python基础之字符编码与文件操作
一、debug调试
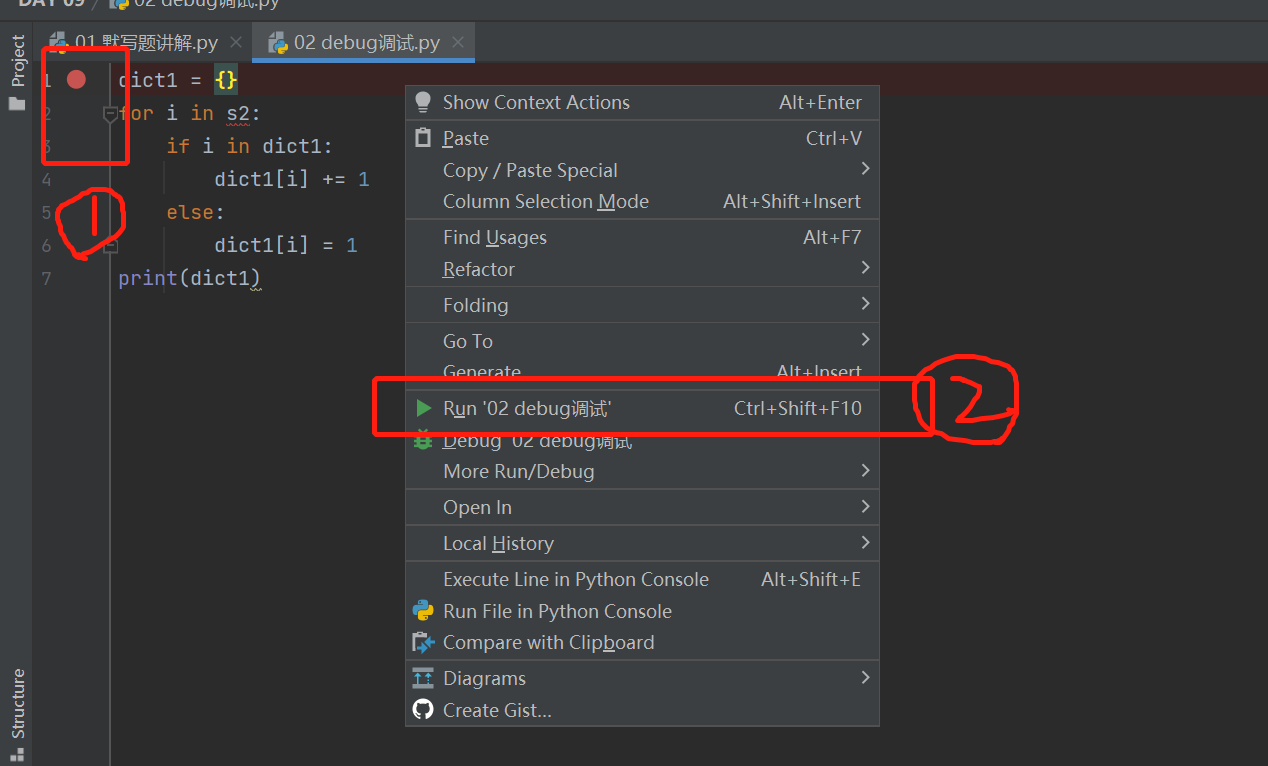
1.先使用鼠标左键在需要调试的代码左边点击一下(会出现一个红点)
2.之后右键点击debug运行代码
二、员工管理系统
三、字符编码
现在默认使用的编码是utf8。
字符编码只跟文本文件和字符串有关,也就是只跟纯文本有关,跟其他的视频、图片之类的都无关。
字符编码:由于计算机内部只能识别二进制,但是用户在使用计算机的时候却可以看成各式各样的语言字符。字符编码内部记录了人类字符与数字的对应关系。
四、字符编码发展史
1.一家独大
计算机最初是由美国人发明的 美国人为了能够让计算机识别英文字符
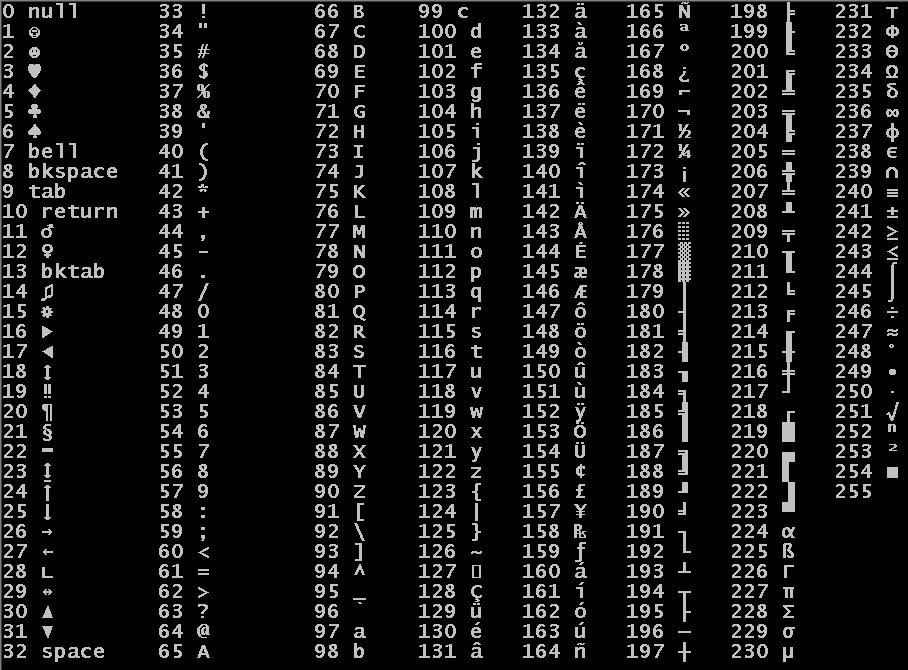
ASCII码:里面记录了英文字符与数字的对应关系,用一个字节来是对应关系。
