Mahout之(二)协同过滤推荐
协同过滤 —— Collaborative Filtering
协同过滤简单来说就是根据目标用户的行为特征,为他发现一个兴趣相投、拥有共同经验的群体,然后根据群体的喜好来为目标用户过滤可能感兴趣的内容。
协同过滤推荐 —— Collaborative Filtering Recommend
协同过滤推荐是基于一组喜好相同的用户进行推荐。它是基于这样的一种假设:为一用户找到他真正感兴趣的内容的最好方法是首先找到与此用户有相似喜好的其他用户,然后将他们所喜好的内容推荐给用户。这与现实生活中的“口碑传播(word-of-mouth)”颇为类似。
协同过滤推荐分为三类:
· 基于用户的推荐(User-based Recommendation)
· 基于项目的推荐(Item-based Recommendation)
· 基于模型的推荐(Model-based Recommendation)
基于用户的协同过滤推荐 —— User CF
原理:基于用户对物品的喜好找到相似邻居用户,然后将邻居用户喜欢的物品推荐给目标用户

上图示意出User CF的基本原理,假设用户A喜欢物品A和物品C,用户B喜欢物品B,用户C喜欢物品A、物品C和物品D;从这些用户的历史喜好信息中,我们可以发现用户A和用户C的口味和偏好是比较类似的,同时用户C还喜欢物品D,那么我们可以推断用户A可能也喜欢物品D,因此可以将物品D推荐给用户A。
实现:将一个用户对所有物品的偏好作为一个向量(Vector)来计算用户之间的相似度,找到K-邻居后,根据邻居的相似度权重以及他们对物品的喜好,为目标用户生成一个排序的物品列表作为推荐,列表里面都是目标用户为涉及的物品。
基于物品的协同过滤推荐 —— Item CF
原理:基于用户对物品的喜好找到相似的物品,然后根据用户的历史喜好,推荐相似的物品给目标用户。与User CF类似,只是关注的视角变成了Item。
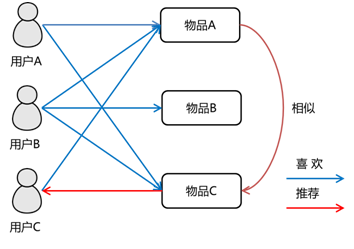
假设用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,从这些用户的历史喜好可以分析出物品A和物品C是比较类似的,喜欢物品A的人都喜欢物品C,基于这个数据可以推断用户C 很有可能也喜欢物品C,所以系统会将物品C推荐给用户C。
实现:将所有用户对某一个物品的喜好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的喜好预测目标用户还没有涉及的物品,计算得到一个排序的物品列表作为推荐。
相似度的计算 —— Similarity Metrics Computing
关于相似度的计算,现有的几种基本方法都是基于向量(Vector)的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐的场景中,在用户 - 物品偏好的二维矩阵中,我们可以将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度。下面我们详细介绍几种常用的相似度计算方法:
· 欧几里德距离(Euclidean Distance)
最初用于计算欧几里德空间中两个点的距离,假设 x,y 是 n 维空间的两个点,它们之间的欧几里德距离是:
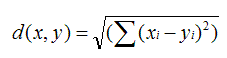
可以看出,当 n=2 时,欧几里德距离就是平面上两个点的距离。
当用欧几里德距离表示相似度,一般采用以下公式进行转换:距离越小,相似度越大
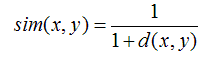
· 皮尔森相关系数(Pearson Correlation Coefficient)
皮尔森相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值在 [-1,+1] 之间。

· Cosine 相似度(Cosine Similarity)
Cosine 相似度被广泛应用于计算文档数据的相似度:

相似邻居的计算
邻居就是上文说到的“兴趣相投、拥有共同经验的群体”,在协同过滤中,邻居的计算对于推荐数据的生成是至关重要的,常用的划分邻居的方法有两类:
· 固定数量的邻居:K-neighborhoods 或者 Fix-size neighborhoods
用“最近”的K个用户或物品最为邻居。如下图中的 A,假设要计算点 1 的 5- 邻居,那么根据点之间的距离,我们取最近的 5 个点,分别是点 2,点 3,点 4,点 7 和点 5。但很明显我们可以看出,这种方法对于孤立点的计算效果不好,因为要取固定个数的邻居,当它附近没有足够多比较相似的点,就被迫取一些不太相似的点作为邻居,这样就影响了邻居相似的程度,比如图 1 中,点 1 和点 5 其实并不是很相似。
· 基于相似度门槛的邻居:Threshold-based neighborhoods
与计算固定数量的邻居的原则不同,基于相似度门槛的邻居计算是对邻居的远近进行最大值的限制,落在以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,这种方法计算得到的邻居个数不确定,但相似度不会出现较大的误差。如下图中的 B,从点 1 出发,计算相似度在 K 内的邻居,得到点 2,点 3,点 4 和点 7,这种方法计算出的邻居的相似度程度比前一种优,尤其是对孤立点的处理。

Threshold-based neighborhoods要表现的就是“宁缺勿滥”,在数据稀疏的情况下效果是非常明显的。Mahout对这两类邻居的计算给出了自己的实现,分别是NearestNUserNeighborhood和ThresholdUserNeighborhood,从名字就可以看出它们的对应关系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号