zhu = 0 js_count = 0 for line in data_list: if line.startswith('//'): continue if line.startswith('/*'): zhu += 1 if line.endswith('*/'): zhu -= 1 if zhu == 0: js_count += 1 count_file['js'] += js_count print(count_file) return count_file def upload(request): if request.method == 'POST': name = request.POST.get('name') upload_file = request.FILES.get('upload_file') count_file = op_zip(upload_file) print(count_file) return render(request, 'result.html', {'name': name, 'result': count_file}) return render(request, 'upload.html')
存在的问题:
1、没有考虑到上传文件时,上传的文件类型是否是压缩包
2、只对zip类型的压缩包进行解压
3、忘记了shutil模块
4、过程中遇到的问题:
正则表达式几乎都忘记了,前端界面bootstrap用的也磕磕绊绊的 ,还是缺少练习
老师的答案:
from django.shortcuts import render, HttpResponse import shutil import os import uuid from django.conf import settings ACCEPT_FILE_TYPE = ["zip", "tar", "gztar", "rar"] # Create your views here. def upload(request): if request.method == "POST": # 拿到上传的文件对象 file_obj = request.FILES.get("code_file") # prefix:前缀 suffix:后缀 # 将上传文件的文件名字 从右边按 '.'切割(最多切一次) filename, suffix = file_obj.name.rsplit(".", maxsplit=1) # 如果上传的文件类型不是可接受的,就直接返回错误提示 if suffix not in ACCEPT_FILE_TYPE: return HttpResponse("上传文件必须是压缩文件") # 上传文件的类型正确 # 在项目的根目录下新建一个和上传文件同名的文件 with open(file_obj.name, "wb") as f: # 从上传文件对象一点一点读取数据 for chunk in file_obj.chunks(): # 将数据写入我新建的文件 f.write(chunk) # 拼接得到上传文件的全路径 real_file_path = os.path.join(settings.BASE_DIR, file_obj.name) # 对上传的文件做处理 upload_path = os.path.join(settings.BASE_DIR, "files", str(uuid.uuid4())) # 解压代码文件至指定文件夹 shutil.unpack_archive(real_file_path, extract_dir=upload_path) # 代码行数统计 total_num = 0 for (dir_path, dir_names, filenames) in os.walk(upload_path): # dir_path: 根目录 dir_names: 文件夹 filenames: 文件 # 遍历所有的文件 for filename in filenames: # 将文件名和根目录拼接成完整的路径 file_path = os.path.join(dir_path, filename) # 完整的路径按照'.' 进行右切割 (最大切割一次) file_path_list = file_path.rsplit(".", maxsplit=1) # 文件没有后缀名直接跳过 if len(file_path_list) != 2: continue # 如果不是py文件直接跳过 if file_path_list[1] != "py": continue # 初始化一个存放当前文件代码行数的变量 line_num = 0 with open(file_path, "r", encoding="utf8") as f: # 一行一行读取 for line in f: # 如果是注释就跳过 if line.strip().startswith("#"): continue # 否则代码行数+1 line_num += 1 total_num += line_num return render( request, "show.html", {"file_name": file_obj.name, "file_size": file_obj.size, "total_num": total_num, "value": "张曌"}) return render(request, "upload.html")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号