所有的英文字符和符号加起来其实不超过127,之所以使用八位是为了后续发现新的语言。
2.群雄割据
中国人:为了能够让计算机识别中文 我们需要发明另外一套编码表
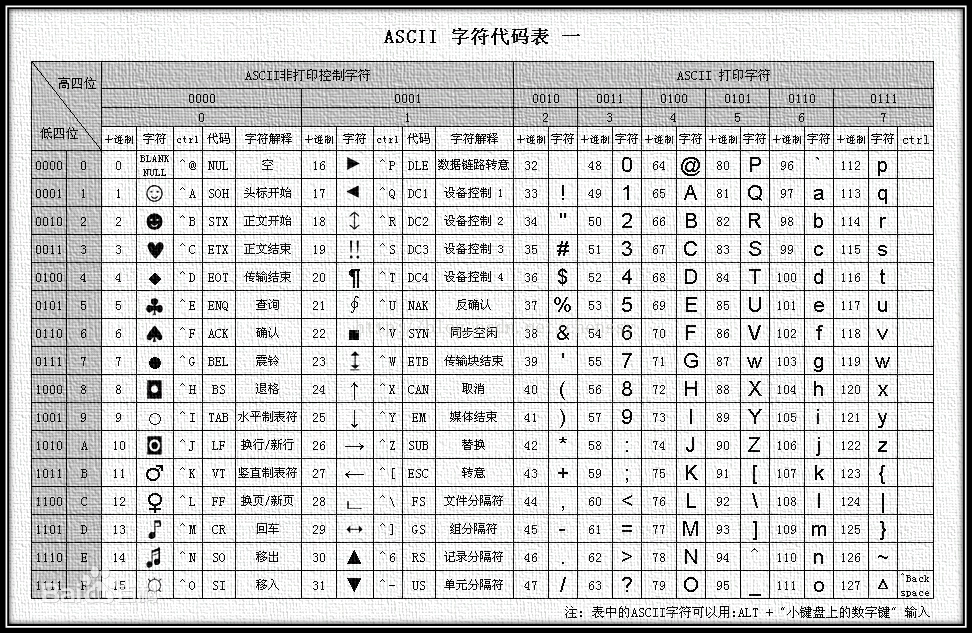
GBK码:记录了英文中文与数字的对应关系,对于英文还是使用一个字节,对应中文使用两个字节甚至更多字节,两个字节其实也不够表示出所有的中文,遇到生僻字可能需要更多位来表示。
日本人:为了能够让计算机识别日文 也需要发明一套编码表
shift_JIS码:记录了日文英文与数字的对应关系
韩国人:为了能够让计算机识别韩文 也需要发明一套编码表
Euc_kr码:记录了韩文英文与数字的对应关系
3.天下一统
为了能够实现不同国家之间的文本数据能够彼此无障碍交流需要对编码统一。
unicode(万国码:1994年产生):统一使用两个及以上字符记录字符与数字的对应关系
