
MySQL详述
目录
- 1、数据库简介
- 2、数据库管理软件的分类
- 3、MySQL简介
- 4、部署MySQL
- 5、MySQL数据库基本管理
- 6、SQL语言
- 7、Mysql数据中的数据类型
- 8、MySQL数据表
- 9、数据表约束
- 10、增加字段
- 11、连表查询
- 12、子查询
- 13、数据库权限管理
- 14、MySQL存储引擎
- 15、InnoDB存储引擎
- 16、索引原理与慢查询优化
- 17、MySQL数据库的事务
- 18、数据库读现象
- 19、数据库锁机制
- 20、数据库备份
- 21、数据导入与导出
- 22、MySQL日志管理
- 23、主从复制
- 24、MHA实现MySQL的高可用
- 25、MySQL中间件Atlas
1、数据库简介
1.数据:事物的状态
2.记录:事物的每一个状态
3.表:存放数据的载体
4.库:存放表的载体
5.数据库管理系统:DataBase Management System 简称DBMS,即管理所有的数据的库
6.数据库服务器:用来部署数据库管理系统软件的服务器
2、数据库管理软件的分类
1.关系型数据库(又称RDBMS:Relational Database Management System)
SQL Server、Oracle、MySQL、MariaDB、
2.非关系型数据库
Mongodb、Redis、Memcache
3、MySQL简介
1.MySQL是一个关系型数据库管理系统,关系数据库将数据保存在不同的表中,增加了速度并提高了灵活性。
2.由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
4、部署MySQL
三种方式部署MySQL,连接地址:https://www.cnblogs.com/90s-blog/p/15937673.html
5、MySQL数据库基本管理
5.1 设置Mysql初始密码
# 设置初始密码:首次登录的原密码为空,设置初始密码为123
[root@localhost ~]# mysqladmin -uroot password "123"
5.2 MySQL连接工具与方式
5.2.1 mysql自带工具:mysql
1. 常见的特定于客户机的连接选项:
-u: 指定用户 # mysql -uroot
-p: 指定密码 # mysql -uroot -pTest123! 或 mysql -uroot -p后输入密码
-h: 指定主机域 # mysql -uroot -pTest123! -h127.0.0.1
-P: 指定端口 # mysql -uroot -pTest123! -h127.0.0.1 -P3307
-S: 指定socket文件 # mysql -uroot -pTest123! -S /tmp/mysql.sock
-e: 指定SQL语句(库外执行SQL语句) # mysql -uroot -pTest123! -e "show databases;"
--protocol: 指定连接方式 # mysql --protocol=TCP --protocol=socket
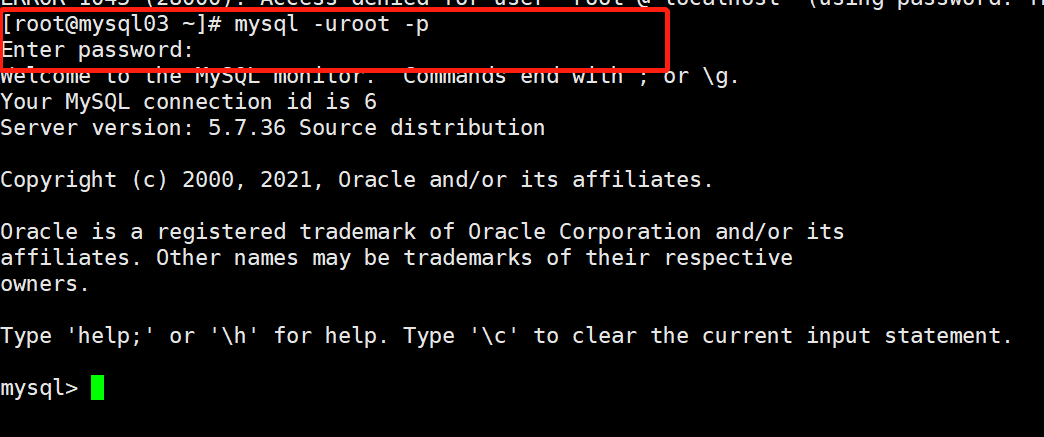
2. 登录Mysql服务器
[root@mysql03 ~]# mysql -uroot -pTest123!
# 如果直接在命令行-p后面接密码,-p选项与密码之间不要有空格
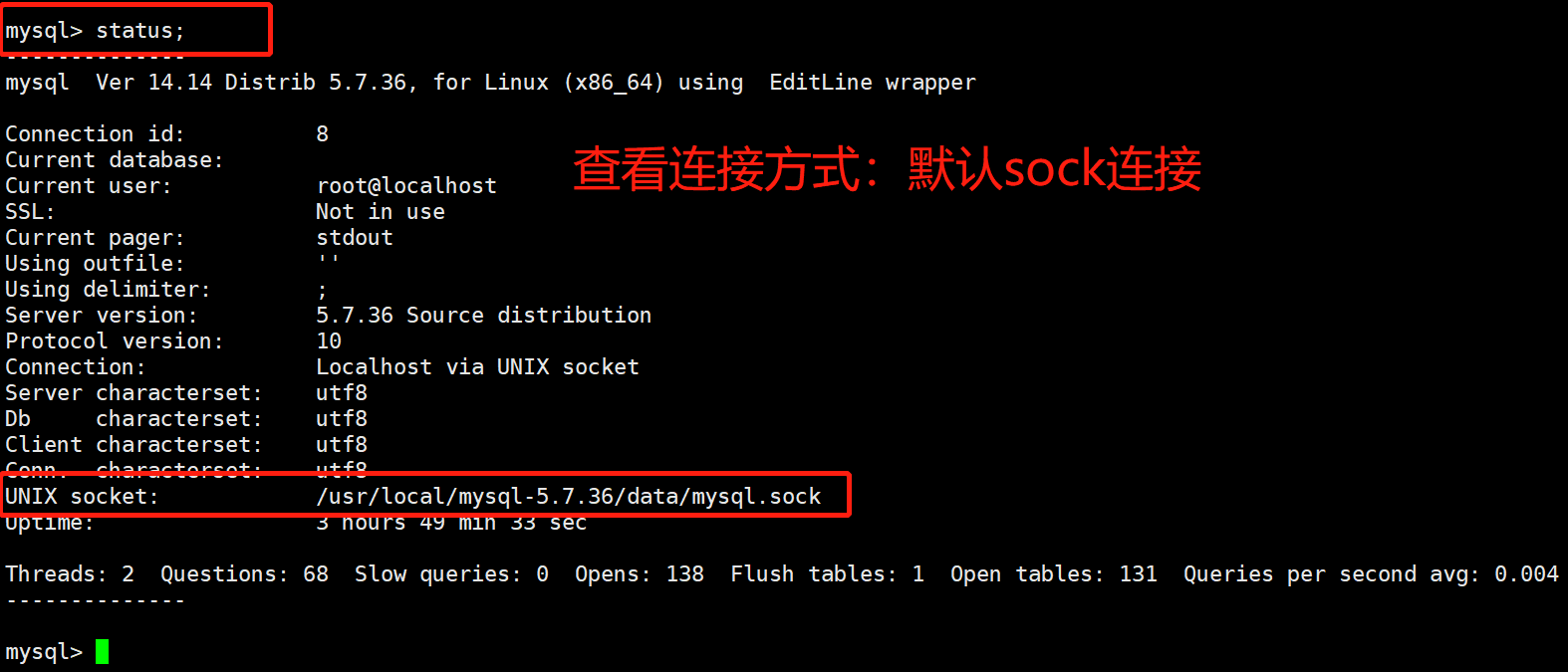
3.连接方式
方式 1. TCP/IP的连接方式,通常登录带有-h选项
方式 2. 套接字连接方式,socket连接(默认使用socket方式连接)
# 查看连接方式: 连接页面输入命令 status;
5.3 第三方工具连接
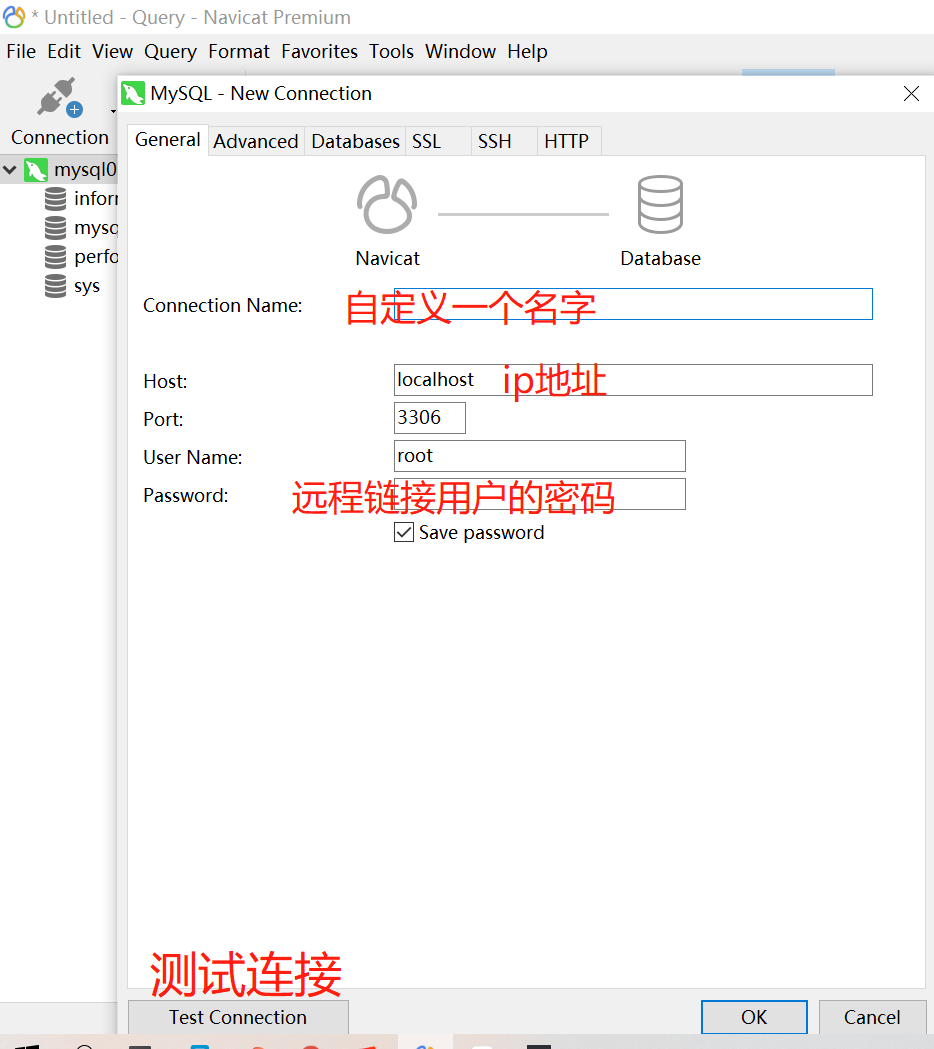
我们最常用的数据库连接工具是navicat来连接数据库,这个数据库连接工具的功能非常强大,非常适合用来操作数据库。
在链接之前,必须在mysql中创建远程连接用户:
# 步骤1:创建
GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' IDENTIFIED BY 'Oldboy@666' WITH GRANT OPTION;
# 步骤2:刷新权限
FLUSH PRIVILEGES;
创建连接用户后,在navicat菜单栏,connect下拉选项选择MySQL连接,先点SSH先连接主机,再选general输入相关内容测试连接通过后OK即可。
注意:云服务器需要防火墙打开3306端口,
5.4 MySQL配置文件
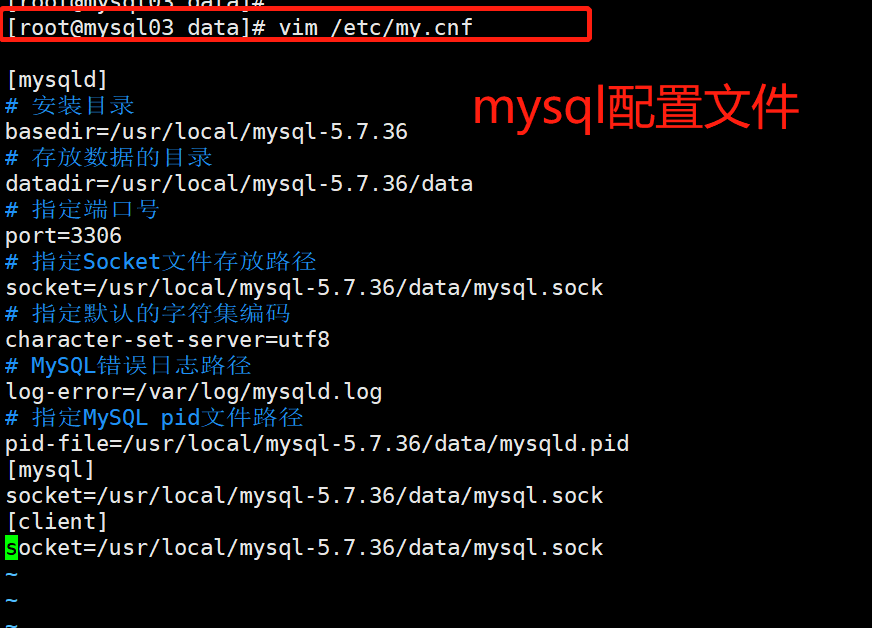
MySQL配置文件的作用是配置MySQL,使MySQL按照我们指定的方式健康运行。
# 配置文件中的注释可以有中文,但是配置项中不能出现中文。
[root@mysql03 data]# vim /etc/my.cnf
[mysqld]
# 安装目录
basedir=/usr/local/mysql-5.7.36
# 存放数据的目录
datadir=/usr/local/mysql-5.7.36/data
# 指定端口号
port=3306
# 指定Socket文件存放路径
socket=/usr/local/mysql-5.7.36/data/mysql.sock
# 指定默认的字符集编码
character-set-server=utf8
# MySQL错误日志路径
log-error=/var/log/mysqld.log
# 指定MySQL pid文件路径
pid-file=/usr/local/mysql-5.7.36/data/mysqld.pid
[mysql]
socket=/usr/local/mysql-5.7.36/data/mysql.sock
[client]
socket=/usr/local/mysql-5.7.36/data/mysql.sock
5.5 统一字符集编码
1.在mysql中创建数据库指定字符集和校验规则:
create database db1 charset utf8mb4 collate utf8mb4_general_ci;
2.修改配置文件后重启mysqld服务再登录查看:
[root@mysql03 data]# vim /etc/my.cnf # 修改配置
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[root@mysql03 data]# systemctl restart mysqld # 重启
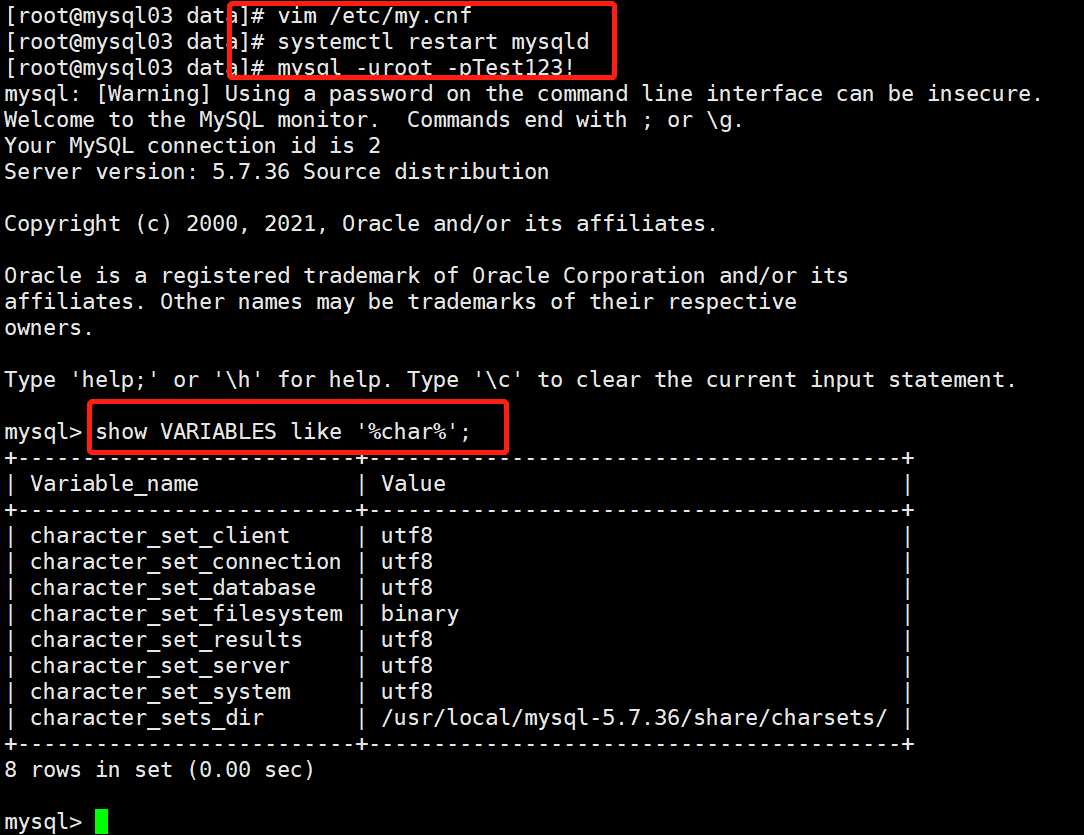
[root@mysql03 data]# mysql -uroot -pTest123! # 登录
mysql> show VARIABLES like '%char%';
5.6 修改MySQL root密码
1.使用grant修改密码后再刷新权限:
mysql> grant all privileges on *.* to root@'%' identified by '123456';
mysql> flush privileges;
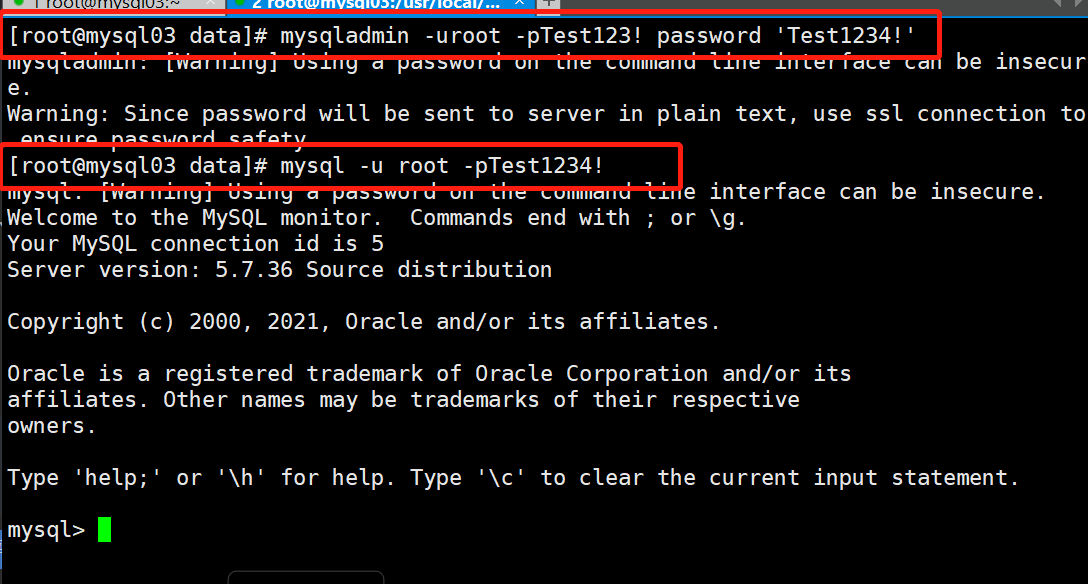
2.mysqladmin命令修改密码:
[root@mysql03 data]# mysqladmin -uroot -pTest123! password 'Test1234!'
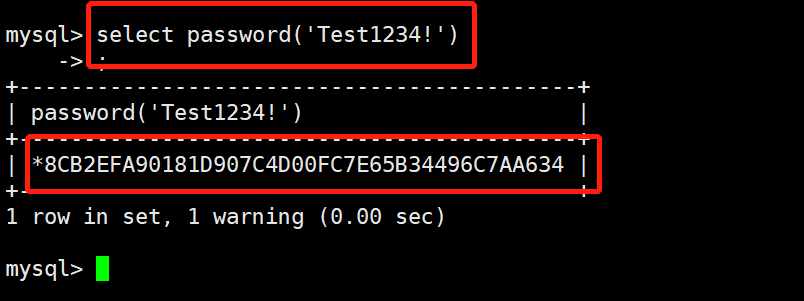
3.通过password命令生成密码密文后去注册表修改密码:
mysql> select password('Test123!');
+-------------------------------------------+
| password('Test123!') |
+-------------------------------------------+
| *48B1BB7AD34484EF0632D4B9A748CC861DFBE88B |
+-------------------------------------------+
4.使用Alter修改密码:
mysql> alter user root@mysql03 identified by '密码';
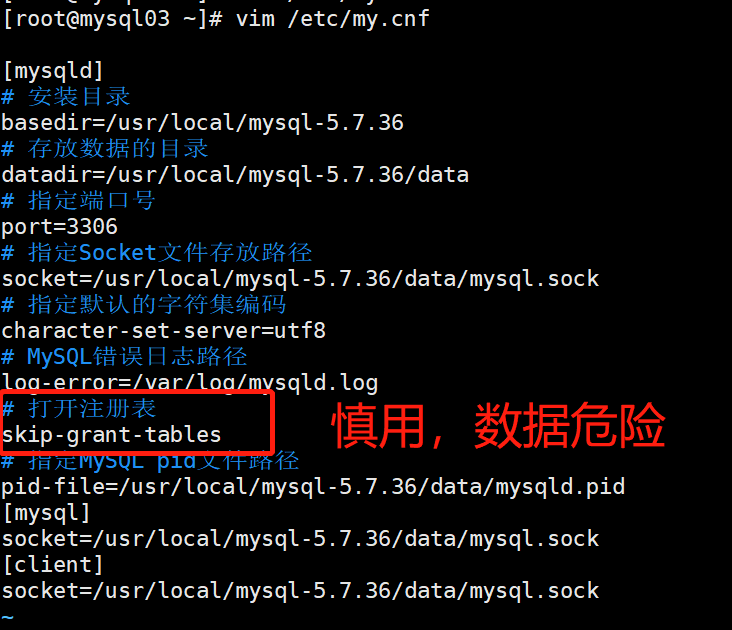
5.通过打开注册表的方式跳过密码(慎用):
[root@mysql03 data]# vim /etc/my.cnf
skip-grant-tables # 打开注册表
[root@mysql03 data]# systemctl restart mysqld
6、SQL语言
6.1 SQL是什么
SQL 是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。与其他程序设计语言(如 C语言、Java 等)不同的是,SQL 由很少的关键字组成,每个 SQL 语句通过一个或多个关键字构成。
1)数据定义语言(Data Definition Language,DDL)
用来创建或删除数据库以及表等对象,主要包含以下几种命令:
● DROP:删除数据库和表等对象
● CREATE:创建数据库和表等对象
● ALTER:修改数据库和表等对象的结构
2)数据操作语言(Data Manipulation Language,DML)
用来变更表中的记录,主要包含以下几种命令:
● SELECT:查询表中的数据
● INSERT:向表中插入新数据
● UPDATE:更新表中的数据
● DELETE:删除表中的数据
3)数据查询语言(Data Query Language,DQL)
用来查询表中的记录,主要包含 SELECT 命令,来查询表中的数据。
4)数据控制语言(Data Control Language,DCL)
用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对数据库中的用户设定权限。主要包含以下几种命令:
● GRANT:赋予用户操作权限
● REVOKE:取消用户的操作权限
● COMMIT:确认对数据库中的数据进行的变更
● ROLLBACK:取消对数据库中的数据进行的变更
6.2 SQL的基本规则
1.SQL 语句要以分号(;)或\G结尾:区别是展示结果不一样,
2.SQL 语句不区分大小写 # 插入到表中的数据是区分大小写的
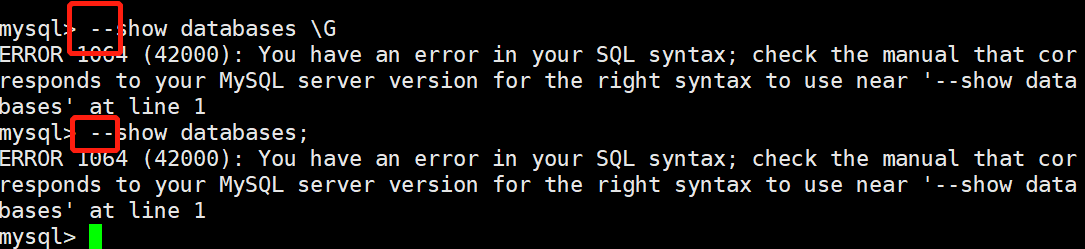
3.SQL的注释(破折号后面有一个空格): -- 注释内容
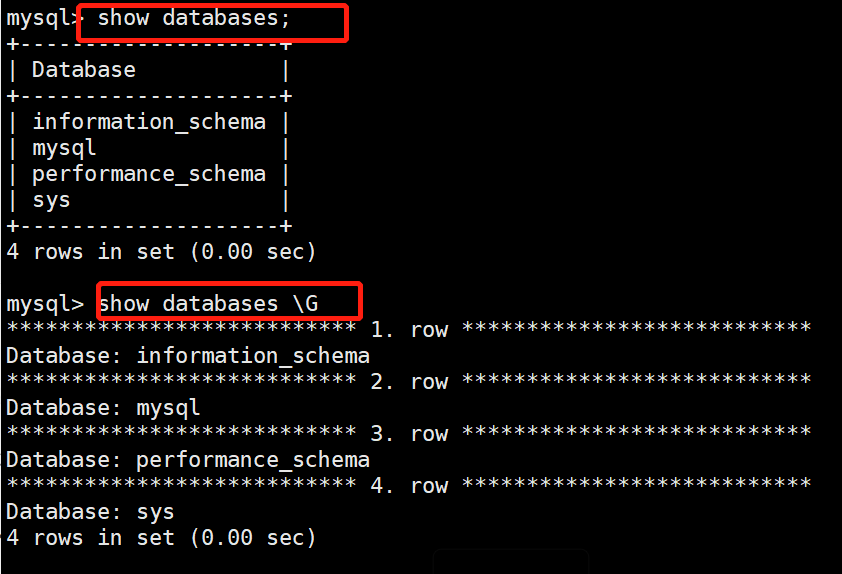
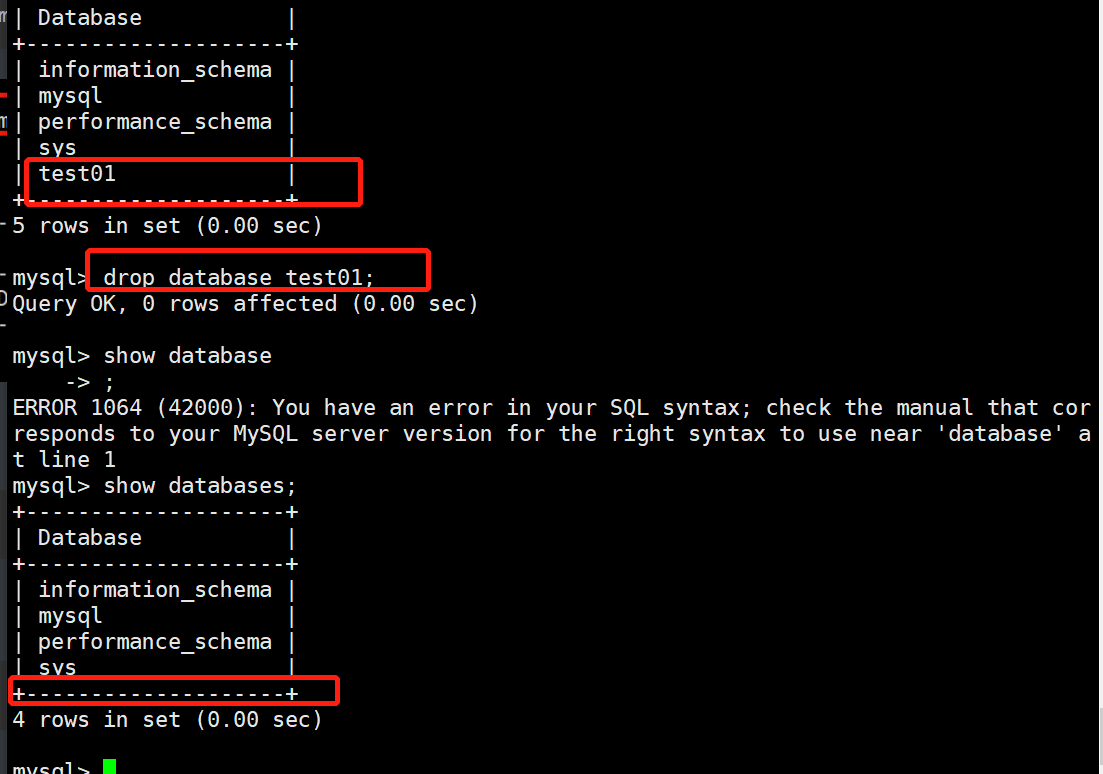
6.3 查看数据库
1.查看所有数据库:show databases;
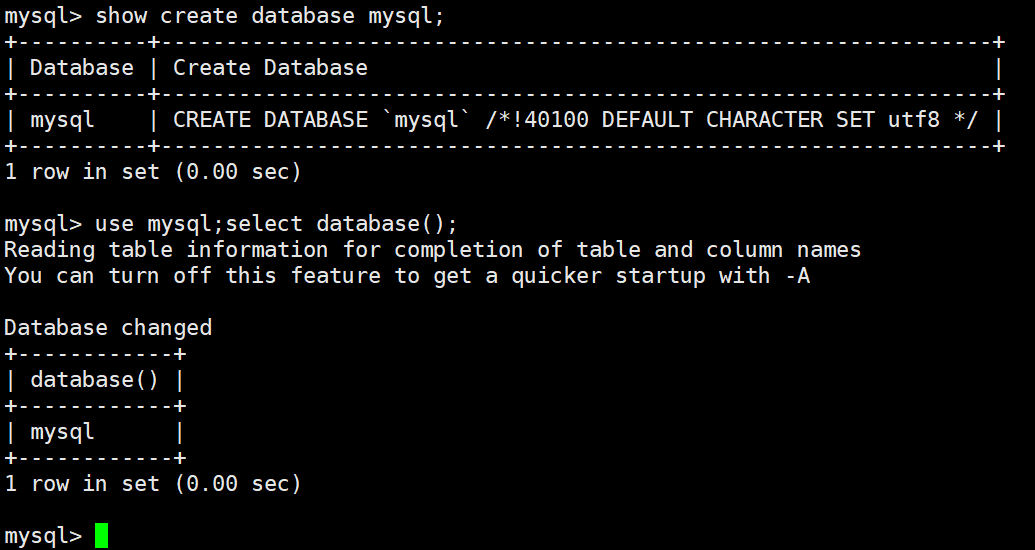
2.查看数据库创建:show create database mysql;
3.查看正在使用的数据库:use mysql;select database();
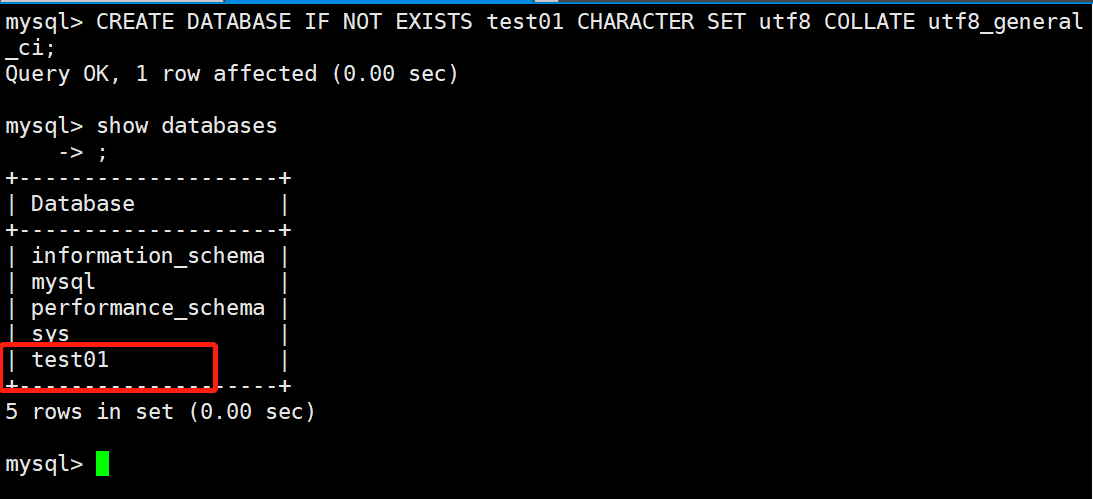
6.4 创建数据库
mysql> CREATE DATABASE IF NOT EXISTS test01 CHARACTER SET utf8 COLLATE utf8_general_ci;
6.5 修改数据库
mysql> ALTER DATABASE test01 CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
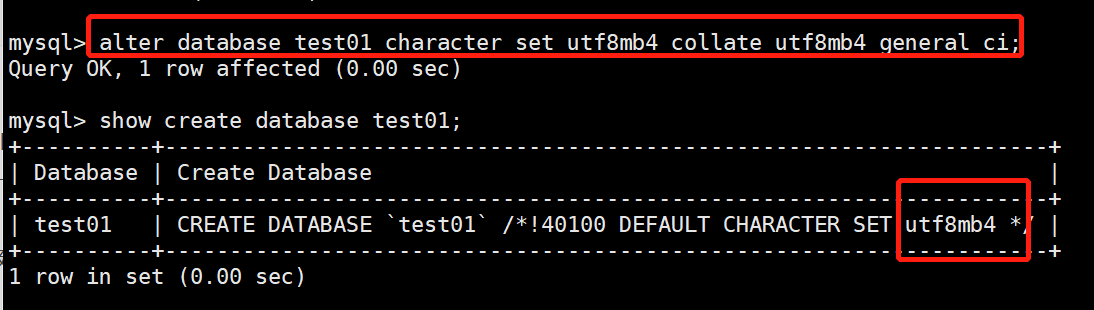
6.6 指定数据库
mysql> use test01;
6.7 删除数据库
mysql> DROP DATABASE test01;
6.8 数据库注释
1.单行注释(2种方式):#注释内容 或 -- 注释内容
2.多行注释:
/*
第一行注释内容
第二行注释内容
*/
7、Mysql数据中的数据类型
数据类型(data_type)是指系统中所允许的数据的类型。MySQL 数据类型定义了列中可以存储什么数据以及该数据怎样存储的规则。MySQL 的数据类型有大概可以分为 5 种,分别是整数类型、浮点数类型和定点数类型、日期和时间类型、字符串类型、二进制类型等。
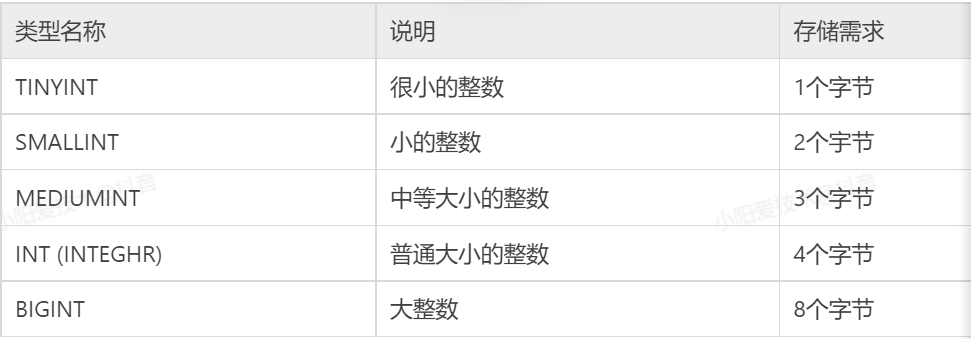
7.1 MySQL整数类型
整数类型又称数值型数据,数值型数据类型主要用来存储数字。
MySQL 提供了多种数值型数据类型,不同的数据类型提供不同的取值范围,可以存储的值范围越大,所需的存储空间也会越大。
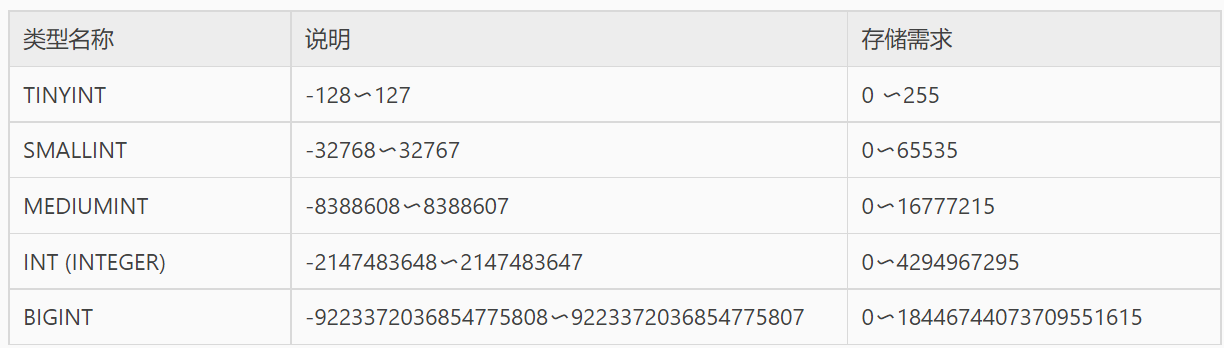
MySQL 主要提供的整数类型有 TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT,其属性字段可以添加 AUTO_INCREMENT 自增约束条件。下图中列出了 MySQL 中的数值类型及相关说明。
从图中可以看到,不同类型的整数存储所需的字节数不相同,占用字节数最小的是 TINYINT 类型,占用字节最大的是 BIGINT 类型,占用的字节越多的类型所能表示的数值范围越大。
根据占用字节数可以求出每一种数据类型的取值范围。例如,TINYINT 需要 1 个字节(8bit)来存储,那么 TINYINT 无符号数的最大值为 28-1,即 255;TINYINT 有符号数的最大值为 27-1,即 127。其他类型的整数的取值范围计算方法相同,如图所示。
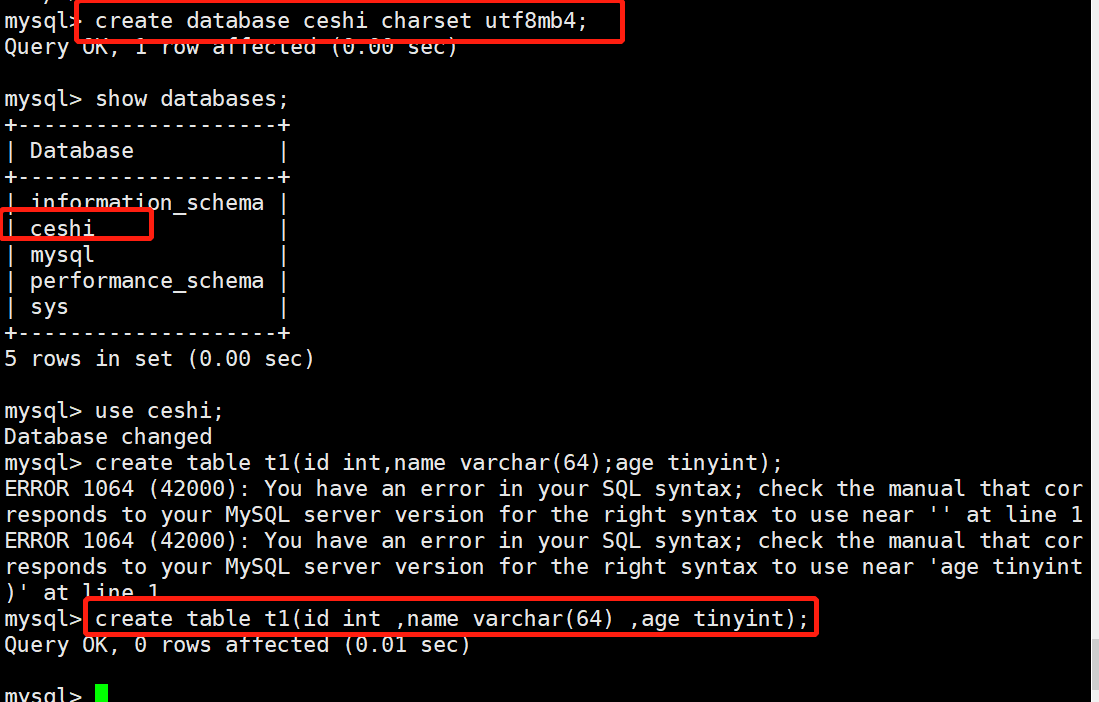
# 案例:
# 1. 创建数据库ceshi
mysql> create database ceshi charset utf8mb4;
# 2. 查看创建完成
mysql> show databases;
# 3. 指定数据库ceshi
mysql> use ceshi;
# 4. 在ceshi库中创建表t1:id指定int,name指定varchar,age指定tinyint存储)
mysql> create table t1(id int ,name varchar(64) ,age tinyint);
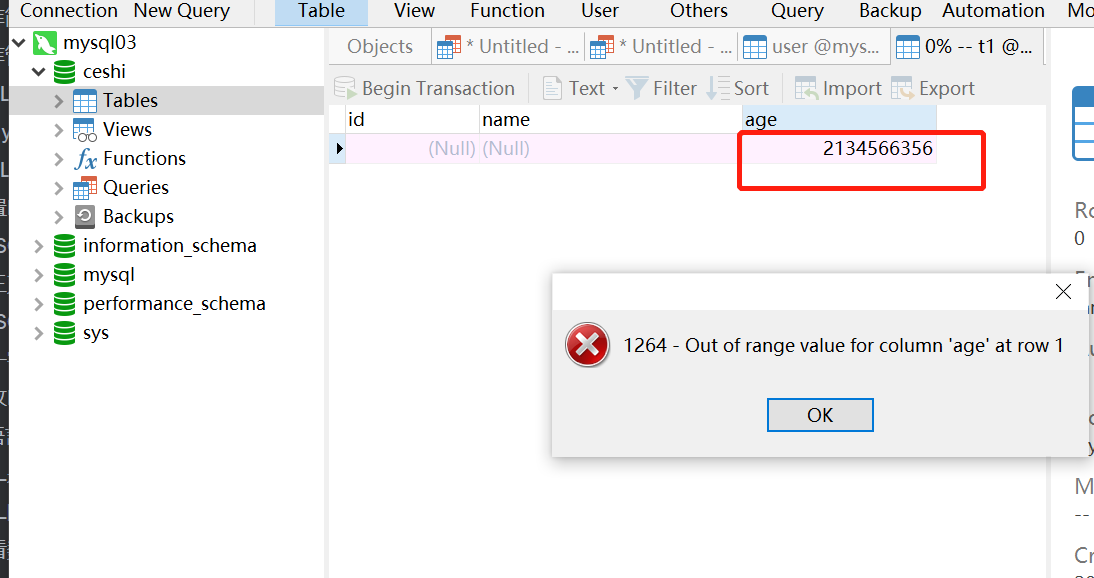
7.2 MySQL小数类型
MySQL 中使用浮点数和定点数来表示小数。
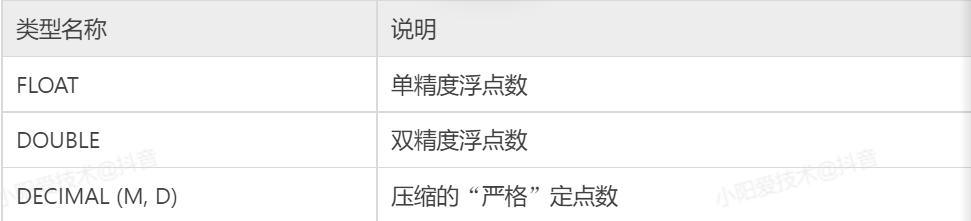
浮点类型有两种,分别是单精度浮点数(FLOAT)和双精度浮点数(DOUBLE);定点类型只有一种,就是 DECIMAL。
浮点类型和定点类型都可以用(M, D)来表示,其中M称为精度,表示总共的位数;D称为标度,表示小数的位数。
浮点数类型的取值范围为 M(1~255)和 D(1~30,且不能大于 M-2),分别表示显示宽度和小数位数。M 和 D 在 FLOAT 和DOUBLE 中是可选的,FLOAT 和 DOUBLE 类型将被保存为硬件所支持的最大精度。DECIMAL 的默认 D 值为 0、M 值为 10。下图中列出了 MySQL 中的小数类型和存储需求。
DECIMAL 类型不同于 FLOAT 和 DOUBLE。DOUBLE 实际上是以字符串的形式存放的,DECIMAL 可能的最大取值范围与 DOUBLE 相同,但是有效的取值范围由 M 和 D 决定。如果改变 M 而固定 D,则取值范围将随 M 的变大而变大。
从图中可以看到,DECIMAL 的存储空间并不是固定的,而由精度值 M 决定,占用 M+2 个字节。
FLOAT 类型的取值范围如下:
● 有符号的取值范围:-3.402823466E+38~-1.175494351E-38。
● 无符号的取值范围:0 和 -1.175494351E-38~-3.402823466E+38。
DOUBLE 类型的取值范围如下:
● 有符号的取值范围:-1.7976931348623157E+308~-2.2250738585072014E-308。
● 无符号的取值范围:0 和 -2.2250738585072014E-308~-1.7976931348623157E+308。
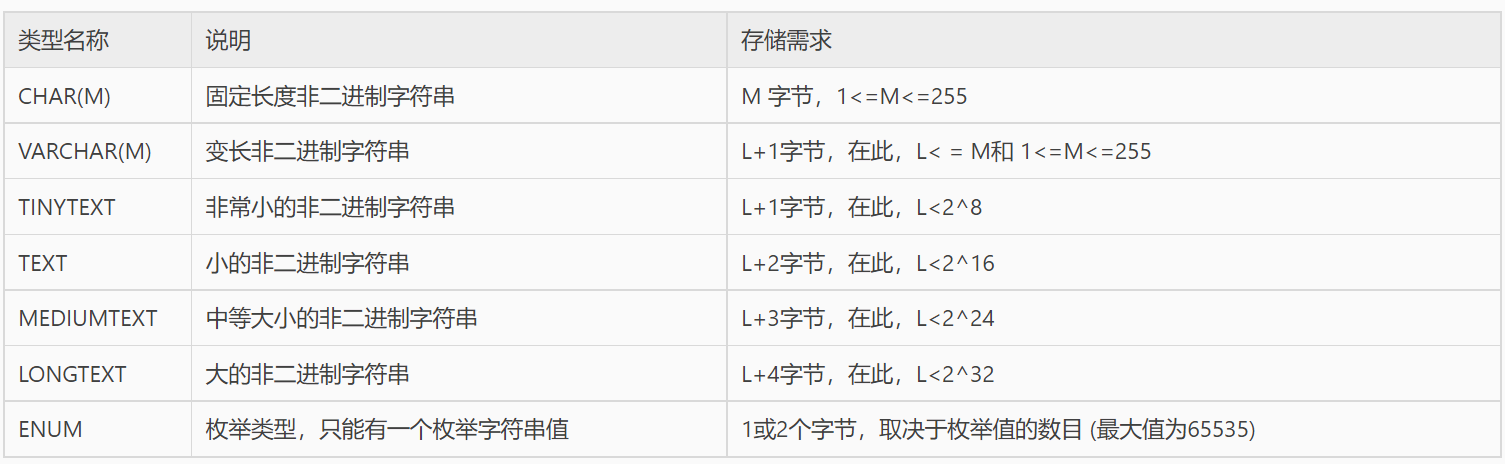
7.3 MySQL字符串类型
字符串类型用来存储字符串数据,还可以存储图片和声音的二进制数据。字符串可以区分或者不区分大小写的串比较,还可以进行正则表达式的匹配查找。
MySQL 中的字符串类型有 CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、ENUM、SET 等。
下图中列出了 MySQL 中的字符串数据类型,括号中的M表示可以为其指定长度。
