
python基础之软件开发目录规范与正则表达式
一、软件开发目录规范
目录规范没有固定要求,只要符合清晰可读的原则即可。
一般有以下目录:
bin文件夹
存放一系列启动文件(若文件数量很少或者只有一个的时候可以直接放外面,不用放文件夹也可以)
start.py
cof文件夹
存放一系列配置文件
settings.py(一般情况下该文件内的变量名都是大写)
lib文件夹
存放公共功能
common.py
db文件夹
存放数据相关文件
userinfo.txt
log文件夹
存放日志记录文件
log.txt
core文件夹
存放核心代码文件
src.py
readme文件
存放说明相关信息(类似于说明书 广告 章程)
requirements.txt
存放项目所需的第三方模块及版本号
二、正则表达式简介
正则表达式是一门独立的语言,跟其他的编程语言都没有关系。
在python中想使用正则表达式就需要借助模块re
正则表达式利用一些特殊符号的组合去字符串中筛选出符合条件的字符。
可用在线测试网址:http://tool.chinaz.com/regex/
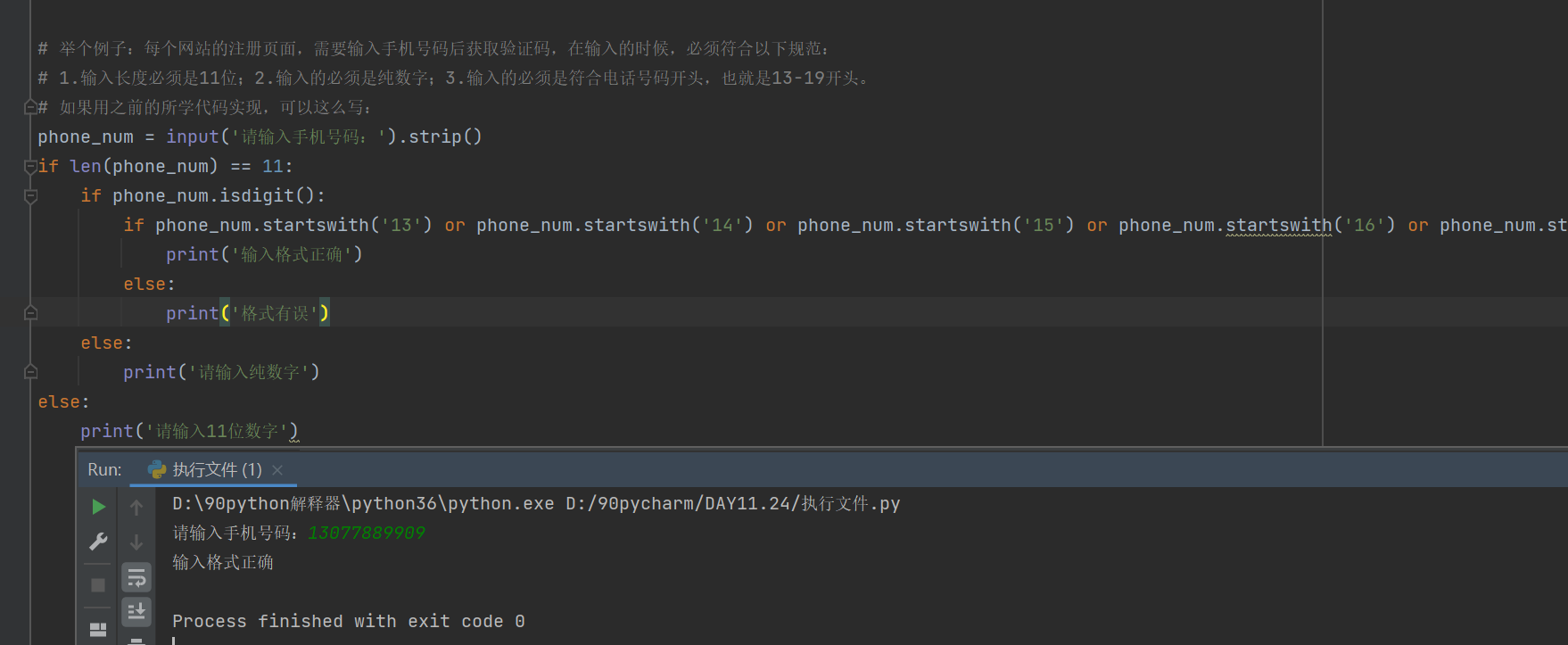