utf8(万国码的优化版本):将英文还是用一个字节存储,将中文使用三个字节或更多字节存储
现在默认使用的编码是utf8。
五、字符编号实操
1.如何解决文件乱码的情况:文件当初以什么编码编的 打开的时候就以什么编码解
2.python解释器版本不同带来的编码差异:python2.X内部使用的编码默认是ASCII;python3.X内部使用utf8码,解决问题可以在文件头加上# coding:utf8,然后在python定义的数据类型前面加个u
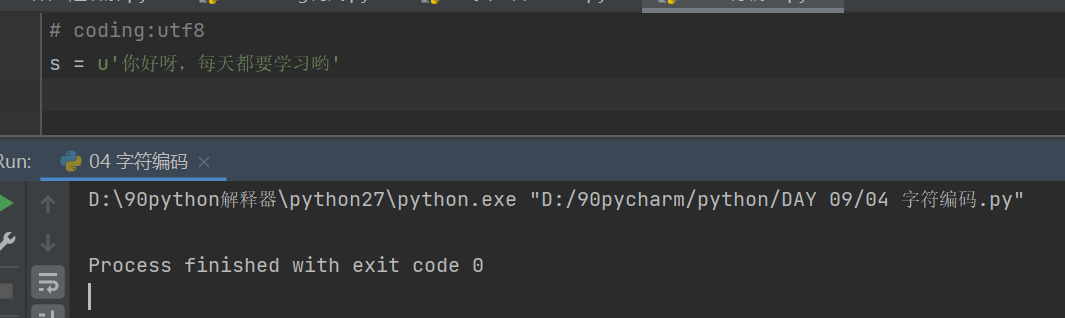
2.1 自定义模板(python3中可以兼容python2):
自定义文件模板内容
file
settings
Editor
file and code templates
python script