VARCHAR 和 TEXT 类型是变长类型,其存储需求取决于列值的实际长度(在前面的表格中用 L 表示),而不是取决于类型的最大可能尺寸。
例如,一个 VARCHAR(10) 列能保存一个最大长度为 10 个字符的字符串,实际的存储需要字符串的长度 L 加上一个字节以记录字符串的长度。对于字符 “abcd”,L 是 4,而存储要求 5 个字节。
# 案例:
mysql> CREATE TABLE test05 (
-> name VARCHAR(255)
-> );
mysql> CREATE TABLE test06( name ENUM("1","2","3") );
7.4 MySQL日期和时间类型
MySQL 中有多处表示日期的数据类型:YEAR、TIME、DATE、DTAETIME、TIMESTAMP。当只记录年信息的时候,可以只使用 YEAR 类型。
每一个类型都有合法的取值范围,当指定确定不合法的值时,系统将“零”值插入数据库中。
下图中列出了 MySQL 中的日期与时间类型。
# 案例:
# 创库:
mysql> CREATE DATABASE db1 charset utf8;
# 指定库
mysql> use db1;
# 创表
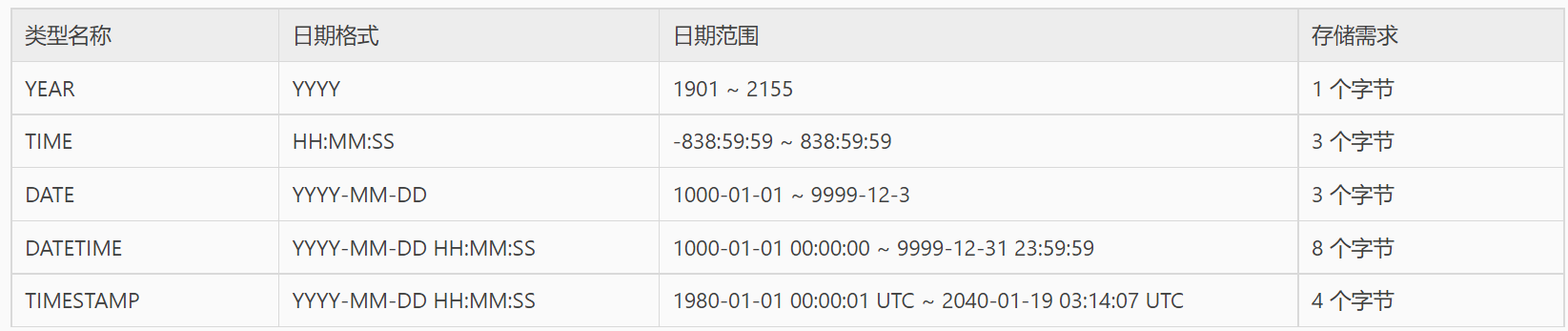
mysql> create TABLE t1(id int, name VARCHAR(18), date1 DATE, date2 time, date3 datetime, date4 timestamp, date5 YEAR);
# 添数据
mysql> insert into t1 VALUES (1,'1', '2021-09-09','12:12:12','2021-09-09','2021-09-09','2021');
# 查看表数据
mysql> SELECT * from t1;
7.5 MySQL二进制类型
MySQL 中的二进制字符串有 BIT、BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。
下图中列出了 MySQL 中的二进制数据类型,括号中的M表示可以为其指定长度。
# 案例:
import pymysql
class BlobDataTestor:
def __init__(self):
self.conn = pymysql.connect(host='127.0.0.1', user='root', passwd='123456', db='db1', port=3306)
def __del__(self):
try:
self.conn.close()
except:
pass
def closedb(self):
self.conn.close()
def setup(self):
cursor = self.conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS `Dem_Picture` (
`ID` int(11) NOT NULL auto_increment,
`PicData` mediumblob,
PRIMARY KEY (`ID`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=4 ;
""")
def testRWBlobData(self):
# 读取源图片数据
f = open("D:\\1.jpg", "rb")
b = f.read()
f.close()
# 将图片数据写入表
cursor = self.conn.cursor()
cursor.execute("INSERT INTO Dem_Picture (PicData) VALUES (%s)", (pymysql.Binary(b)))
# self.conn.commit()
# 读取表内图片数据,并写入硬盘文件
cursor.execute("SELECT PicData FROM Dem_Picture ORDER BY ID DESC limit 1")
d = cursor.fetchone()[0]
cursor.close()
f = open("D:\\1.jpg", "wb")
f.write(d)
f.close()
# 下面一句的作用是:运行本程序文件时执行什么操作
if __name__ == "__main__":
test = BlobDataTestor()
try:
test.setup()
test.testRWBlobData()
# test.teardown()
finally:
test.closedb()

7.6 MySQL系统变量
在 MySQL 数据库,变量分为系统变量和用户自定义变量。系统变量以 @@ 开头,用户自定义变量以 @ 开头。
服务器维护着两种系统变量,即全局变量(GLOBAL VARIABLES)和会话变量(SESSION VARIABLES)。全局变量影响 MySQL 服务的整体运行方式,会话变量影响具体客户端连接的操作。
每一个客户端成功连接服务器后,都会产生与之对应的会话。会话期间,MySQL 服务实例会在服务器内存中生成与该会话对应的会话变量,这些会话变量的初始值是全局变量值的拷贝。
1.查看系统变量:
mysql> show global variables;
2.查看与当前会话相关的所有会话变量以及全局变量:
mysql> show session variables;
8、MySQL数据表
数据表是数据库的重要组成部分,每一个数据库都是由若干个数据表组成的。换句话说,没有数据表就无法在数据库中存放数据。
8.1 创建数据表
在创建数据库之后,接下来就要在数据库中创建数据表。所谓创建数据表,指的是在已经创建的数据库中建立新表。
创建数据表的过程是规定数据列的属性的过程,同时也是实施数据完整性(包括实体完整性、引用完整性和域完整性)约束的过程。接下来我们介绍一下创建数据表的语法形式。
在 MySQL 中,可以使用 CREATE TABLE 语句创建表。
其语法格式为:CREATE TABLE <表名> ([字段1][字段类型1],[字段2][字段类型2],...);
# 案例:
mysql> create table t2 (id int,name varchar(20),age tinyint);
8.2 修改数据表
修改数据表的前提是数据库中已经存在该表。修改表指的是修改数据库中已经存在的数据表的结构。修改数据表的操作也是数据库管理中必不可少的,就像画素描一样,画多了可以用橡皮擦掉,画少了可以用笔加上。
不了解如何修改数据表,就相当于是我们只要画错了就要扔掉重画,这样就增加了不必要的成本。
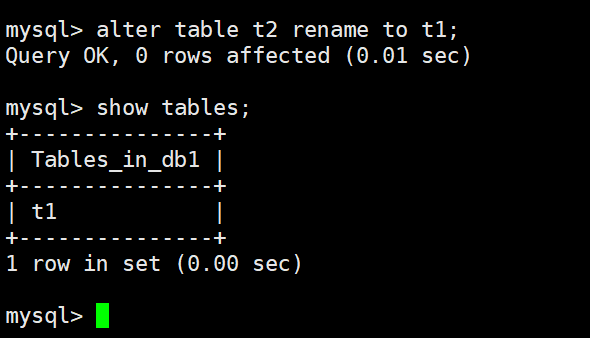
1.修改表名:MySQL 通过 ALTER TABLE 语句来实现表名的修改。
语法格式为:ALTER TABLE <旧表名> RENAME [TO] <新表名>;
# 案例:
mysql> alter table t2 rename to t1;
2.修改表字符集:MySQL 通过 ALTER TABLE 语句来实现表字符集的修改。
语法格式为:ALTER TABLE 表名 [DEFAULT] CHARACTER SET <字符集名> [DEFAULT] COLLATE <校对规则名>;
# 案例:
mysql> show collation; # 查看字符集编码
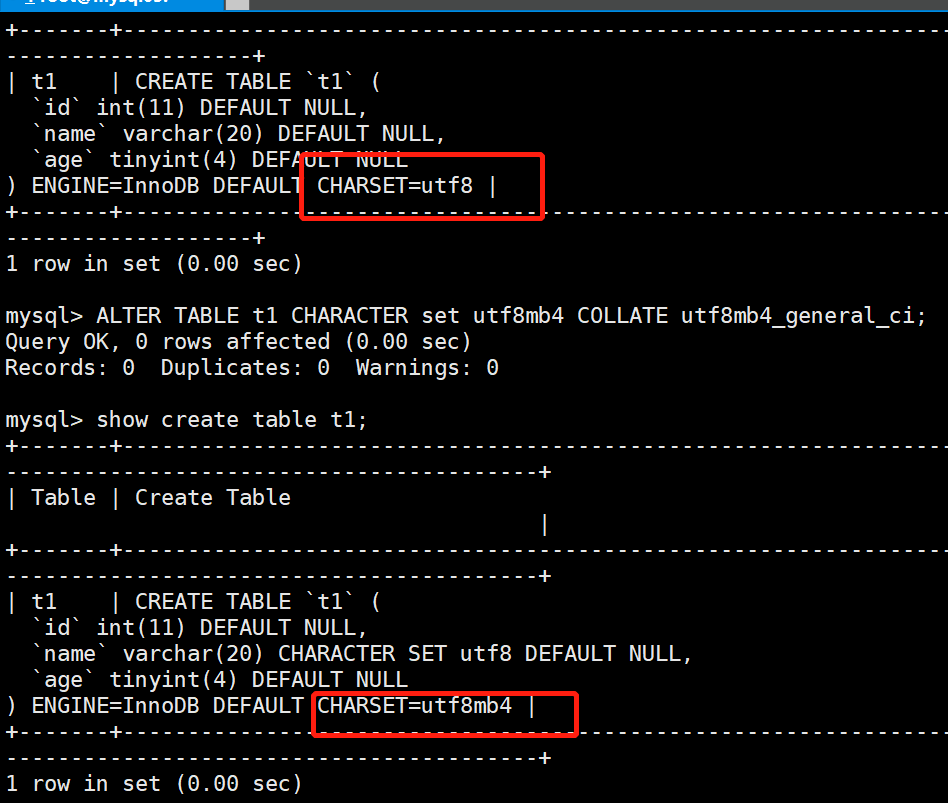
mysql> ALTER TABLE t1 CHARACTER set utf8mb4 COLLATE utf8mb4_general_ci;
mysql> show create table t1;
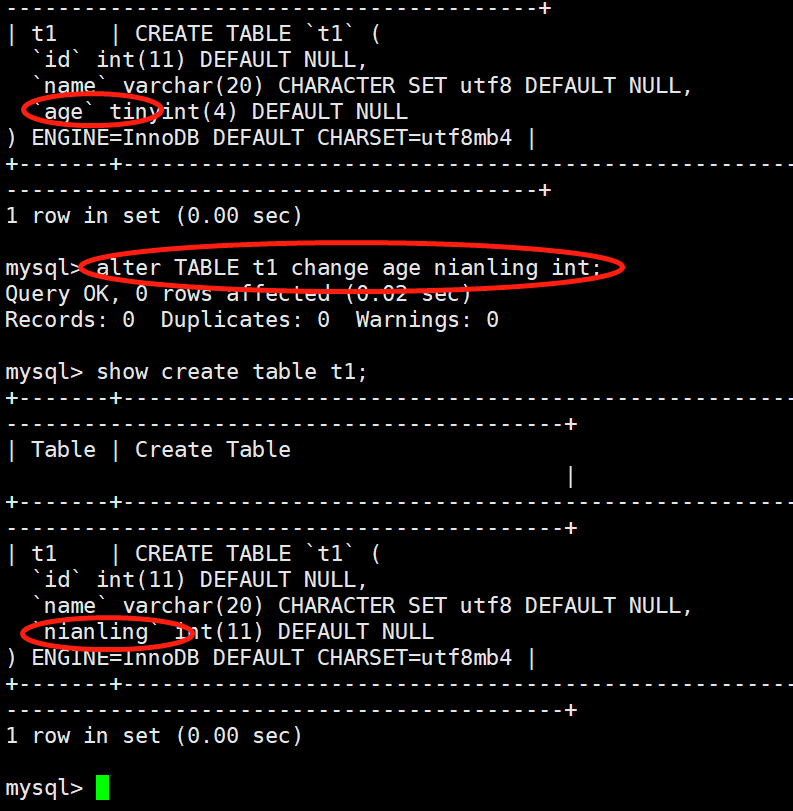
3.修改表字段:在 MySQL 中可以使用 ALTER TABLE 语句来改变原有表的结构,例如增加或删减列、更改原有列类型、重新命名列或表等。
其语法格式为:ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <新数据类型>;
# 案例:
mysql> alter TABLE t1 change age nianling int;
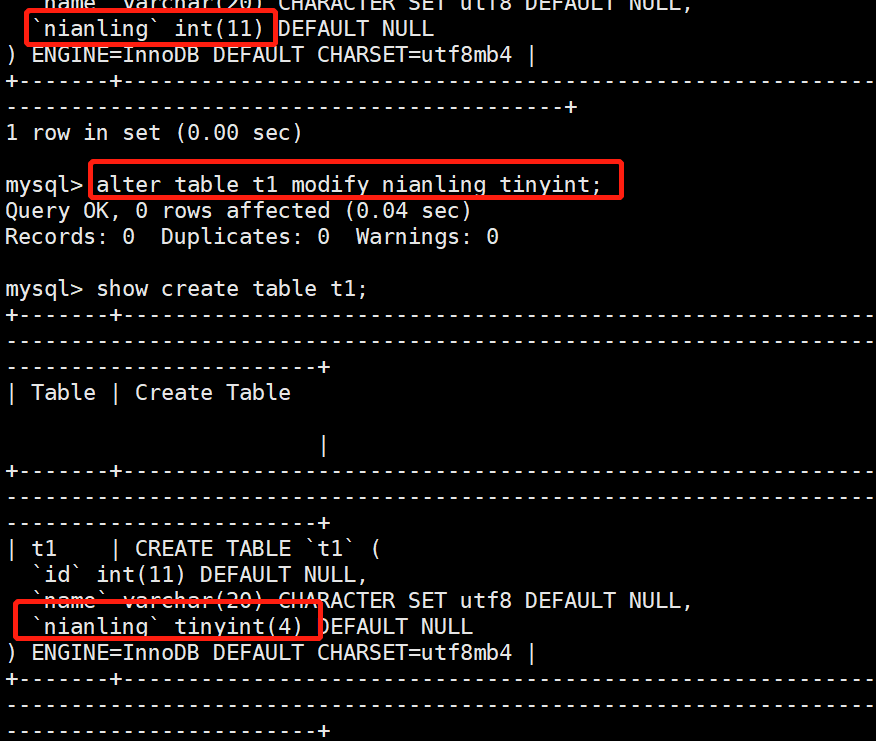
4.修改字段数据类型:修改字段的数据类型就是把字段的数据类型转换成另一种数据类型。
语法格式为:ALTER TABLE <表名> MODIFY <字段名> <数据类型>
# 案例:
mysql> alter table t1 modify nianling tinyint;
8.3 删除数据表
在 MySQL 数据库中,对于不再需要的数据表,我们可以将其从数据库中删除。
在删除表的同时,表的结构和表中所有的数据都会被删除,因此在删除数据表之前最好先备份,以免造成无法挽回的损失。
下面我们来了解一下 MySQL 数据库中数据表的删除方法。
1.删除数据表
基础语法:使用 DROP TABLE 语句可以删除一个或多个数据表,语法格式为:DROP TABLE [IF EXISTS] 表名1 [ ,表名2, 表名3 ...]
# 案例:
mysql> drop table t1;
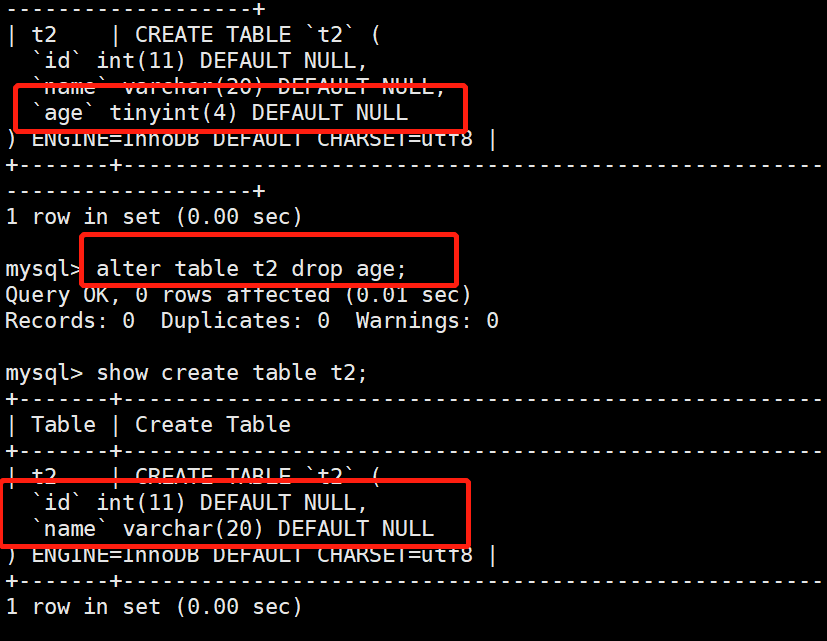
2.删除字段:删除字段是将数据表中的某个字段从表中移除,语法格式:ALTER TABLE <表名> DROP <字段名>;
mysql> alter table t2 drop age;
8.4 表数据的增删改查
1.增加表数据:增加数据其实就是向表中插入数据,或者是向表中添加数据。
语法格式:INSERT INTO <表名> (字段1,字段2,...字段n) VALUES (数据1,数据2...数据n);
# 案例:
mysql> insert into t2 (id,name,age) values (1,'qql'),(2,'xx'),(3,'yy');
mysql> insert into t2 values (4,'zz'),(5,'aa'),(6,'tt');
2.查询数据:表中保存了很多数据,其目的就是为了使用的时候可以立即查询出来,所以数据库的查询语句的使用率是其他语句的数倍。语法格式为:SELECT [查询字段] FROM [表名] [条件语句] [显示规则] [规则条件]
# 案例:
mysql> SELECT * from t2;
mysql> SELECT name from t2;
3.条件语句(where):条件语句是用来筛选数据的,主要用于查询某些数据
判断条件包含:
> :大于
< : 小于
= :等于
!= 和 <> : 不等于
>= : 大于等于
<= : 小于等于
like : 模糊查询
and : 并且
or :或者
# 案例:
mysql> SELECT * from t2 where id>4;
mysql> SELECT * FROM t2 WHERE id >= 1 OR name = zz;
4.排序(order by): 顾名思义就是按照某种规则查询出数据,默认情况下是按照从前到后查询数据,但是也可以通过排序语法查询出相关的数据。语法格式:SELECT [查询字段] FROM [表名] [显示规则]
-- 排序的规则
ASC :默认,正向排序
DESC :反向排序
# 案例:
mysql> select * from t2 order by id desc;
5.去重(DISTINCT):去重,顾名思义就是在查询的数据中过滤掉重复数据,默认会显示所有的数据,可以使用出重语法实现去掉重复数据。语法格式为:SELECT DISTINCT [字段] FROM [表名];
# 案例:
mysql> select distinct name from t2;
6.别名:顾名思义就是将字段设置一个新的名字。
# 案例:
mysql> select count(id) '行数' from t2;
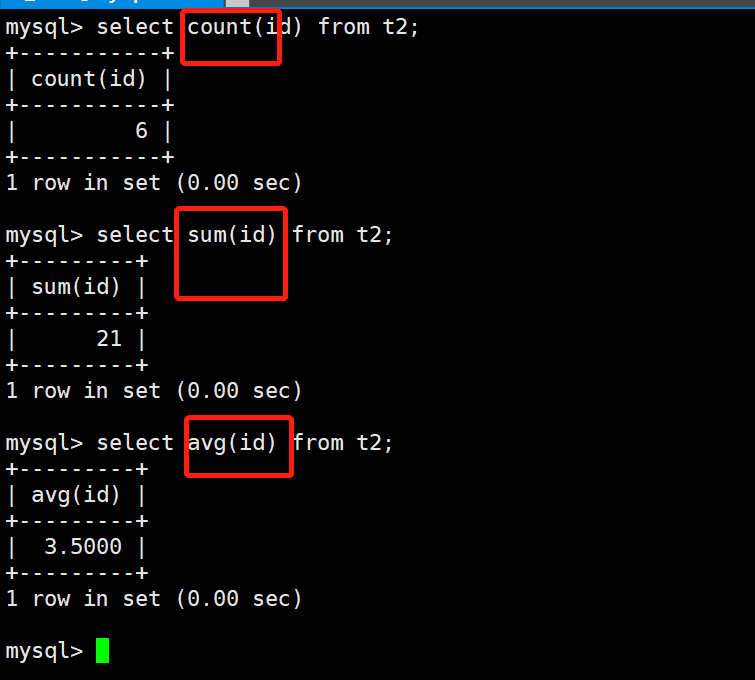
7.常用函数:在数据库中使用函数就是通过函数实现某种具体的功能。
# 案例:计算个数
mysql> SELECT count(id) FROM t2;
# 案例:求和
mysql> select sum(id) from t2;
# 案例:求平均值
mysql> select avg(id) from t2;
8.having语句:having也是一个条件判断语句,是作用于查询之后的语句。
# 案例:
mysql> SELECT * FROM t2 WHERE id >2 HAVING name='zz';
9.分组:按照某种要求进行分组查询
# 案例:
mysql> SELECT SUM(id) FROM t2 GROUP BY name;
8.5 修改表数据
在数据表中存储的数据时常都会有所更改,例如:是否单身,是今天是否国庆。所以,怎么会随着一些事务的推移从而需要修改表数据,这个时候我们就需要用到MySQL UPDATE语句。
语法格式为:UPDATE <表名> SET [修改的内容] [条件];
# 案例:
mysql> UPDATE t2 SET name = 'cc',id = 7 where name='aa';
mysql> UPDATE t2 SET name = 'ww',id = 7 where name='cc';
8.6 删除表数据
删除表数据,就是当数据表中有错误或者没有任何价值的数据时,通过SQL语句去将这部分数据删除。
语法格式为:DELETE FROM <表名> [条件];
# 案例:
mysql> DELETE FROM t2;
mysql> DELETE FROM t2 WHERE id = 2;
mysql> TRUNCATE TABLE t2;
9、数据表约束
索引约束和数据类型约束,从字段名字上可以知道,它是为了控制数据而生的。
9.1 主键索引约束
所谓的主键约束就是在数据表中(一般是id字段),选择一个字段充当索引角色。强烈建议一个表中至少要有一个主键索引约束。主键是一个字段的类型,不能够单独的存在。主键索引的数据库底层的数据是按照一定顺序进行排序的,取数的时候效率更高。
# 案例:创建一个具有主键索引的数据表
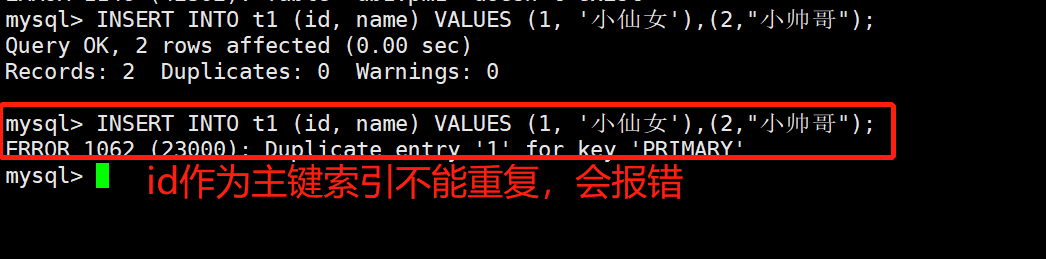
mysql> -- 创建一个具有主键索引的数据表
mysql> CREATE TABLE IF NOT EXISTS t1(
id int PRIMARY KEY,
name VARCHAR(20)
);
mysql> -- 插入数据
mysql> INSERT INTO t1 (id, name) VALUES (1, '小仙女'),(2,"小帅哥");
1.自增长:在日常使用数据库的时候常常不知道当天数据的主键索引的编号属于哪一个,这个时候我们就很需要一个自动为我们填充主键编号的功能即为:自增长。
# 案例:自动填充主键
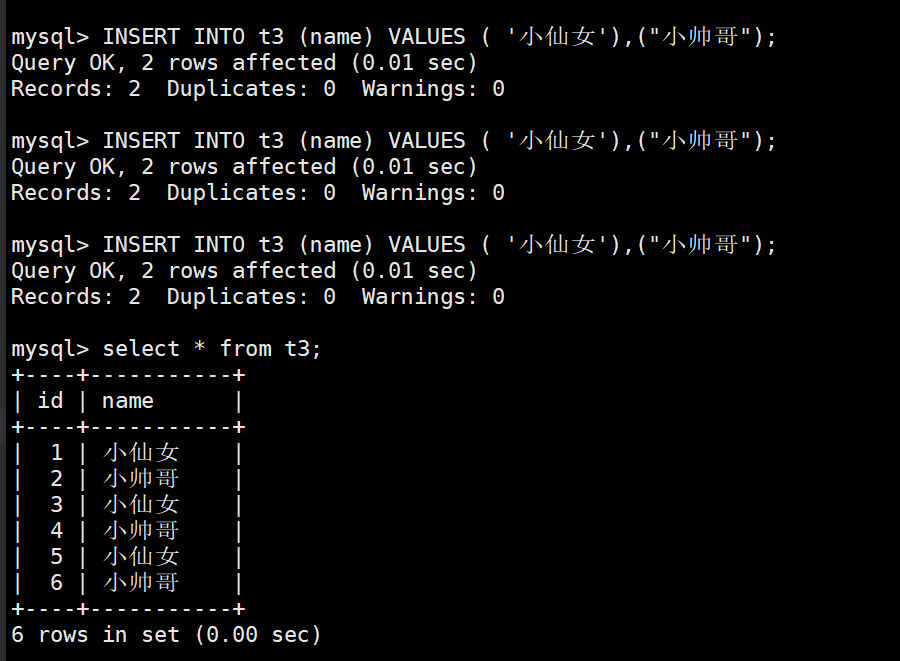
mysql> -- 创建一个具有主键索引的数据表
mysql> CREATE TABLE IF NOT EXISTS t3(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
mysql> -- 查看表信息
mysql> SHOW CREATE TABLE t3\G
mysql> -- 多次插入数据查看id会不会自增长
mysql> INSERT INTO t3 (name) VALUES ( '小仙女'),("小帅哥");
mysql> INSERT INTO t3 (name) VALUES ( '小仙女'),("小帅哥");
mysql> INSERT INTO t3 (name) VALUES ( '小仙女'),("小帅哥");
mysql> SELECT * FROM t3;
# 案例2:设置自动增长的起始值
mysql> -- 创建一个具有主键索引的数据表
CREATE TABLE IF NOT EXISTS t4(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
) ENGINE=INNODB AUTO_INCREMENT=10000;
mysql> -- 填入输入
mysql> insert into t4 (name) values ('小仙女'),("小帅哥");
mysql> insert into t4 (name) values ('小仙女'),("小帅哥");
mysql> insert into t4 (name) values ('小仙女'),("小帅哥");
mysql> select * from t4;
9.2 添加主键
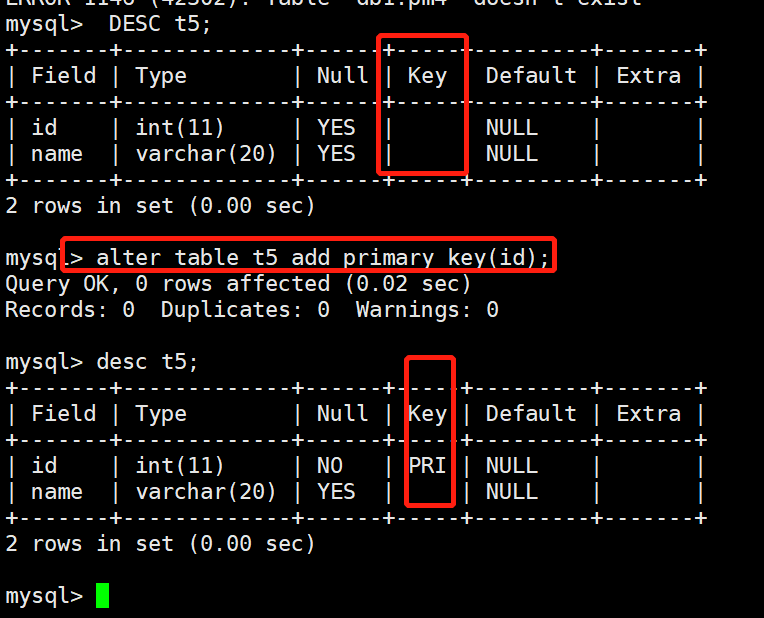
当数据表已经创建完毕了,我们需要为该表添加主键,如何添加呢?