# 举个例子:每个网站的注册页面,需要输入手机号码后获取验证码,在输入的时候,必须符合以下规范:
# 1.输入长度必须是11位;2.输入的必须是纯数字;3.输入的必须是符合电话号码开头,也就是13-19开头。
# 如果用之前的所学代码实现,可以这么写:
phone_num = input('请输入手机号码:').strip()
if len(phone_num) == 11:
if phone_num.isdigit():
if phone_num.startswith('13') or phone_num.startswith('14') or phone_num.startswith('15') or phone_num.startswith('16') or phone_num.startswith('17') or phone_num.startswith('18') or phone_num.startswith('19'):
print('输入格式正确')
else:
print('格式有误')
else:
print('请输入纯数字')
else:
print('请输入11位数字')
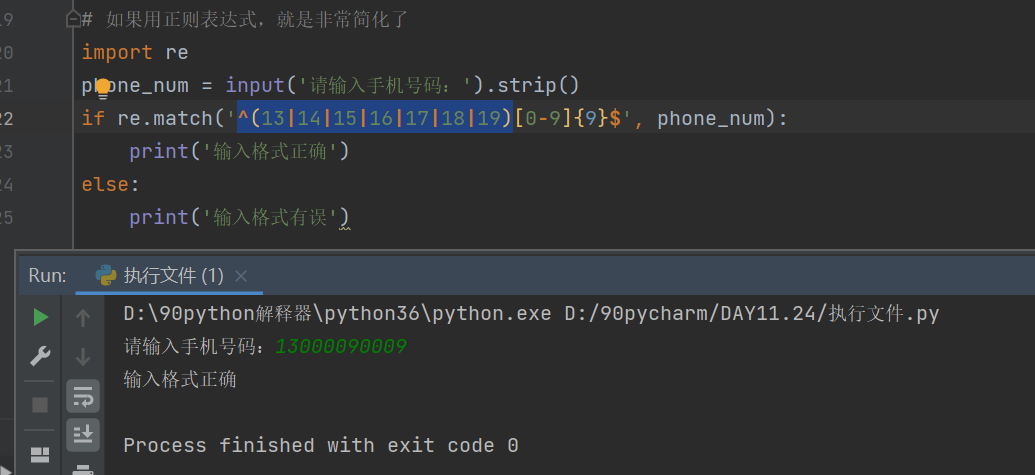
# 如果用正则表达式,就是非常简化了
import re
phone_num = input('请输入手机号码:').strip()
if re.match('^(13|14|15|16|17|18|19)[0-9]{9}$', phone_num):
print('输入格式正确')
else:
print('输入格式有误')
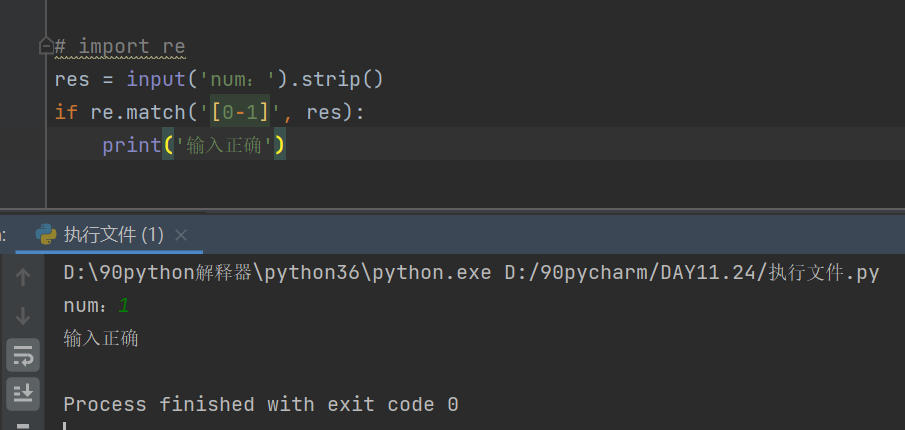
三、正则表达式之字符组
字符组的特征是中括号括起来,字符串默认只能单个单个字符匹配。
[0-9] 匹配0-9任意一个数字
[a-z] 匹配a-z任意一个小写字母
[A-Z] 匹配A-Z任意一个大写字母
[0-9a-zA-Z] 匹配0-9,a-z,A-Z之间的任意一个字符,书写的时候中括号内不需要字符隔开,会自动有识别的
四、正则表达式之特殊符号
特殊符号也默认只能单个单个匹配。
. 匹配除了换行符之外的任意字符
\d 匹配任意数字
^ 匹配字符串的开头
$ 匹配字符串的末尾
^...$连用就是精准匹配...字符串
