react面试核心知识总结
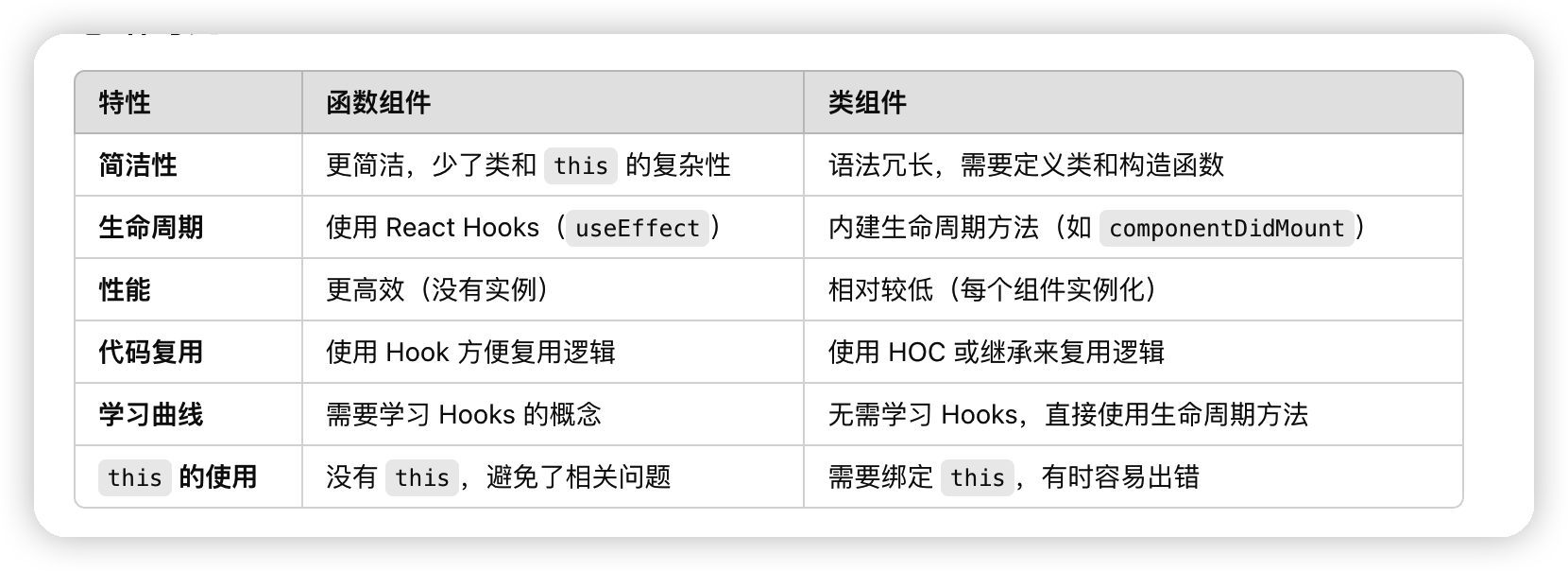
类组件和函数组件的比较
一、React Hook
Hook 是 React 16.8 的新增特性。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性。
1.要解决什么问题?