语法格式:ALTER TABLE <数据表> ADD PRIMARY KEY(字段名称);
# 案例:
mysql> -- 创建一个没有主键索引的数据表
mysql> CREATE TABLE IF NOT EXISTS t5(
id int ,
name VARCHAR(20)
);
mysql> DESC t5;
mysql> -- 添加主键
mysql> alter table t5 add primary key(id);
mysql> DESC t5;
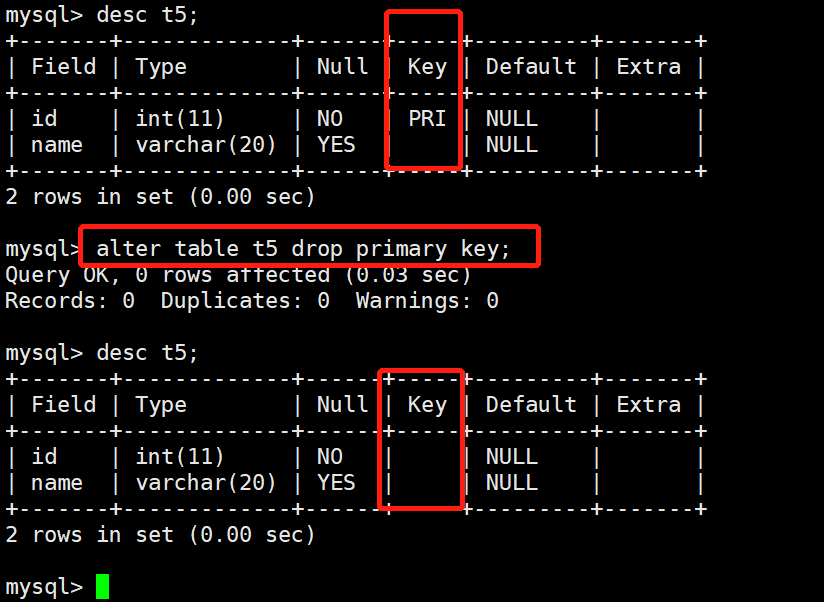
9.3 删除主键
当数据表不需要主键时,我们可以尝试将其删除.
语法格式为:ALTER TABLE <数据表名> DROP PRIMARY KEY;
# 案例:
mysql> alter table t5 drop primary key;
mysql> desc t5;
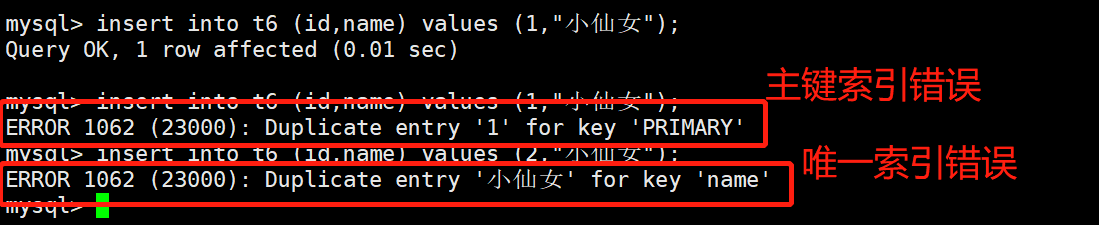
9.4 唯一索引约束
唯一索引约束跟主键索引类似,也是要求不允许重复,但是主键索引一般作用于id, 唯一索引可以作用于所有的字段。同理唯一索引也是依赖于字段,能够单独存在。唯一索引不能代替主键索引,不能直接去数据库底层取数,主键索引的数据库底层存储数据是无序的,因此取数的时候速度时快时慢,抖动较大。
# 案例:
mysql> create table if not exists t6(id int primary key,name varchar(20) unique key)engine=innodb;
mysql> desc t6;
mysql> insert into t5 (id,name) values (1,"小仙女");
mysql> insert into t6 (id,name) values (1,"小仙女");
mysql> insert into t6 (id,name) values (2,"小仙女");
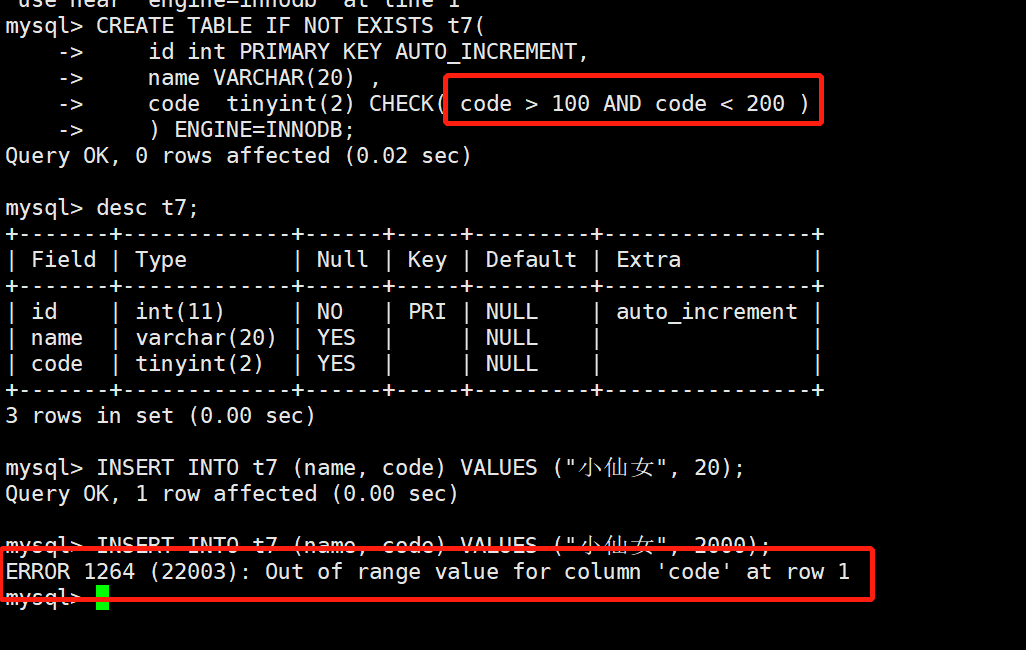
9.5 检查索引
检查索引,顾名思义就是通过设置范围,来管控数据。
# 案例:
mysql> CREATE TABLE IF NOT EXISTS t7(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) ,
code tinyint(2) CHECK( code > 100 AND code < 200 )
) ENGINE=INNODB;
mysql> desc t7;
mysql> INSERT INTO t7 (name, code) VALUES ("小仙女", 20);
mysql> INSERT INTO t7 (name, code) VALUES ("小仙女", 2000);
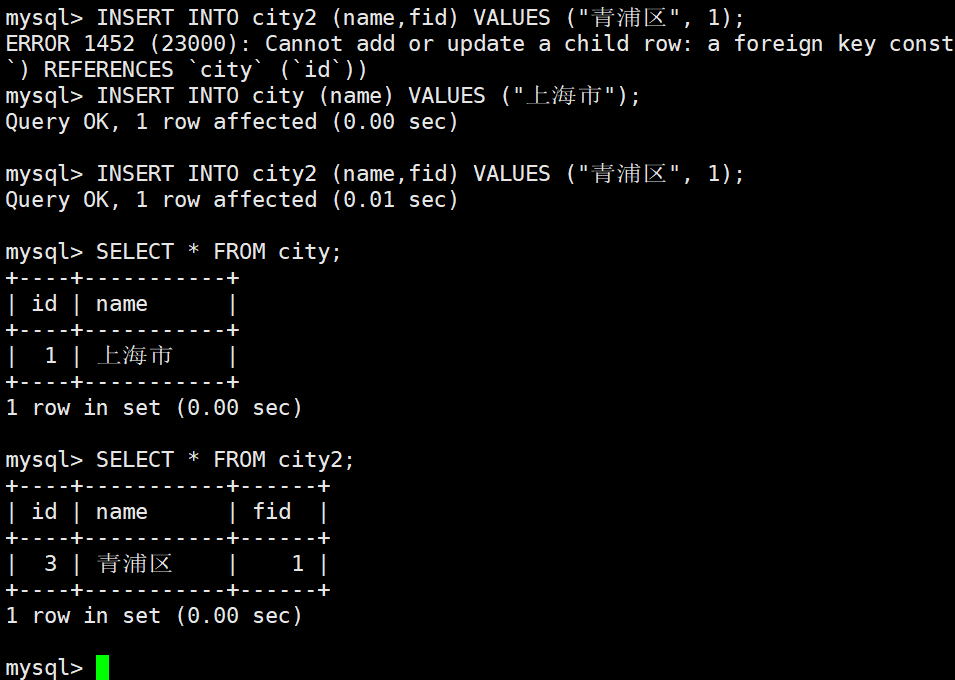
9.6 外键索引(不推荐使用)
外键索引顾名思义就是依赖别的表的数据的一种索引。
# 案例:
mysql> CREATE TABLE city(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
mysql> CREATE TABLE city2(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
fid int ,
FOREIGN KEY(fid) REFERENCES city(id)
);
mysql> DESC city;
mysql> DESC city2;
mysql> INSERT INTO city2 (name,fid) VALUES ("青浦区", 1);
mysql> INSERT INTO city (name) VALUES ("上海市");
mysql> INSERT INTO city2 (name,fid) VALUES ("青浦区", 1);
mysql> SELECT * FROM city;
mysql> SELECT * FROM city2;
# city2变依赖于city变数据,当city表中没有相关数据时,则不能够添加数据到city2。
10、增加字段
MySQL数据表是由行和列构成的,通常把表的“列”称为字段(Field),把表的“行”称为记录(Record)。随着业务的变化,可能需要在已有的表中添加新的字段。
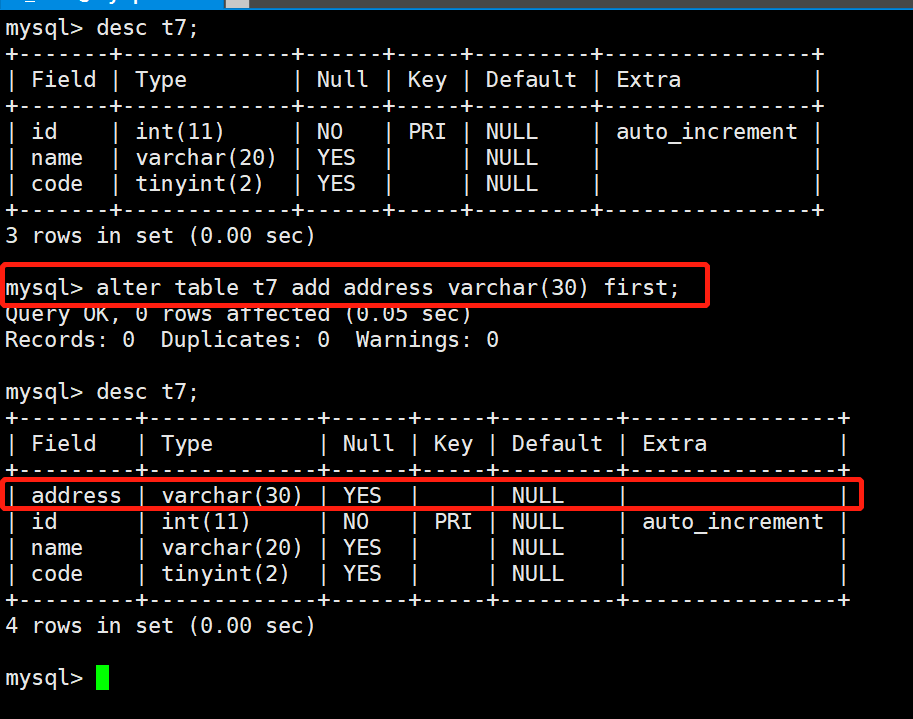
10.1 在开头位置添加字段
MySQL 默认在表的最后位置添加新字段,如果希望在开头位置(第一列的前面)添加新字段,那么可以使用 FIRST 关键字。
语法格式:ALTER TABLE <表名> ADD <新字段名> <数据类型> [约束条件] FIRST;
# 案例:
mysql> DESC t7;
mysql> ALTER TABLE t7 ADD address VARCHAR(20) FIRST;
mysql> DESC t7;
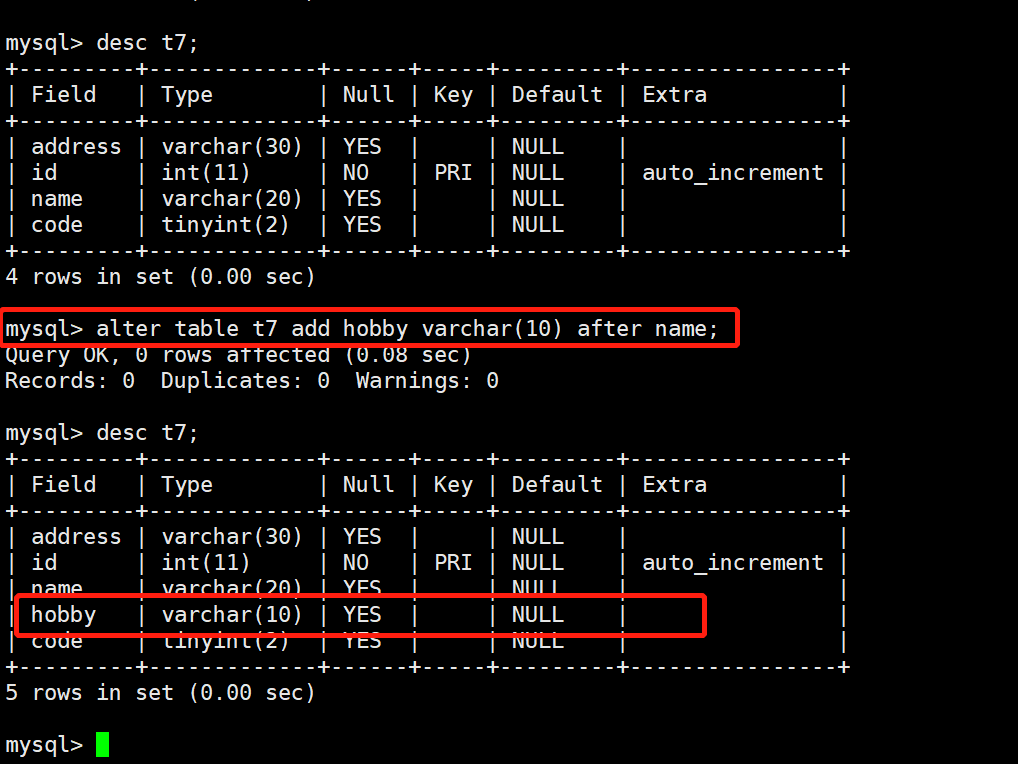
10.2 在中间位置添加字段
MySQL 除了允许在表的开头位置和末尾位置添加字段外,还允许在中间位置(指定的字段之后)添加字段,此时需要使用 AFTER 关键字。
语法格式为:ALTER TABLE <表名> ADD <新字段名> <数据类型> [约束条件] AFTER <已经存在的字段名>;
# 案例:
mysql> DESC t7;
mysql> ALTER TABLE t7 ADD hobby VARCHAR(20) after name;
mysql> DESC t7;
10.3 在末尾位置添加字段
一个完整的字段包括字段名、数据类型和约束条件。
语法格式:ALTER TABLE <表名> ADD <新字段名><数据类型>[约束条件];
# 案例:
mysql> DESC t7;
mysql> ALTER TABLE t7 ADD city VARCHAR(20);
mysql> DESC t7;
10.4 字段的琐碎内容
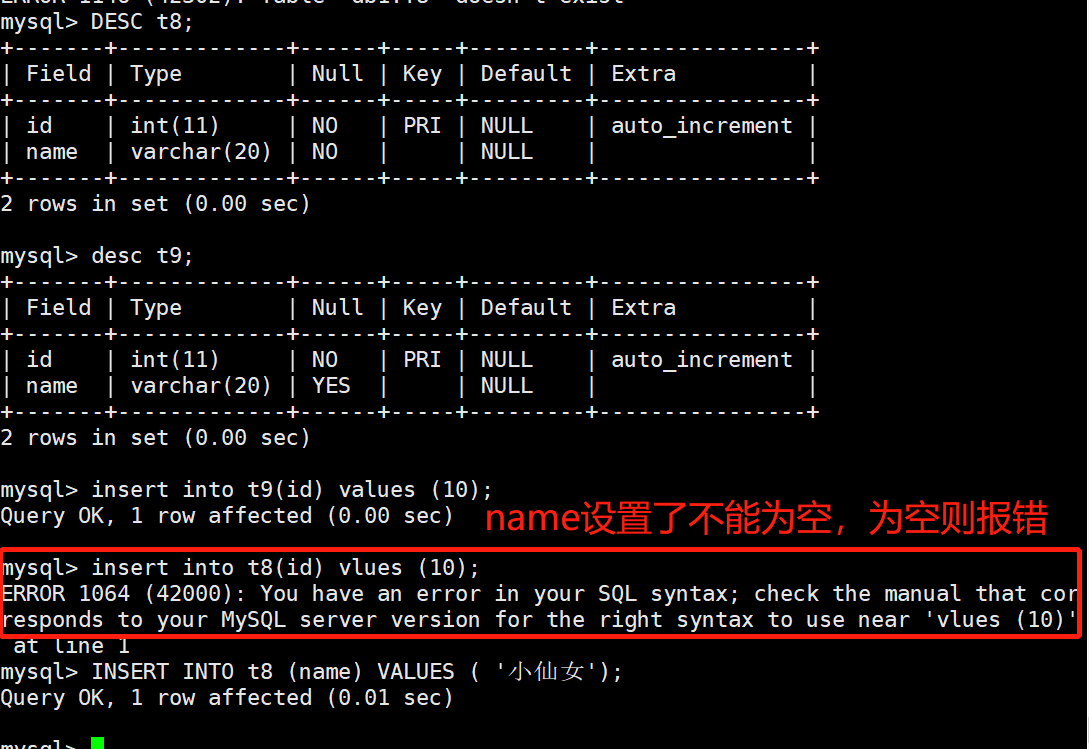
1、是否允许为空:设置是否允许字段为空。其格式是:NOT NULL
# 案例:
mysql> CREATE TABLE IF NOT EXISTS t8(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL
) ENGINE=INNODB;
mysql> CREATE TABLE IF NOT EXISTS t9(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
) ENGINE=INNODB;
mysql> INSERT INTO t9 (id) VALUES (10);
mysql> INSERT INTO t8 (id) VALUES (10);
mysql> INSERT INTO t8 (name) VALUES ( '小仙女');
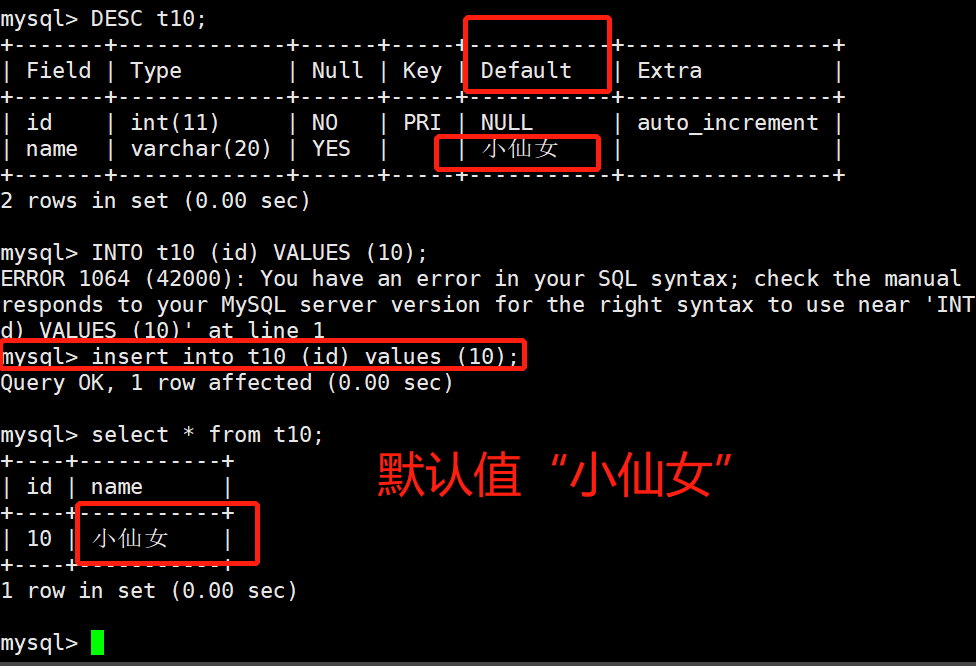
2.默认值: DEFAULT '默认值'
# 案例:
默认值,顾名思义就是给字段设置一个默认值,当字段没有添加任何值的时候,使用默认值进行填充。
mysql> CREATE TABLE IF NOT EXISTS t10(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) DEFAULT "小仙女"
) ENGINE=INNODB;
mysql> DESC t10;
mysql> INSERT INTO t10 (id) VALUES (10);
mysql> SELECT * FROM t10;
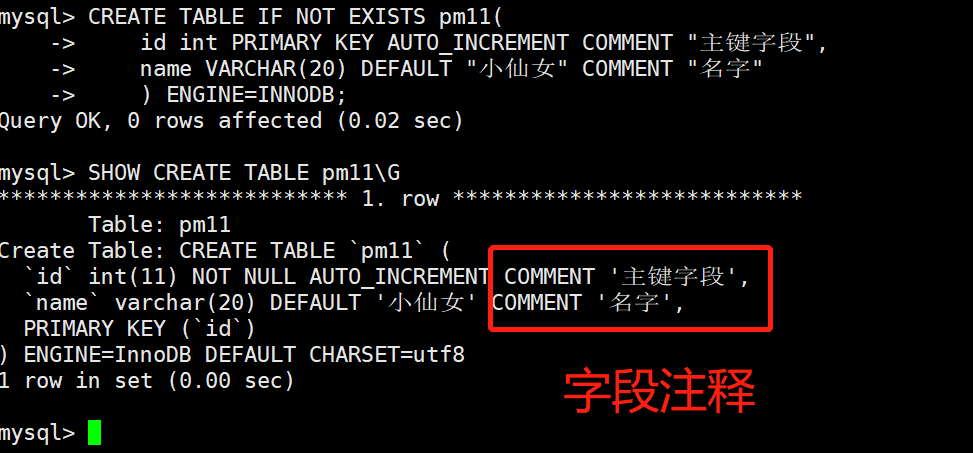
3.字段注释:给字段一个注释,有利于后期维护的时候快速理解字段含义
# 案例:
mysql> CREATE TABLE IF NOT EXISTS pm11(
id int PRIMARY KEY AUTO_INCREMENT COMMENT "主键字段",
name VARCHAR(20) DEFAULT "小仙女" COMMENT "名字"
) ENGINE=INNODB;
mysql> SHOW CREATE TABLE pm11\G
11、连表查询
两个或多个表至之间通过某种关系,按照某种规则合并起来查询出来的数据即为连表查询,连表查询是企业中常用一种查询数据方式,在关系型数据库中连表查询是很常见的。但是连表查询仅仅限于同一个数据库内多张数据表相互链接,不同数据库中的数据便无法使用连表查询。
11.1 内连接(INNER JOIN )
把两个数据表中的所有的数据一次性按照某种条件一次性查询出来。
# 案例:
mysql> create database ceshi character set utf8 collate utf8_general_ci;
mysql> use ceshi;
mysql> CREATE TABLE IF NOT EXISTS student(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT "学生名称",
age TINYINT(2) NOT NULL DEFAULT 18 COMMENT "年龄"
);
mysql> CREATE TABLE IF NOT EXISTS major (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT "专业名称"
);
mysql> CREATE TABLE IF NOT EXISTS student_major(
id INT PRIMARY KEY AUTO_INCREMENT,
stu_id INT NOT NULL COMMENT "学生表ID",
m_id INT NOT NULL COMMENT "专业表ID"
);
mysql> CREATE TABLE IF NOT EXISTS teacher(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT "老师名称"
);
mysql> CREATE TABLE IF NOT EXISTS tearch_major(
id INT PRIMARY KEY AUTO_INCREMENT,
tea_id INT NOT NULL COMMENT "老师表ID",
m_id INT NOT NULL COMMENT "专业表ID"
);
mysql> INSERT INTO student (name,age) VALUES ("小明", 18),("小红", 17),("小花", 16);
mysql> INSERT INTO major (name) VALUES ("数学"),("英语"),("毛概");
mysql> INSERT INTO teacher (name) VALUES ("李铁锤"),("石林"),("为李飞");
mysql> select * FROM teacher;
+----+-----------+
| id | name |
+----+-----------+
| 1 | 李铁锤 |
| 2 | 石林 |
| 3 | 为李飞 |
+----+-----------+
3 rows in set (0.00 sec)
mysql> select * FROM student;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 小明 | 18 |
| 2 | 小红 | 17 |
| 3 | 小花 | 16 |
+----+--------+-----+
3 rows in set (0.00 sec)
mysql> select * FROM major;
+----+--------+
| id | name |
+----+--------+
| 1 | 数学 |
| 2 | 英语 |
| 3 | 毛概 |
+----+--------+
3 rows in set (0.00 sec)
mysql> INSERT INTO student_major (stu_id, m_id) VALUES (1, 1),(1,2);
mysql> INSERT INTO student_major (stu_id, m_id) VALUES (2, 1),(2,3);
mysql> INSERT INTO student_major (stu_id, m_id) VALUES (3, 1),(3,2),(3,3);
mysql> select * from student_major;
+----+--------+------+
| id | stu_id | m_id |
+----+--------+------+
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
| 4 | 2 | 3 |
| 5 | 3 | 1 |
| 6 | 3 | 2 |
| 7 | 3 | 3 |
+----+--------+------+
7 rows in set (0.00 sec)
mysql> INSERT INTO tearch_major (tea_id, m_id) VALUES (1,3),(2,1),(3,2);
mysql> select * FROM tearch_major;
+----+--------+------+
| id | tea_id | m_id |
+----+--------+------+
| 1 | 1 | 3 |
| 2 | 2 | 1 |
| 3 | 3 | 2 |
+----+--------+------+
3 rows in set (0.00 sec)
# 1、查询出小明选修哪几门课?
mysql> SELECT student.id,student.name,student.age, major.name FROM student INNER JOIN student_major ON student.id = student_major.stu_id INNER JOIN major ON student_major.m_id = major.id WHERE student.id = 1;
+----+--------+-----+--------+
| id | name | age | name |
+----+--------+-----+--------+
| 1 | 小明 | 18 | 数学 |
| 1 | 小明 | 18 | 英语 |
+----+--------+-----+--------+
2 rows in set (0.00 sec)