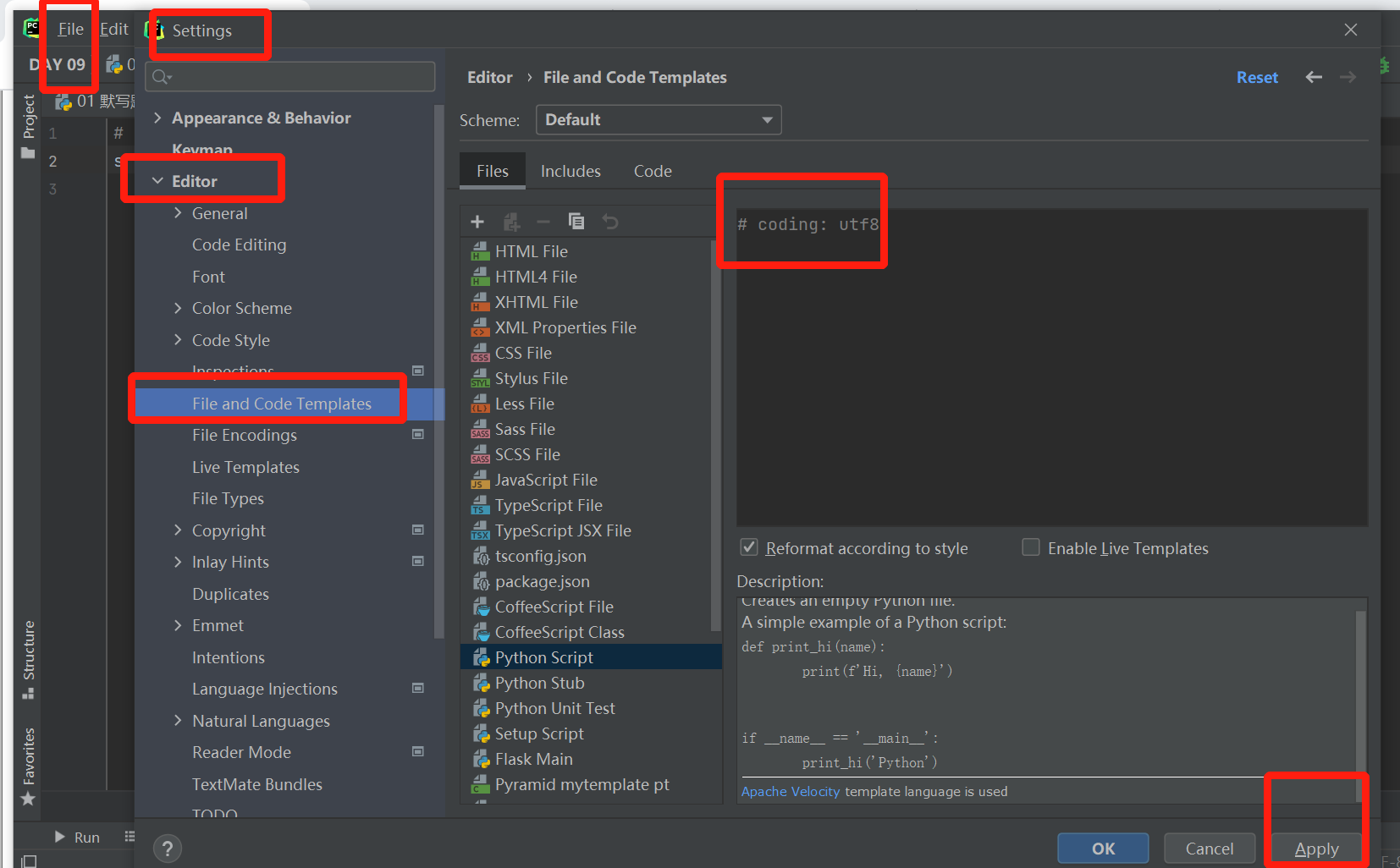
3.编码与解码
编码:将人类能够读懂的字符安装指定的编码转换成数字>>> .encode()
解码:将数字按照指定的编码转换成人类能够读懂的字符>>> .decode()
六、文件操作
文件:操作系统暴露给用户简单快捷操作硬盘的接口。
代码如何操作文件:关键字open();三步走:1.利用关键字open打开文件;2.利用其它方法操作文件; 3.关闭文件
文件路径:相对路径与绝对路径
路径中出现了字母与斜杠的组合产生了特殊含义如何取消:在路径字符串前面加一个r >>> eg: r'D:\py20\day08\a.txt'
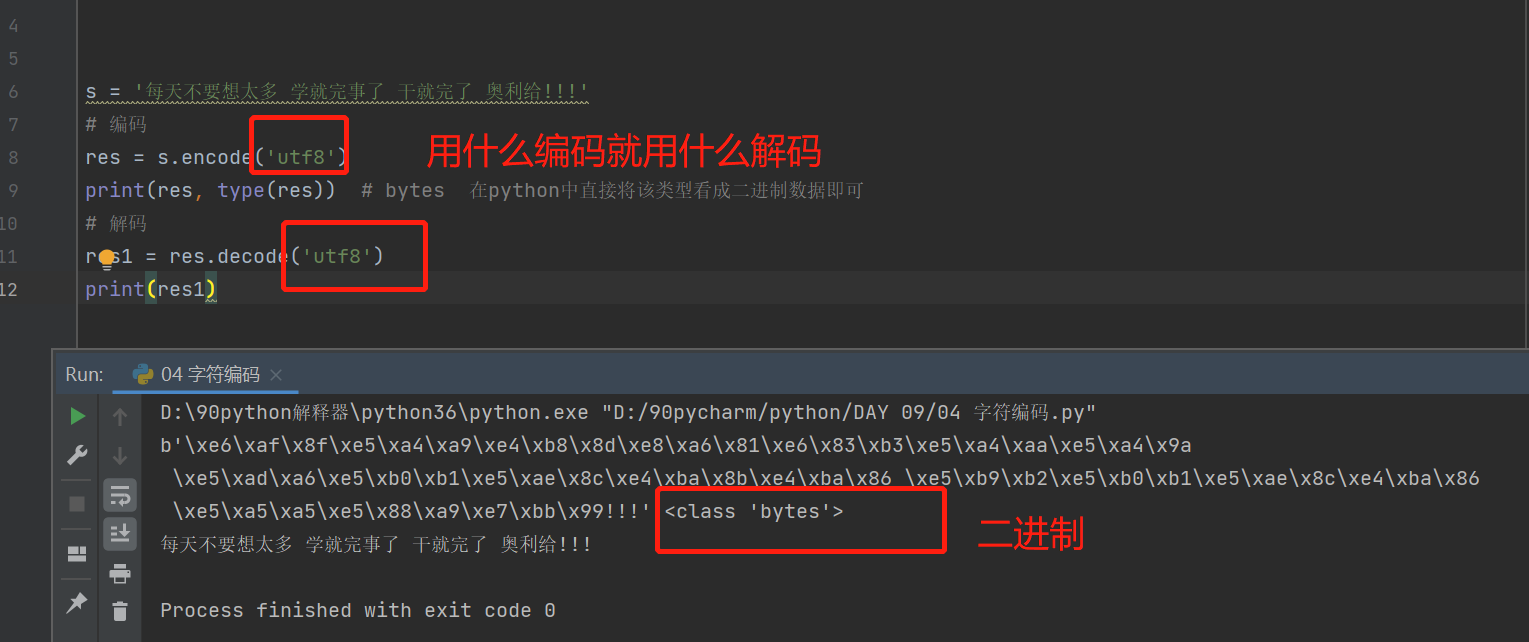
格式(with上下文管理(能够自动实现close())):
with open(r'文件路径',读写模式,字符编码) as f1:
print(f1.read())
res = open(r'D:\90pycharm\python\DAY 09\a.txt', 'r', encoding='utf8')
print(res.read())
res.close()
'''
格式:
open(r'文件路径',读写模式,字符编码)
文件路径和字符编码是必须的,读写模式是可以选的(有些模式需要编码)
格式变形:
with open(r'文件路径',读写模式,字符编码) as f1:
print(f1.read())
'''
with open(r'a.txt', 'r', encoding='utf8') as f1: # 这里的f1相当于f1=open(),f1=close()
print(f1.read())
七、文件读写模式
1.小知识点: 补全语法结构,没实际含义:
pass或者...
