20180918-1 词频统计
20180918-1 词频统计
1.项目分析及效果展示
项目说明,本次项目使用了Python作为开发语言,该语言较为简易灵活,对多平台的支持较好。
- 开发环境是 macOS High Sierra
- 开发工具是 pycharm
- Python语言版本为 3.7
- 版本控制选用 Git
1.1 功能一
要求:小文件输入。通过程序统计文件中单词的总量total,并统计各个单词出现的频率,total一项中相同的单词不重复计数数,重复出现的单词记为1次。
1.1.1 功能一重点、难点
文件读取:由于该项目对输入有要求,首先要解决的就是文件读取的问题,要以读文件的模式打开一个文件对象,使用Python内置的open()函数,传入文件名和标示符即可。代码如下:
1 # 通过with open as 方法读取文件内容 2 with open(inputText, encoding="UTF-8") as textFile: 3 inputText = textFile.read()
词频统计:在本次项目中对于词频统计的思路是先将文本中的特殊符号通过replace()方法使用空格替换掉,这里需要注意,替换方法不是唯一的,也可以使用正则表达式进行替换,但是笔者认为正则表达式不如按需要去除灵活,故没有选择。然后使用Python中的split()方法通过空格分隔每个单词,最后将分割好的单词通过字典类型进行存储并统计。统计时需要注意大小写问题,例如:‘A’和‘a’是同一个单词,这样就要先将文本中的英文单词使用lower()方法换成小写后统计。代码如下:
1 # inputText存储了文本内容 2 inputText = inputText.lower() 3 4 # 通过replace方法将特殊字符转换为空格 5 for disCh in '!.",)—(#:\n': 6 inputText = inputText.replace(disCh, ' ') 7 8 # 定义词频字典 9 frequencyDic = {} 10 11 # 循环统计 12 for word in inputText.split(): 13 if word in frequencyDic: 14 frequencyDic[word] += 1 15 else: 16 frequencyDic[word] = 1 17 18 # 根据字典的value值排序 19 frequencyDic = sorted(frequencyDic.items(), key = lambda x: x[1], reverse = True)
命令行参数:该项目要求通过控制台使用命令行参数运行,Python代码无法直接在控制台运行,我所使用的方法是将Python文件转换成exe格式的文件。但是此时会产生一个问题,在Python文件中所写的input()方法接受不到命令行参数,因此我的解决方法是通过mian()函数中的argv参数进行接收。代码如下:
1 # 定义main()方法,对操作进行分类 2 def main(argv): 3 4 # 功能一,读小文件 5 if sys.argv[1] == '-s': 6 getCount(sys.argv[2]) 7 8 # 功能三,读取文件夹中的文件 9 elif os.path.isdir(sys.argv[1]): 10 findAndCount(sys.argv[1]) 11 12 # 功能二 13 else: 14 getCount(sys.argv[1]) 15 16 # 程序入口 17 if __name__ == "__main__": 18 main(sys.argv[1:])
1.1.2 效果展示
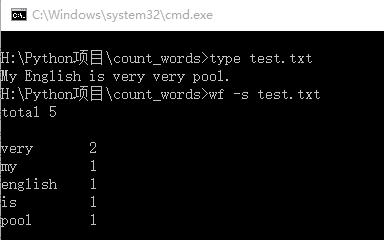
通过type命令可以查看到test.txt文件中的内容,程序名为wf,然后通过-s参数来执行功能一,效果如下图所示:
1.2 功能二