# 2、查询出小花选修的课的老师有哪些?
mysql> SELECT student.id,student.name,student.age, major.name,teacher.name FROM student INNER JOIN student_major ON student.id = student_major.stu_id INNER JOIN major ON student_major.m_id = major.id INNER JOIN tearch_major ON tearch_major.m_id = major.id INNER JOIN teacher ON teacher.id = tearch_major.tea_id WHERE student.id = 3;
+----+--------+-----+--------+-----------+
| id | name | age | name | name |
+----+--------+-----+--------+-----------+
| 3 | 小花 | 16 | 毛概 | 李铁锤 |
| 3 | 小花 | 16 | 数学 | 石林 |
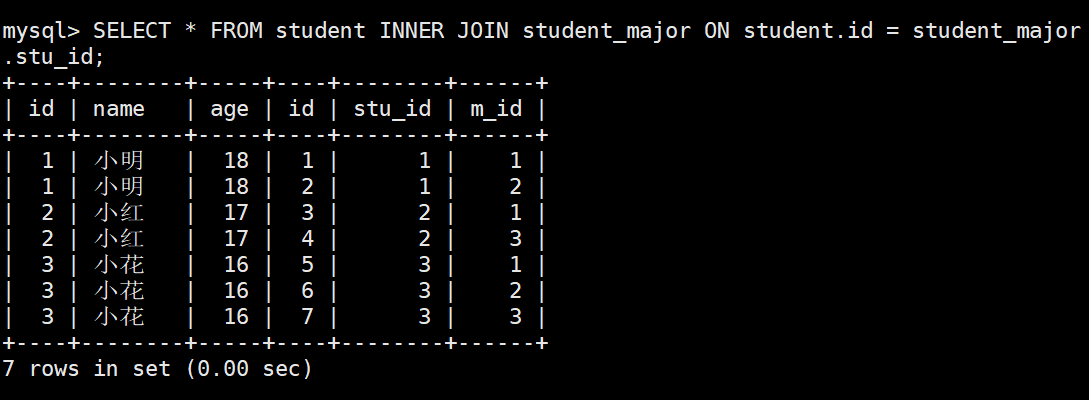
| 3 | 小花 | 16 | 英语 | 为李飞 |
+----+--------+-----+--------+-----------+
3 rows in set (0.00 sec)
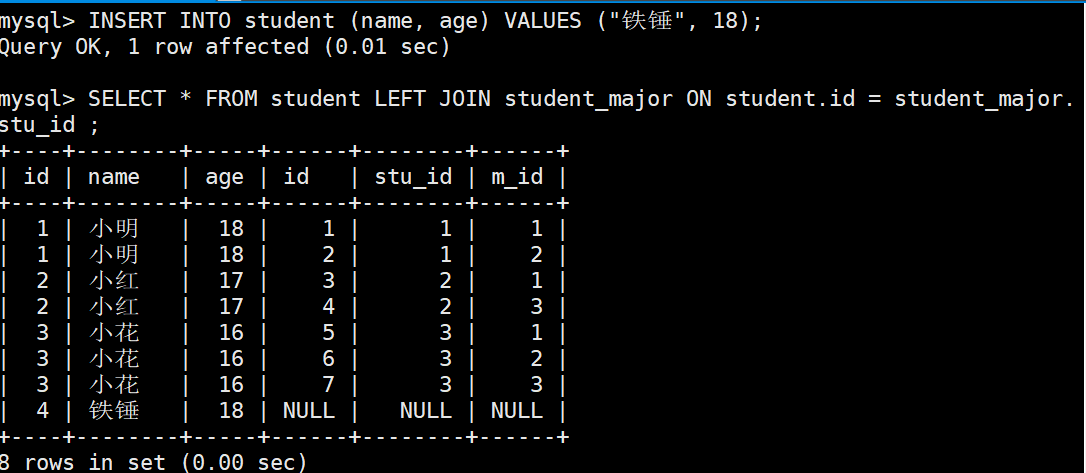
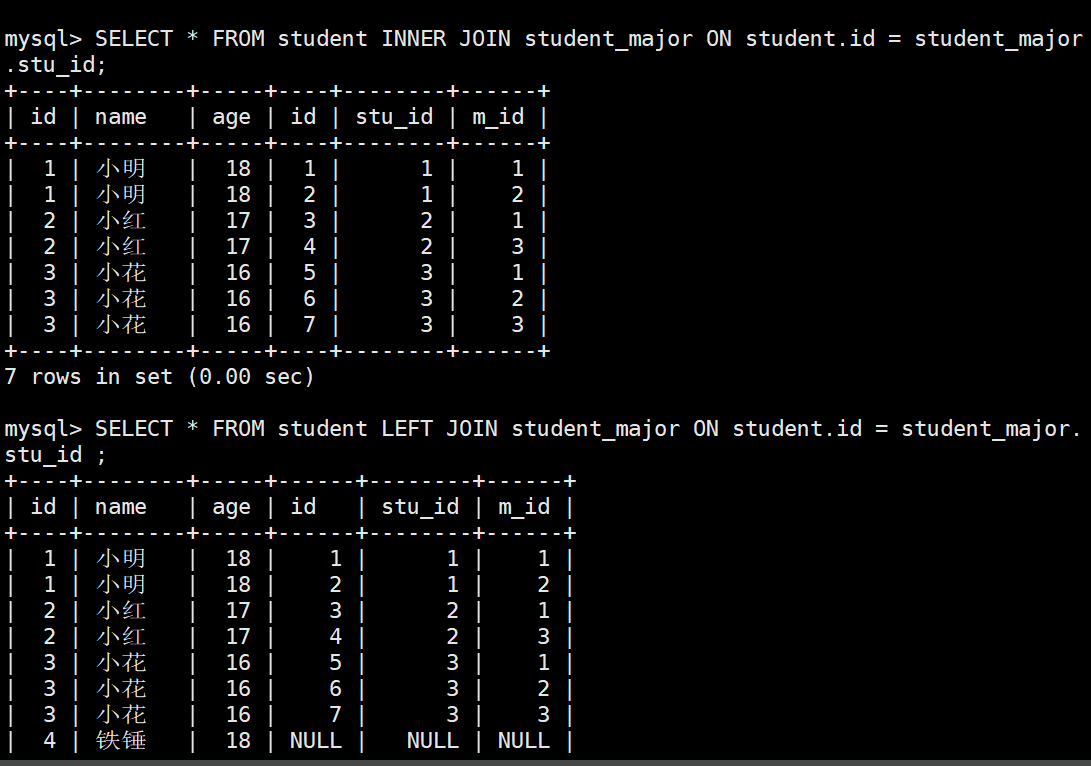
11.2 左连接(LEFT JOIN)
左连接顾名思义就是以左边的表为主表,其他的表为副表;也就是说会把左边表中所有的符合条件的数据全部查询出来,至于后面的表有没有内容不管,没有内容则用空来代替。
# 案例:
-- 插入一个学生数据
mysql> INSERT INTO student (name, age) VALUES ("铁锤", 18);
mysql> SELECT * FROM student LEFT JOIN student_major ON student.id = student_major.stu_id ;
mysql> SELECT * FROM student INNER JOIN student_major ON student.id = student_major.stu_id;
mysql> SELECT * FROM student LEFT JOIN student_major ON student.id = student_major.stu_id ;
mysql> SELECT * FROM student INNER JOIN student_major ON student.id = student_major.stu_id;
11.3 右链接(Right JOIN)
右链接顾名思义就是用右边表作为主表,其他表作为副表。也就是说,右链接是会把右边的表中的所有的数据全部都查询出来,至于左边的表如果没有数据既用空代替。
# 案例:
mysql> INSERT INTO student_major (stu_id,m_id) VALUES (4, 5);
mysql> SELECT * FROM major LEFT JOIN student_major ON major.id = student_major.m_id;
+----+--------+------+--------+------+
| id | name | id | stu_id | m_id |
+----+--------+------+--------+------+
| 1 | 数学 | 1 | 1 | 1 |
| 2 | 英语 | 2 | 1 | 2 |
| 1 | 数学 | 3 | 2 | 1 |
| 3 | 毛概 | 4 | 2 | 3 |
| 1 | 数学 | 5 | 3 | 1 |
| 2 | 英语 | 6 | 3 | 2 |
| 3 | 毛概 | 7 | 3 | 3 |
| 4 | Linux | NULL | NULL | NULL |
+----+--------+------+--------+------+
8 rows in set (0.00 sec)
mysql> SELECT * FROM major RIGHT JOIN student_major ON major.id = student_major.m_id;
+------+--------+----+--------+------+
| id | name | id | stu_id | m_id |
+------+--------+----+--------+------+
| 1 | 数学 | 1 | 1 | 1 |
| 1 | 数学 | 3 | 2 | 1 |
| 1 | 数学 | 5 | 3 | 1 |
| 2 | 英语 | 2 | 1 | 2 |
| 2 | 英语 | 6 | 3 | 2 |
| 3 | 毛概 | 4 | 2 | 3 |
| 3 | 毛概 | 7 | 3 | 3 |
| NULL | NULL | 8 | 4 | 5 |
+------+--------+----+--------+------+
8 rows in set (0.00 sec)
mysql> SELECT * FROM major INNER JOIN student_major ON major.id = student_major.m_id;
+----+--------+----+--------+------+
| id | name | id | stu_id | m_id |
+----+--------+----+--------+------+
| 1 | 数学 | 1 | 1 | 1 |
| 2 | 英语 | 2 | 1 | 2 |
| 1 | 数学 | 3 | 2 | 1 |
| 3 | 毛概 | 4 | 2 | 3 |
| 1 | 数学 | 5 | 3 | 1 |
| 2 | 英语 | 6 | 3 | 2 |
| 3 | 毛概 | 7 | 3 | 3 |
+----+--------+----+--------+------+
7 rows in set (0.00 sec)
11.4 合并数据
顾名思义就是将多个SQL语句查询出来的数据合并一次性查询出来。需要注意的是,两边的字段必须一致。
# 案例:
mysql> SELECT name,age FROM student UNION SELECT * FROM teacher;
+--------+-----------+
| name | age |
+--------+-----------+
| 小明 | 18 |
| 小红 | 17 |
| 小花 | 16 |
| 铁锤 | 18 |
| 1 | 李铁锤 |
| 2 | 石林 |
| 3 | 为李飞 |
+--------+-----------+
7 rows in set (0.00 sec)
12、子查询
子查询顾名思义就是在SQL中依赖于另一个SQL语句的结果来共同查询一个结果。每一个子查询语句只能够返回一条数据。在工作用极其不建议使用子查询,因为子查询的性能非常低。
# 案例:
mysql> SELECT * FROM student WHERE id = (SELECT DISTINCT stu_id FROM student_major LIMIT 1);
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 小明 | 18 |
+----+--------+-----+
1 row in set (0.00 sec)
13、数据库权限管理
MySQL 是一个多用户数据库,具有功能强大的访问控制系统,可以为不同用户指定不同权限。我们使用的是 root 用户,该用户是超级管理员,拥有所有权限,包括创建用户、删除用户和修改用户密码等管理权限。为了实际项目的需要,可以创建拥有不同权限的普通用户。
13.1 Mysql权限表
MySQL 在安装时会自动创建一个名为 mysql 的数据库,mysql 数据库中存储的都是用户权限表。用户登录以后,MySQL 会根据这些权限表的内容为每个用户赋予相应的权限。user 表是 MySQL 中最重要的一个权限表,用来记录允许连接到服务器的账号信息。需要注意的是,在 user 表里启用的所有权限都是全局级的,适用于所有数据库。user 表中的字段大致可以分为 4 类,分别是用户列、权限列、安全列和资源控制列,下面主要介绍这些字段的含义。
13.1.1 用户列
用户列存储了用户连接 MySQL 数据库时需要输入的信息。需要注意的是 MySQL 5.7 版本不再使用 Password 来作为密码的字段,而改成了 authentication_string。
用户登录时,如果这 3 个字段同时匹配,MySQL 数据库系统才会允许其登录。创建新用户时,也是设置这 3 个字段的值。修改用户密码时,实际就是修改 user 表的 authentication_string 字段的值。因此,这 3 个字段决定了用户能否登录。
| 字段名 | 字段类型 | 是否为空 | 默认值 | 说明 |
|---|---|---|---|---|
| Host | char(60) | NO | 无 | 主机名 |
| User | char(32) | NO | 无 | 用户名 |
| authentication_string | text | YES | 无 | 密码 |
13.1.2 权限列
权限列的字段决定了用户的权限,用来描述在全局范围内允许对数据和数据库进行的操作。
权限大致分为两大类,分别是高级管理权限和普通权限:
● 高级管理权限主要对数据库进行管理,例如关闭服务的权限、超级权限和加载用户等;
● 普通权限主要操作数据库,例如查询权限、修改权限等。
user 表的权限列包括 Select_priv、Insert_ priv 等以 priv 结尾的字段,这些字段值的数据类型为 ENUM,可取的值只有 Y 和 N:Y 表示该用户有对应的权限,N 表示该用户没有对应的权限。从安全角度考虑,这些字段的默认值都为 N
如果要修改权限,可以使用 GRANT 语句为用户赋予一些权限,也可以通过 UPDATE 语句更新 user 表的方式来设置权限。
| 字段名 | 字段类型 | 是否为空 | 默认值 | 说明 |
|---|---|---|---|---|
| Select_priv | enum('N','Y') | NO | N | 是否可以通过SELECT 命令查询数据 |
| Insert_priv | enum('N','Y') | NO | N | 是否可以通过 INSERT 命令插入数据 |
| Update_priv | enum('N','Y') | NO | N | 是否可以通过UPDATE 命令修改现有数据 |
| Delete_priv | enum('N','Y') | NO | N | 是否可以通过DELETE 命令删除现有数据 |
| Create_priv | enum('N','Y') | NO | N | 是否可以创建新的数据库和表 |
| Drop_priv | enum('N','Y') | NO | N | 是否可以删除现有数据库和表 |
| Reload_priv | enum('N','Y') | NO | N | 是否可以执行刷新和重新加载MySQL所用的各种内部缓存的特定命令,包括日志、权限、主机、查询和表 |
| Shutdown_priv | enum('N','Y') | NO | N | 是否可以关闭MySQL服务器。将此权限提供给root账户之外的任何用户时,都应当非常谨慎 |
| Process_priv | enum('N','Y') | NO | N | 是否可以通过SHOW PROCESSLIST命令查看其他用户的进程 |
| File_priv | enum('N','Y') | NO | N | 是否可以执行SELECT INTO OUTFILE和LOAD DATA INFILE命令 |
| Grant_priv | enum('N','Y') | NO | N | 是否可以将自己的权限再授予其他用户 |
| References_priv | enum('N','Y') | NO | N | 是否可以创建外键约束 |
| Index_priv | enum('N','Y') | NO | N | 是否可以对索引进行增删查 |
| Alter_priv | enum('N','Y') | NO | N | 是否可以重命名和修改表结构 |
| Show_db_priv | enum('N','Y') | NO | N | 是否可以查看服务器上所有数据库的名字,包括用户拥有足够访问权限的数据库 |
| Super_priv | enum('N','Y') | NO | N | 是否可以执行某些强大的管理功能,例如通过KILL命令删除用户进程;使用SET GLOBAL命令修改全局MySQL变量,执行关于复制和日志的各种命令。(超级权限) |
| Create_tmp_table_priv | enum('N','Y') | NO | N | 是否可以创建临时表 |
| Lock_tables_priv | enum('N','Y') | NO | N | 是否可以使用LOCK TABLES命令阻止对表的访问/修改 |
| Execute_priv | enum('N','Y') | NO | N | 是否可以执行存储过程 |
| Repl_slave_priv | enum('N','Y') | NO | N | 是否可以读取用于维护复制数据库环境的二进制日志文件 |
| Repl_client_priv | enum('N','Y') | NO | N | 是否可以确定复制从服务器和主服务器的位置 |
| Create_view_priv | enum('N','Y') | NO | N | 是否可以创建视图 |
| Show_view_priv | enum('N','Y') | NO | N | 是否可以查看视图 |
| Create_routine_priv | enum('N','Y') | NO | N | 是否可以更改或放弃存储过程和函数 |
| Alter_routine_priv | enum('N','Y') | NO | N | 是否可以修改或删除存储函数及函数 |
| Create_user_priv | enum('N','Y') | NO | N | 是否可以执行CREATE USER命令,这个命令用于创建新的MySQL账户 |
| Event_priv | enum('N','Y') | NO | N | 是否可以创建、修改和删除事件 |
| Trigger_priv | enum('N','Y') | NO | N | 是否可以创建和删除触发器 |
| Create_tablespace_priv | enum('N','Y') | NO | N | 是否可以创建表空间 |
13.1.3 安全列
安全列主要用来判断用户是否能够登录成功。
通常标准的发行版不支持 ssl,读者可以使用 SHOW VARIABLES LIKE "have_openssl" 语句来查看是否具有 ssl 功能。如果 have_openssl 的值为 DISABLED,那么则不支持 ssl 加密功能。
# 注意:即使 password_expired 为“Y”,用户也可以使用密码登录 MySQL,但是不允许做任何操作。
13.1.4 资源控制列
资源控制列的字段用来限制用户使用的资源。
以下字段的默认值为 0,表示没有限制。一个小时内用户查询或者连接数量超过资源控制限制,用户将被锁定,直到下一个小时才可以在此执行对应的操作。可以使用 GRANT 语句更新这些字段的值。
| 字段名 | 字段类型 | 是否为空 | 默认值 | 说明 |
|---|---|---|---|---|
| max_questions | int(11) unsigned | NO | 0 | 规定每小时允许执行查询的操作次数 |
| max_updates | int(11) unsigned | NO | 0 | 规定每小时允许执行更新的操作次数 |
| max_connections | int(11) unsigned | NO | 0 | 规定每小时允许执行的连接操作次数 |
| max_user_connections | int(11) unsigned | NO | 0 | 规定允许同时建立的连接次数 |
13.2 MySQL创建用户
MySQL 在安装时,会默认创建一个名为 root 的用户,该用户拥有超级权限,可以控制整个 MySQL 服务器。
在对 MySQL 的日常管理和操作中,为了避免有人恶意使用 root 用户控制数据库,我们通常创建一些具有适当权限的用户,尽可能地不用或少用 root 用户登录系统,以此来确保数据的安全访问。
MySQL 提供了以下 3 种方法创建用户。
1. 使用 CREATE USER 语句创建用户
2. 在 mysql.user 表中添加用户
3. 使用 GRANT 语句创建用户
13.2.1 使用 CREATE USER 语句创建用户
可以使用 CREATE USER 语句来创建 MySQL 用户,并设置相应的密码。其基本语法格式如下:
CREATE USER <用户> [ IDENTIFIED BY [ PASSWORD ] 'password' ] [ ,用户 [ IDENTIFIED BY [ PASSWORD ] 'password' ]]
1、用户
指定创建用户账号,格式为 user_name'@'host_name。这里的user_name是用户名,host_name为主机名,即用户连接 MySQL 时所用主机的名字。如果在创建的过程中,只给出了用户名,而没指定主机名,那么主机名默认为“%”,表示一组主机,即对所有主机开放权限。
2、IDENTIFIED BY子句
用于指定用户密码。新用户可以没有初始密码,若该用户不设密码,可省略此子句。
3、PASSWORD 'password'
PASSWORD 表示使用哈希值设置密码,该参数可选。如果密码是一个普通的字符串,则不需要使用 PASSWORD 关键字。
# 案例:
mysql> CREATE USER 'test1'@'localhost' IDENTIFIED BY 'test1';
Query OK, 0 rows affected (19.46 sec)
mysql> SELECT password('test2'); -- 查询密码,它是按照password中的字符去生成的密码。
+-------------------------------------------+
| password('test2') |
+-------------------------------------------+
| *7CEB3FDE5F7A9C4CE5FBE610D7D8EDA62EBE5F4E |
+-------------------------------------------+
1 row in set, 1 warning (0.00 sec)
"*06C0BF5B64ECE2F648B5F048A71903906BA08E5C"就是 test1 的哈希值。下面创建用户 test1,SQL 语句和执行过程如下:
mysql> create user 'test2'@'localhost' identified by password '*7CEB3FDE5F7A9C4CE5FBE610D7D8EDA62EBE5F4E';
Query OK, 0 rows affected (0.04 sec)
13.2.2 使用 INSERT 语句新建用户
可以使用 INSERT 语句将用户的信息添加到 mysql.user 表中,但必须拥有对 mysql.user 表的 INSERT 权限。通常 INSERT 语句只添加 Host、User 和 authentication_string 这 3 个字段的值。
# 案例:
mysql> INSERT INTO mysql.user(Host, User, authentication_string, ssl_cipher, x509_issuer, x509_subject) VALUES ('localhost', 'test3', PASSWORD('test3'), '', '', '');
Query OK, 1 row affected, 1 warning (0.00 sec)
-- 使用INSERT创建的用户需要使用FLUSH PRIVILEGES;刷新权限。
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.01 sec)
mysql> exit
Bye
[root@mysql03 ~]# mysql -utest3 -ptest3
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 61
Server version: 5.7.35 MySQL Community Server (GPL)
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
13.2.3 使用GRANT语句新建用户
虽然 CREATE USER 和 INSERT INTO 语句都可以创建普通用户,但是这两种方式不便授予用户权限。于是 MySQL 提供了 GRANT 语句(常用)。语法格式为:GRANT priv_type ON database.table TO user [IDENTIFIED BY [PASSWORD] 'password']
其中:
● priv_type 参数表示新用户的权限
● database.table 参数表示新用户的权限范围,即只能在指定的数据库和表上使用自己的权限
● user 参数指定新用户的账号,由用户名和主机名构成
● IDENTIFIED BY 关键字用来设置密码
● password 参数表示新用户的密码
# 案例:
mysql> GRANT SELECT ON *.* TO 'test4'@'localhost' IDENTIFIED BY 'test4';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'test5'@'localhost' IDENTIFIED BY 'test5';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
-- ALL PRIVILEGES : 给所有的权限
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
13.3 MySQL修改用户
在 MySQL 中,我们可以使用 RENAME USER 语句修改一个或多个已经存在的用户账号。
语法格式如下:RENAME USER <旧用户> TO <新用户>
其中:
● <旧用户>:系统中已经存在的 MySQL 用户账号。
● <新用户>:新的 MySQL 用户账号。
# 案例:
mysql> RENAME USER 'test4'@'localhost' TO 'test4'@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> select host,user from mysql.user;
+-----------+---------------+
| host | user |
+-----------+---------------+
| % | root |
| % | test01 |
| % | user |
| localhost | mysql.session |
| localhost | mysql.sys |
| localhost | root |
| localhost | test1 |
| localhost | test2 |
| localhost | test3 |
| localhost | test5 |
+-----------+---------------+
10 rows in set (0.00 sec)
mysql> exit
Bye
[root@mysql03 ~]# mysql -utest5 -ptest4 # 使用修改后的账户名和原密码登录
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 16
Server version: 5.7.36 Source distribution
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
13.4 MySQL删除用户
在 MySQL 数据库中,可以使用 DROP USER 语句删除用户,也可以直接在 mysql.user 表中删除用户以及相关权限。
1、使用 DROP USER 语句删除普通用户:DROP USER <用户1> [ , <用户2> ]…
# 案例:
mysql> drop user test01@'%';
Query OK, 0 rows affected (0.01 sec)
mysql> DROP USER test2;
Query OK, 0 rows affected (0.00 sec)
2、使用DELETE语句删除普通用户:可以使用 DELETE 语句直接删除 mysql.user 表中相应的用户信息,但必须拥有 mysql.user 表的 DELETE 权限。格式:DELETE FROM mysql.user WHERE Host='hostname' AND User='username';
# 案例:
mysql> delete from mysql.user where host='localhost' and user='test2';
Query OK, 1 row affected (0.00 sec)
13.5 MySQL查看权限
在 MySQL 中,可以通过查看 mysql.user 表中的数据记录来查看相应的用户权限,也可以使用 SHOW GRANTS 语句查询用户的权限。格式:SHOW GRANTS FOR 'username'@'hostname';
# 案例:
mysql> SHOW GRANTS FOR 'test3'@'localhost';
+-------------------------------------------+
| Grants for test3@localhost |
+-------------------------------------------+
| GRANT USAGE ON *.* TO 'test3'@'localhost' |
+-------------------------------------------+
1 row in set (0.00 sec)
mysql> SHOW GRANTS FOR 'root'@'localhost';
+---------------------------------------------------------------------+
| Grants for root@localhost |
+---------------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION |
| GRANT PROXY ON ''@'' TO 'root'@'localhost' WITH GRANT OPTION |
+---------------------------------------------------------------------+
2 rows in set (0.00 sec)
13.6 MySQL授权
授权就是为某个用户赋予某些权限。例如,可以为新建的用户赋予查询所有数据库和表的权限。MySQL 提供了 GRANT 语句来为用户设置权限。
在 MySQL 中,拥有 GRANT 权限的用户才可以执行 GRANT 语句,其语法格式如下:
GRANT priv_type [(column_list)] ON database.table
TO user [IDENTIFIED BY [PASSWORD] 'password']
[, user[IDENTIFIED BY [PASSWORD] 'password']] ...
[WITH with_option [with_option]...]
其中:
● priv_type 参数表示权限类型;
● columns_list 参数表示权限作用于哪些列上,省略该参数时,表示作用于整个表;
● database.table 用于指定权限的级别;
● user 参数表示用户账户,由用户名和主机名构成,格式是“'username'@'hostname'”;
● IDENTIFIED BY 参数用来为用户设置密码;
● password 参数是用户的新密码。
WITH 关键字后面带有一个或多个 with_option 参数。这个参数有 5 个选项,详细介绍如下:
● GRANT OPTION:被授权的用户可以将这些权限赋予给别的用户;
● MAX_QUERIES_PER_HOUR count:设置每个小时可以允许执行 count 次查询;
● MAX_UPDATES_PER_HOUR count:设置每个小时可以允许执行 count 次更新;
● MAX_CONNECTIONS_PER_HOUR count:设置每小时可以建立 count 个连接;
● MAX_USER_CONNECTIONS count:设置单个用户可以同时具有的 count 个连接。
MySQL 中可以授予的权限有如下几组:
● 列权限,和表中的一个具体列相关。例如,可以使用 UPDATE 语句更新表 students 中 name 列的值的权限。
● 表权限,和一个具体表中的所有数据相关。例如,可以使用 SELECT 语句查询表 students 的所有数据的权限。
● 数据库权限,和一个具体的数据库中的所有表相关。例如,可以在已有的数据库 mytest 中创建新表的权限。
● 用户权限,和 MySQL 中所有的数据库相关。例如,可以删除已有的数据库或者创建一个新的数据库的权限。
对应地,在 GRANT 语句中可用于指定权限级别的值有以下几类格式:
● *:表示当前数据库中的所有表。
● *.*:表示所有数据库中的所有表。
● db_name.*:表示某个数据库中的所有表,db_name 指定数据库名。
● db_name.tbl_name:表示某个数据库中的某个表或视图,db_name 指定数据库名,tbl_name 指定表名或视图名。
13.6.1 权限类型
授予数据库权限时,<权限类型>可以指定为以下值:
| 权限名称 | 对应user表中的字段 | 说明 |
|---|---|---|
| SELECT | Select_priv | 表示授予用户可以使用 SELECT 语句访问特定数据库中所有表和视图的权限。 |
| INSERT | Insert_priv | 表示授予用户可以使用 INSERT 语句向特定数据库中所有表添加数据行的权限。 |
| DELETE | Delete_priv | 表示授予用户可以使用 DELETE 语句删除特定数据库中所有表的数据行的权限。 |
| UPDATE | Update_priv | 表示授予用户可以使用 UPDATE 语句更新特定数据库中所有数据表的值的权限。 |
| REFERENCES | References_priv | 表示授予用户可以创建指向特定的数据库中的表外键的权限。 |
| CREATE | Create_priv | 表示授权用户可以使用 CREATE TABLE 语句在特定数据库中创建新表的权限。 |
| ALTER | Alter_priv | 表示授予用户可以使用 ALTER TABLE 语句修改特定数据库中所有数据表的权限。 |
| SHOW VIEW | Show_view_priv | 表示授予用户可以查看特定数据库中已有视图的视图定义的权限。 |
| CREATE ROUTINE | Create_routine_priv | 表示授予用户可以为特定的数据库创建存储过程和存储函数的权限。 |
| ALTER ROUTINE | Alter_routine_priv | 表示授予用户可以更新和删除数据库中已有的存储过程和存储函数的权限。 |
| INDEX | Index_priv | 表示授予用户可以在特定数据库中的所有数据表上定义和删除索引的权限。 |
| DROP | Drop_priv | 表示授予用户可以删除特定数据库中所有表和视图的权限。 |
| CREATE TEMPORARY TABLES | Create_tmp_table_priv | 表示授予用户可以在特定数据库中创建临时表的权限。 |
| CREATE VIEW | Create_view_priv | 表示授予用户可以在特定数据库中创建新的视图的权限。 |
| EXECUTE ROUTINE | Execute_priv | 表示授予用户可以调用特定数据库的存储过程和存储函数的权限。 |
| LOCK TABLES | Lock_tables_priv | 表示授予用户可以锁定特定数据库的已有数据表的权限。 |
| ALL 或 ALL PRIVILEGES 或 SUPER | Super_priv | 表示以上所有权限/超级权限 |
13.6.2 用户授权
# 案例:
使用 GRANT 语句创建一个新的用户 test7,密码为 test7。用户 testUser 对所有的数据有查询、插入权限,并授予 GRANT 权限。SQL 语句和执行过程如下:
mysql> GRANT SELECT,INSERT ON *.* TO 'test7'@'localhost' IDENTIFIED BY 'test7' WITH GRANT OPTION;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> SHOW GRANTS FOR 'test7'@'localhost';
+----------------------------------------------------------------------+
| Grants for test7@localhost |
+----------------------------------------------------------------------+
| GRANT SELECT, INSERT ON *.* TO 'test7'@'localhost' WITH GRANT OPTION |
+----------------------------------------------------------------------+
1 row in set (0.00 sec)
# 注:常用的权限:SELECT, SHOW VIEW : 数据库可读权限。
13.6.2 删除用户权限
在 MySQL 中,可以使用 REVOKE 语句删除某个用户的某些权限(此用户不会被删除),在一定程度上可以保证系统的安全性。例如,如果数据库管理员觉得某个用户不应该拥有 DELETE 权限,那么就可以删除 DELETE 权限。
1、删除用户某些特定的权限,格式:
REVOKE priv_type [(column_list)]...
ON database.table
FROM user [, user]...
REVOKE 语句中的参数与 GRANT 语句的参数意思相同。其中:
● priv_type 参数表示权限的类型
● column_list 参数表示权限作用于哪些列上,没有该参数时作用于整个表上
● user 参数由用户名和主机名构成,格式为'username'@'hostname'
2、删除特定用户的所有权限,格式:REVOKE ALL PRIVILEGES, GRANT OPTION FROM user [, user] ...
删除用户权限需要注意以下几点:
● REVOKE 语法和 GRANT 语句的语法格式相似,但具有相反的效果。
● 要使用 REVOKE 语句,必须拥有 MySQL 数据库的全局 CREATE USER 权限或 UPDATE 权限。
# 案例:
mysql> REVOKE INSERT ON *.* FROM 'test7'@'localhost';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> SHOW GRANTS FOR 'test7'@'localhost';
+--------------------------------------------------------------+
| Grants for test7@localhost |
+--------------------------------------------------------------+
| GRANT SELECT ON *.* TO 'test7'@'localhost' WITH GRANT OPTION |
+--------------------------------------------------------------+
1 row in set (0.00 sec)
13.7 MySQL登录和退出
启动 MySQL 服务后,可以使用以下命令来登录。
mysql -h hostname|hostlP -p port -u username -p DatabaseName -e "SQL语句"
-- 退出
exit
quit
\q
14、MySQL存储引擎
据库存储引擎是数据库底层软件组件,数据库管理系统使用数据引擎进行创建、查询、更新和删除数据操作。简而言之,存储引擎就是指表的类型。数据库的存储引擎决定了表在计算机中的存储方式。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎还可以获得特定的功能。
现在许多数据库管理系统都支持多种不同的存储引擎。MySQL 的核心就是存储引擎。
MySQL 提供了多个不同的存储引擎,包括处理事务安全表的引擎和处理非事务安全表的引擎。在 MySQL 中,不需要在整个服务器中使用同一种存储引擎,针对具体的要求,可以对每一个表使用不同的存储引擎。
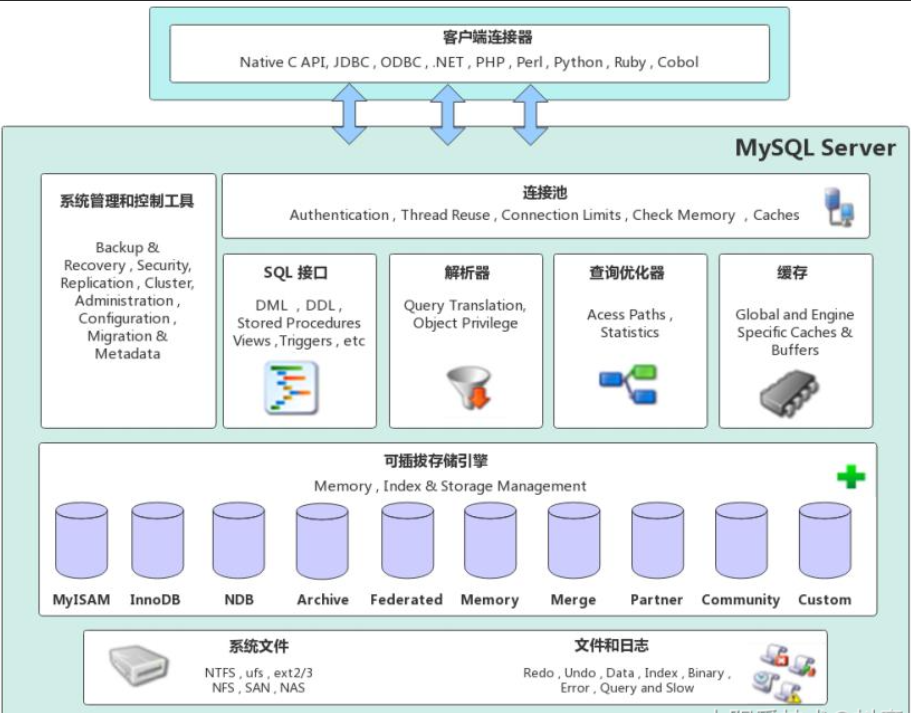
14.1 存储引擎
关系数据库表是用于存储和组织信息的数据结构,可以将表理解为由行和列组成的表格,类似于Excel的电子表格的形式。有的表简单,有的表复杂,有的表根本不用来存储任何长期的数据,有的表读取时非常快,但是插入数据时去很差。而我们在实际开发过程中,就可能需要各种各样的表,不同的表,就意味着存储不同类型的数据,数据的处理上也会存在着差异。那么,对于MySQL来说,它提供了很多种类型的存储引擎,我们可以根据对数据处理的需求,选择不同的存储引擎,从而最大限度的利用MySQL强大的功能。这篇博文将总结和分析各个引擎的特点,以及适用场合,并不会纠结于更深层次的东西。我的学习方法是先学会用,懂得怎么用,再去知道到底是如何能用的。下面就对MySQL支持的存储引擎进行简单的介绍。
| 存储引擎 | 描述 |
|---|---|
| ARCHIVE | 用于数据存档的引擎,数据被插入后就不能在修改了(只支持SELECT和INSERT语句),且不支持索引。 |
| CSV | 在存储数据时,会以逗号作为数据项之间的分隔符。 |
| BLACKHOLE | 会丢弃写操作,该操作会返回空内容。 |
| FEDERATED | 将数据存储在远程数据库中,用来访问远程表的存储引擎。 |
| InnoDB | 支持事务、行级锁以及外键等功能。 |
| MEMORY | 置于内存的表,也就是说将数据存放于内存之中,类似于Redis。 |
| MERGE | 用来管理由多个 MyISAM 表构成的表集合。 |
| MyISAM | 主要的非事务处理存储引擎,性能相对于InnoDB来说要高一些。 |
| NDB | MySQL 集群专用存储引擎 |
14.2 查看存储引擎信息
通常情况下,我们使用数据库存储数据的时候,都会使用到存储引擎,下面我们来一起看看MySQL数据库支持哪些存储引擎。
1.查看当前数据库中支持的存储引擎
mysql> show engines;
2.临时设置数据库存储引擎
mysql> set default_storage_engine=MyISAM;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| MyISAM |
+--------------------------+
1 row in set (0.00 sec)
3.查看某个表的存储引擎
mysql> SHOW CREATE TABLE db1.db01\G
*************************** 1. row ***************************
Table: db01
Create Table: CREATE TABLE `db01` (
`name` varchar(20) DEFAULT NULL,
`id` int(11) NOT NULL AUTO_INCREMENT,
`sex` varchar(20) DEFAULT NULL,
`addr` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> SELECT TABLE_NAME, ENGINE FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'db01' AND TABLE_SCHEMA = 'db1'\G
*************************** 1. row ***************************
TABLE_NAME: db01
ENGINE: InnoDB
1 row in set (0.00 sec)
mysql> SELECT ENGINE FROM information_schema.TABLES WHERE TABLE_NAME="pm20";
+--------+
| ENGINE |
+--------+
| MyISAM |
+--------+
1 row in set (0.00 sec)
4.查看myisam的表有哪些
mysql> select table_schema,table_name,engine from information_schema.tables where engine='myisam';
+--------------+------------------+--------+
| table_schema | table_name | engine |
+--------------+------------------+--------+
| db1 | Dem_Picture | MyISAM |
| db1 | t2 | MyISAM |
| mysql | columns_priv | MyISAM |
| mysql | db | MyISAM |
| mysql | event | MyISAM |
| mysql | func | MyISAM |
| mysql | ndb_binlog_index | MyISAM |
| mysql | proc | MyISAM |
| mysql | procs_priv | MyISAM |
| mysql | proxies_priv | MyISAM |
| mysql | tables_priv | MyISAM |
| mysql | user | MyISAM |
+--------------+------------------+--------+
12 rows in set (0.07 sec)
5.查看innodb的表有哪些
mysql> select table_schema,table_name,engine from information_schema.tables where engine='innodb';
+--------------------+---------------------------+--------+
| table_schema | table_name | engine |
+--------------------+---------------------------+--------+
| information_schema | COLUMNS | InnoDB |
| information_schema | EVENTS | InnoDB |
| information_schema | OPTIMIZER_TRACE | InnoDB |
| information_schema | PARAMETERS | InnoDB |
| information_schema | PARTITIONS | InnoDB |
| information_schema | PLUGINS | InnoDB |
| information_schema | PROCESSLIST | InnoDB |
| information_schema | ROUTINES | InnoDB |
| information_schema | TRIGGERS | InnoDB |
| information_schema | VIEWS | InnoDB |
| db1 | db01 | InnoDB |
| db1 | t1 | InnoDB |
| mysql | engine_cost | InnoDB |
| mysql | gtid_executed | InnoDB |
| mysql | help_category | InnoDB |
| mysql | help_keyword | InnoDB |
| mysql | help_relation | InnoDB |
| mysql | help_topic | InnoDB |
| mysql | innodb_index_stats | InnoDB |
| mysql | innodb_table_stats | InnoDB |
| mysql | plugin | InnoDB |
| mysql | server_cost | InnoDB |
| mysql | servers | InnoDB |
| mysql | slave_master_info | InnoDB |
| mysql | slave_relay_log_info | InnoDB |
| mysql | slave_worker_info | InnoDB |
| mysql | time_zone | InnoDB |
| mysql | time_zone_leap_second | InnoDB |
| mysql | time_zone_name | InnoDB |
| mysql | time_zone_transition | InnoDB |
| mysql | time_zone_transition_type | InnoDB |
| sys | sys_config | InnoDB |
| test | student | InnoDB |
| test | t1 | InnoDB |
+--------------------+---------------------------+--------+
34 rows in set (0.01 sec)
14.3 修改存储引擎
在使用数据库的时候,我们经常会去使用不同的存储引擎来存储数据,那就难免需要修改存储引擎。下面我们介绍几个存储引擎的修改方法。
1.修改配置文件(永久)
[root@mysql03 ~]# vim /etc/my.cnf
[mysqld]
default-storage-engine=innodb
innodb_file_per_table=1 # InnoDB独立表空间
2.临时修改存储引擎(临时)
mysql> set default_storage_engine=MyISAM;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| MyISAM |
+--------------------------+
1 row in set (0.00 sec)
3.创建表的时候修改存储引擎
CREATE TABLE shanhe(id INT) ENGINE=innodb;
14.5 存储引擎的实验
mysql> use db1;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> create table t1(id int)engine=innodb;
Query OK, 0 rows affected (0.03 sec)
mysql> create table t2(id int)engine=myisam;
Query OK, 0 rows affected (0.00 sec)
mysql> create table t3(id int)engine=memory;
Query OK, 0 rows affected (0.00 sec)
mysql> create table t4(id int)engine=blackhole;
Query OK, 0 rows affected (0.00 sec)
mysql> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| t1 |
| t2 |
| t3 |
| t4 |
+---------------+
6 rows in set (0.00 sec)
mysql> exit
Bye
[root@mysql03 /var/lib/mysql/db1]# ls
t1.frm t1.ibd t2.MYD t2.MYI t2.frm t3.frm t4.frm
# 发现后两种存储引擎只有表结构,无数据。
# memory,在重启mysql或者重启机器后,表内数据清空。
# blackhole,往表内插入任何数据,都相当于丢入黑洞,表内永远不存记录。
# innodb支持事务,而myisam存储引擎是不支持事务。
15、InnoDB存储引擎
InnoDB 引擎是MySQL数据库的一个重要的存储引擎、跟所有的二进制安装包里面、和其它的存储引擎相比、InnoDB引擎的优点是支持事务、以及参数完整性(有外键)等。MySQL5.5.5以后默认的存储引擎都是InnoDB引擎。
15.1 InnoDB的逻辑架构原理
InnoDB的逻辑架构有三个组成部分,分别是:在内存中的架构(In-Memory Structures)、操作系统缓存(Operating System Cache)和在硬盘上的架构(On-Disk Structures);这三个架构组成了一款高性能的InnoDB存储引擎。
15.1.1 内存中的架构(In-Memory Structures)
InnoDB在内存架构上主要分成四个部分,分别是:缓冲池(Buffer Pool)、写缓冲(Change Buffer)、日志缓冲(Log Buffer)以及自适应哈希索引(Adaptive Hash Index)。我们知道计算机优化速度主要从两个方面:即网络IO和磁盘IO。
优化磁盘IO:利用内存空间换取磁盘时间:
在读数据的时候需要查询磁盘,会造成磁盘IO过高,磁盘延时严重,磁盘变得更慢。这时候自适应哈希索引发挥作用,一旦发现数据适合添加索引,就会自动添加索引,返回到缓冲池里面的链表中。链表分成新子链表和旧子链表,在每次查询数据的时候,查询到的数据会自动添加到新子链表最前面,也就是形成热点,方便下一次查询的时候可以最快读到数据,因而当前链表里面的数据就按顺序往后排。如果一次性查询的数据量过大的时候,为了保护热点数据被挤出链表,在下一次查询的时候又从磁盘中读数而造成磁盘压力大,也只会按照新链表的内存容量把查询出的数据添加到新链表,把当前链表的热点推到旧链表中。这就能极大缓解了磁盘的IO压力问题。写缓冲区的核心也是为了缓解磁盘IO过高的问题,在需要修改数据的数据,把数据读到Change Buffer,修改完成后保存在Change Buffer,在两种情况下再存入磁盘中。第一种是临时查询数据的时候,会从Change Buffer把保存好的数据加载到缓冲池(Buffer Pool),同时再写入磁盘中;第二种是master线程10秒钟会执行一次把Change Buffer中的数据写入磁盘中。为了避免Change Buffer修改完成的数据未在写入磁盘前服务器宕机导致Change Buffer的数据丢失,日志缓冲(Log Buffer)就会发挥作用,把Change Buffer的数据写入到redo log进行保存,Log Buffer的作用也是为了减少redo log的IO压力。
1. 缓冲池(Buffer Pool)
缓冲池是一块用于缓存被访问过的表和索引数据的内存区域,缓冲池允许在内存中处理一些被用户频繁访问的数据,在某一些专用的服务器上,甚至有可能使用80%的物理内存作为缓冲池。缓冲池的存在主要是为了通过降低磁盘IO的次数来提升数据的访问性能。
缓冲池
2. 写缓冲(Change Buffer)
写缓冲是为了缓存缓冲池(Buffer Pool)中不存在的二级索引(Secondary Index)页的变更操作的一种特殊的内存数据结构。
这些变更通常是一些Insert、Update、Delete等DML操作引发的,如果有一些其它的读操作将这些被变更的二级索引页加进了缓冲池(Buffer Pool),则这些变更会被马上合并至缓冲池中以保证用户可以读取到一致的数据。
3. 日志缓冲(Log Buffer)
InnoDB将数据的每次写优化为了批量写,这便以降低磁盘IO的次数,为了防止一些数据尚未写入硬盘就断电了,需要记录日志;而日志缓冲就是用来缓存一些即将要被写入磁盘日志文件(log files)中的数据。
4. 自适应哈希索引(Adaptive Hash Index)
在InnoDB中,用户是不可以直接去创建哈希索引的,这个自适应哈希索引是InnoDB为了加速查询性能,会根据实际需要来决定是否对于一些频繁需要被访问的索引页构建哈希索引,它会利用key的前缀来构建哈希索引。这样做可以提高查询性能,因为索引采用类似B+树的结构进行存储,B+树的单key查询时间复杂度为O(log2n),但是优化为哈希索引后,单key的查询时间复杂度就为O(1)了。
15.1.2 操作系统缓存(Operating System Cache)
操作系统为了提升性能而降低磁盘IO的次数,在InnoDB的缓存体系与磁盘文件之间,加了一层操作系统的缓存/页面缓存。用户态innodb存储引擎的进程向操作系统发起write系统调用时,在内核态完成页面缓存写入后即返回,如果想立即将页面缓存的内容立即刷入磁盘,innodb存储引擎需要发起fsync系统调用才可以。
15.1.3 硬盘上的架构(On-Disk Structures)
InnoDB在硬盘上总共分为六个部分,分别是表(Tables)、表空间(Tablespaces)、索引(Indexes)、双写缓冲(Doublewrite Buffer)、Redo日志和Undo段
。
1. 表(Tables)
a. 如果已经指定了数据的默认存储引擎,那么创建表的时候,无需指定再指定存储引擎。
b. 默认情况下,创建InnoDB表的时候innodb_file_per_table参数是开启的,它表明用户创建的表和索引,会被以单表单文件的形式放入到file-per-table表空间中。
c. 如果禁用了该参数innodb_file_per_table,那么表及索引会被放入系统表空间(System Tablespaces)中。
d. 如果创建表的时候,想要把表创建在通用表空间(General Tablespaces)中,那么需要用户使用CREATE TABLE … TABLESPACE语法来创建表结构。
2. 表空间(Tablespaces)
a. 系统表空间(System Tablespaces):系统表空间主要用于存储双写缓冲、写缓存以及用户创建的表和索引(当innodb_file_per_table被禁用的情况下)
b. file-per-table表空间(file-per-tableTablespaces):存储用户创建的表和索引数据,默认情况下(innodb_file_per_table参数是启用的)
c. 通用表空间(General Tablespaces):通用表空间允许用户存储一些自己想要放进通常表空间的表或数据,需要用户创建表的时候,自己指定采用通用表空间,上面讲表的时候已经介绍过。
d. 回滚表空间(Undo Tablespaces):回滚表空间是为了存储回滚日志,通常回滚日志在表空间会以回滚段(Undo Segments)的形式存在。
e. 临时表空间(Temporary Tablespaces):临时表空间用于存储用户创建的临时表,或者优化器内部自己创建的临时表。
3. 索引(Indexes)
索引存在的目的主要是为了加速数据的读取速度,InnoDB采用BTree(实际为优化改进后的B+树索引)。主键索引也是聚集索引,二级索引都是非聚集索引。自适应哈希索引是InnoDB为了加速查询性能,它自己按需在内存中对加载进内存的BTree索引优化为哈希索引的一种手段。
4. 双写缓冲(Doublewrite Buffer)
双写缓冲是一个在系统表空间System Tablespaces中存储区,在这个存储区中,在InnoDB将页面写入InnoDB数据文件中的适当位置之前,会先从缓冲池中刷新页面 。如果在页面写入过程中发生操作系统,存储子系统或mysqld进程崩溃,则InnoDB可以在崩溃恢复期间从双写缓冲中找到页面的原来的数据。
5. Redo日志
redo即redo日志,是用于记录数据库中数据变化的日志,只要你修改了数据块那么就会记录redo信息。
你的每次操作都会先记录到redo日志中,当出现实例故障(像断电),导致数据未能更新到数据文件,则数据库重启时须redo,重新把数据更新到数据文件。
6. Undo段
undo即undo段,是指数据库为了保持读一致性(原子性),存储历史数据在一个位置。 用于记录更改前的一份copy,用于回滚、撤销还原。
# 案例
mysql> show global variables like '%undo%';
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 |
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
+--------------------------+------------+
5 rows in set (0.00 sec)
mysql> show global variables like '%truncate%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| innodb_purge_rseg_truncate_frequency | 128 |
| innodb_undo_log_truncate | OFF |
+--------------------------------------+-------+
2 rows in set (0.00 sec)
15.2 innodb存储引擎执行流程
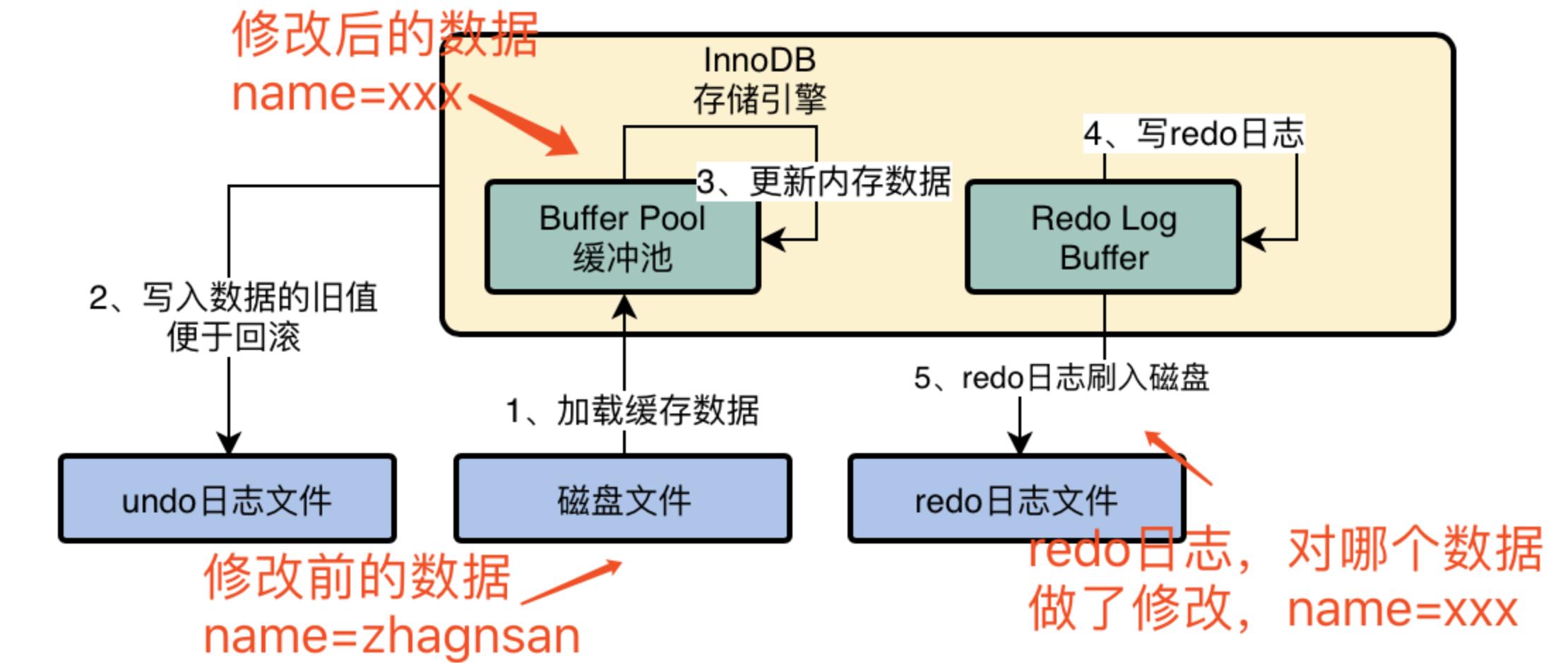
执行一条更新sql语句,存储引擎执行流程可以分为三大阶段,8个小步骤:
1. 三大阶段
a. 执行阶段:数据从磁盘加载到内存,写undo log,更新内存中数据,写redo log buffer
b. 事务提交阶段:redo log和binlog刷盘,commit标记写入redo log中
c. 写入磁盘:后台io线程随机把内存中脏数据刷到磁盘上
# 注:InnoDB存储引擎中的每一条修改数据的SQL都是一个事务。
2. 八个小步骤
a. 把需要更新的数据从磁盘加载到buffer pool中,并对该数据进行加锁
b. 把旧数据(从磁盘中加载出来的未更新的数据)写入undo log,以便修改出错情况下的回滚(回滚就是把旧数据从undo log加载到buffer pool中)
c. 在缓冲池buffer pool中的进行数据更新,得到脏数据(脏数据即更新后未刷入磁盘的数据)
d. 把修改后的数据(脏数据)写入到redo log buffer当中(redo log buffer缓冲写入redo log的时候产生的IO压力)
e. 准备提交事务redo log刷入磁盘(把脏数据从redo log buffer写入redo log)
f. 把修改的操作记录准备写入binlog日志
g. 把binlog的文件名和位置写入commit(预提交)标记,commit标记写入redolog中(redo log中存放的修改后的数据与binlog中的修改操作对应上,双管齐下),事务才算提交成功;否则不会成功
h. IO线程(master线程)或者数据查询时Buffer Pool中的脏数据刷入磁盘文件,完成最终修改
# 注:脏数据就是写入了内存中还没有来得及写入硬盘的数据就称之为脏数据。
15.3 InnoDB中进程
innodb存储引擎是多线程的模型,因此其在后台有多个不同的后台线程,负责处理不同工作任务。下面我们进行详细的讲解。
# 总结:master线程指挥Page cleaner线程去把磁盘数据拿给IO线程进行IO操作磁盘,最后Purge Thread回收垃圾。
1、master thread
master thread是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷到磁盘,保障数据的一致性,其中包括脏页的刷新、合并插入缓冲(insert buffer) undo页的回收。
2、IO thread
在Innodb存储引擎中大量使用了AIO(Async IO即异步IO)来处理写IO请求,这样可以极大提高了数据库的性能。而IO thread 的工作主要负责这些IO请求的回调(call back)处理。
innodb 1.0版本之前共有4个IO thread ,分别是write 、read 、insert buffer和log io thread。在linux平台下,iO thread 的数量不能进行调整,但是在window平台上可以通过参数innodb_file_io_thread来增大IO thread来增大IO thread ,从innodb 1.0.x版本开始,read thread 和write thread分别增大到了4个,并且不再使用innodb_file_io_threads参数,而是分别使用innodb_read_io_thread和innodb_write_io_threads参数进行设置:
mysql> show variables like '%io_thread%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_read_io_threads | 4 |
| innodb_write_io_threads | 4 |
+-------------------------+-------+
2 rows in set (0.00 sec)
# 查看IO thread进程状态
mysql> show engine innodb status\G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2021-09-27 15:20:40 0x7fa18c620700 INNODB MONITOR OUTPUT
=====================================
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
327 OS file reads, 158 OS file writes, 31 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
# 可以看到IO thread 0为insert buffer thread。io thread 1为log thread.之后就是根据参数innodb_read_io_thread及innodb_write_io_threads来设置的读写线程,并且读线程iD总是小于写线程。
3、Purge Thread
事务被提交后,其所使用的undolog可能不再需要,因为需要purge thread来回收已经使用并分配的undo页。在innodb1.1版本之前,purge操作仅在innodb存储引擎的master thread中完成,而从innodb1.1版本开始,purge操作可以独立到单独的线程中进行,以此来减轻master thread的工作,从而提供cpu的使用率以及提升存储引擎的性能,用户可以在配置文件中进行配置:
mysql> show variables like '%purge_thread%';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| innodb_purge_threads | 4 |
+----------------------+-------+
1 row in set (0.01 sec)
4、Page cleaner thread
Page cleaner thread作用是将之前版本中的脏页的刷新操作都放入到单独的线程中来完成,而其目的是为了减轻master thread 的工作及对于用户查询线程的阻塞,进一步提高innodb存储引擎的性能。
# 注:当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。
16、索引原理与慢查询优化
索引是存储引擎中一种数据结构,或者说数据的组织方式,又称之为键key,是存储引擎用于快速找到记录的一种数据结构。 为数据建立索引就好比是为书建目录,或者说是为字典创建音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
16.1 使用索引的好处
一般的应用系统,读写比例在9:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的、也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。 索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
16.2 理解索引的储备知识
要了解索引的数据结构需要先来储备一些知识。
1.储备知识1:机械磁盘一次IO的时间
机械磁盘一次io的时间 = 寻道时间 + 旋转延迟 + 传输时间
# 寻道时间
寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下
# 旋转延迟
旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;
# 传输时间
传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计
所以访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右
这9ms对于人来说可能非常短,但对于计算机来可是非常长的一段时间,长到什么程度呢?