a|b 匹配a或b
() 匹配括号内的表达式,也表示一个组,不会影响正则表达式的匹配单纯的分组而已
[...] 匹配字符组中的字符
[^...] 取反,匹配除了字符组中的所有字符
五、正则表达式之量词
在没有量词修饰的情况下,字符串匹配都是默认单个。量词必须要配合字符组或者特殊字符使用,不能单独使用。量词只能作用前面一个表达式。量词的使用默认贪婪匹配,意思是匹配的时候符合多的就出多的结果。
* 重复零次或多次
+ 重复一次或多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n到多次
{n, m} 重复n到m次
六、贪婪匹配与非贪婪匹配
正则表达式默认贪婪匹配,尽可能多的匹配。
前面的那些量词*、+、?、{n}...都是默认贪婪匹配
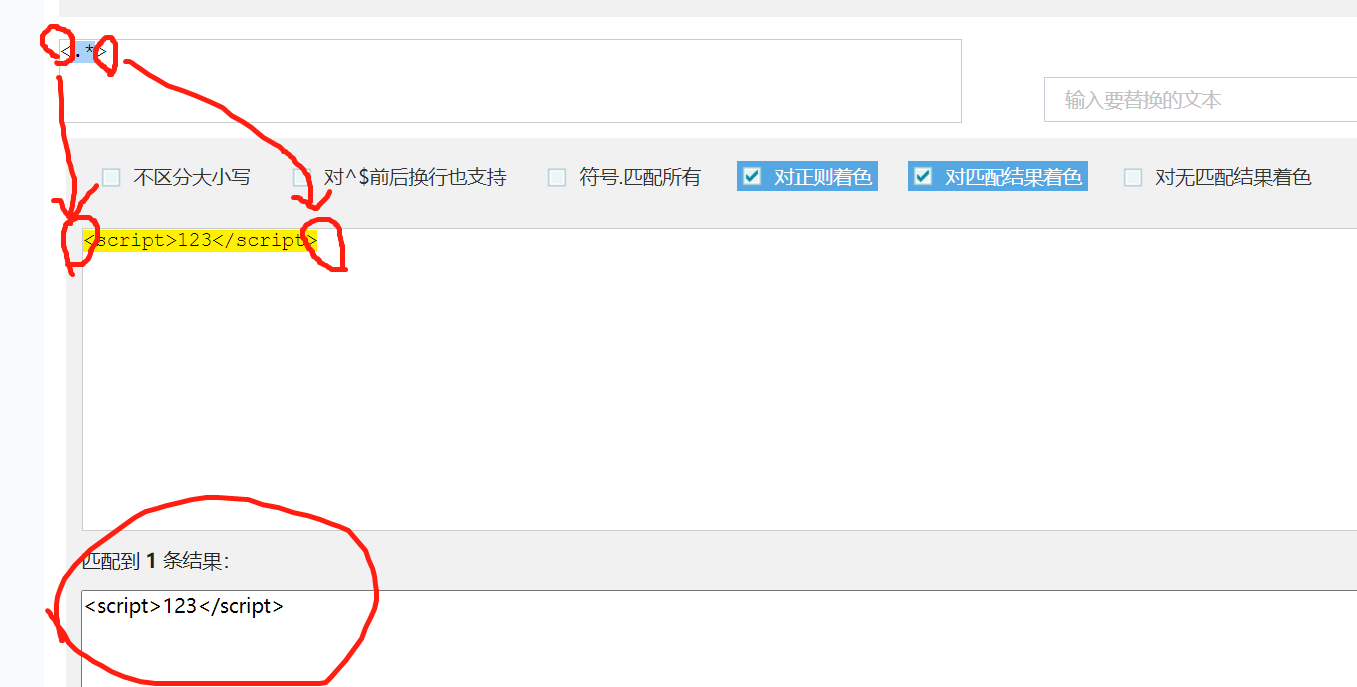
如果要变成非贪婪匹配,可以这么写(加个问号):
在量词后面加一个? .? 就可以变成非贪婪匹配。
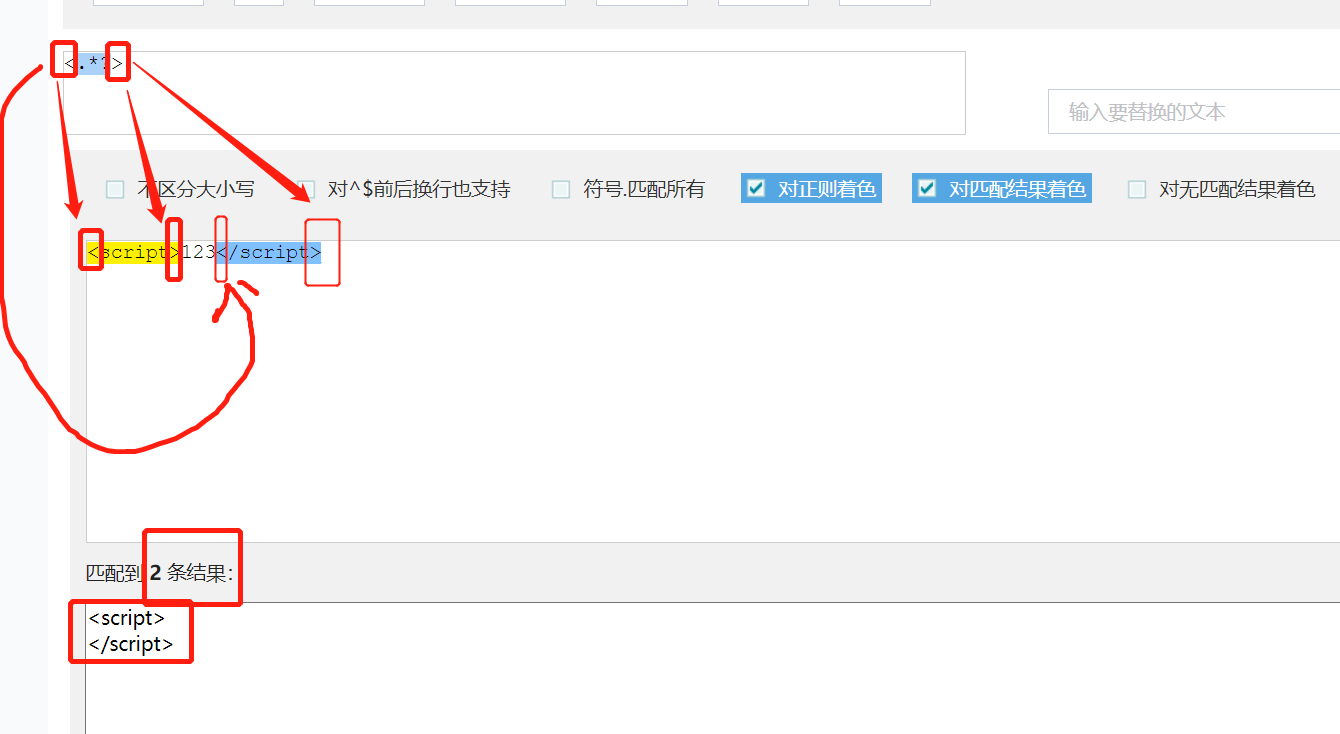
注意:一些常见的正则表达式不需要自己写,可以网上找一下