- 可以在函数组件中使用状态、模拟组件的生命周期
- 可以复用组件状态及相关的变更逻辑。
不要在循环,条件或嵌套函数中调用 Hook, 确保总是在你的 React 函数的最顶层以及任何 return 之前调用他们。遵守这条规则,你就能确保 Hook 在每一次渲染中都按照同样的顺序被调用。这让 React 能够在多次的 useState 和 useEffect 调用之间保持 hook 状态的正确。
这样做的原因是因为: React 靠的是 Hook 调用的顺序来确定state应该和哪个useState对应,因此Hook 的调用顺序在多次渲染之间应保持一致。
3.底层核心原理
React Hook 的实现依赖于 React Fiber 架构,Fiber 架构为每个组件实例分配了一个独立的 Fiber 节点,每个节点都是一个对象,组件所有的hook存储在对象的memoizedState属性中, 该属性指向当前组件实例的第1个Hook 对象
每个hook对象,通常包含以下信息:
memoizedState:存储最新的局部状态,useState的state值|useEffect的deps对象 |useMemo的缓存值和deps|useRef的ref对象。baseState: 用于 useReducer,存储初始 state
baseQueue: 用于 useReducer,存储更新队列
next:指向下一个 Hook 的引用
queue:需要更新的队列,如果queue.pending之前有多个setState,多个update会形成一个环形链表,以确保按顺序执行
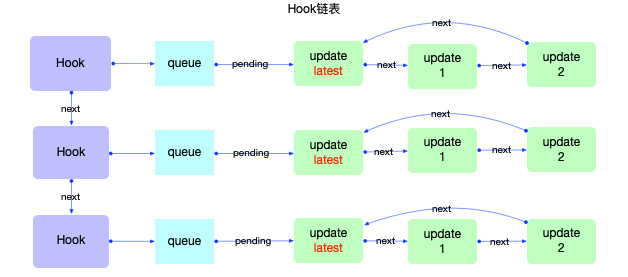
这些hook对象组成了一个单向链表,那么memoizedState的初始值是何时产生的呢?
- hooks初始化
react使用renderWithHooks来调用函数组件,在组件首次渲染 (mount) 时,React并不知道有多少hooks,因此一边执行一边收集组件内所有的Hook,并存储到 memoizedState 链表中,以下面的例子展示一下过程:
function Counter() {
const [count, setCount] = useState(0);
const [name, setName] = useState("React");
useEffect(() => {
console.log("副作用");
}, []);
return <div>{count} - {name}</div>;
}
React 内部执行流程
- React 触发组件渲染(执行
Counter())。 - 组件中的
useState/useEffect被调用:useState(0)-> 触发mountWorkInProgressHook(),创建第一个 Hook。useState("React")-> 触发mountWorkInProgressHook(),创建第二个 Hook,链接到next。useEffect()-> 触发mountWorkInProgressHook(),创建第三个 Hook,链接到next。
mountWorkInProgressHook函数每次被执行,都产生一个hook对象,里面保存了当前hook信息,然后将每个hooks以链表形式串联起来,并赋值给workInProgress的memoizedState关键源码如下:
function mountWorkInProgressHook() {
const hook = {
memoizedState: null, // 该 Hook 的状态
next: null // 指向下一个 Hook
};
if (workInProgressHook === null) {
// 这是组件的第一个 Hook,存入 Fiber 节点的 memoizedState
currentlyRenderingFiber.memoizedState = hook;
} else {
// 不是第一个 Hook,则链接到前一个 Hook 的 next
workInProgressHook.next = hook;
}
// 更新当前执行的 Hook 指针