一台500 -MIPS(Million Instructions Per Second)的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行约450万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
2.储备知识2:磁盘的预读
# 考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化:
当一次IO时,不光读当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
3.储备知识3:索引原理精髓提炼
# 索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等
本质都是:
通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
16.3 索引分类
索引模型分为很多种类:
#===========B+树索引(等值查询与范围查询都快)
二叉树->平衡二叉树->B树->B+树
#===========HASH索引(等值查询快,范围查询慢)
将数据打散再去查询
#===========FULLTEXT:全文索引 (只可以用在MyISAM引擎)
通过关键字的匹配来进行查询,类似于like的模糊匹配
like + %在文本比较少时是合适的
但是对于大量的文本数据检索会非常的慢
全文索引在大量的数据面前能比like快得多,但是准确度很低
百度在搜索文章的时候使用的就是全文索引,但更有可能是ES
# 不同的存储引擎支持的索引类型也不一样
● InnoDB存储引擎
支持事务,支持行级别锁定,支持 B-tree(默认)、Full-text 等索引,不支持 Hash 索引。
● MyISAM存储引擎
不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引。
● Memory存储引擎
不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引。
因为mysql默认的存储引擎是innodb,而innodb存储引擎的索引模型/结构是B+树,所以我们着重介绍B+树,那么大家最关注的问题来了:
B+树索引到底是如何加速查询的呢?
16.4 索引的数据结构
常见的数据结构有4种:二叉查找树、平衡二叉树、B树以及B+树。
# 创建索引的两大步骤
为某个字段创建索引,即以某个字段的值为基础构建索引结构,那么如何构建呢?分为两大步骤
● 1、提取每行记录中该字段的值,以该值当作key,至于key对的value是什么?每种索引结构各不相同
● 2、然后以key值为基础构建索引结构
以后的查询条件中使用了该字段,则会命中索引结构。
那么索引的结构到底长什么样子,让其能够加速查询呢?
innodb存储引擎默认的索引结构为B+树,而B+树是由二叉树、平衡二叉树、B树再到B+树一路演变过来的。
16.5 二叉查找树
二叉查找树(Binary Search Tree),也称有序二叉树(ordered binary tree),排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
a. 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
b. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
c. 任意节点的左、右子树也分别为二叉查找树。
d. 没有键值相等的节点(no duplicate nodes)。
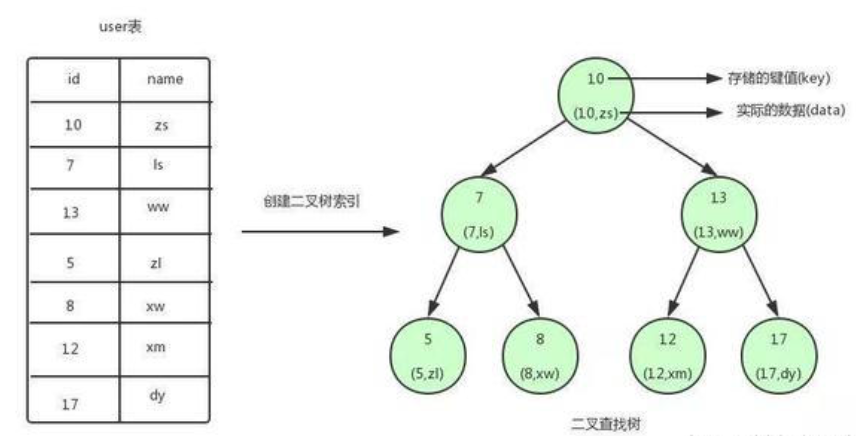
# 有user表,我们以id字段值为基础创建索引。
1、提取每一条记录的id值作为key值,value为本行完整记录;
2、以key值的大小为基础构建二叉树,如上图所示
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。
顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。
如果我们需要查找id=12的用户信息:select * from user where id=12;
利用我们创建的二叉查找树索引,查找流程如下:
1. 将根节点作为当前节点,把12与当前节点的键值10比较,12大于10,接下来我们把当前节点>的右子节点作为当前节点。
2. 继续把12和当前节点的键值13比较,发现12小于13,把当前节点的左子节点作为当前节点。
3. 把12和当前节点的键值12对比,12等于12,满足条件,我们从当前节点中取出data,即id=1>2,name=xm。
利用二叉查找树我们只需要3次即可找到匹配的数据。如果在表中一条条的查找的话,我们需要6次才能找到。
16.6 平衡二叉树
基于5.1所示的二叉树,我们确实可以快速地找到数据。但是让我们回到二叉查找树地特点上,只论二叉查找树,它的特点只是:任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。 所以,依据二叉查找树的特点,二叉树可以是这样构造的,如图:
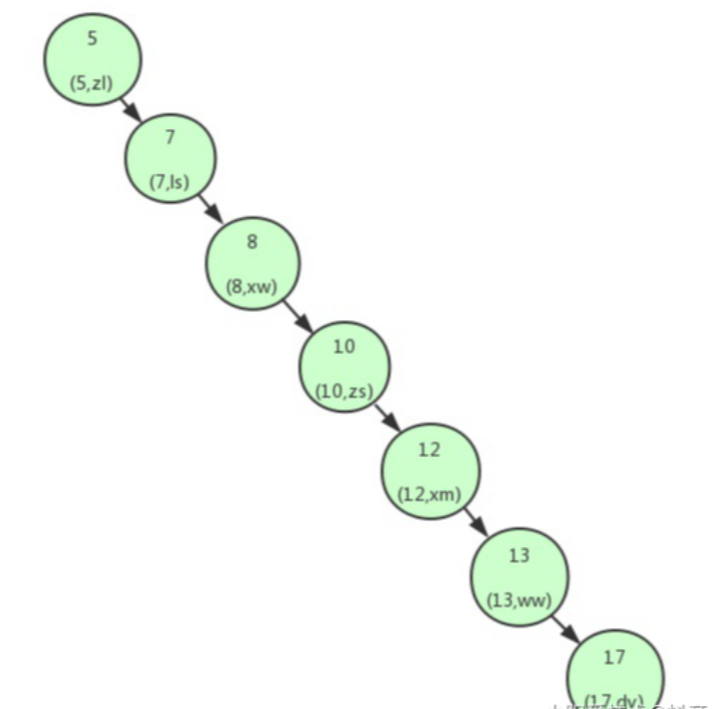
这个时候可以看到我们的二叉查找树变成了一个链表。如果我们需要查找id=17的用户信息,我们需要查找7次,也就相当于全表扫描了。 导致这个现象的原因其实是二叉查找树变得不平衡了,也就是高度太高了,从而导致查找效率的不稳定。
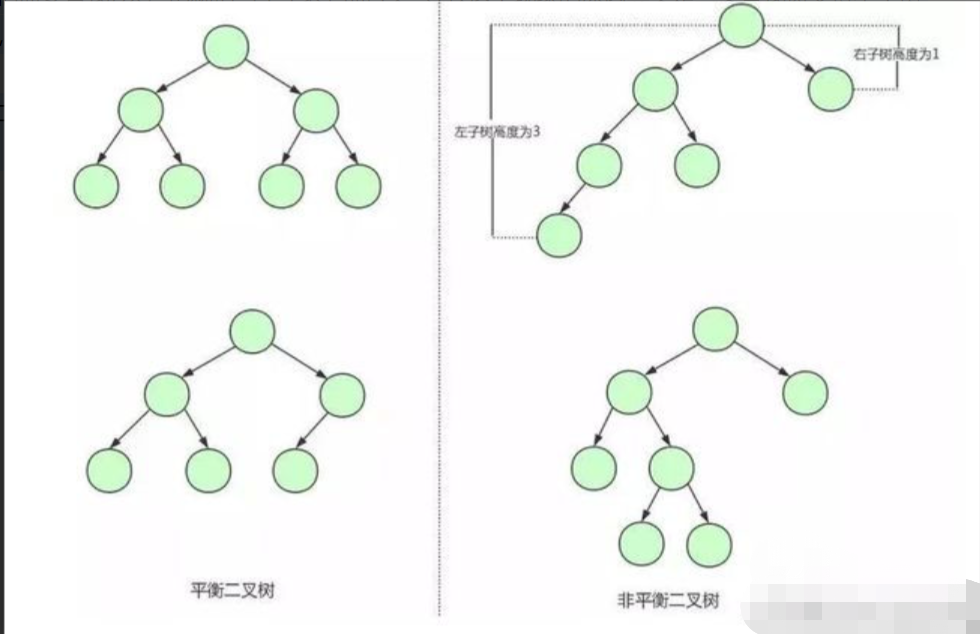
为了解决这个问题,我们需要保证二叉查找树一直保持平衡,就需要用到平衡二叉树了。平衡二叉树又称AVL树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度不能超过1。 下面是平衡二叉树和非平衡二叉树的对比:
由平衡二叉树的构造我们可以发现第一张图中的二叉树其实就是一棵平衡二叉树。平衡二叉树保证了树的构造是平衡的,当我们插入或删除数据导致不满足平衡二叉树不平衡时,平衡二叉树会进行调整树上的节点来保持平衡。具体的调整方式这里就不介绍了。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
那么是不是说基于平衡二叉树构建索引的结构就可以了呢?答案是否!
16.7 B树
那么直接用平衡二叉树这种数据结构来构建索引有什么问题?
首先,因为内存的易失性。一般情况下,我们都会选择将user表中的数据和索引存储在磁盘这种外围设备中。但是和内存相比,从磁盘中读取数据的速度会慢上百倍千倍甚至万倍,所以,我们应当尽量减少从磁盘中读取数据的次数。另外,从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。 如果我们能把尽量多的数据放进磁盘块中,那一次磁盘读取操作就会读取更多数据,那我们查找数据的时间也会大幅度降低。所以,如果我们单纯用平衡二叉树这种数据结构作为索引的数据结构,即每个磁盘块只放一个节点,每个节点中只存放一组键值对,此时如果数据量过大,二叉树的节点则会非常多,树的高度也随即变高,我们查找数据的也会进行很多次磁盘IO,查找数据的效率也会变得极低!
综上,如果我们能够在平衡二叉的树的基础上,把更多的节点放入一个磁盘块中,那么平衡二叉树的弊端也就解决了。即构建一个单节点可以存储多个键值对的平衡树,这就是B树。
# 注意:
1、图中的p节点为指向子节点的指针,二叉查找树和平衡二叉树其实也有,因为图的美观性,被省略了。
2、图中的每个节点里面放入了多组键值对,一个节点也称为一页,一页即一个磁盘块,在mysql中数据读取的基本单位都是页,即一次io读取一个页的数据,所以我们这里叫做页更符合mysql中索引的底层数据结构。
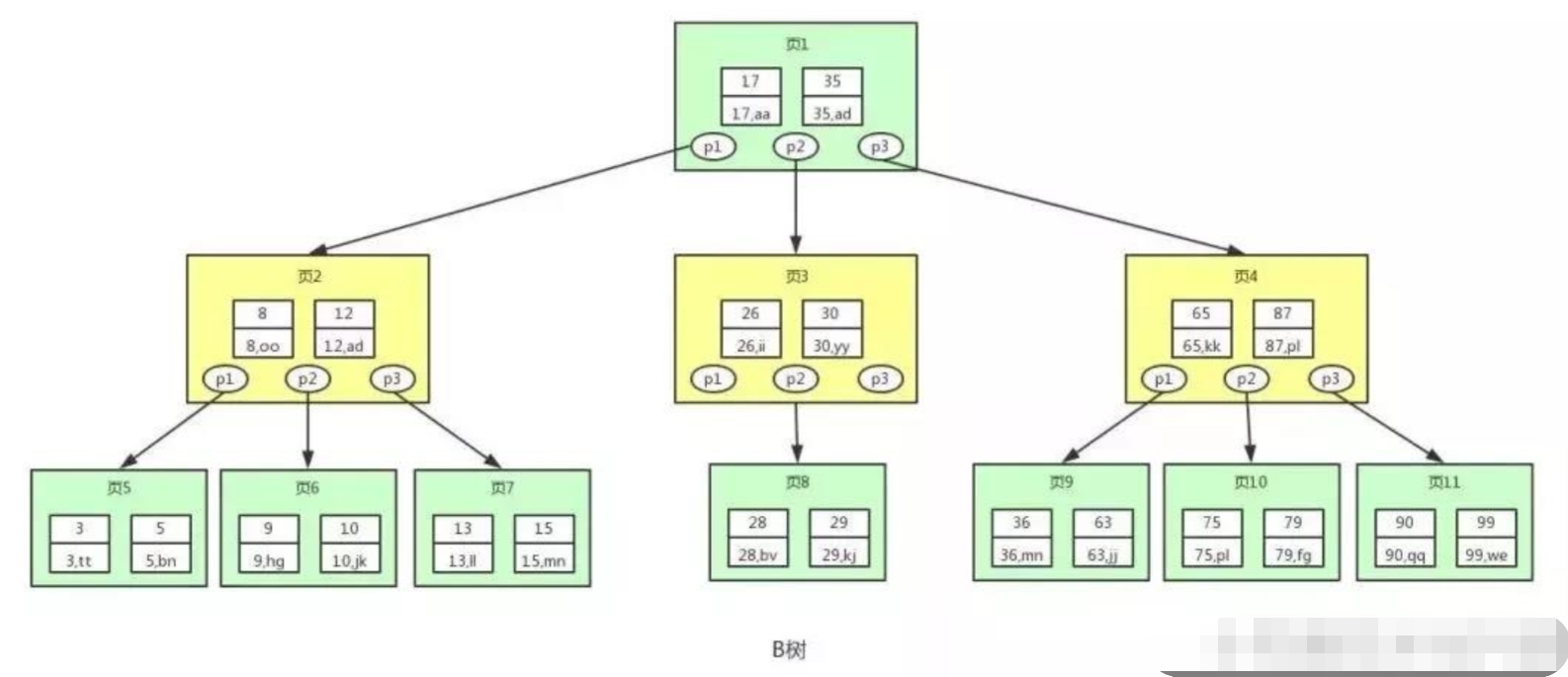
从下图可以看出,B树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会很低。 基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。 假如我们要查找id=28的用户信息,那么我们在上图B树中查找的流程如下:
● 1、先找到根节点也就是页1,判断28在键值17和35之间,我们那么我们根据页1中的指针p2找到页3。
● 2、将28和页3中的键值相比较,28在26和30之间,我们根据页3中的指针p2找到页8。
● 3、将28和页8中的键值相比较,发现有匹配的键值28,键值28对应的用户信息为(28,bv)。
# 注意:
● 1、B树的构造是有一些规定的,但这不是本文的关注点,有兴趣的同学可以令行了解。
● 2、B树也是平衡的,当增加或删除数据而导致B树不平衡时,也是需要进行节点调整的。
那么B树是否就是索引的最终结构了呢?答案是no,B树只擅长做等值查询,而对于范围查询(范围查询的本质就是n次等值查询),或者说排序操作,B树也帮不了我们,于是有了B+树。
select * from user where id=3; -- 擅长
select * from user where id>3; -- 不擅长
16.7 B+树
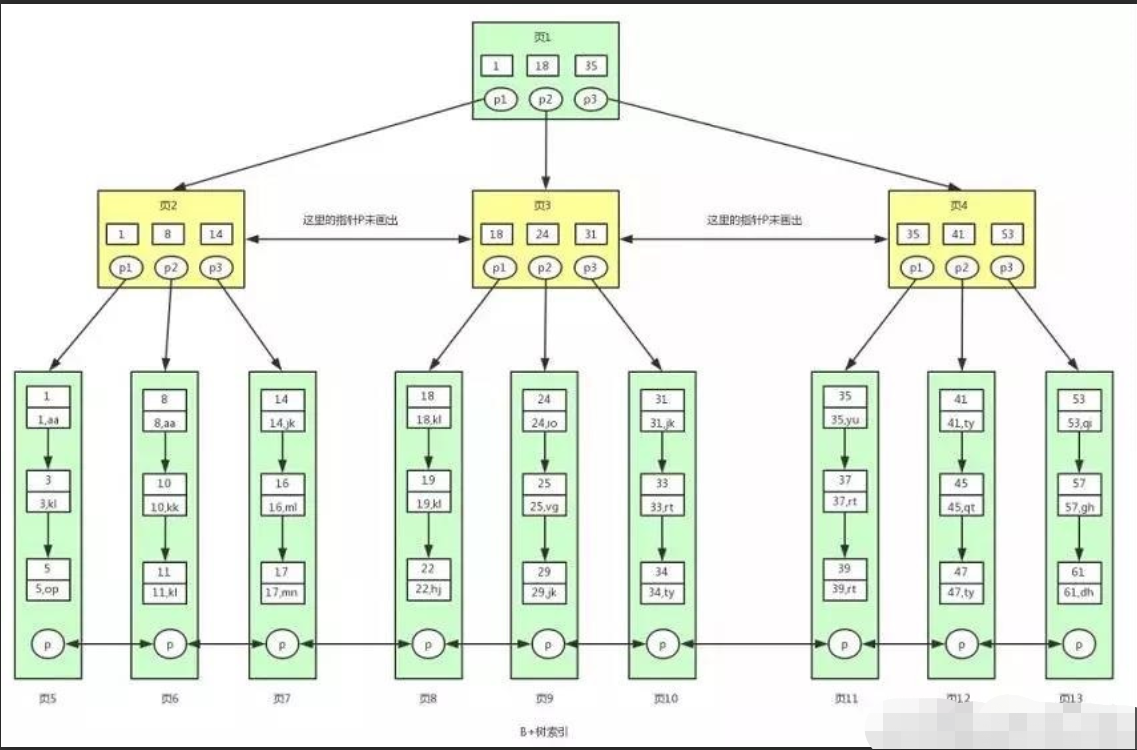
B+树是对B树的进一步优化。让我们先来看下B+树的结构图:
# 根据下图我们来看下B+树和B树有什么不同。
1. B+树非叶子节点non-leaf node上是不存储数据的,仅存储键,而B树的非叶子节点中不仅存储键,也会存储数据。B+树之所以这么做的意义在于:树一个节点就是一个页,而数据库中页的大小是固定的,innodb存储引擎默认一页为16KB,所以在页大小固定的前提下,能往一个页中放入更多的节点,相应的树的阶数(节点的子节点树)就会更大,那么树的高度必然更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
2. B+树的阶数是等于键的数量的,例如上图,我们的B+树中每个节点可以存储3个键,3层B+树存可以存储3*3*3=27个数据。所以如果我们的B+树一个节点可以存储1000个 键值,那么3层B+树可以存储1000×1000×1000=10亿个数据。而一般根节点是常驻内存的,所以一般我们查找10亿数据,只需要2次磁盘IO,真是屌炸天的设计。
3. 因为B+树索引的所有数据均存储在叶子节点leaf node,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而B树因为数据分散在各个节点,要实现这一点是很不容易的。 而且B+树中各个页之间也是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。其实上面的B树我们也可以对各个节点加上链表。其实这些不是它们之前的区别,是因为在mysql的innodb存储引擎中,索引就是这样存储的。也就是说上图中的B+树索引就是innodb中B+树索引真正的实现方式,准确的说应该是聚集索引(聚集索引和非聚集索引下面会讲到)。
通过上图可以看到,在innodb中,我们通过数据页之间通过双向链表连接以及叶子节点中数据之间通过单向链表连接的方式可以找到表中所有的数据。
16.8 索引管理
1. 索引的功能就是加速查找
2. mysql中的primary key,unique,联合唯一也都是索引,这些索引除了加速查找以外,还有约束的功能.
16.9 MySQL常用的索引分类
我们可以在创建上述索引的时候,为其指定索引类型,主要有以下几类:
#===========B+树索引(innodb存储引擎默认)
聚集索引:即主键索引,PRIMARY KEY
用途:
1、加速查找
2、约束(不为空、不能重复)
唯一索引:UNIQUE
用途:
1、加速查找
2、约束(不能重复)
普通索引INDEX:
用途:
1、加速查找
联合索引:
PRIMARY KEY(id,name):联合主键索引
UNIQUE(id,name):联合唯一索引
INDEX(id,name):联合普通索引
#===========HASH索引(查询单条快,范围查询慢)
将数据打散再去查询
Innodb和Myisam都不支持,设置完还是Btree
memery存储引擎支持
#===========FULLTEXT:全文索引 (只可以用在MyISAM引擎)
通过关键字的匹配来进行查询,类似于like的模糊匹配
like + %在文本比较少时是合适的
但是对于大量的文本数据检索会非常的慢
全文索引在大量的数据面前能比like快得多,但是准确度很低
百度在搜索文章的时候使用的就是全文索引,但更有可能是ES
#===========RTREE:R树索引
RTREE在mysql很少使用,仅支持geometry数据类型
geometry数据类型一般填写经纬度那样的数据
支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种。
RTREE范围查找很强,但Btree也不弱.
#不同的存储引擎支持的索引类型也不一样
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引;
Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
16.9 创建/删除索引的语法
#方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
#案例:
mysql> CREATE TABLE t11 (
id int PRIMARY KEY
);
Query OK, 0 rows affected (0.01 sec)
mysql> show create table t11\G
*************************** 1. row ***************************
Table: t11
Create Table: CREATE TABLE `t11` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
#方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
mysql> CREATE TABLE t12 ( id int );
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE UNIQUE INDEX index12 ON t12 (id);
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
#方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
mysql> CREATE TABLE t13 (
id int
);
Query OK, 0 rows affected (0.00 sec)
mysql> ALTER TABLE t13 ADD UNIQUE INDEX index13 (id);
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table t13;
+-------+----------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------+
| t13 | CREATE TABLE `t13` (
`id` int(11) DEFAULT NULL,
UNIQUE KEY `index13` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+----------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
#删除索引:
DROP INDEX 索引名 ON 表名字;
alter table country drop index 索引名字;
mysql> show create table t13;
+-------+----------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------+
| t13 | CREATE TABLE `t13` (
`id` int(11) DEFAULT NULL,
UNIQUE KEY `index13` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+----------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> DROP INDEX index13 ON t13;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table t13;
+-------+---------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------+
| t13 | CREATE TABLE `t13` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+---------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
#查看索引
方法一:
mysql> desc t1;
+-----+
| Key |
+-----+
| PRI | 主键索引
| MUL | 普通索引
| UNI | 唯一键索引
+-----+
方法二:
mysql> show index from t1;
# 案例:
# 1)主键索引(聚集索引)
#创建主键索引
mysql> alter table student add primary key pri_id(id);
mysql> create table student(id int not null, primary key(id));
mysql> create table student(id int not null primary key auto_increment comment '学号');
#提示:
database可以写 schema
index可以写 key
# 2)唯一键索引
#创建唯一建索引
mysql> alter table country add unique key uni_name(name);
mysql> create table student(id int unique key comment '学号');
mysql> create unique key index index_name on table_name(id);
# 3)普通索引(辅助索引)
#普通索引的创建
mysql> alter table student add index idx_gender(gender);
CREATE INDEX index_name ON table_name (column_list);
# 4)创建前缀索引
按照该列数据的前n个字母创建索引
mysql> alter table student add index idx_name(name(4));
# 5)全文索引
#针对content做了全文索引:
CREATE TABLE t1 (
id int NOT NULL AUTO_INCREMENT,
title char(255) NOT NULL,
content text,
PRIMARY KEY (id),
FULLTEXT (content));
# 查找时:
select * from table where match(content) against('想查询的字符串');
# 总结:
#1. 一定是为搜索条件的字段创建索引,比如select * from s1 where id = 333;就需要为id加上索引
#2. 在表中已经有大量数据的情况下,建索引会很慢,且占用硬盘空间,建完后查询速度加快
比如create index idx on s1(id);会扫描表中所有的数据,然后以id为数据项,创建索引结构,存放于硬盘的表中。
建完以后,再查询就会很快了。
#3. 需要注意的是:innodb表的索引会存放于s1.ibd文件中,而myisam表的索引则会有单独的索引文件table1.MYI
MySAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在innodb中,表数据文件本身就是按照B+Tree(BTree即Balance True)组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此innodb表数据文件本身就是主索引。
因为inndob的数据文件要按照主键聚集,所以innodb要求表必须要有主键(Myisam可以没有),如果没有显式定义,则mysql系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则mysql会自动为innodb表生成一个隐含字段作为主键,这字段的长度为6个字节,类型为长整型。
16.10 正确的使用索引
并不是说我们创建了索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果,我们在添加索引时,必须遵循以下问题。
1.范围问题:条件不明确,条件中出现这些符号或关键字:>、>=、<、<=、!= 、between...and...、like。
# 注:like关键字当使用%前置的时候,是无法命中索引,既而查询速度很慢,所以,在企业中尽量避免使用%前置。
2.查询优化神器-explain
关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快(有例外,下面会讲到)。所以优化语句基本上都是在优化rows。
# 各个字段详解:
1. id:
包含一组数字,表示查询中执行select子句或操作表的顺序
Example(id相同,执行顺序由上至下)
如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
2. select_type
示查询中每个select子句的类型(简单OR复杂)
a. SIMPLE:查询中不包含子查询或者UNION
b. 查询中若包含任何复杂的子部分,最外层查询则被标记为:PRIMARY
c. 在SELECT或WHERE列表中包含了子查询,该子查询被标记为:SUBQUERY
d. 在FROM列表中包含的子查询被标记为:DERIVED(衍生)用来表示包含在from子句中的子查询的select,mysql会递归执行并将结果放到一个临时表中。服务器内部称为"派生表",因为该临时表是从子查询中派生出来的
e. 若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED
f. 从UNION表获取结果的SELECT被标记为:UNION RESULT
SUBQUERY和UNION还可以被标记为DEPENDENT和UNCACHEABLE。
DEPENDENT意味着select依赖于外层查询中发现的数据。
UNCACHEABLE意味着select中的某些 特性阻止结果被缓存于一个item_cache中。
第一行:id列为1,表示第一个select,select_type列的primary表 示该查询为外层查询,table列被标记为<derived3>,表示查询结果来自一个衍生表,其中3代表该查询衍生自第三个select查询,即id为3的select。
第二行:id为3,表示该查询的执行次序为2( 4 => 3),是整个查询中第三个select的一部分。因查询包含在from中,所以为derived。
第三行:select列表中的子查询,select_type为subquery,为整个查询中的第二个select。
第四行:select_type为union,说明第四个select是union里的第二个select,最先执行。
第五行:代表从union的临时表中读取行的阶段,table列的<union1,4>表示用第一个和第四个select的结果进行union操作。
3、 type
表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
ALL:Full Table Scan,
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
4、table
显示这一行的数据是关于哪张表的,有时不是真实的表名字,看到的是derivedx(x是个数字,我的理解是第几步执行的结果)
5、possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询
6、Key key列显示MySQL实际决定使用的键(索引)
如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。(注:索引是否命中)
7、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
不损失精确性的情况下,长度越短越好
8、ref
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
9、rows
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
10、Extra
该列包含MySQL解决查询的详细信息,有以下几种情况:
Using where:列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询
Using filesort:MySQL中无法利用索引完成的排序操作称为“文件排序”
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行。
explain字段详解
16.11 慢日志
将MySQL服务器中影响数据库性能的相关SQL语句记录到日志文件中;通过对这些特殊的SQL语句进行分析和改进,提高数据库的性能。
默认情况下,MySQL 数据库并不启动慢查询日志,需要我们手动来设置这个参数,当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志或多或少会带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
1、配置慢日志:
[root@mysql03 ~]# vim /etc/my.cnf
#开启慢查询
slow_query_log = on
#慢查询中记录没有使用索引的query
log_queries_not_using_indexes=on
#返回较慢的日志mysql5.6版本以上,取消了参数log-slow-queries,更改为slow-query-log-file
slow_query_log_file=/usr/local/mysql-5.7.36/data/slow.log
#慢查询时间,这里为2秒,超过2秒会被记录
long_query_time=0.05
2、重启mysql:
[root@mysql03 data]# systemctl restart mysqld
[root@mysql03 ~]# cd /usr/local/mysql-5.7.36/data/
[root@mysql03 data]# ll # 查看当前目录已经生成slow.log文件
3、查看是否开启慢日志:
mysql> show variables like '%slow_query_log%';
+---------------------+---------------+
| Variable_name | Value |
+---------------------+---------------+
| slow_query_log | ON |
| slow_query_log_file | /tmp/slow.log |
+---------------------+---------------+
2 rows in set (0.00 sec)
4、测试慢日志
mysql> select sleep(2);
+----------+
| sleep(2) |
+----------+
| 0 |
+----------+
1 row in set (2.00 sec)
[root@mysql03 data]# cat slow.log # 查看有没有日志记录
# Time: 2021-09-28T16:15:29.967489Z
# User@Host: skip-grants user[root] @ localhost [] Id: 2
# Query_time: 2.000316 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1632845729;
select sleep(2);
17、MySQL数据库的事务
17.1 事务
1.事务(Transaction),顾名思义就是要做的或所做的事情,数据库事务指的则是作为单个逻辑工作单元执行的一系列操作(SQL语句)。这些操作要么全部执行,要么全部不执行。
2.为什么需要事务?