要求:支持命令行输入英文作品的文件名。
1.2.1 功能二重点、难点
对参数的判断:功能二在格式上要求输入的参数不带.txt后缀,因此在输入路径时,要将文件名补充完整。这里我认为我有创新点,我通过布尔类型的变量theNameHasSuffix来标识文件是否带有后缀,在下方法复用中会有帮助,代码如下:
1 # 通过该变量标记文件是否带后缀 2 theNameHasSuffix = True 3 4 # 添加后缀,转换标记的真假 5 if '.txt' not in inputText: 6 inputText = inputText + '.txt' 7 theNameHasSuffix = False
1.2.2 功能二创新点
统计方法的复用:功能二所完成的事情与功能一类似,可以考虑功能的复用,需要注意两点,一点是文件路径,如上文所说的需添加后缀;第二点是输出格式的改变,这里利用了之前所设立的theNameHasSuffix变量来标记,当theNameHasSuffix为False时说明方法正在执行功能二,这时要按照功能二的格式进行输出。代码如下所示:
1 # 输出单词总量 2 print('total', len(frequencyDic), end='') 3 4 # 如果没有后缀就按照功能二的格式输出 5 if not theNameHasSuffix: 6 print(' words', end='') 7 print('\n')
1.2.3 效果展示
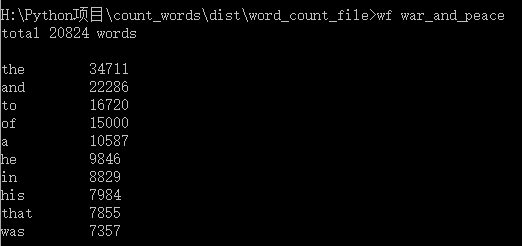
下图是《The Dead Return》这篇课文的词频统计结果

1.3 功能三
1.3.1 功能三重点、难点
判断是否为文件夹:由于在命令行中接受参数的不确定性,我们在调用函数时要先判断输入的路径是否为文件夹,这时要用到os.path.isdir()方法,如果参数对象是文件夹则返回True。代码如下:
1 if sys.argv[1] == '-s': 2 getCount(sys.argv[2]) 3 4 # 如果是文件夹则执行多文件查找方法,统计文件夹下所有的文件 5 elif os.path.isdir(sys.argv[1]): 6 findAndCount(sys.argv[1]) 7 else: 8 getCount(sys.argv[1])
导入文件夹下所有文件:该功能要求通过文件夹名来遍历文件夹下所有文件,因此要通过文件夹路径来循环统计每个文件,这时需要通过os.listdir()方法和os.path.join()方法,前者遍历文件夹,后者提取文件夹下的文件。具体代码如下:
1 # 查找目录下文件 2 def findAndCount(filePath): 3 4 # 遍历文件夹 5 fs = os.listdir(filePath) 6 7 # 循环提取文件夹下的文件 8 for f1 in fs: 9 10 # 提取文件 11 tmp_path = os.path.join(filePath, f1) 12 13 # 判断是否是文件 14 if os.path.isfile(tmp_path): 15 multifileCount(tmp_path) 16 else: 17 print("The file path has error!")
1.3.2 功能三的创新点
在功能三的输出格式要求中,有输出文件名的一项,文件遍历时会在子文件的路径中显示全部的路径信息,因此需要去掉前面的路径及文件后缀。例如:《War and Pace》文件的路径是“folder/war_and_pace.txt”。显然去除“.txt”很容易办到,但是文件前面的路径不确定是几层也可能是“c:/file/folder/”因此我使用的办法是从后向前遍历,遇到“.”则说明后缀已经遍历过了,接下来存储文件名称,直到遇到“/”则表示文件名遍历结束,此时结束循环。代码如下:
1 # 纯文件名 2 purName = '' 3 4 # 逆序遍历 5 for ch in txtName[::-1]: 6 7 # 后缀遍历结束,直接下一层循环记录文件名 8 if ch == '.': 9 10 # 通过该变量表示是否开始记录文件名 11 theCharIsName = True 12 continue 13 14 # 文件名遍历结束,结束循环 15 if ch == '/': 16 break 17 18 # 开始逆序记录文件名 19 if theCharIsName: 20 purName = purName + ch 21 22 # 由于文件名是逆序存储的,需要逆序打印 23 for ch in purName[::-1]: 24 print(ch, end='') 25 print()
1.3.3 效果展示
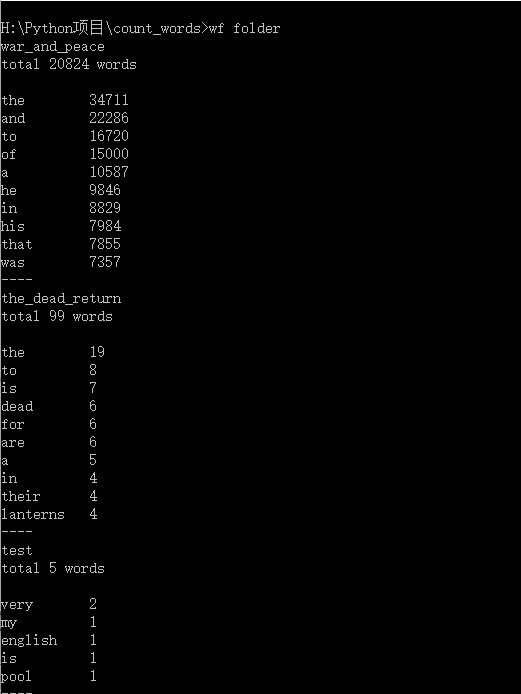
通过文件夹名称将文件夹中的文件遍历并统计词频,统计结果依次是:文件名,单词总数,出现频率前十的单词及次数。并由规定的结果“----”做分割。效果如下:
1.4 功能四
要求:从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
1.4.1 功能三重点、难点
重定向:首先要将功能一与功能四进行区分,这里通过对控制台参数的数量进行判断,具体方法为判断len(sys.argv)是否等于3,若等于3则执行功能一,否则执行功能四。
其次,将控制台的内容重定向到代码中处理,具体方法是通过sys.stdin.read(),然后通过之前写好的代码对文本进行统计。具体代码如下
1 if sys.argv[1] == '-s': 2 3 # 若参数的长度为3则执行功能一,否则执行功能四 4 if (len(sys.argv) == 3): 5 getCount(sys.argv[2]) 6 else: 7 8 # 通过重定向将文本读入 9 redirect_words = sys.stdin.read() 10 getCountByPurText(redirect_words)
1.4.2 效果展示
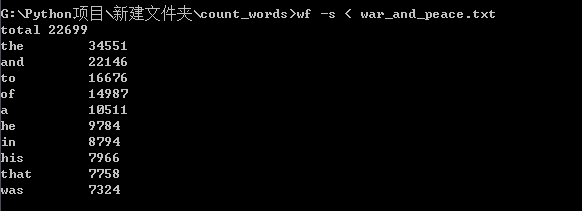
按照题目要求通过“-s”命令及“<”命令调用功能四,将文本中的内容重定向后进行统计
二. 版本控制
本地项目地址为:
https://git.coding.net/tianl364/count_words.git
三. PSP
| PSP阶段 | 预计花费时间(min) | 实际花费时间(min) | 原因分析 |
| 创建Git仓库并推送到coding | 20 | 33 | 因为本科阶段使用过Git仓库并将部分项目上传到GitHub上,所以虽然一段时间没有使用但是觉得会很快捡起来,但是这次重新学习命令的时间超过预期 |
| 阅读要求并编写功能一 | 60 | 127 | 对题意理解不够透彻,反复查看多遍,在使用Python的部分库时比较生疏,在网上查找资料的时间较长。 |
| 测试功能一 | 30 | 43 | 一开始使用了正则表达式的方法,但是与结果有一定差距,便对代码进行较大改动,放弃使用正则表达式。 |
| 编写功能二 | 60 | 88 | 在细节方面开始时分析不到位,边写边改动有较大误差。 |
| 测试功能二 | 30 | 34 | 出现了逻辑上的漏洞,在方法上为了重复使用做了较大改动 |
| 编写功能三 | 30 | 40 | 程序功能按时完成,但是在显示格式上花费时间较多。 |
| 测试功能三 | 20 | 33 | 路径总是出错,原因是Windows系统下路径要换成“\\”,我的开发系统是macOS High Sierra,路径是“/” |
| 打包exe文件 | 30 | 52 | 文件名与命令行参数按题目要求调整了较长时间,每更换一次就重新打包比较费时。 |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号