workInProgressHook = hook;
return hook;
}
最终,React 会创建一个 memoizedState 链表,记录所有 Hook:
fiber.memoizedState = {
memoizedState: 0, // useState(0)
next: {
memoizedState: "React", // useState("React")
next: {
memoizedState: { /* useEffect数据 */ },
next: null
}
}
};
- hooks更新
以useState进行说明,首先,我们来看 useState 内部存储的 Hook 结构:
const hook = {
memoizedState: currentState, // 当前状态值
queue: { // 维护 state 更新队列
pending: null // 存储等待更新的状态
},
next: null // 指向下一个 Hook(单向链表)
};
假设有一个const [count,setCount] = useState(0)的代码;当 setCount(x) 执行时:
step1: React 内部会创建一个更新对象:
const update = {
action: (prevState) => prevState + 1, // 计算新状态的方法
next: null // 指向下一个更新(如果有多个 setState)
};
step2: React 将 update 加入 queue.pending,形成循环链表
const queue = hook.queue;
if (queue.pending === null) {
update.next = update; // 只有一个更新时,形成环
} else {
update.next = queue.pending.next;
queue.pending.next = update;
}
queue.pending = update;
step3: React 调用 scheduleUpdateOnFiber(workInProgress) ,该函数负责标记当前组件 Fiber 节点需要更新,并触发 React 的调度更新流程
step4: renderWithHooks 计算新的 state 并创建新的 Fiber 树
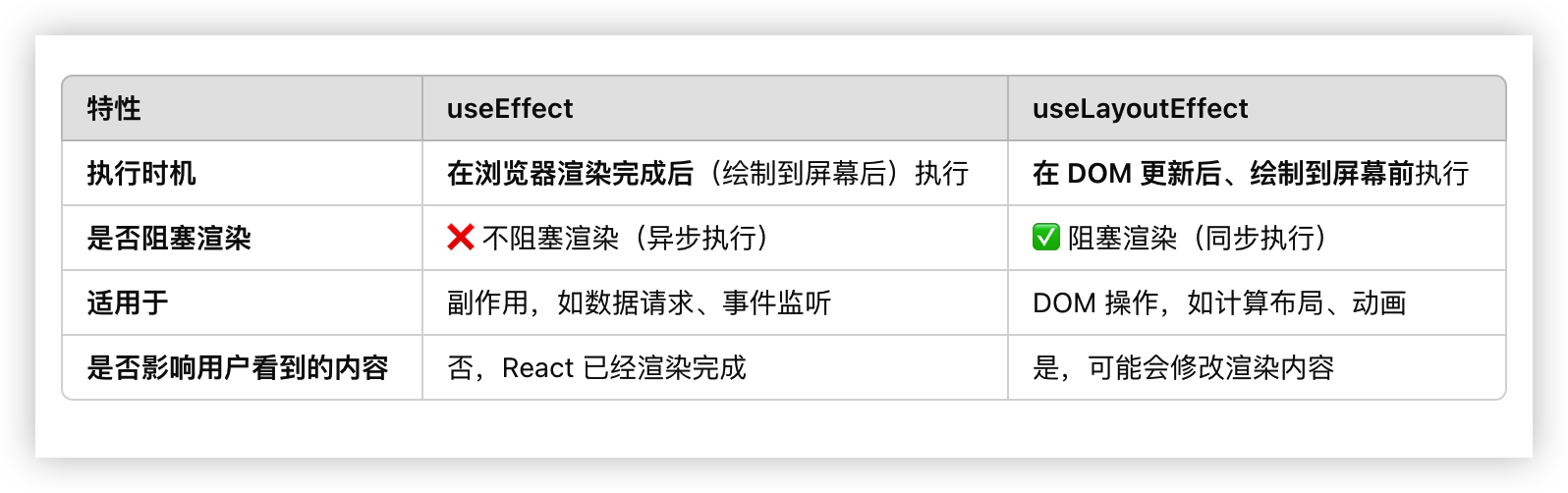
4. useEffect和useLayout的区别
| 场景 | 更新方式 |
| React 事件处理函数(俗称合成事件) | 异步 |
| 生命周期函数(useEffect也是) | 异步 |
| 原生 JavaScript 事件处理函数 | 同步 |
setTimeout、setInterval 回调函数 |
同步 |
Promise 的 then 回调函数(需要特别注意) |
同步 |
一些注意事项:
- 当你的状态更新依赖于之前的状态时,应该使用函数式更新(react会把最新的状态传进来):
function FunctionalUpdateExample() {
const [count, setCount] = useState(0);
const handleClick = () => {
//可能产生bug:由于 setState 的异步行为,直接使用 count + 1 可能会导致状态更新不正确
setCount(count + 1);
//正确
setCount((prevCount) => prevCount + 1);
};
console.log('render', count);
return (
<div>
<p>Count: {count}</p>
<button onClick={handleClick}>Increment</button>
</div>
);
}
- 多次更新同一个
State会自动合并为一个
const [count, setCount] = useState(0);
const handleClick = () => {
setCount(count + 1);
setCount(count + 1);