一个经典的例子:A账户转给B账户10元,数据库操作需要两步,第一步A账户减10元,第二步B账户加10元,如果没有事务并且在两步中间发生异常,就会导致A的账户少了10元,但B的账户没有变化,如果不能保证这两步操作统一,银行的转账业务也没法进行展开了。
当一个事务被提交给了DBMS(数据库管理系统),则DBMS需要确保该事务中的所有操作都成功完成且其结果被永久保存在数据库中,如果事务中有的操作没有成功完成,则事务中的所有操作都需要被回滚,回到事务执行前的状态(要么全执行,要么全都不执行);同时,该事务对数据库或者其他事务的执行无影响,所有的事务都好像在独立的运行。
3.事务的4个特性:
# 1、原子性(Atomicity)
事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
# 2、一致性(Consistency)
事务应确保数据库的状态从一个一致状态转变为另一个一致状态,例如转账行为中,一个人减了50元,另外一个人就应该加上这50元,而不能是40元。
其他一致状态的含义是数据库中的数据应满足完整性约束,例如字段约束不能为负数,事务执行完毕后的该字段也同样不是负数
# 3、隔离性(Isolation)
多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
# 4、持久性(Durability)
一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
4.MySQL事务的运行模式
手动开启的事务里默认不会自动提交
所以我们可以将要执行的sql语句放在我们自己手动开启的事务里,如此便是显式开启、显式提交
start transaction; # 开启事物
update test.t1 set id=33 where name = "jack"; # 执行命令
commit; # 提交
这种方式在当你使用commit或者rollback后,事务就结束了
再次进入事务状态需要再次start transaction
5.事务保存点
savepoint和虚拟机中的快照类似,用于事务中,没设置一个savepoint就是一个保存点,当事务结束时会自动删除定义的所有保存点,在事务没有结束前可以回退到任意保存点。
# 1、设置保存点savepoint,保存点名字
# 2、回滚到某个保存点,该保存点之后的操作无效,rollback 某个保存点名
# 3、取消全部事务,删除所有保存点rollback
# 注意:rollback和commit都会结束掉事务,这之后无法再回退到某个保存点
# 案例:
mysql> CREATE TABLE employee (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
age TINYINT(2)
);
Query OK, 0 rows affected (0.05 sec)
mysql> INSERT INTO employee (name, age) VALUES ("qiuqiu", 18),("linlin", 16);
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from employee;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | qiuqiu | 18 |
| 2 | linlin | 16 |
+----+--------+------+
2 rows in set (0.00 sec)
mysql> BEGIN;
Query OK, 0 rows affected (0.01 sec)
mysql> UPDATE employee SET name="qinqin" WHERE id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SAVEPOINT one; -- 保存点one
Query OK, 0 rows affected (0.00 sec)
mysql> select * from employee;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | qinqin | 18 |
| 2 | linlin | 16 |
+----+--------+------+
2 rows in set (0.00 sec)
mysql> UPDATE employee SET name="lily" WHERE id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SAVEPOINT two;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM employee;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | lily | 18 |
| 2 | linlin | 16 |
+----+--------+------+
2 rows in set (0.00 sec)
mysql> ROLLBACK TO one;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM employee;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | qinqin | 18 |
| 2 | linlin | 16 |
+----+--------+------+
2 rows in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
17.2 MySQL事务中的redo与undo
众所周知InnoDB 是一个事务性的存储引擎,在上一小节我们提到事务有4种特性:原子性、一致性、隔离性和持久性,在事务中的操作,要么全部执行,要么全部不做,这就是事务的目的。
那么事务的四种特性到底是基于什么机制实现呢???在InnoDB中存在两种Log,它们分别是redo log 是重做日志,提供再写入操作,实现事务的持久性;undo log 是回滚日志,提供回滚操作,保证事务的一致性。
17.2.1 Redo Log
Redo Log 记录的是尚未完成的操作,数据库崩溃则用其重做。
Redo Log的作用:
Redo log可以简单分为以下两个部分:
● 保存在内存中重做日志的缓冲 (redo log buffer),是易失的
● 保存在硬盘中重做日志文件 (redo log file),是持久的
# Redo工作流程:
第一步:InnoDB 会先把记录从硬盘读入内存
第二部:修改数据的内存拷贝
第三步:生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值
第四步:当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加写的方式
第五步:定期将内存中修改的数据刷新到磁盘中(注意,不是从redo log file刷入磁盘,而是从内存刷入磁盘,redo log file只在崩溃恢复数据时才用),如果数据库崩溃,则依据redo log buffer、redo log file进行重做,恢复数据,这才是redo log file的价值所在。
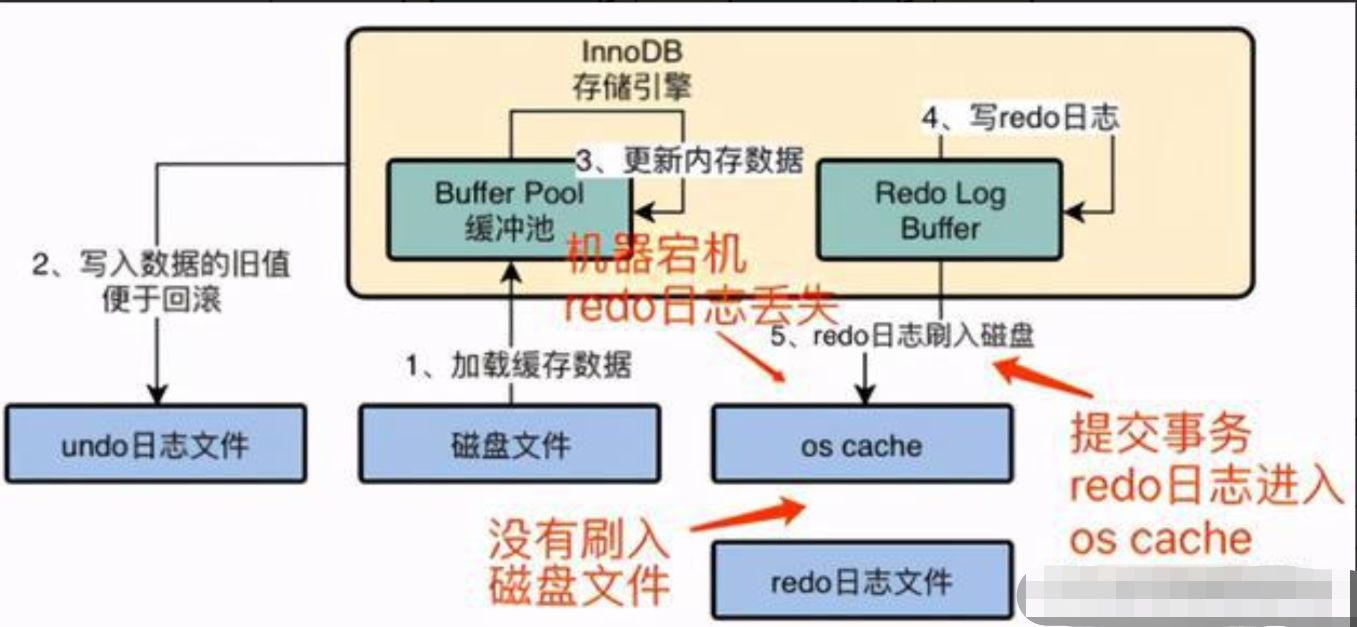
17.2.2 Undo log
undo即撤销还原。用于记录更改前的一份copy,在操作出错时,可以用于回滚、撤销还原,只将数据库逻辑地恢复到原来的样子。
1、undo日志记录了什么?
比如有两个用户访问数据库,当然并发罗。A是更改,B是查询。
--A更改还没有提交,B查询的话,数据肯定为历史数据,这个历史数据就是来源于UNDO段,
--A更改未提交,需要回滚rollback,回滚rollback的数据也来至于UNDO段。
结论:为了并发时读一致性成功,那么DML操作,肯定先写UNDO段。
2、undo的存储位置
在InnoDB存储引擎中,undo存储在回滚段(Rollback Segment)中,每个回滚段记录了1024个undo log segment,而在每个undo log segment段中进行undo 页的申请,在5.6以前,Rollback Segment是在共享表空间里的,5.6.3之后,可通过 innodb_undo_tablespace设置undo存储的位置。
3、undo的类型
在InnoDB存储引擎中,undo log分为:
● insert undo log
● update undo log
insert undo log是指在insert 操作中产生的undo log,因为insert操作的记录,只对事务本身可见,对其他事务不可见。故该undo log可以在事务提交后直接删除,不需要进行purge操作。
update undo log记录的是对delete 和update操作产生的undo log,该undo log可能需要提供MVCC机制,因此不能再事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。
purge线程两个主要作用是:清理undo页和清除page里面带有Delete_Bit标识的数据行。
在InnoDB中,事务中的Delete操作实际上并不是真正的删除掉数据行,而是一种Delete Mark操作,在记录上标识Delete_Bit,而不删除记录。是一种"假删除",只是做了个标记,真正的删除工作需要后台purge线程去完成。
4、undo log 是否是redo log的逆过程
其实从前文就可以得出答案了,undo log是逻辑日志,undo log记录的是逻辑标识,对事务回滚时,只是将数据库逻辑地恢复到原来的样子,也就是根据标识把缓冲区里面的数据根据undo log里面记录的标识进行恢复,而redo log是物理日志,记录的是数据页的物理变化,显然undo log不是redo log的逆过程。
18、数据库读现象
18.1 数据库读现象
数据库管理软件的“读现象”指的是当多个事务并发执行时,在读取数据方面可能碰到的问题,包括有脏读、不可重复读和幻读。
对于一些数据库管理软件会自带相应的机制去解决脏读、不可重复读、幻读等问题,因为这些自带的机制,下述的一些实验现象可能在某一数据库管理软件的默认机制下并不成立,即我们并不能在所有数据库管理软件中看到所有的读现象。所以此处我们暂且抛开具体的某个数据库管理软件的默认机制的干扰,暂时假设没有附加任何机制为前提,单纯地去理解数据库的读现象。
18.1.1 脏读
事务T2更新了一行记录的内容,但是并没有提交所做的修改。
事务T1读取更新后的行,然后T1执行回滚操作,取消了刚才所做的修改。此时T1所读取的行就无效了,称之为脏数据。
在下方的例子中,事务2回滚后就没有id是1,age是21的数据了。所以,事务一读到了一条脏数据。
| 事务1 | 事务2 |
|---|---|
| set tx_isolation='READ-UNCOMMITTED'; | set tx_isolation='READ-UNCOMMITTED'; |
| -- 开启事务start transaction; | -- 开启事务start transaction; |
| /* Query 1 / SELECT age FROM users WHERE id = 1; / will read 20 */ | |
| /* Query 2 / UPDATE users SET age = 21 WHERE id = 1; / No commit here */ | |
| /* Query 1 / SELECT age FROM users WHERE id = 1; / will read 21 */ | |
| ROLLBACK; /* lock-based DIRTY READ */ |
18.1.2 不可重复读取
事务T1读取一行记录,紧接着事务T2修改了T1刚才读取的那一行记录并且提交了。
然后T1又再次读取这行记录,发现与刚才读取的结果不同。这就称为“不可重复”读,因为T1原来读取的那行记录已经发生了变化。
举例:
在基于锁的并发控制中“不可重复读(non-repeatable read)”现象发生在当执行SELECT 操作时没有获得读锁(read locks)或者SELECT操作执行完后马上释放了读锁; 多版本并发控制中当没有要求一个提交冲突的事务回滚也会发生“不可重复读(non-repeatable read)”现象。
在这个例子中,事务2提交成功,因此他对id为1的行的修改就对其他事务可见了。但是事务1在此前已经从这行读到了另外一个“age”的值。
| 事务1 | 事务2 |
|---|---|
| /* Query 1 */ SELECT * FROM users WHERE id = 1; | |
| /* Query 2 / UPDATE users SET age = 21 WHERE id = 1; COMMIT; / in multiversion concurrency control, or lock-based READ COMMITTED */ | |
| /* Query 1 / SELECT * FROM users WHERE id = 1; COMMIT; /lock-based REPEATABLE READ */ |
18.1.3 幻像读取 (phantom read)
幻读(phantom read)”是不可重复读(Non-repeatable reads)的一种特殊场景:
当事务没有获取范围锁的情况下执行SELECT … WHERE操作有可能会发生“幻影读(phantom read)”。
事务T1读取或修改了指定的WHERE子句所返回的结果集。然后事务T2新插入一行记录,这行记录恰好可以满足T1所使用的查询条件中的WHERE 子句的条件。然后T1又使用相同的查询再次对表进行检索,但是此时却看到了事务T2刚才插入的新行或者发现了处于WHRE子句范围内,但却未曾修改过的记录。就好像“幻觉”一样,因为对T1来说这一行就像突然出现的一样。一般解决幻读的方法是增加范围锁RangeS,锁定检锁范围为只读,这样就避免了幻读。
举例
当事务1两次执行SELECT … WHERE检索一定范围内数据的操作中间,事务2在这个表中创建了(如INSERT)了一行新数据,这条新数据正好满足事务1的“WHERE”子句。
| 事务一 | 事务二 |
|---|---|
| /* Query 1 */ SELECT * FROM users WHERE age BETWEEN 10 AND 30; | |
| /* Query 2 */ INSERT INTO users VALUES ( 3, 'Bob', 27 ); COMMIT; | |
| /* Query 1 */ SELECT * FROM users WHERE age BETWEEN 10 AND 30; |
18.2 解决方案
其实,脏写、脏读、不可重复读、幻读,都是因为业务系统会多线程并发执行,每个线程可能都会开启一个事务,每个事务都会执行增删改查操作。然后数据库会并发执行多个事务,多个事务可能会并发地对缓存页里的同一批数据进行增删改查操作,于是这个并发增删改查同一批数据的问题,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。
所以这些问题的本质,都是数据库的多事务并发问题,那么为了解决多事务并发带来的脏读、不可重复读、幻读等读等问题,数据库才设计了锁机制、事务隔离机制、MVCC 多版本隔离机制,用一整套机制来解决多事务并发问题。
19、数据库锁机制
19.1 数据库的锁机制
# 1.什么是锁?为何要加入锁机制?
锁是计算机协调多个进程或线程并发访问某一资源的机制,那为何要加入锁机制呢?
因为在数据库中,除了传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供需要用户共享的资源。
当并发事务同时访问一个共享的资源时,有可能导致数据不一致、数据无效等问题。
例如我们在数据库的读现象中介绍过,在并发访问情况下,可能会出现脏读、不可重复读和幻读等读现象
为了应对这些问题,主流数据库都提供了锁机制,以及事务隔离级别的概念,而锁机制可以将并发的数据访问顺序化,以保证数据库中数据的一致性与有效性此外,锁冲突也是影响数据库并发访问性能的一个重要因素,锁对数据库而言显得尤其重要,也更加复杂。
# 2.并发控制
在计算机科学,特别是程序设计、操作系统、多处理机和数据库等领域,并发控制(Concurrency control)是确保及时纠正由并发操作导致的错误的一种机制。
数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。下面举例说明并发操作带来的数据不一致性问题:
现有两处火车票售票点,同时读取某一趟列车车票数据库中车票余额为 X。两处售票点同时卖出一张车票,同时修改余额为 X -1写回数据库,这样就造成了实际卖出两张火车票而数据库中的记录却只少了一张。 产生这种情况的原因是因为两个事务读入同一数据并同时修改,其中一个事务提交的结果破坏了另一个事务提交的结果,导致其数据的修改被丢失,破坏了事务的隔离性。并发控制要解决的就是这类问题。
封锁、时间戳、乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
19.2 锁的分类
一、按锁的粒度划分,可分为行级锁、表级锁、页级锁。(mysql支持)::实际上只是一种锁的现象,并不是真实存在的锁
二、按锁级别划分,可分为共享锁、排他锁:真实存在的锁
三、按使用方式划分,可分为乐观锁、悲观锁:实际上只是一种锁的现象,并不是真实存在的锁
四、按加锁方式划分,可分为自动锁、显式锁
五、按操作划分,可分为DML锁、DDL锁
19.3 MySQL中的行级锁,表级锁,页级锁(粒度)
在DBMS中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
1、行级锁
行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁和排他锁。
● 特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
● 支持引擎:InnoDB
● 行级锁定分为行共享读锁(共享锁)与行独占写锁(排他锁)
共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
排他锁(X): SELECT * FROM table_name WHERE ... FOR UPDATE
# 注意:1、对于insert、update、delete语句,InnoDB会自动给涉及的数据加锁,而且是排他锁(X)。
# 注意:2、对于普通的select语句,InnoDB不会加任何锁,需要我们手动自己加,可以加两种类型的锁。
2、表级锁
表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
● 特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
● 支持引擎:MyISAM、MEMORY、InNoDB
● 分类:表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁),如下所示:
lock table 表名 read(write),表名 read(write),.....;
//给表加读锁或者写锁,例如
mysql> lock table employee write;
Query OK, 0 rows affected (0.00 sec)
mysql> show open tables where in_use>= 1;
+----------+----------+--------+-------------+
| Database | Table | In_use | Name_locked |
+----------+----------+--------+-------------+
| ttt | employee | 1 | 0 |
+----------+----------+--------+-------------+
1 row in set (0.00 sec)
mysql> unlock tables; -- UNLOCK TABLES释放被当前会话持有的任何锁
Query OK, 0 rows affected (0.00 sec)
mysql> show open tables where in_use>= 1;
Empty set (0.00 sec)
mysql>
3、页级锁
页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
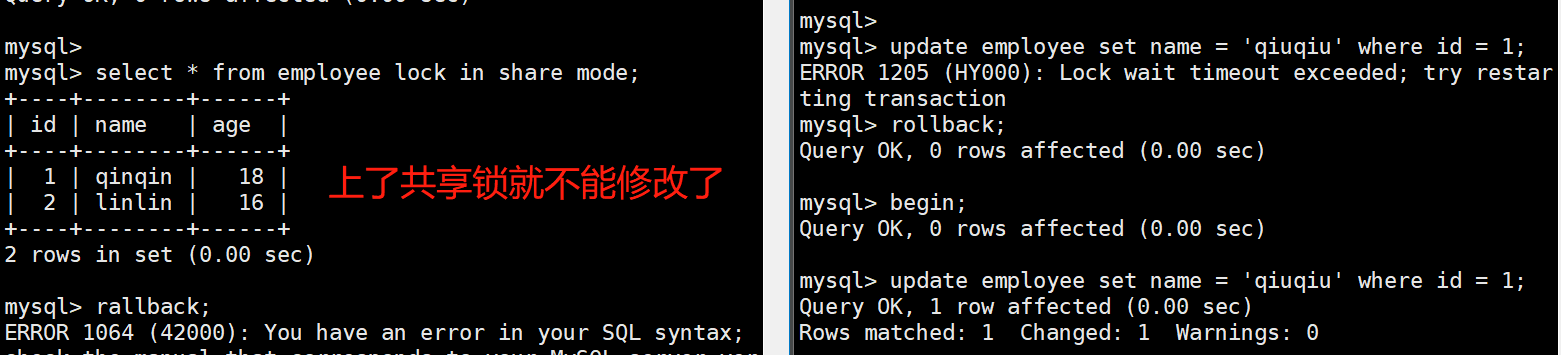
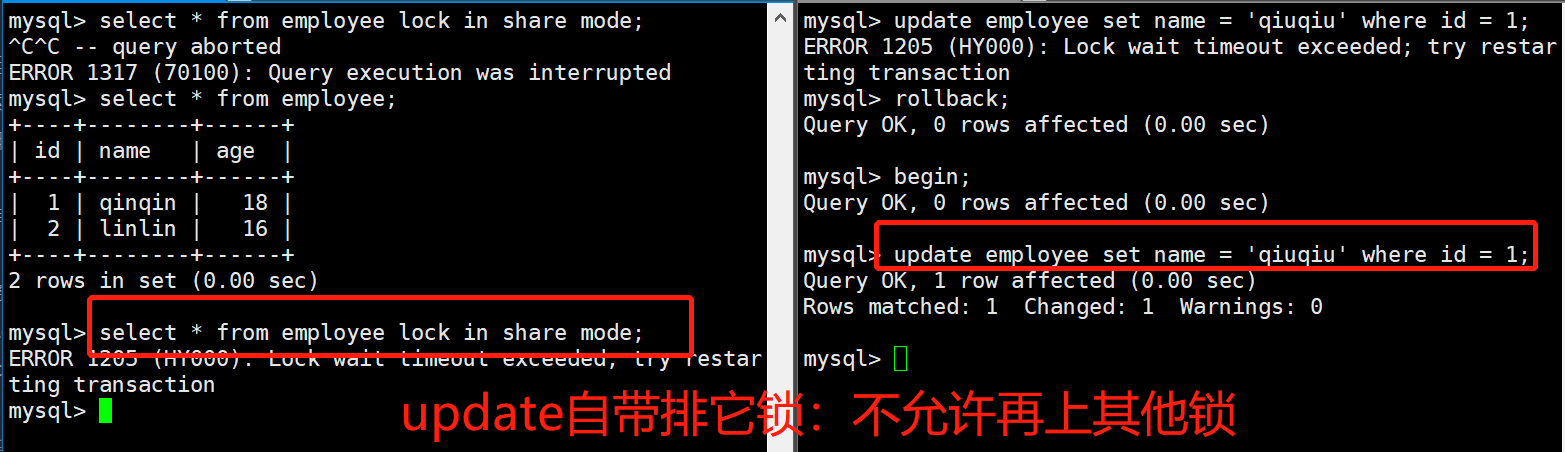
19.4 行级锁之共享锁与排他锁以及死锁
行级锁分为共享锁和排他锁两种。
1、共享锁
共享锁又称为读锁,简称S锁,顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
现在我们对id=1的数据行排他查询,这里会使用begin开启事务,而不会看见我关闭事务,这样做是用来测试,因为提交事务或回滚事务就会释放锁。
# 注:在其他事务里也只能加共享锁或不加锁
| 事务一 | 事务二 | |
|---|---|---|
| 步骤1 | -- 开启事务、加共享锁,start transaction; | -- 开启事务、加共享锁,锁住id<3的所有行start transaction;select * from s1 where id < 3 lock in share mode; |
| 步骤2 | -- 加排他锁,会阻塞在原地select * from s1 where id = 1 for update;-- 加共享锁,可以查出结果,不会阻塞在原地select * from s1 where id = 1 lock in share mode;-- 不加锁,必然也可以查出结果,不会阻塞在原地select name from s1 where id = 1; | |
| 步骤3 | -- 提交一下事务,不要影响下一次实验 commit; |
-- 提交一下事务,不要影响下一次实验 commit; |
2、排它锁
排他锁又称为写锁,简称X锁,顾名思义,排他锁就是不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取和修改。
| 事务一 | 事务二 | |
|---|---|---|
| 步骤1 | -- 开启事务 start transaction; | -- 开启事务start transaction; |
| 步骤2 | -- 加排他锁,锁住id<3的所有行select * from s1 where id < 3 for update; | |
| 步骤3 | -- 阻塞在原地select * from s1 where id = 1 for update;-- 阻塞在原地select * from s1 where id = 1 lock in share mode;-- 我们看到开了排他锁查询和共享锁查询都会处于阻塞状态-- 因为id=1的数据已经被加上了排他锁,此处阻塞是等待排他锁释放。 | |
| 步骤4 | -- ctrl+c终止步骤3的阻塞状态-- 注意:-- 下述实验遇到阻塞都可以用采用ctrl+c的方式结束,或者等待锁超时 | |
| 步骤5 | -- 如果我们直接使用以下查询,即便id<3的行都被事务二锁住了-- 但此处仍可以查看到数据-- 证明普通select查询没有任何锁机制select name from s1 where id = 1; | |
| 步骤6 | -- 提交一下事务,不要影响下一次实验 commit; |
-- 提交一下事务,不要影响下一次实验 commit; |
3、死锁
两个事务都持有对方需要的锁,并且在等待对方释放,并且双方都不会释放自己的锁。
所谓死锁:是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。表级锁不会产生死锁.所以解决死锁主要还是针对于最常用的InnoDB。
# 案例:
mysql> select * from employee where id = 1 lock in share moode;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | qinqin | 18 |
+----+--------+------+
1 row in set (0.00 sec)
mysql> select * from employee where id = 2 lock in share mode;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 2 | linlin | 16 |
+----+--------+------+
1 row in set (0.00 sec)
mysql> update employee set name = 'xiaoxiao' where id = 1
mysql> update employee set name = 'dada' where id = 2;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
# 为何会出现死锁?
因为事务二中,步骤4的update语句是想获取互斥锁,会阻塞在原地,需要等待事务一先释放共享锁。 而事务一执行下述了下述update语句同样是想获取互斥锁, 同样需要等事务二先释放共享锁,至此双方互相锁死。事务一在抛出死锁异常之后,会被强行终止,只剩事务二自己,这个时候事务二就可以得到他所需要的锁, 于是事务二的sql不存在锁争抢问题,会立即执行成功。
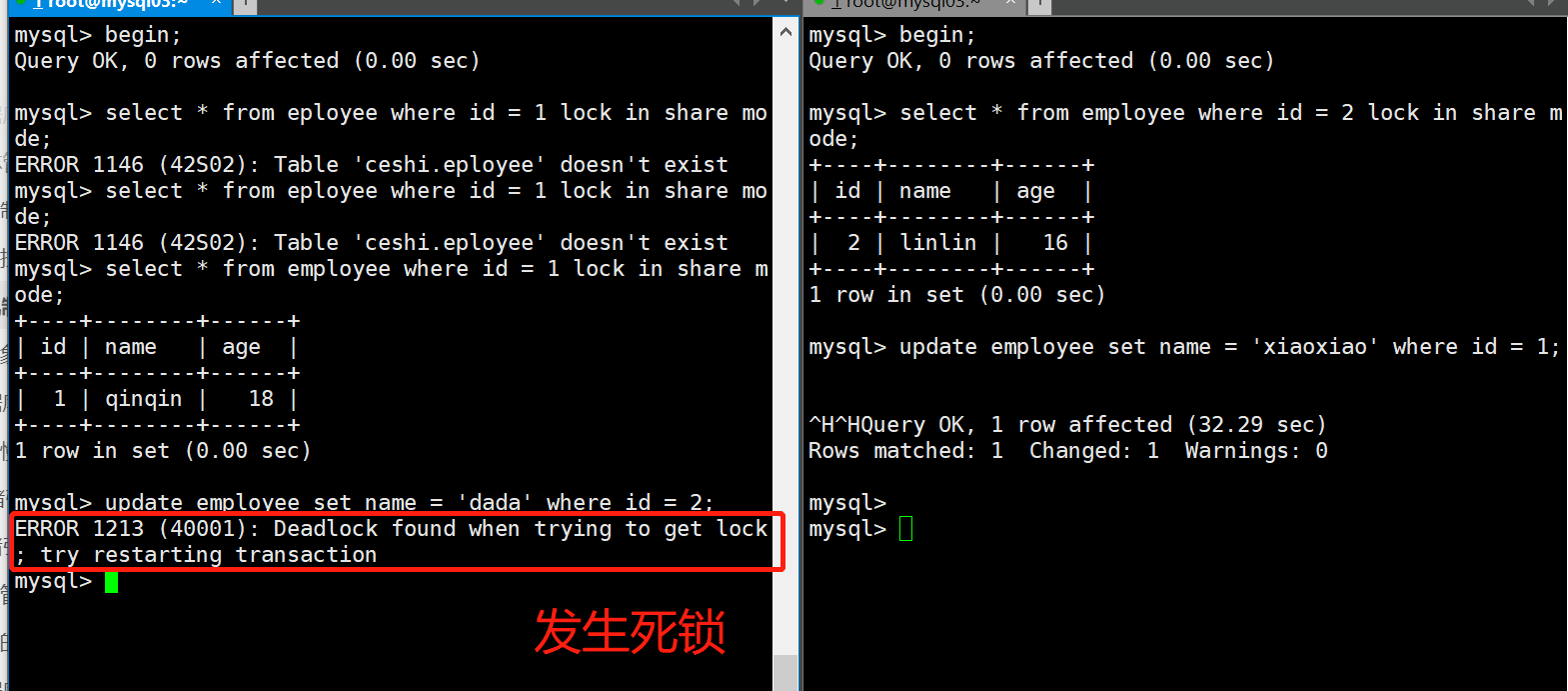
19.5 Innodb存储引擎的锁机制
MyISAM和MEMORY采用表级锁(table-level locking)。
BDB采用页级锁(page-level locking)或表级锁,默认为页级锁。
InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁(偏向于写)。
InnoDB的锁定模式实际上可以分为四种:共享锁(S),排他锁(X),意向共享锁(IS)和意向排他锁(IX),我们可以通过以下表格来总结上面这四种所的共存逻辑关系:
如果一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。
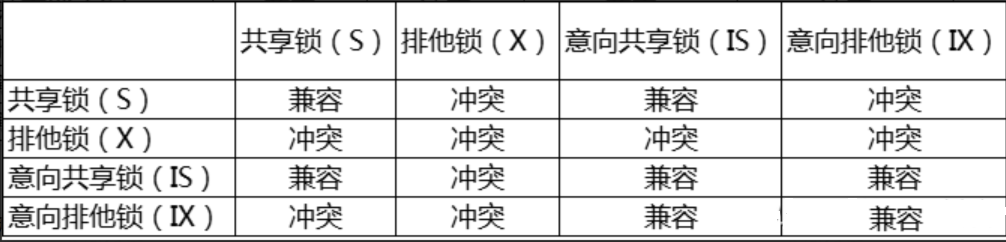
19.5.1 行级锁与表级锁的使用区分
MyISAM 操作数据都是使用表级锁,MyISAM总是一次性获得所需的全部锁,要么全部满足,要么全部等待。所以不会产生死锁,但是由于每操作一条记录就要锁定整个表,导致性能较低,并发不高。
InnoDB 与 MyISAM 的最大不同有两点:一是 InnoDB 支持事务;二是 InnoDB 采用了行级锁。也就是你需要修改哪行,就可以只锁定哪行。
在Mysql中,行级锁并不是直接锁记录,而是锁索引。InnoDB 行锁是通过给索引项加锁实现的,而索引分为主键索引和非主键索引两种:
a. 如果一条sql 语句操作了主键索引,Mysql 就会锁定这条语句命中的主键索引(或称聚簇索引)。
b. 如果一条语句操作了非主键索引(或称辅助索引),MySQL会先锁定该非主键索引,再锁定相关的主键索引。
c. 如果没有索引,InnoDB 会通过隐藏的主键索引来对记录加锁。也就是说:如果不通过索引条件检索数据,那么InnoDB将对表中所有数据加锁,实际效果跟表级锁一样。
在实际应用中,要特别注意InnoDB行锁的这一特性,不然的话,可能导致大量的锁冲突,从而影响并发性能。
a. 在不通过索引条件查询的时候,InnoDB 的效果就相当于表锁
b. 当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,无论是使用主键索引、唯一索引或普通索引,InnoDB 都会使用行锁来对数据加锁。
c. 由于 MySQL 的行锁是针对索引加的锁,不是针对记录加的锁,所以即便你的sql语句访问的是不同的记录行,但如果命中的是相同的被锁住的索引键,也还是会出现锁冲突的。
d. 即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同 执行计划的代价来决定的,如果 MySQL 认为全表扫 效率更高,比如对一些很小的表,它 就不会使用索引,这种情况下 InnoDB 将锁住所有行,相当于表锁。因此,在分析锁冲突时, 别忘了检查 SQL 的执行计划,以确认是否真正使用了索引。
1、验证未命中索引引发表锁
| 事务一 | 事务二 | |
|---|---|---|
| 步骤1 | -- 开启事务 start transaction; | -- 开启事务start transaction; |
| 步骤2 | -- 查询时未命中索引,从而引发表锁select * from s1 where email like "%xxx" for update; | |
| 步骤3 | -- 在事务二中查询数据阻塞select * from s1 where id = 2 for update ;-- 在事务二中查询数据阻塞select * from s1 where id = 3 for update ;-- 在事务二中查询数据阻塞select * from s1 where id = 4 for update ; | |
| 步骤4 | -- 提交一下事务,不要影响下一次实验commit; | -- 提交一下事务,不要影响下一次实验commit; |
2、 验证命中索引则锁行
| 事务一 | 事务二 | |
|---|---|---|
| 步骤1 | -- 开启事务 start transaction; | -- 开启事务start transaction; |
| 步骤2 | -- 查询时未命中索引,从而引发表锁select * from s1 where email like "%xxx" for update; | |
| 步骤3 | -- 在事务二中查询数据正常select * from s1 where id = 2 for update ;-- 在事务二中查询数据正常select * from s1 where id = 3 for update ;-- 在事务二中查询数据正常select * from s1 where id = 4 for update ; | |
| 步骤4 | -- 提交一下事务,不要影响下一次实验 commit; |
-- 提交一下事务,不要影响下一次实验 commit; |
19.5.2 三种行锁的算法
InnoDB有三种行锁的算法,都属于排他锁:
a. Record Lock:单个行记录上的锁。
b. Gap Lock:间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;
对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
# 例如
例:假如employee表中只有101条记录,其depid的值分别是 1,2,...,100,101,下面的SQL:
mysql> select * from emp where depid > 100 for update;是一个范围条件的检索,并且命中了索引,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
Next-Key Lock:等于Record Lock结合Gap Lock,也就说Next-Key Lock既锁定记录本身也锁定一个范围,特别需要注意的是,InnoDB存储引擎还会对辅助索引下一个键值加上gap lock。
对于行查询,innodb采用的都是Next-Key Lock,主要目的是解决幻读的问题,以满足相关隔离级别以及恢复和复制的需要。
# 准备数据
mysql> create table t1(id int,key idx_id(id))engine=innodb;
Query OK, 0 rows affected (0.03 sec)
mysql> insert t1 values (1),(5),(7),(11);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> explain select * from t1 where id=7 for update\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ref
possible_keys: idx_id
key: idx_id
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec) 5-7 7-11 5 - 11
实验测试
| 事务一 | 事务二 | |
|---|---|---|
| 步骤1 | -- 开启事务start transaction; | -- 开启事务start transaction; |
| 步骤2 | -- 加排他锁select * from t1 where id=7 for update;-- 须知-- 1、上述语句命中了索引,所以加的是行锁-- 2、InnoDB对于行的查询都是采用了Next-Key Lock的算法,锁定的不是单个值,而是一个范围(GAP)表记录的索引值为1,5,7,11,其记录的GAP区间如下:(-∞,1],(1,5],(5,7],(7,11],(11,+∞)因为记录行默认就是按照主键自增的,所以是一个左开右闭的区间其中上述查询条件id=7处于区间(5,7]中,所以Next-Key lock会锁定该区间的记录,但是还没完-- 3、InnoDB存储引擎还会对辅助索引下一个键值加上gap lock。区间(5,7]的下一个Gap是(7,11],所以(7,11]也会被锁定综上所述,最终确定5-11之间的值都会被锁定 | |
| 步骤3 | -- 下述sql全都会阻塞在原地insert t1 values(5);insert t1 values(6);insert t1 values(7);insert t1 values(8);insert t1 values(9);insert t1 values(10);-- 下述等sql均不会阻塞insert t1 values(11); insert t1 values(1); insert t1 values(2);insert t1 values(3);insert t1 values(4); | |
| 步骤4 | -- 提交一下事务,不要影响下一次实验commit; | -- 提交一下事务,不要影响下一次实验commit; |
插入超时失败后,会怎么样?
超时时间的参数:innodb_lock_wait_timeout ,默认是50秒。
超时是否回滚参数:innodb_rollback_on_timeout 默认是OFF。
19.5.3 什么时候使用表锁
绝大部分情况使用行锁,但在个别特殊事务中,也可以考虑使用表锁
1. 事务需要更新大部分数据,表又较大
若使用默认的行锁,不仅该事务执行效率低(因为需要对较多行加锁,加锁是需要耗时的); 而且可能造成其他事务长时间锁等待和锁冲突; 这种情况下可以考虑使用表锁来提高该事务的执行速度。
2. 事务涉及多个表,较复杂,很可能引起死锁,造成大量事务回滚
这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销当然,应用中这两种事务不能太多,否则,就应该考虑使用MyISAM。
19.5.4 行锁优化建议
通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况,在着手根据状态量来分析改善。
mysql> show status like 'innodb_row_lock%';
+-------------------------------+--------+
| Variable_name | Value |
+-------------------------------+--------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 114092 |
| Innodb_row_lock_time_avg | 7606 |
| Innodb_row_lock_time_max | 50683 |
| Innodb_row_lock_waits | 15 |
+-------------------------------+--------+
5 rows in set (0.00 sec)
● 尽可能让所有数据检索都通过索引来完成, 从而避免无索引行锁升级为表锁
● 合理设计索引,尽量缩小锁的范围
● 尽可能减少检索条件,避免间隙锁
● 尽量控制事务大小,减少锁定资源量和时间长度
● 尽可能使用低级别事务隔离
19.6 乐观锁与悲观锁
数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。
乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
无论是悲观锁还是乐观锁,都是人们定义出来的概念,可以认为是一种思想。其实不仅仅是关系型数据库系统中有乐观锁和悲观锁的概念,像memcache、hibernate、tair等都有类似的概念。
针对于不同的业务场景,应该选用不同的并发控制方式。所以,不要把乐观并发控制和悲观并发控制狭义的理解为DBMS中的概念,更不要把他们和数据中提供的锁机制(行锁、表锁、排他锁、共享锁)混为一谈。其实,在DBMS中,悲观锁正是利用数据库本身提供的锁机制来实现的。
下面来分别学习一下悲观锁和乐观锁。
19.6.1 悲观锁
当我们要对一个数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。
这种借助数据库锁机制在修改数据之前先锁定,再修改的方式被称之为悲观并发控制(又名“悲观锁”,Pessimistic Concurrency Control,缩写“PCC”)。
悲观并发控制主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
● 优点:
○ 悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。
● 缺点:
○ 在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;
○ 在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;还有会降低了并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数
# 案例:假设商品表中有一个字段quantity表示当前该商品的库存量。假设有一件商品A,其id为100,quantity=8个;如果不使用锁,那么操作方法:
# 悲观锁:
//step1: 查出商品状态
select quantity from items where id=100 for update;
//step2: 根据商品信息生成订单
insert into orders(id,item_id) values(null,100);
//step3: 修改商品的库存
update Items set quantity=quantity-2 where id=100;
19.6.2 乐观锁
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。
# 案例:假设商品表中有一个字段quantity表示当前该商品的库存量。假设有一件商品A,其id为100,quantity=8个;如果不使用锁,那么操作方法:
# 乐观锁:
//step1: 判断商品状态是否加锁
update items set quantity=quantity-2 where id = 100 and quantity-2 >= 0;
//step2: 根据商品信息生成订单
insert into orders(id,item_id) values(null,100);
19.6.3 优点与不足
乐观并发控制相信事务之间的数据竞争(data race)的概率是比较小的,因此尽可能直接做下去,直到提交的时候才去锁定,所以不会产生死锁。
# 那么如何选择悲观锁还是乐观锁?
在乐观锁与悲观锁的选择上面,主要看下两者的区别以及适用场景就可以了。
1. 乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败
2. 悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
随着互联网三高架构(高并发、高性能、高可用)的提出,悲观锁已经越来越少的被使用到生产环境中了,尤其是并发量比较大的业务场景。
20、数据库备份
数据库备份的步骤:全备--基于全备的增备--基于增备的增备--恢复全备数据--恢复全备的增备数据--恢复增备的增备。
# 创建备份目录
[root@mysql03 2022-03-07_22-15-27]# mkdir /backup
# 安装依赖包
[root@mysql03 2022-03-07_22-15-27]# yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MYSQL
# 上传软件包并安装
[root@mysql03 2022-03-07_22-15-27]# yum install percona-xtrabackup-24-2.4.24-1.el7.x86_64.rpm -y
# 全量备份数据库
[root@mysql03 2022-03-07_22-15-27]# innobackupex --user=root --password=Test123! /backup/full
# 查看备份完成
[root@mysql03 2022-03-07_22-15-27]# cd /backup/full/
[root@mysql03 2022-03-07_22-15-27]# ll
# 登录数据库新增数据
[root@mysql03 2022-03-07_22-15-27]# mysql -uroot -pTest123!
mysql> use ceshi;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
mysql> insert into student (name, age) value ('美美', 20);
Query OK, 1 row affected (0.01 sec)
mysql> select *from student;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 小明 | 18 |
| 2 | 小红 | 17 |
| 3 | 小花 | 16 |
| 4 | 铁锤 | 18 |
| 5 | 美美 | 20 |
+----+--------+-----+
5 rows in set (0.00 sec)
mysql> exit;
Bye
# 进行增量备份
[root@mysql03 backup]# innobackupex --user=root --password=Test123! --incremental --incremental-basedir=/backup/full/2022-03-07_22-15-27/ /backup/full2
# 查看备份完成
[root@mysql03 backup]# ll
# 再次登录数据库新增数据
[root@mysql03 full2]# mysql -uroot -pTest123!
mysql> insert into ceshi.student (name,age) value ('球球', 16);
mysql> select * from ceshi.student;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 小明 | 18 |
| 2 | 小红 | 17 |
| 3 | 小花 | 16 |
| 4 | 铁锤 | 18 |
| 5 | 美美 | 20 |
| 6 | 球球 | 16 |
+----+--------+-----+
6 rows in set (0.00 sec)
mysql> exit;
Bye
# 进行增量的增量备份
[root@mysql03 full2]# innobackupex --user=root --password=Test123! --incremental --incremental-basedir=/backup/full/2022-03-07_22-15-27/ --incremental-dir=/backup/full2/2022-03-07_22-30-41/ /backup/full3
# 登录数据库删除数据模拟数据库故障
[root@mysql03 full2]# mysql -uroot -pTest123!
mysql> drop database ceshi;
# 合并全备目录确保数据一致性(初始化预处理)
[root@mysql03 backup]# innobackupex --apply-log --redo-only /backup/full/2022-03-07_22-15-27/
# 把增备数据合并到全备数据目录中
[root@mysql03 backup]# innobackupex --apply-log --redo-only /backup/full/2022-03-07_22-15-27/ --incremental-dir=/backup/full2/2022-03-07_22-30-41/
[root@mysql03 backup]# innobackupex --apply-log --redo-only /backup/full/2022-03-07_22-15-27/ --incremental-dir=/backup/full3/2022-03-07_22-38-24/
# 恢复数据:要求空目录,原目录不为空,先改名再创建一个同名的空目录授权即可
[root@mysql03 data]# cd /usr/local/mysql-5.7.36/
[root@mysql03 mysql-5.7.36/]# mv data datav1
[root@mysql03 mysql-5.7.36/]# mkdir data
[root@mysql03 mysql-5.7.36/]# chown mysql.mysql data
[root@mysql03 backup]# innobackupex --copy-back /backup/full/2022-03-07_22-15-27/
# 授权给恢复的数据目录并启动mysql查看恢复情况
[root@mysql03 data]# chown -R mysql.mysql /usr/local/mysql-5.7.36/data
[root@mysql03 backup]# systemctl restart mysqld
[root@mysql03 backup]# mysql -uroot -pTest123!
mysql> select * from ceshi.student;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 小明 | 18 |
| 2 | 小红 | 17 |
| 3 | 小花 | 16 |
| 4 | 铁锤 | 18 |
| 5 | 美美 | 20 |
+----+--------+-----+
5 rows in set (0.00 sec)
mysql>
21、数据导入与导出
# 修改配置文件:新增
[root@mysql03 data]# cat /etc/my.cnf
secure_file_priv=
# 重启mysql并登录mysql
[root@mysql03 data]# systemctl restart mysqld
[root@mysql03 data]# mysql -uroot -pTest123!
# 导出数据
mysql> SELECT * FROM ceshi.student
-> INTO OUTFILE '/tmp/db_t1.txt'
-> FIELDS TERMINATED by ','
-> OPTIONALLY ENCLOSED by '"'
-> LINES TERMINATED by '\n';
Query OK, 5 rows affected (0.00 sec)
# 查看导出
[root@mysql03 backup]# cd /tmp
[root@mysql03 backup]# ll
# 删除原表
mysql> DELETE from student;
Query OK, 0 rows affected (0.00 sec)
# 安装原表结构创建新的表并导入数据:
mysql> load data infile '/tmp/db_t1.txt'
-> into table ceshi.student2
-> fields terminated by ','
-> optionally enclosed by '"'
-> lines terminated by '\n';
Query OK, 5 rows affected (0.00 sec)
Records: 5 Deleted: 0 Skipped: 0 Warnings: 0
# 查看导入的数据
mysql> select * from student2;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 小明 | 18 |
| 2 | 小红 | 17 |
| 3 | 小花 | 16 |
| 4 | 铁锤 | 18 |
| 5 | 美美 | 20 |
+----+--------+-----+
5 rows in set (0.00 sec)
mysql>
22、MySQL日志管理
22.1 日志分类
| 日志种类 | 作用 |
|---|---|
| 错误日志 | 记录 MySQL 服务器启动、关闭及运行错误等信息 |
| 事务日志 | 1、redo log重做日志 2、undo log回滚日志 |
| 查询日志 | 记录所有的sql |
| 慢查询日志 | 记录执行时间超过指定时间的操作,如果是全表查询,即便没有超时也会被记录下来 |
| 二进制日志 | 又称binlog日志,以二进制文件的方式记录数据库中除 SELECT 以外的操作。即只记录写操作不记录读操作 |
| 中继日志 | 备库将主库的二进制日志复制到自己的中继日志中,从而在本地进行重放 |
| 通用日志 | 审计哪个账号、在哪个时段、做了哪些事件 |
22.2 错误日志
MySQL错误日志是记录MySQL 运行过程中较为严重的警告和错误信息,以及MySQL每次启动和关闭的详细信息。错误日志使用log_error以及log_warnings等参数进行定义。
# 查看错误日志
-- 方式一
mysql> show variables like '%log_error%';
+---------------------+---------------------+
| Variable_name | Value |
+---------------------+---------------------+
| binlog_error_action | ABORT_SERVER |
| log_error | /var/log/mysqld.log |
| log_error_verbosity | 3 |
+---------------------+---------------------+
3 rows in set (0.13 sec)
-- 方式二
[root@localhost ~]# mysqladmin -uroot -pTest123! variables | grep -w log_error
| log_error | /var/log/mysqld.log
22.3 查看警告日志
log_warnings:
0:表示不记录警告信息
1:表示记录警告信息到错误日志
大于1表示"失败的连接"的信息和创建新连接时"拒绝访问"类的错误信息也会被记录到错误日志中。
# 查看
mysql> show variables like '%log_warnings%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_warnings | 2 |
+---------------+-------+
1 row in set (0.00 sec)
22.4 设置错误日志
设置错误日志的方式也有两种,分别是临时设置和永久设置。
# 临时设置:
[root@localhost mysql-5.7.34]# /usr/local/mysql-5.7.34/support-files/mysql.server start --log_error=/tmp/DB-Server.localdomain.err
[root@localhost mysql-5.7.34]# mysql -uroot -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.7.34 Source distribution
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show variables like '%log_error%';
+---------------------+--------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------+
| binlog_error_action | ABORT_SERVER |
| log_error | /tmp/DB-Server.localdomain.err |
| log_error_verbosity | 3 |
+---------------------+--------------------------------+
3 rows in set (0.01 sec)
mysql>
# 永久设置:
[root@localhost ~]# vim /etc/my.cnf
log-error=/var/log/mysql-error.log
[root@localhost ~]# touch /var/log/mysql-error.log
[root@localhost ~]# chown mysql.mysql /var/log/mysql-error.log
[root@localhost ~]# systemctl start mysqld
[root@localhost ~]# mysql -uroot -pTest123!
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.7.34 Source distribution
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show variables like '%log_error%';
+---------------------+--------------------------+
| Variable_name | Value |
+---------------------+--------------------------+
| binlog_error_action | ABORT_SERVER |
| log_error | /var/log/mysql-error.log |
| log_error_verbosity | 3 |
+---------------------+--------------------------+
3 rows in set (0.00 sec)
22.5 事务的日志
innodb事务日志包括redo log和undo log。redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作。
undo log不是redo log的逆向过程,其实它们都算是用来恢复的日志:
1. redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
2. undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录。根据标记进行回滚
# redo log
redo log包括两部分:
1. 内存中的日志缓冲(redo log buffer),该部分日志是易失性的
2. 磁盘上的重做日志文件(redo log file),该部分日志是持久的
在概念上,innodb通过force log at commit机制实现事务的持久性,即在事务提交的时候,必须先将该事务的所有事务日志写入到磁盘上的redo log file和undo log file中进行持久化。
为了确保每次日志都能写入到事务日志文件中,在每次将log buffer中的日志写入日志文件的过程中都会调用一次操作系统的fsync操作(即fsync()系统调用)。因为MariaDB/MySQL是工作在用户空间的,MariaDB/MySQL的log buffer处于用户空间的内存中。要写入到磁盘上的log file中,中间还要经过操作系统内核空间的os buffer,调用fsync()的作用就是将OS buffer中的日志刷到磁盘上的log file中。
# undo log
undo log有两个作用:提供回滚和多个行版本控制(MVCC)。
在数据修改的时候,不仅记录了redo,还记录了相对应的undo,如果因为某些原因导致事务失败或回滚了,可以借助该undo进行回滚。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。有时候应用到行版本控制的时候,也是通过undo log来实现的:当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定一致性读取。
undo log是采用段(segment)的方式来记录的,每个undo操作在记录的时候占用一个undo log segment。另外,undo log也会产生redo log,因为undo log也要实现持久性保护。
# undo log相关的变量
mysql> show variables like "%undo%";
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 |
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
+--------------------------+------------+
5 rows in set (0.00 sec)
22.6 一般查询日志
一般不会开启,因为哪怕你开启事务一顿操作,最后不提交也会记录,生产上程序跑sql很多,会非常非常占地方,从来都不启动,要看操作去binlog。
[root@localhost ~]# vim /etc/my.cnf
general_log=on
general_log_file=/var/log/select.log
[root@localhost ~]# touch /var/log/select.log
[root@localhost ~]# chown mysql.mysql /var/log/select.log
[root@localhost ~]# chmod 640 /var/log/select.log
[root@localhost ~]# systemctl restart mysqld
[root@localhost ~]# mysql -uroot -p123456
mysql> show variables like '%gen%';
+----------------------------------------+---------------------+
| Variable_name | Value |
+----------------------------------------+---------------------+
| auto_generate_certs | ON |
| general_log | ON |
| general_log_file | /var/log/select.log |
| sha256_password_auto_generate_rsa_keys | ON |
+----------------------------------------+---------------------+
4 rows in set (0.01 sec)
22.7 慢查询日志
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10S以上的语句。默认情况下,Mysql数据库并不启动慢查询日志,需要我们手动来设置这个参数,当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
# 慢查询日志相关参数
● slow_query_log:是否开启慢查询日志,1表示开启,0表示关闭。
● log-slow-queries :旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
● slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
● long_query_time :慢查询阈值,当查询时间多于设定的阈值时,记录日志
● log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。
● log_output:日志存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。MySQL数据库支持同时两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
#指定是否开启慢查询日志
slow_query_log = on
#指定慢日志文件存放位置(默认在data)
slow_query_log_file=/var/log/slow.log
#设定慢查询的阀值(默认10s)
long_query_time=0.05
#不使用索引的慢查询日志是否记录到日志
log_queries_not_using_indexes=ON
#查询检查返回少于该参数指定行的SQL不被记录到慢查询日志,少于100行的sql语句查询慢的话不记录,一般不使用
log_output='FILE'
# 测试慢日志
[root@localhost ~]# cat /etc/my.cnf
[mysqld]
#指定是否开启慢查询日志
slow_query_log = on
#指定慢日志文件存放位置(默认在data)
slow_query_log_file=/var/log/slow.log
#设定慢查询的阀值(默认10s)
long_query_time=0.05
#不使用索引的慢查询日志是否记录到日志
log_queries_not_using_indexes=ON
#查询检查返回少于该参数指定行的SQL不被记录到慢查询日志,少于100行的sql语句查询慢的话不记录,一般不使用
log_output='FILE'
[root@localhost ~]# touch /var/log/slow.log
[root@localhost ~]# chown mysql.mysql /var/log/slow.log
[root@localhost ~]# systemctl restart mysqld
mysql> show variables like '%slow_query%';
+---------------------+-------------------+
| Variable_name | Value |
+---------------------+-------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/log/slow.log |
+---------------------+-------------------+
2 rows in set (0.01 sec)
[root@localhost ~]# mysql -uroot -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.34-log Source distribution
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select sleep(3);
+----------+
| sleep(3) |
+----------+
| 0 |
+----------+
1 row in set (3.01 sec)
22.8 二进制日志
MySQL的二进制日志(binary log)是一个二进制文件,主要用于记录修改数据或有可能引起数据变更的MySQL语句。二进制日志(binary log)中记录了对MySQL数据库执行更改的所有操作,并且记录了语句发生时间、执行时长、操作数据等其它额外信息,但是它不记录SELECT、SHOW等那些不修改数据的SQL语句。二进制日志(binary log)主要用于数据库恢复和主从复制,以及审计(audit)操作。
# 开启和设置二进制日志
默认情况下二进制日志是关闭的,通过配置文件来启动和设置二进制日志。修改my.cnf,插入如下内容,然后重启mysqld服务。
[mysqld]
server-id = 1 # mysql5.7必须加,否则mysql服务启动报错
binlog_format='row' # binlog工作模式
log-bin = /var/lib/mysql/mybinlog # 路径及命名,默认在data下
expire_logs_days = 10 # 过期时间,二进制文件自动删除的天数,0代表不删除
max_binlog_size = 100M # 单个日志文件大小
binlog_rows_query_log_events=on # 打开才能查看详细记录,默认为off
-- 开启binglog
[root@localhost ~]# vim /etc/my.cnf
[root@localhost ~]# touch /var/lib/mysql/mybinlog
[root@localhost ~]# chown mysql.mysql /var/lib/mysql/mybinlog
[root@localhost ~]# systemctl restart mysqld
# 二进制日志状态查看
-- 通过show variables like 'log_bin%'查看二进制日志设置
mysql> show variables like 'log_bin%';
+---------------------------------+-------------------------------+
| Variable_name | Value |
+---------------------------------+-------------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/mybinlog |
| log_bin_index | /var/lib/mysql/mybinlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
+---------------------------------+-------------------------------+
5 rows in set (0.01 sec)
-- 查看当前服务器所有的二进制日志文件 show binary logs / show master logs
mysql> show binary logs;
+-----------------+-----------+
| Log_name | File_size |
+-----------------+-----------+
| mybinlog.000001 | 154 |
+-----------------+-----------+
1 row in set (0.00 sec)
-- 查看当前二进制日志状态 show master status
mysql> show master status;
+-----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------------+----------+--------------+------------------+-------------------+
| mybinlog.000001 | 154 | | | |
+-----------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
# 二进制日志切换方法
每次重启MySQL服务也会生成一个新的二进制日志文件,相当于二进制日志切换。切换二进制日志时,你会看到这些number会不断递增。另外,除了这些二进制日志文件外,你会看到还生成了一个DB-Server-bin.index的文件,这个文件中存储所有二进制日志文件的清单又称为二进制文件的索引。
执行 flush logs 可以刷新切换二进制文件。
mysql> show master status;
+-----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------------+----------+--------------+------------------+-------------------+
| mybinlog.000001 | 154 | | | |
+-----------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
mysql> flush logs;
Query OK, 0 rows affected (0.35 sec)
mysql> show master status;
+-----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------------+----------+--------------+------------------+-------------------+
| mybinlog.000002 | 154 | | | |
+-----------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
# 二进制文件的查看
使用show binlog events 可以获取二进制日志。
mysql> show binlog events\G
*************************** 1. row ***************************
Log_name: mybinlog.000001
Pos: 4
Event_type: Format_desc
Server_id: 1
End_log_pos: 123
Info: Server ver: 5.7.34-log, Binlog ver: 4
*************************** 2. row ***************************
Log_name: mybinlog.000001
Pos: 123
Event_type: Previous_gtids
Server_id: 1
End_log_pos: 154
Info:
*************************** 3. row ***************************
Log_name: mybinlog.000001
Pos: 154
Event_type: Rotate
Server_id: 1
End_log_pos: 200
Info: mybinlog.000002;pos=4
3 rows in set (0.00 sec)
# 打印二进制日志到一个明文文件,该文件记录的更新了数据的sql,但是在5.7以上已经被加密。
# 打印日志文件
[root@localhost ~]# mysqlbinlog /var/lib/mysql/mybinlog.000001 > mysql-bin.log
# 解密文件
[root@localhost ~]# mysqlbinlog --base64-output=decode-rows -v /var/lib/mysql/mybinlog.000001 > mysql-bin.log
# 使用二进制日志恢复数据库
如果开启了二进制日志,出现了数据丢失,可以通过二进制日志恢复数据库,语法如下:mysqlbinlog [option] filename | mysql -u user -p passwd
option的参数主要有两个 --start-datetime --stop-datetime 和 start-position --stop-position ,前者指定恢复的时间点,后者指定恢复的位置(位置指的是二进制文件中 # at 580 580就是位置)。原理就是把记录的语句重新执行了一次,如果恢复了两次。会产生重复数据。
[root@localhost mysql]# mysqlbinlog --start-position="154" /var/lib/mysql/mybinlog.000004 | mysql -uroot -pTest123!
# 注意,要找到插入更新的语句所在的时间点或位置。如果恢复的语句包含只有delete,会报错1032错误。
# 暂时停止二进制日志功能
可以通过修改配置文件停止二进制日志功能,但是需要重启数据库,mysql提供了语句可以在线停止二进制功能。
set sql_log_bin = 0 # 停止二进制日志功能
set sql_log_bin = 1 # 开启二进制日志功能
# 二进制日志的三种模式
二进制日志三种格式:STATEMENT,ROW,MIXED,由参数binlog_format控制。
1. STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况(如非确定函数)下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)。
2. ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
3. MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
22.9 中继日志
从服务器I/O线程将主服务器的二进制日志读取过来记录到从服务器本地文件,然后从服务器SQL线程会读取relay-log日志的内容并应用到从服务器,从而使从服务器和主服务器的数据保持一致。
mysql> show variables like '%relay%';
+---------------------------+--------------------------------------------------------+
| Variable_name | Value |
+---------------------------+--------------------------------------------------------+
| max_relay_log_size | 0 |
| relay_log | |
| relay_log_basename | /usr/local/mysql-5.7.34/data/localhost-relay-bin |
| relay_log_index | /usr/local/mysql-5.7.34/data/localhost-relay-bin.index |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | FILE |
| relay_log_purge | ON |
| relay_log_recovery | OFF |
| relay_log_space_limit | 0 |
| sync_relay_log | 10000 |
| sync_relay_log_info | 10000 |
+---------------------------+--------------------------------------------------------+
11 rows in set (0.00 sec)
# 变量详解
relay_log fileName: 指定中继日志的文件名。【文件名为空,表示禁用了中继日志】
relay_log_index: 索引表
relay_log_info_file: 记录中继日志文件的相关信息
relay_log_purge: 指定是否自动删除无用的中继日志文件
relay_log_recovery: 是否可以对中继日志做自动恢复相关的配置
relay_log_space_limit: 指定中继日志可以占用的空间大小(0表示不限制)
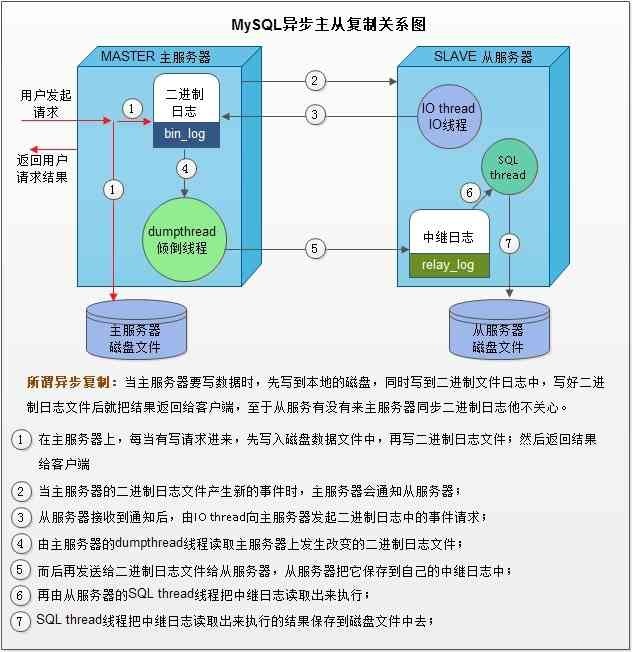
22.10 通用日志
记录连接数据库信息和所有操作信息。
mysql> show variables where variable_name like "%general_log%" or variable_name="log_output";
+------------------+---------------------+
| Variable_name | Value |
+------------------+---------------------+
| general_log | ON |
| general_log_file | /var/log/select.log |
| log_output | FILE |
+------------------+---------------------+
3 rows in set (0.00 sec)
# 变量解析
● general_log:OFF表示关闭通用日志,ON表示开启通用日志
● general_log_file:表示通用日志文件路径
● log_output:FILE表示记录文件,TABLE表示记录表,FILE,TABLE表示同时记录文件和表
# 测试通用日志
mysql> SET GLOBAL general_log = 'ON';
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL log_output = 'FILE,TABLE';
Query OK, 0 rows affected (0.00 sec)
mysql> select * from mysql.general_log\G
*************************** 1. row ***************************
event_time: 2021-10-13 21:22:23.599822
user_host: root[root] @ localhost []
thread_id: 2
server_id: 1
command_type: Query
argument: select * from mysql.general_log
*************************** 2. row ***************************
event_time: 2021-10-13 21:22:55.783993
user_host: [root] @ localhost []
thread_id: 4
server_id: 1
command_type: Connect
argument: root@localhost on using Socket
*************************** 3. row ***************************
event_time: 2021-10-13 21:22:55.784466
user_host: root[root] @ localhost []
thread_id: 4
server_id: 1
command_type: Query
argument: select @@version_comment limit 1
*************************** 4. row ***************************
event_time: 2021-10-13 21:22:58.409048
user_host: root[root] @ localhost []
thread_id: 2
server_id: 1
command_type: Query
argument: select * from mysql.general_log
*************************** 5. row ***************************
event_time: 2021-10-13 21:23:27.197193
user_host: root[root] @ localhost []
thread_id: 2
server_id: 1
command_type: Query
argument: select * from mysql.general_log
5 rows in set (0.00 sec)
23、主从复制
23.1 在主库上创建一个用于复制的账号
mysql> grant replication slave on *.* to 'shanhe'@'%' identified by 'Test123!';
23.2 刷新权限
mysql> flush privileges;
23.3 修改主库配置文件并重启mysql
[root@mysql03 data]# vim /etc/my.cnf
[mysqld]
basedir=/var/lib/mysql
port=3306
socket=/var/lib/mysql/mysql.sock
character-set-server=utf8
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
server-id=1
log-bin = /var/lib/mysql/mybinlog
sync_binlog=1
binlog_format=row
expire_logs_days=7
max_binlog_size=100m
binlog_cache_size=4m
max_binlog_cache_size=512m
binlog-ignore-db=mysql
auto-increment-offset=1
auto-increment-increment=1
slave-skip-errors=all
[mysql]
socket=/var/lib/mysql/mysql.sock
[client]
socket=/var/lib/mysql/mysql.sock
# 创建binlog目录并授权
[root@mysql03 data]# touch /var/lib/mysql/mybinlog
[root@mysql03 data]# chown mysql.mysql /var/lib/mysql/mybinlog
# 重启主库mysql
[root@mysql03 data]# systemctl restart mysqld
23.4 修改从库配置文件并重启mysql
[root@mysql-2 mysql]# vim /etc/my.cnf
basedir=/var/lib/mysql
port=3306
socket=/var/lib/mysql/mysql.sock
character-set-server=utf8
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
server-id=2
# 中继日志
relay-log=/var/lib/mysql/mysql02-relay-bin
replicate-wild-ignore-table=mysql.%
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%
[mysql]
socket=/var/lib/mysql/mysql.sock
[client]
socket=/var/lib/mysql/mysql.sock
# 重启从库的mysql
[root@mysql01 mysql]# systemctl restart mysqld
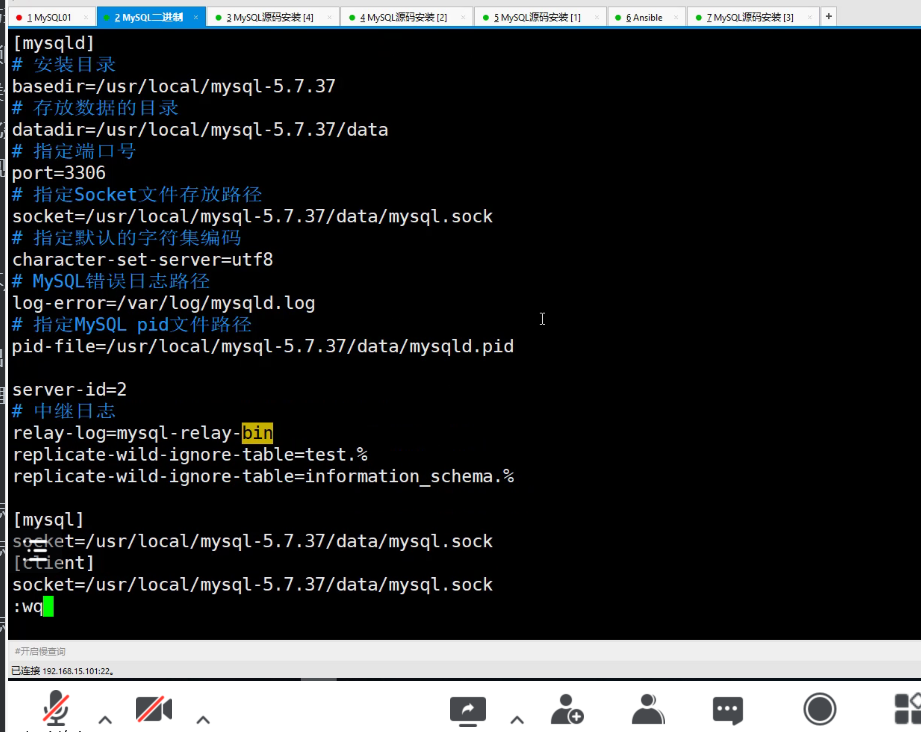
23.5 查看主库bin-log日志状态用于配置主从配置
# 配置主从复制,首先得在MySQL Master节点查出binlog日志状态,然后配置主从复制
# 在MySQL Master节点查出binlog日志状态:
mysql> show master status ;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000001 | 154 | | mysql | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
23.6 在从库配置主从复制
# 首先测试主库是否连接正常
[root@mysql-2 mysql]# mysql -uroot -pTest123! -h192.168.15.61
[root@slave1 ~]# mysql -uroot -pTest123! # 登录然后执行
change master to
master_host='192.168.15.61', -- 库服务器的IP
master_port=3306, -- 主库端口
master_user='shanhe', -- 主库用于复制的用户
master_password='Test123!', -- 密码
master_log_file='binlog.000001', -- 主库日志名
master_log_pos=154; -- 主库日志偏移量,即从何处开始复制
23.7 查看主从复制结果
mysql> start slave;
23.8 半同步复制
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
# 半同步复制超时则会切换回异步复制,正常后则切回半同步复制
在半同步复制时,如果主库的一个事务提交成功了,在推送到从库的过程当中,从库宕机了或网络故障,导致从库并没有接收到这个事务的Binlog,此时主库会等待一段时间(这个时间由rpl_semi_sync_master_timeout的毫秒数决定),如果这个时间过后还无法推送到从库,那MySQL会自动从半同步复制切换为异步复制,当从库恢复正常连接到主库后,主库又会自动切换回半同步复制。
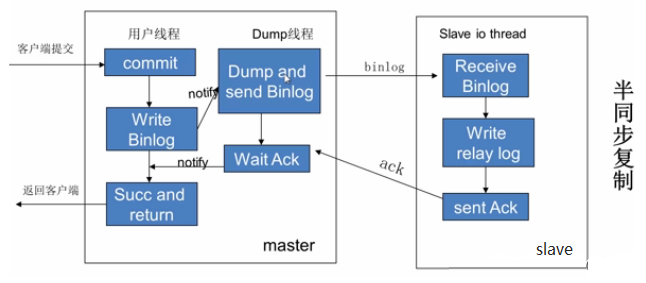
23.9部署半同步复制
半同步模式是作为MySQL5.5的一个插件来实现的,主从库使用的插件不一样。
#1.先确认主从的MySQL服务器是否支持动态增加插件
mysql> select @@have_dynamic_loading;
+------------------------+
| @@have_dynamic_loading |
+------------------------+
| YES |
+------------------------+
1 row in set (0.08 sec)
#2.分别在主从库上安装对用插件
-- 主库安装插件
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.28 sec)
-- 从库安装插件
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (0.20 sec)
#3.在主库开启半同步复制
mysql> set global rpl_semi_sync_master_enabled=1;
Query OK, 0 rows affected (0.09 sec)
mysql> set global rpl_semi_sync_master_timeout=30000;
Query OK, 0 rows affected (0.00 sec)
# 添加到配置文件
[root@mysql-1 ~]# vim /etc/my.cnf
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000
#4.在从库开启半同步复制
mysql> set global rpl_semi_sync_slave_enabled=1;
Query OK, 0 rows affected (0.07 sec)
mysql> stop slave io_thread;
Query OK, 0 rows affected (0.09 sec)
mysql> start slave io_thread;
Query OK, 0 rows affected (0.06 sec)
# 添加到配置文件之中
[root@mysql-2 ~]# vim /etc/my.cnf
rpl_semi_sync_slave_enabled =1
#5.在主库上查看半同步复制的状态(这两个变量常用来监控主从是否运行在半同步复制模式下。)
-- 主库查看
mysql> show status like 'Rpl_semi_sync_master_status';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| Rpl_semi_sync_master_status | ON |
+-----------------------------+-------+
1 row in set (0.00 sec)
-- 从库查看
mysql> show status like 'Rpl_semi_sync_slave_status';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
1 row in set (0.00 sec)
23.9 多主多从
在企业中,数据库高可用一直是企业的重中之重,中小企业很多都是使用mysql主从方案,一主多从,读写分离等,但是单主存在单点故障,从库切换成主库需要作改动。因此,如果是双主或者多主,就会增加mysql入口,增加高可用。不过多主需要考虑自增长ID问题,这个需要特别设置配置文件,比如双主,可以使用奇偶,总之,主之间设置自增长ID相互不冲突就能完美解决自增长ID冲突问题。
23.9.1 MySQL双主(主主)架构方案思路
1. 两台mysql都可读写,互为主备,默认只使用一台(masterA)负责数据的写入,另一台(masterB)备用。
2. masterA是masterB的主库,masterB又是masterA的主库,它们互为主从。
3. 两台主库之间做高可用,可以采用keepalived等方案(使用VIP对外提供服务)。
4. 所有提供服务的从服务器与masterB进行主从同步(双主多从)。
5. 建议采用高可用策略的时候,masterA或masterB均不因宕机恢复后而抢占VIP(非抢占模式)。
这样做可以在一定程度上保证主库的高可用,在一台主库down掉之后,可以在极短的时间内切换到另一台主库上(尽可能减少主库宕机对业务造成的影响),减少了主从同步给线上主库带来的压力;但是也有几个不足的地方:
1. masterB可能会一直处于空闲状态。
2. 主库后面提供服务的从库要等masterB先同步完了数据后才能去masterB上去同步数据,这样可能会造成一定程度的同步延时。
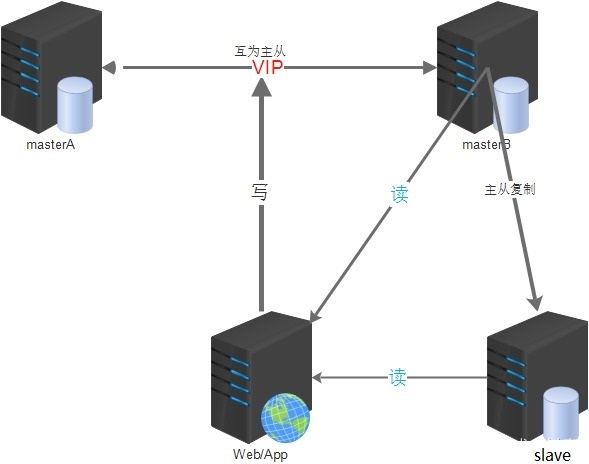
23.9.2 修改主节点的配置文件
[mysqld]
basedir=/usr/local/mysql
datadir=/data
port=3306
socket=/usr/local/mysql/mysql.sock
character-set-server=utf8
log-error=/var/log/mysqld.log
pid-file=/tmp/mysqld.pid
# 节点ID,确保唯一
server-id = 1
#开启mysql的binlog日志功能
log-bin=binlog
#控制数据库的binlog刷到磁盘上去 , 0 不控制,性能最好,1每次事物提交都会刷到日志文件中,性能最差,最安全
sync_binlog=1
#binlog日志格式
binlog_format=row
#binlog过期清理时间
expire_logs_days=7
#binlog每个日志文件大小
max_binlog_size=100m
#binlog缓存大小
binlog_cache_size=4m
#最大binlog缓存大小
max_binlog_cache_size=512m
#不生成日志文件的数据库,多个忽略数据库可以用逗号拼接,或者 复制黏贴下述配置项,写多行
binlog-ignore-db=mysql
# 表中自增字段每次的偏移量
auto-increment-offset=1
# 表中自增字段每次的自增量
auto-increment-increment=2
#跳过从库错误
slave-skip-errors=all
#将复制事件写入binlog,一台服务器既做主库又做从库此选项必须要开启
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency=true
master-info-repository=file
relay-log-info-repository=file
sync-master-info=1
slave-parallel-workers=0
sync_binlog=0
binlog-checksum=CRC32
master-verify-checksum=1
slave-sql-verify-checksum=1
binlog-rows-query-log_events=1
max_binlog_size=1024M
# 忽略同步的数据库
replicate-ignore-db=mysql
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
replicate-ignore-db=sys
max_connections=3000
max_connect_errors=30
#忽略应用程序想要设置的其他字符集
skip-character-set-client-handshake
#连接时执行的SQL
init-connect='SET NAMES utf8'
#服务端默认字符集
character-set-server=utf8
#请求的最大连接时间
wait_timeout=1800
#和上一参数同时修改才会生效
interactive_timeout=1800
#sql模式
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
max_allowed_packet=10M
bulk_insert_buffer_size=8M
query_cache_type=1
query_cache_size=128M
query_cache_limit=4M
key_buffer_size=256M
read_buffer_size=16K
# 禁用反向解析
skip-name-resolve
slow_query_log=1
long_query_time=6
slow_query_log_file=slow-query.log
innodb_flush_log_at_trx_commit=2
innodb_log_buffer_size=16M
[mysql]
socket=/usr/local/mysql/mysql.sock
[client]
socket=/usr/local/mysql/mysql.sock
23.9.3 修改备节点的配置文件
[mysqld]
basedir=/usr/local/mysql
datadir=/data
port=3306
socket=/usr/local/mysql/mysql.sock
character-set-server=utf8
log-error=/var/log/mysqld.log
pid-file=/tmp/mysqld.pid
# 节点ID,确保唯一
server-id=2
#开启mysql的binlog日志功能
log-bin=binlog
#控制数据库的binlog刷到磁盘上去 , 0 不控制,性能最好,1每次事物提交都会刷到日志文件中,性能最差,最安全
sync_binlog=1
#binlog日志格式
binlog_format=row
#binlog过期清理时间
expire_logs_days=7
#binlog每个日志文件大小
max_binlog_size=100m
#binlog缓存大小
binlog_cache_size=4m
#最大binlog缓存大小
max_binlog_cache_size=512m
#不生成日志文件的数据库,多个忽略数据库可以用逗号拼接,或者 复制黏贴下述配置项,写多行
binlog-ignore-db=mysql
# 表中自增字段每次的偏移量
auto-increment-offset=2
# 表中自增字段每次的自增量
auto-increment-increment=2
#跳过从库错误
slave-skip-errors=all
#将复制事件写入binlog,一台服务器既做主库又做从库此选项必须要开启
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency=true
master-info-repository=file
relay-log-info-repository=file
sync-master-info=1
slave-parallel-workers=0
sync_binlog=0
binlog-checksum=CRC32
master-verify-checksum=1
slave-sql-verify-checksum=1
binlog-rows-query-log_events=1
max_binlog_size=1024M
# 忽略同步的数据库
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
replicate-ignore-db=sys
max_connections=3000
max_connect_errors=30
#忽略应用程序想要设置的其他字符集
skip-character-set-client-handshake
#连接时执行的SQL
init-connect='SET NAMES utf8'
#服务端默认字符集
character-set-server=utf8
#请求的最大连接时间
wait_timeout=1800
#和上一参数同时修改才会生效
interactive_timeout=1800
#sql模式
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
max_allowed_packet=10M
bulk_insert_buffer_size=8M
query_cache_type=1
query_cache_size=128M
query_cache_limit=4M
key_buffer_size=256M
read_buffer_size=16K
# 禁用反向解析
skip-name-resolve
slow_query_log=1
long_query_time=6
slow_query_log_file=slow-query.log
innodb_flush_log_at_trx_commit=2
innodb_log_buffer_size=16M
[mysql]
socket=/usr/local/mysql/mysql.sock
[client]
socket=/usr/local/mysql/mysql.sock
23.9.4 两个master阶段都必须重新初始化数据库
[root@mysql-1 ~]# mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/data
[root@mysql-2 ~]# mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/data
23.9.5 分别登陆数据库并创建复制账号(每个机器上都必须执行)
-- 使用临时密码登陆数据库
[root@mysql-2 ~]# mysql -uroot -p'_<r,zjMpG6-.'