setCount(count + 1);
};
在上述代码中,React 会合并多个 setCount 调用,确保只进行一次渲染,而不是三次。
react18之前,仅复合事件和生命周期支持,js原生事件方式、异步(setTimeout/setInterval、promise)都不会自动合并. react18支持了所有的方式
- 集中处理state的更新
state,React 会集中在一次渲染中一起处理,而不会触发多次重新渲染。import React, { useState } from "react";
export default function App() {
const [count, setCount] = useState(0);
const [text, setText] = useState("Hello");
const handleClick = () => {
setCount(count + 1);
setText("World");
console.log("Before render:", count, text); // 可能还是旧值
};
return (
<div>
<p>Count: {count}</p>
<p>Text: {text}</p>
<button onClick={handleClick}>Update</button>
</div>
);
}
react18之前,仅复合事件和生命周期支持,js原生事件方式、异步(setTimeout/setInterval、promise)都不会自动合并. react18支持了所有的方式
使用浅比较判断各个依赖项是否发生了变化,对于基本类型(如 string、number、boolean),只比较值本身;对于引用类型(如对象、数组、函数),只比较引用是否相同(即内存地址),而不比较内容是否发生了变化。
注意的点:
- 所有依赖项都必须声明,如果在依赖项数组中漏掉了某些值,可能会导致闭包问题、结果还是上次的,从而引发意料之外的行为
- 使用常量依赖没有意义,因为常量不会改变
- 如果依赖项数组中有复杂的对象或函数,可能导致不必要的重计算或重新创建(应该使用useRef来存储复杂变量)
启用const obj = { key: 'value' }; const memoizedValue = useMemo(() => doSomething(obj), [obj]); // 组件函数每次被执行时,obj每次都是新引用,导致重计算 // 改进 const stableObj = useRef({ key: 'value' }); const memoizedValue = useMemo(() => doSomething(stableObj.current), []);eslint-plugin-react-hooks插件。它可以帮助你检查依赖项是否完整和正确
React16之前组件更新是一个递归的过程,深度优先遍历整个组件树,所有工作必须在单一的渲染周期中完成,这可能导致卡顿、丢帧等性能问题,React Fiber 是 React 的一个重写的核心算法,用来处理渲染过程中的调度和更新。它是 React 16 版本引入的重要改进,旨在提升 React 在大型应用中的性能,尤其是在复杂 UI 更新、动画和高频更新场景。
fiber算法将渲染任务分割成一个个小单元,并指定优先级,当有更高优先级的任务(如用户输入)需要处理时,React 可以暂停当前任务,先去执行高优先级任务,然后在合适的时机恢复之前未完成的渲染任务。
为了实现这种细粒度的任务控制,Fiber 架构引入了以下几个关键机制:
(1)Fiber 节点
- 每个 React 组件实例对应一个 Fiber 节点。Fiber 节点是一个 JavaScript 对象,用于描述组件的类型、状态、子节点等信息。
- 在组件更新过程中,每个组件对应的 Fiber 节点可以存储其状态和更新内容,以便在重新渲染时可以直接访问并更新。
(2)双缓存树结构(Current 和 WorkInProgress)
- React Fiber 使用双缓存树来管理渲染工作。它分为