-- 修改数据库临时密码
mysql> alter user root@localhost identified by 'Test123!';
Query OK, 0 rows affected (0.00 sec)
-- 利用数据库临时密码创建登陆
[root@mysql-2 ~]# mysql -uroot -p'Test123!'
-- 创建远程连接账号
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
Query OK, 0 rows affected, 1 warning (0.08 sec)
-- 删除其他默认密码
mysql> delete from mysql.user where host = 'localhost';
Query OK, 3 rows affected (0.29 sec)
-- 刷新权限
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.09 sec)
-- 重新登陆并创建远程复制账号
[root@mysql-2 ~]# mysql -uroot -pTest123!
mysql> grant replication slave on *.* to 'shanhe'@'%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
23.9.6 开始配置主从复制
-- 在master2上执行
mysql> change master to
-> master_host='192.168.15.61',
-> master_port=3306,
-> master_user='shanhe',
-> master_password='123456',
-> master_log_file='binlog.000002',
-> master_log_pos=1459;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
-- 在master1上执行
mysql> change master to
-> master_host='192.168.15.62',
-> master_port=3306,
-> master_user='shanhe',
-> master_password='123456',
-> master_log_file='binlog.000002',
-> master_log_pos=1459;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
23.9.7 查看连接结果
mysql> show slave status\G
23.9.8 测试双主
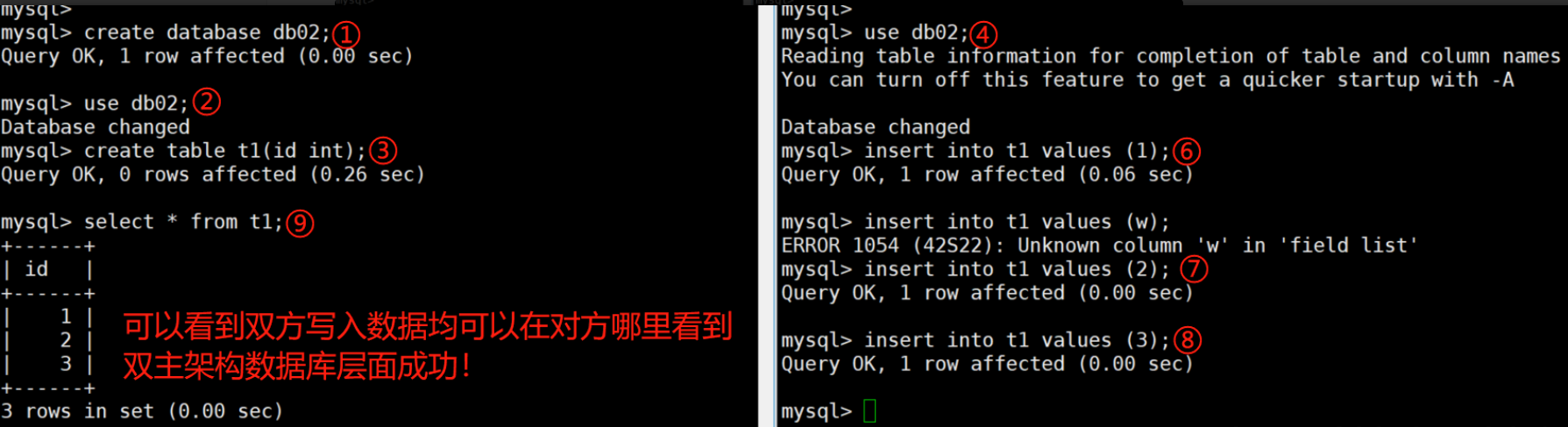
23.9.9 双主高可用
高可用是使用keepalived实现VIP。从而实现一个IP无感知操作两个主节点。
1、安装keepalived高可用软件(两个节点上全都安装)
[root@mysql-1 ~]# yum install keepalived -y
[root@mysql-2 ~]# yum install keepalived -y
2、修改keepalived的配置文件
[root@mysql-1 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_kubernetes {
script "/etc/keepalived/check_kubernetes.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
mcast_src_ip 192.168.15.61 # 所在节点的IP
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.15.60
}
}
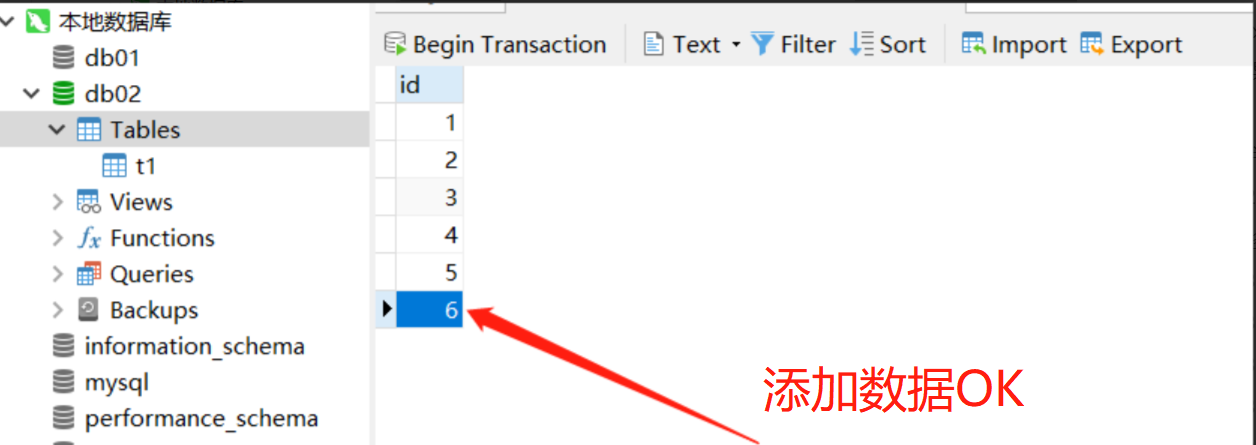
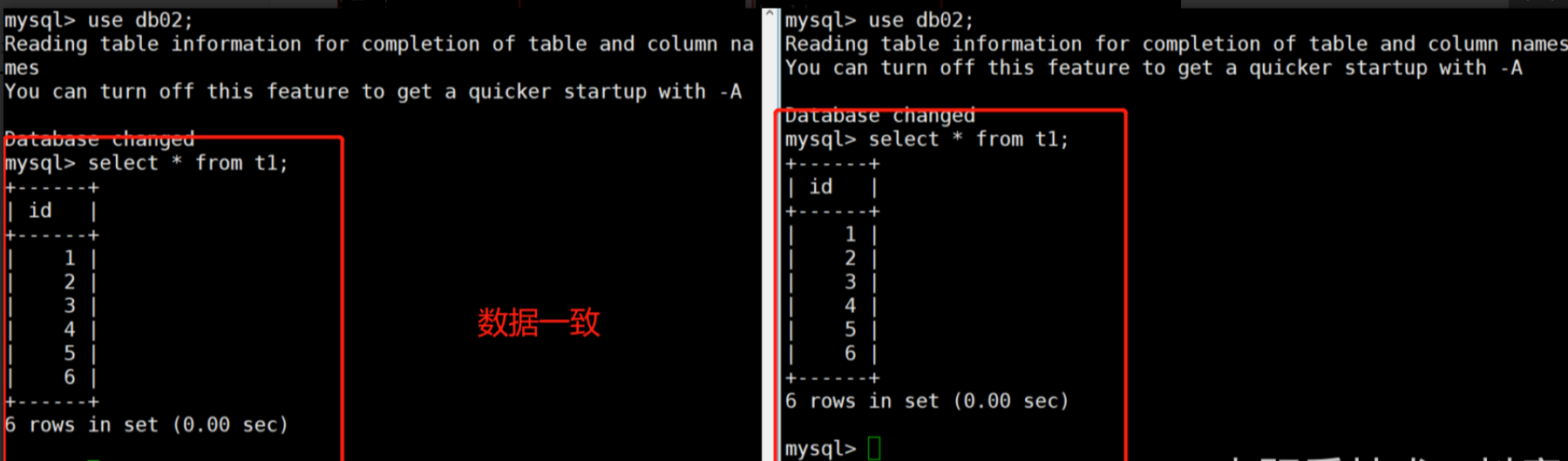
24、MHA实现MySQL的高可用
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA里有两个角色一个是MHA Node(数据节点)另一个是MHA Manager(管理节点)。 MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
24.1 MHA的工作原理
相较于其它HA软件,MHA的目的在于维持MySQL Replication中Master库的高可用性,其最大特点是可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并将其它Slave指向它。
1. 从宕机崩溃的master保存二进制日志事件(binlogevents)。
2. 识别含有最新更新的slave。
3. 应用差异的中继日志(relay log)到其它slave。
4. 应用从master保存的二进制日志事件(binlogevents)。
5. 提升一个slave为新master。 -使其它的slave连接新的master进行复制。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器。
24.2 MHA的优点总结
1. 自动的故障检测与转移,通常在10-30秒以内
2. MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升为主库),大概0.5-2秒内即可完成。
3. 很好地解决了主库崩溃数据的一致性问题。
4. 不需要对当前的mysql环境做重大修改。
5. 不需要在现有的复制框架中添加额外的服务器,仅需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量。
6. 性能优秀,可以工作在半同步和异步复制框架,支持gtid,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
7. 只要replication支持的存储引擎都支持MHA,不会局限于innodb。
8. 对于一般的keepalived高可用,当vip在一台机器上的时候,另一台机器是闲置的,而MHA中并无闲置主机。
24.3 GTID主从复制
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用自MySQL 5.5开始引入的半同步复制,可以大大降低数据丢失的风险。
MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性,或者采用GTID。
24.3.1 GTID
从MySQL 5.6.2 开始新增了一种基于 GTID 的复制方式,用以替代以前传统的复制方式,到MySQL5.6.10后逐渐完善。通过 GTID 保证了每个在主库上提交的事务在集群中有一个唯一的ID。这种方式强化了数据库的主备一致性,故障恢复以及容错能力,那么它如何做到的呢?
要想在分布式集群环境中不丢失事务,就必须为每个事务定制一个全局唯一的ID号,并且该ID是趋势递增的,以此我们便可以方便地顺序读取、不丢事务,其实GTID就是一种很好的分布式ID实践方案,它满足分布ID的两个基本要求
a. 全局唯一性
b. 趋势递增
GTID (Global Transaction ID全局事务ID)是如何做到全局唯一且趋势递增的呢,它是由UUID+TID两部分组成。
a. UUID是数据库实例的标识符
b. TID表示事务提交的数量,会随着事务的提交递增
因此他与主库上提交的每个事务相关联,GTID不仅对其发起的服务器是唯一的,而且在给定复制设置中的所有服务器都是唯一的,即所有的事务和所有的GTID都是1对1的映射。
当在主库上提交事务或者被从库应用时,可以定位和追踪每一个事务,对DBA来说意义就很大了,我们可以适当的解放出来,不用手工去可以找偏移量的值了,而是通过CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION=1的即可方便的搭建从库,在故障修复中也可以采用MASTER_AUTO_POSITION= 'X' 的方式。
5.7版本GTID做了增强,不手工开启也自动维护匿名的GTID信息。
24.3.2 GTID主从的原理
从服务器连接到主服务器之后,把自己执行过的GTID、获取到的GTID发给主服务器,主服务器把从服务器缺少的GTID及对应的transactions发过去补全即可。当主服务器挂掉的时候,找出同步最成功的那台从服务器,直接把它提升为主即可。如果硬要指定某一台不是最新的从服务器提升为主, 先change到同步最成功的那台从服务器, 等把GTID全部补全了,就可以把它提升为主了。
GTID是MySQL 5.6的新特性,可简化MySQL的主从切换以及Failover。GTID用于在binlog中唯一标识一个事务。当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog都会传递到从库,从库在执行的时候也是用同样的GTID写binlog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
简而言之,GTID的工作流程为:
● master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
● slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
● sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
● 如果有记录,说明该GTID的事务已经执行,slave会忽略。
● 如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
● 在解析过程中会判断是否有主键,如果没有就用二级索引,如果二级索引没有就用全部扫描。
24.3.3 GTID架构
同样的GTID不能被执行两次,如果有同样的GTID,会自动被skip掉。
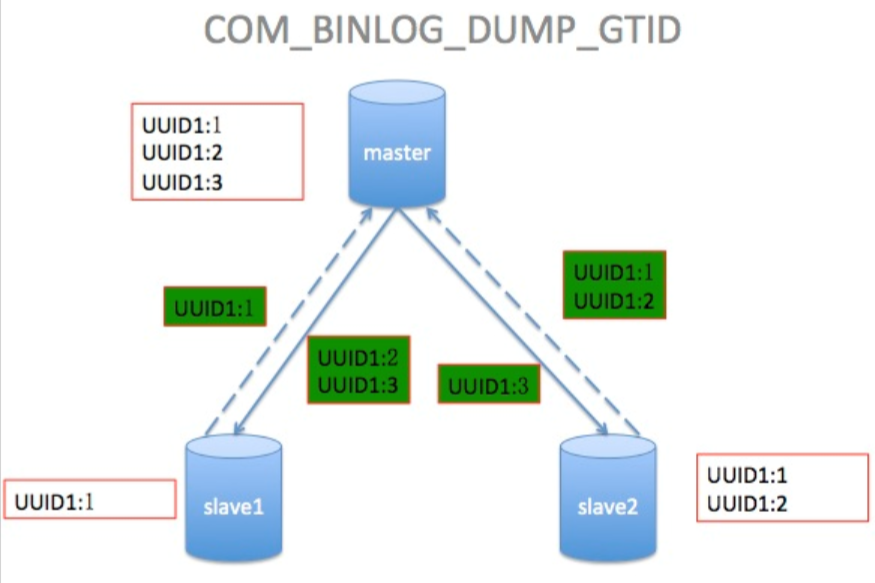
25.4.4 GTID的优缺点
# GTID的优点
● 一个事务对应一个唯一ID,一个GTID在一个服务器上只会执行一次。
● GTID是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置。
● 减少手工干预和降低服务故障时间,当主机挂了之后通过软件从众多的备机中提升一台备机为主机。
# GTID的缺点(限制)
● 不支持非事务引擎。
● 不支持create table ... select 语句复制(主库直接报错);(原理: 会生成两个sql, 一个是DDL创建表SQL, 一个是insert into 插入数据的sql; 由于DDL会导致自动提交, 所以这个sql至少需要两个GTID, 但是GTID模式下, 只能给这个sql生成一个GTID)。
● 不允许一个SQL同时更新一个事务引擎表和非事务引擎表。
● 在一个复制组中,必须要求统一开启GTID或者是关闭GTID。
● 开启GTID需要重启 (mysql5.7除外)。
● 开启GTID后,就不再使用原来的传统复制方式。
● 对于create temporary table(创建临时表) 和 drop temporary table (删除临时表)语句不支持。
● 不支持sql_slave_skip_counter(跳过错误)。
24.4 搭建实验环境
| 机器名称 | IP地址 | 角色 | 备注 |
|---|---|---|---|
| manager | 192.168.15.51 | Manager控制器 | 用于监控管理 |
| master | 192.168.15.52 | 主数据库服务器 | 开启binlog、relay-log,关闭relay_log_purge |
| slave1 | 192.168.15.53 | 从1数据库服务器 | 开启binlog、relay-log,关闭relay_log_purge、设置read_only=1 |
| slave2 | 192.168.15.54 | 从2数据库服务器 | 开启binlog、relay-log,关闭relay_log_purge、设置read_only=11 |
其中master对外提供写服务,备选master提供读服务,slave也提供相关的读服务,一旦master宕机,将会把备选master提升为新的master,slave指向新的master,manager作为管理服务器。
24.4.1 主库配置
[root@master ~]# vim /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/mysql_data
port=3306
socket=/usr/local/mysql/mysql.sock
character-set-server=utf8
log-error=/var/log/mysqld.log
pid-file=/tmp/mysqld.pid
# 节点ID,确保唯一
server-id=1
binlog_format=row
log-bin=mysql-bin
skip-name-resolve
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
relay_log_purge=0
sync_binlog=1
expire_logs_days=7
#binlog每个日志文件大小
max_binlog_size=100m
#binlog缓存大小
binlog_cache_size=4m
#最大binlog缓存大小
max_binlog_cache_size=512m
[mysql]
socket=/usr/local/mysql/mysql.sock
[client]
socket=/usr/local/mysql/mysql.sock
24.4.2 从库配置
[mysqld]
basedir=/usr/local/mysql
datadir=/mysql_data
port=3306
socket=/usr/local/mysql/mysql.sock
character-set-server=utf8
log-error=/var/log/mysqld.log
pid-file=/tmp/mysqld.pid
# 中继日志
relay-log=mysql-relay-bin
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%
# 节点ID,确保唯一
server-id=2
binlog_format=row
log-bin=mysql-bin
skip-name-resolve
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
relay_log_purge=0
sync_binlog=1
expire_logs_days=7
#binlog每个日志文件大小
max_binlog_size=100m
#binlog缓存大小
binlog_cache_size=4m
#最大binlog缓存大小
max_binlog_cache_size=512m
[mysql]
socket=/usr/local/mysql/mysql.sock
[client]
socket=/usr/local/mysql/mysql.sock
24.4.3 重新初始化
[root@slave01 ~]# mkdir /mysql_data
[root@slave01 ~]# chmod o+w /var/log
[root@slave01 ~]# mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/mysql_data
[root@slave01 ~]# vim /usr/lib/systemd/system/mysqld.service
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=https://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 5000
[root@slave01 ~]# chown -R mysql.mysql /usr/local/mysql
[root@slave01 ~]# chown -R mysql.mysql /usr/local/mysql-5.7.35-linux-glibc2.12-x86_64/
[root@slave01 ~]# systemctl daemon-reload
[root@slave01 ~]# systemctl start mysqld
[root@slave01 ~]# mysql -uroot -pTest123!
# 修改密码
mysql> alter user root@localhost identified by 'Test123!';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
24.4.4 增加主从复制用户
-- 主库执行
GRANT REPLICATION SLAVE ON *.* TO shanhe@'%' IDENTIFIED BY 'Test123!';
flush privileges;
-- 从库执行
change master to
master_host='172.16.0.11',
master_user='shanhe',
master_password='Test123!',
MASTER_AUTO_POSITION=1;
24.4.5 创建MHA管理用户
grant all on *.* to 'mhaadmin'@'%' identified by 'Test123!';
flush privileges;
24.4.6 设置从库可读
#1、在从库上进行操作
#设置只读,不要添加配置文件,因为从库以后可能变成主库
mysql> set global read_only=1;
# 2、查看可读状态
mysql> show global variables like "%read_only%";
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_read_only | OFF |
| read_only | ON |
| super_read_only | OFF |
| transaction_read_only | OFF |
| tx_read_only | OFF |
+-----------------------+-------+
5 rows in set (0.00 sec)
24.4.7 关闭MySQL自动清除relaylog的功能
#2、在所有库上都进行操作(这一步我们在5.3小节已经做过了,此处忽略即可)
#关闭MySQL自动清除relaylog的功能
mysql> set global relay_log_purge = 0;
#编辑配置文件
[root@mysql-db02 ~]# vim /etc/my.cnf
[mysqld]
#禁用自动删除relay log永久生效
relay_log_purge = 0
24.5 部署MHA
24.5.1 配置免密登录(所有主机之间互做)
ssh-copy-id
24.5.2 安装依赖包(所有机器执行)
# 安装yum源
wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
rpm -ivh epel-release-latest-7.noarch.rpm
# 安装MHA依赖的perl包
yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager
wget https://qiniu.wsfnk.com/mha4mysql-node-0.58-0.el7.centos.noarch.rpm --no-check-certificate
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
24.5.3 manager主机安装manager包
wget https://qiniu.wsfnk.com/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm --no-check-certificate
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
24.5.4 配置MHA Manager
# 创建工作目录
mkdir -p /service/mha/
mkdir /service/mha/app1
24.5.5 修改配置
vim /service/mha/app1.cnf
[server default]
#日志存放路径
manager_log=/service/mha/manager.log
#定义工作目录位置
manager_workdir=/service/mha/app1
#binlog存放目录(如果三台数据库机器部署的路径不一样,可以将配置写到相应的server下面)
#master_binlog_dir=/usr/local/mysql/data
#设置ssh的登录用户名
ssh_user=root
#如果端口修改不是22的话,需要加参数,不建议改ssh端口
#否则后续如负责VIP漂移的perl脚本也都得改,很麻烦
ssh_port=22
#管理用户
user=mhaadmin
password=123456
#复制用户
repl_user=shanhe
repl_password=123456
#检测主库心跳的间隔时间
ping_interval=1
[server1]
# 指定自己的binlog日志存放目录
master_binlog_dir=/mysql_data/mysql-bin
hostname=172.16.16.9
port=3306
[server2]
#暂时注释掉,先不使用
#candidate_master=1
#check_repl_delay=0
master_binlog_dir=/mysql_data/mysql-bin
hostname=172.16.16.11
port=3306
[server3]
master_binlog_dir=/mysql_data/mysql-bin
hostname=172.16.16.2
port=3306
# 1、设置了以下两个参数,则该从库成为候选主库,优先级最高
# 不管怎样都切到优先级高的主机,一般在主机性能差异的时候用
candidate_master=1
# 不管优先级高的备选库,数据延时多久都要往那切
check_repl_delay=0
# 2、上述两个参数详解如下:
# 设置参数candidate_master=1后,则判断该主机为为候选master,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave。
# 默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
# 3、应该为什么节点设置这俩参数,从而把该节点的优先级调高
# (1)、多地多中心,设置本地节点为高权重
# (2)、在有半同步复制的环境中,设置半同步复制节点为高权重
# (3)、你觉着哪个机器适合做主节点,配置较高的 、性能较好的
24.5.6 检测mha配置状态
#测试免密连接
1.使用mha命令检测ssh免密登录
masterha_check_ssh --conf=/service/mha/app1.cnf
ALL SSH ... successfilly 表示ok了
2.使用mha命令检测主从状态
masterha_check_repl --conf=/service/mha/app1.cnf
... Health is OK
#如果出现问题,可能是反向解析问题,配置文件加上
skip-name-resolve
#还有可能是主从状态,mha用户密码的情况
24.5.7 启动MHA
nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
命令参数:
--remove_dead_master_conf 该参数代表当发生主从切换后,宕机库的配置信息将会从配置文件中移除。
--manger_log 日志存放位置
--ignore_last_failover 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录,也就是上面设置的manager_workdir目录中产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为--ignore_last_failover。
#MHA的安全机制:
1.完成一次切换后,会生成一个锁文件在工作目录中
2.下次切换之前,会检测锁文件是否存在
3.如果锁文件存在,8个小时之内不允许第二次切换
24.5.8 主库切换优先级
1.做好主从
2.在主库上创建表
create database if not exists test;
create table test.t1(id int);
3.在主库运行下述脚本
for i in `seq 1 1000000`
do
mysql -e "insert into test.t1 values($i);"
sleep 1
done
4.将某一台从库的IO线程停止,该从库的数据必然落后了
stop slave io_thread;
5.停止主库查看切换情况
肯定不会选择那个停掉io先从的从库当新主库,但是该从库的io线程会
启动起来,然后指向新主库,并且数据更新到了最新
24.5.9 为自动切换主库配置vip漂移脚本
1.VIP漂移的两种方式:
1)通过keepalived的方式,管理虚拟IP的漂移
2)通过MHA自带脚本方式,管理虚拟IP的漂移(推荐)
# 为了防止脑裂发生,推荐生产环境采用脚本的方式来管理虚拟vip,而不是使用 keepalived来完成。
2.配置文件中指定脚本路径
[root@mysql-db03 ~]# vim /etc/mha/app1.cnf
[server default]
#指定自动化切换主库后,执行的vip迁移脚本路径
master_ip_failover_script=/service/mha/master_ip_failover
25、MySQL中间件Atlas
Mysql 的 proxy 中间件有比较多的工具,例如,mysql-proxy(官方提供), atlas , cobar, mycat, tddl, tinnydbrouter等等。而Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。目前该项目在360公司内部得到了广泛应用,很多MySQL业务已经接入了Atlas平台,每天承载的读写请求数达几十亿条。
同时,有超过50家公司在生产环境中部署了Atlas,超过800人已加入了我们的开发者交流群,并且这些数字还在不断增加。而且安装方便。配置的注释写的蛮详细的,都是中文。
Atlas官方链接: https://github.com/Qihoo360/Atlas/blob/master/README_ZH.md
Atlas下载链接: https://github.com/Qihoo360/Atlas/releases
25.1 主要功能
Atlas主要功能(代理)
1.读写分离
2.从库负载均衡
3.IP过滤
4.自动分表
5.DBA可平滑上下线DB(不影响用户的体验,把你的数据库下线)
6.自动摘除宕机的DB
Atlas相对于官方MySQL-Proxy的优势
1.将主流程中所有Lua代码用C重写,Lua仅用于管理接口
2.重写网络模型、线程模型
3.实现了真正意义上的连接池
4.优化了锁机制,性能提高数十倍
25.2 使用场景
Atlas是一个位于前端应用与后端MySQL数据库之间的中间件,在后端DB看来,Atlas相当于连接它的客户端,在前端应用看来,Atlas相当于一个DB。Atlas作为服务端与应用程序通讯,它实现了MySQL的客户端和服务端协议,同时作为客户端与MySQL通讯。它对应用程序屏蔽了DB的细节,同时为了降低MySQL负担,它还维护了连接池。
Atlas使得应用程序员无需再关心读写分离、分表等与MySQL相关的细节,可以专注于编写业务逻辑,同时使得DBA的运维工作对前端应用透明,上下线DB前端应用无感知。
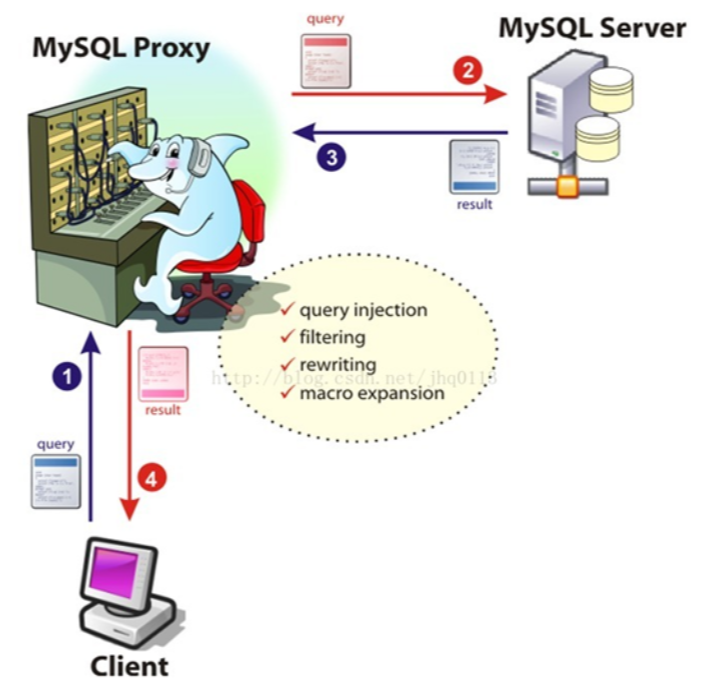
25.2.1 企业读写分离及分库分表其他方案了解
● Mysql-proxy(oracle)
● Mysql-router(oracle)
● Atlas (Qihoo 360)
● Atlas-sharding (Qihoo 360)
● Cobar(是阿里巴巴(B2B)部门开发)
● Mycat(基于阿里开源的Cobar产品而研发)
● TDDL Smart Client的方式(淘宝)
● Oceanus(58同城数据库中间件)
● OneProxy(原支付宝首席架构师楼方鑫开发 )
● vitess(谷歌开发的数据库中间件)
● Heisenberg(百度)
● TSharding(蘑菇街白辉)
● Xx-dbproxy(金山的Kingshard、当当网的sharding-jdbc )
● amoeba
25.3 安装Atlas
# 虽然包是el6的,但是centos7也能用
wget https://github.com/Qihoo360/Atlas/releases/download/2.2.1/Atlas-2.2.1.el6.x86_64.rpm
rpm -ivh Atlas-2.2.1.el6.x86_64.rpm
25.4 mysql库创建账号
grant all on *.* to 'root'@'%' identified by '123456';
flush privileges;
grant all on *.* to 'shanhe'@'%' identified by '123456';
flush privileges;
25.5 配置
[root@manager ~]# cd /usr/local/mysql-proxy/conf
[root@manager mysql-proxy]# vim test.cnf
[mysql-proxy]
#带#号的为非必需的配置项目
#管理接口的用户名
admin-username = shanhe
#管理接口的密码
admin-password = 123456
#Atlas后端连接的MySQL主库的IP和端口,可设置多项,用逗号分隔
proxy-backend-addresses = 192.168.0.10:3306
#Atlas后端连接的MySQL从库的IP和端口,@后面的数字代表权重,用来作负载均衡,若省略则默认为1,可设置多项,用逗号分隔
proxy-read-only-backend-addresses = 192.168.0.14:3306,192.168.0.6:3306
#用户名与其对应的加密过的MySQL密码,密码使用PREFIX/bin目录下的加密程序encrypt加密,下行的user1和user2为示例,将其替换为你的MySQL的用户名和加密密码!
pwds = root:/iZxz+0GRoA=, shanhe:/iZxz+0GRoA=
#设置Atlas的运行方式,设为true时为守护进程方式,设为false时为前台方式,一般开发调试时设为false,线上运行时设为true,true后面不能有空格。
daemon = true
#设置Atlas的运行方式,设为true时Atlas会启动两个进程,一个为monitor,一个为worker,monitor在worker意外退出后会自动将其重启,设为false时只有worker,没有monitor,一般开发调试时设为false,线上运行时设为true,true后面不能有空格。
keepalive = true
#工作线程数,对Atlas的性能有很大影响,可根据情况适当设置
event-threads = 8
#日志级别,分为message、warning、critical、error、debug五个级别
log-level = message
#日志存放的路径
log-path = /usr/local/mysql-proxy/log
#SQL日志的开关,可设置为OFF、ON、REALTIME,OFF代表不记录SQL日志,ON代表记录SQL日志,REALTIME代表记录SQL日志且实时写入磁盘,默认为OFF
sql-log = OFF
#慢日志输出设置。当设置了该参数时,则日志只输出执行时间超过sql-log-slow(单位:ms)的日志记录。不设置该参数则输出全部日志。
#sql-log-slow = 10
#实例名称,用于同一台机器上多个Atlas实例间的区分
#instance = test
#Atlas监听的工作接口IP和端口
proxy-address = 0.0.0.0:1234
#Atlas监听的管理接口IP和端口
admin-address = 0.0.0.0:2345
#分表设置,此例中person为库名,mt为表名,id为分表字段,3为子表数量,可设置多项,以逗号分隔,若不分表则不需要设置该项
#tables = person.mt.id.3
#默认字符集,设置该项后客户端不再需要执行SET NAMES语句
charset = utf8
#允许连接Atlas的客户端的IP,可以是精确IP,也可以是IP段,以逗号分隔,若不设置该项则允许所有IP连接,否则只允许列表中的IP连接
#client-ips = 127.0.0.1, 192.168.1
#Atlas前面挂接的LVS的物理网卡的IP(注意不是虚IP),若有LVS且设置了client-ips则此项必须设置,否则可以不设置
#lvs-ips = 192.168.1.1
25.6 启动服务
#1、启动,配置文件名为test.conf对应此处的test
[root@VM-0-11-centos conf]# /usr/local/mysql-proxy/bin/mysql-proxyd test start
OK: MySQL-Proxy of test is started
#2、验证启动(没起来他也显示OK)
[root@VM-0-11-centos conf]# ps -ef|grep [m]ysql-proxy
[root@VM-0-11-centos conf]# netstat -lntup|grep [m]ysql-proxy
#3、查看日志定位问题
tail -f /usr/local/mysql-proxy/log/test.log
25.7 Atlas使用
[root@VM-0-10-centos ~]# mysql -ushanhe -p123456 -h192.168.0.11 -P2345
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.0.99-agent-admin
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SELECT * FROM help;
+----------------------------+---------------------------------------------------------+
| command | description |
+----------------------------+---------------------------------------------------------+
| SELECT * FROM help | shows this help |
| SELECT * FROM backends | lists the backends and their state |
| SET OFFLINE $backend_id | offline backend server, $backend_id is backend_ndx's id |
| SET ONLINE $backend_id | online backend server, ... |
| ADD MASTER $backend | example: "add master 127.0.0.1:3306", ... |
| ADD SLAVE $backend | example: "add slave 127.0.0.1:3306", ... |
| REMOVE BACKEND $backend_id | example: "remove backend 1", ... |
| SELECT * FROM clients | lists the clients |
| ADD CLIENT $client | example: "add client 192.168.1.2", ... |
| REMOVE CLIENT $client | example: "remove client 192.168.1.2", ... |
| SELECT * FROM pwds | lists the pwds |
| ADD PWD $pwd | example: "add pwd user:raw_password", ... |
| ADD ENPWD $pwd | example: "add enpwd user:encrypted_password", ... |
| REMOVE PWD $pwd | example: "remove pwd user", ... |
| SAVE CONFIG | save the backends to config file |
| SELECT VERSION | display the version of Atlas |
+----------------------------+---------------------------------------------------------+
16 rows in set (0.00 sec)
mysql> SELECT * FROM backends;
+-------------+-------------------+-------+------+
| backend_ndx | address | state | type |
+-------------+-------------------+-------+------+
| 1 | 192.168.0.10:3306 | up | rw |
| 2 | 192.168.0.14:3306 | up | ro |
| 3 | 192.168.0.6:3306 | up | ro |
+-------------+-------------------+-------+------+
3 rows in set (0.00 sec)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号