current tree和workInProgress tree,即当前树和工作树。 current tree表示当前屏幕上展示的 UI 状态,而workInProgress tree是新的更新任务的工作空间。- 在渲染的过程中,React 会在
workInProgress tree上构建新的 UI 状态,更新完成后会将其替换成current tree,从而完成一次更新。
(3)任务的中断与恢复
- Fiber 使用 JavaScript 的
requestIdleCallback或scheduler来实现任务中断,使得更新任务可以分批执行。 - 这种机制确保在渲染任务被打断后,React 可以从中断的地方恢复,继续执行未完成的任务。
(4)任务优先级调度
- 每个任务都会被分配一个优先级,React 会根据优先级来调度任务,确保高优先级任务在低优先级任务之前完成。
- Fiber 支持多种优先级策略,内部的优先级策略大体如下:
Immediate(同步)优先级:比如事件处理,setState 发生在事件回调中,立即执行。
User Blocking 优先级:比如交互性较强的输入(如文本输入),需要尽快响应,但可以打断。
Normal(默认)优先级:大部分更新,比如组件挂载、数据请求后更新等。
Low 优先级:非关键的后台任务,比如渲染不在视口中的组件。
Idle 优先级:最低级,比如不紧急的预渲染、数据预加载等。
- 在react18以前,没有提供相关的api给用户,从18版本开始,开发者可以手动控制优先级
1. Concurrent Mode : React 会自动根据更新的类型来分配优先级。你只需在渲染根组件时启用 Concurrent Mode 即可:
import ReactDOM from 'react-dom';
import App from './App';
ReactDOM.createRoot(document.getElementById('root')).render(<App />);
注意:React 18 之后默认开启了 Concurrent Mode,使用 ReactDOM.createRoot 即可
2.使用 useTransition 和 startTransition(降低任务的优先级)
useTransition 和 startTransition 是 React 18 引入的 API,允许我们手动设置更新的优先级。startTransition 和 useTransition 通常用于较低优先级的任务,例如加载数据等不影响用户操作的任务。
useTransition
useTransition 是一个 React Hook,返回一个布尔值 isPending 和一个 startTransition 函数。
import { useState, useTransition } from 'react';
function Example() {
const [isPending, startTransition] = useTransition();
const [value, setValue] = useState(0);
const handleClick = () => {
startTransition(() => {
setValue((v) => v + 1);
});
};
return (
<div>
<button onClick={handleClick}>Increment</button>
{isPending ? <p>Updating...</p> : <p>Value: {value}</p>}
</div>
);
}
在上述例子中,handleClick 函数中的 setValue 被包裹在 startTransition 中,表示这是一个低优先级的任务。即使用户频繁点击按钮,React 也会优先渲染其他高优先级的任务,而把这个更新安排在后面。
startTransition
import { startTransition } from 'react';
function handleClick() {
startTransition(() => {
// 放入低优先级更新
setValue((v) => v + 1);
});
}
1. 父组件传递给子组件的属性值是对象、函数时,不要使用内联模式,不然父组件每次render,即使属性值没发生变化,都会导致子组件渲染。
2. 函数组件的优化
- 组件内部如果涉及到复杂耗时的数据计算,可以使用useMemo来缓存计算结果
- 若内部有子组件,并且子组件需要接收函数做为属性值的话,此时父组件中的回调函数需要使用useCallback函数,不然会导致子组件的渲染优化判断机制失败。
- 使用React.memo(fnComponent)这个高阶组件来做记忆函数,当props不变时,直接复用上一次的渲染结果。对props的比较是浅比较,可以自己实现比较逻辑,文档说明
3. class组件非必要情况下,不要使用state;可以在shouldComponentUpdate里判断props或state是否发生了改变,或者继承自PureComponent
const Foo = React.lazy(() => import('../componets/Foo));
React.lazy不能单独使用,需要配合React.suspense,suspence是用来包裹异步组件,添加loading效果等。
<React.Suspense fallback={<div>loading...</div>}>
<Foo/>
</React.Suspense>
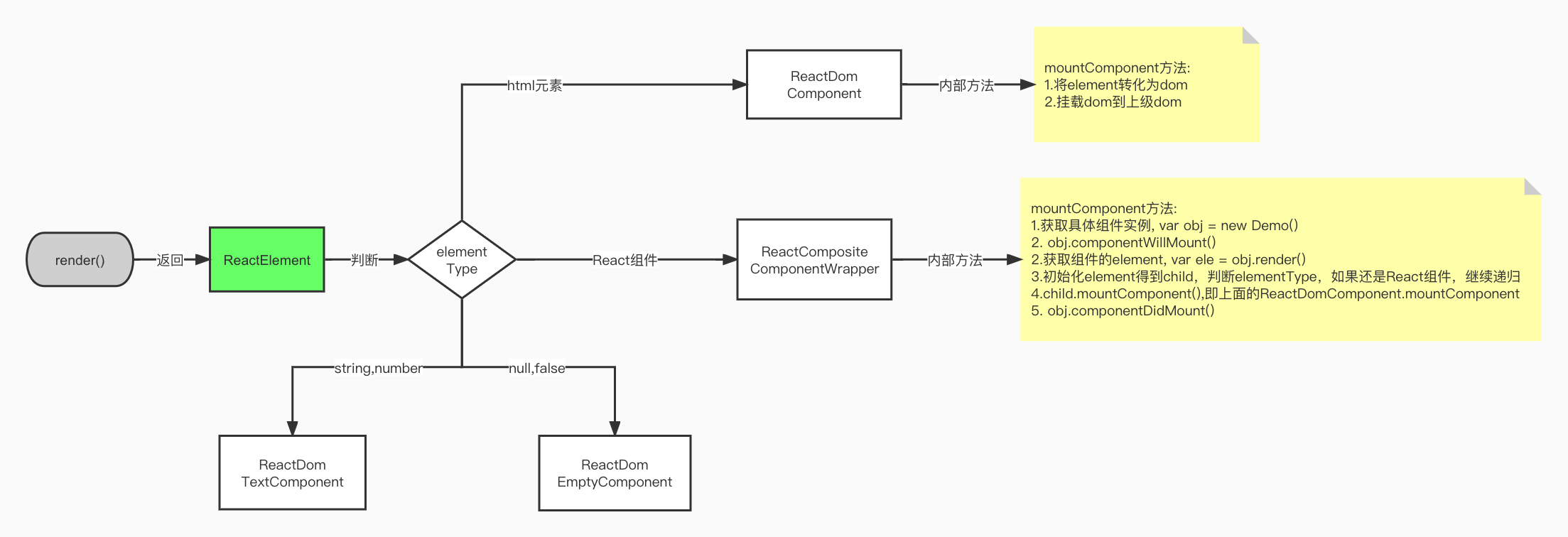
六、渲染原理
七、React17、18有哪些新特性
react17没功能上的更新,主要为后续版本升级做了一些铺垫.
- jsx中不再需要import React from 'react'; 为了实现该特性,需要支持新转换的工具链(如 Babel 7.9+ 或 TypeScript 4.1+)
- React 17 优化了开发环境中的错误信息,使堆栈追踪更清晰、更有上下文
- React 事件系统被重写,避免事件绑定到
document,而是直接绑定到 React 渲染树的根节点。
在 React 16 及更早版本中,React 使用事件委托(Event Delegation),即:
所有事件不会直接绑定到 DOM 元素,
而是统一绑定到 document 上,然后在事件冒泡阶段处理它们
document.addEventListener('click', function(event) {
// React 事件监听器在 document 上处理
});
- 在 React 17 及以后,事件绑定不再挂载到document上,而是挂载到 React 渲染树的根节点。
// React 17+ 的事件绑定示例 const root = document.getElementById("root"); // React 根节点 root.addEventListener("click", function(event) { // 事件监听器绑定到 root,而不是 document });
-
- 允许在同一应用中同时使用多个 React 版本
react18的主要在并发渲染方面做了一些更新:
- Concurrent Rendering(并发渲染): React 18 默认启用了并发渲染,它不会阻塞主线程,从而使应用更具响应性。
- 自动批处理(Automatic Batching): React 18 会将多个状态更新自动批处理,从而减少渲染次数
function handleClick() { setCount((c) => c + 1); setFlag((f) => !f); // React 18 中只会触发一次渲染,而不是两次。 } -
开发者声明低优先级任务(
useTransition)、延迟更新值(useDeferredValue) - React 18 引入了新的根 API(
createRoot和hydrateRoot):createRoot是为了支持并发渲染,hydrateRoot则用于支持 SSR 的改进 - ssr的改进:1. 增加了流式渲染,支持以流的方式将 HTML 发送到客户端,提升首屏加载性能 2.
<Suspense>支持服务端渲染(SSR)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号