2.r:只读模式(只能看不能改)
with open(r'a.txt', 'r', encoding='utf8') as f:
print(f.read()) # 一次性读取文件内所有的内容
with open(r'a.txt', 'r', encoding='utf8') as f1:
print(f1.readline()) # 每次只读文件一行内容
with open(r'a.txt', 'r', encoding='utf8') as f2:
print(f2.readlines()) # 读取文件所有的内容 组织成列表 每个元素是文件的每行内容
with open(r'a.txt', 'r', encoding='utf8') as f3:
print(f3.readable()) # 判断当前文件是否具备读的能力
# r 模式:当路径存在
with open(r'a.txt', 'r', encoding='utf8') as f1:
print(f1.read()) # .read() 读取文件内所有的内容
print(f1.write()) # .write() 写文件内容
# r 模式:当路径不存在,直接报错
with open(r'c.txt', 'r', encoding='utf8') as f1:
pass
2.1 r模式优化
一次性读完之后,光标停留在了文件末尾,无法再次读取内容;在读取大文件的时候,可能会造成内存溢出的情况:用for循环优化解决
with open(r'a.txt', 'r', encoding='utf8') as f1:
for line in f1:
print(line)
3.w:只写模式(只能写不能看)
with open(r'a.txt', 'w', encoding='utf8') as f:
print(f.write('克服一切困难\n')) # 往文件内写入文本内容
with open(r'b.txt', 'w', encoding='utf8') as f1:
print(f1.write('123\n')) # 写入的内容必须是字符串类型
with open(r'c.txt', 'w', encoding='utf8') as f3:
print(f3.writelines(['jason', 'kevin', 'tony'])) # 可以将列表中多个字符串元素全部写入
with open(r'a.txt', 'w', encoding='utf8') as f:
print(f.writable()) # True
print(f.readable()) # False
f.flush() # 直接将内存内文件数据刷到硬盘 相当于ctrl+s
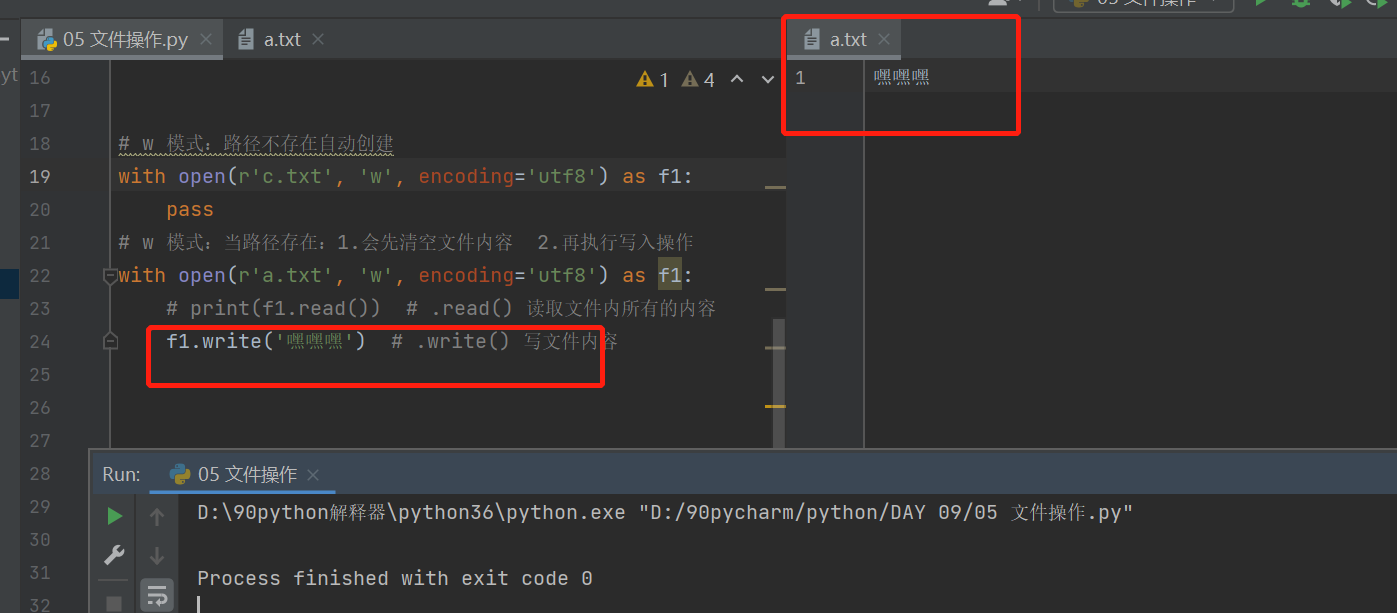
# w 模式:路径不存在自动创建
with open(r'c.txt', 'w', encoding='utf8') as f1:
pass
# w 模式:当路径存在:1.会先清空文件内容 2.再执行写入操作
with open(r'a.txt', 'w', encoding='utf8') as f1:
# print(f1.read()) # .read() 读取文件内所有的内容
f1.write('嘿嘿嘿') # .write() 写文件内容
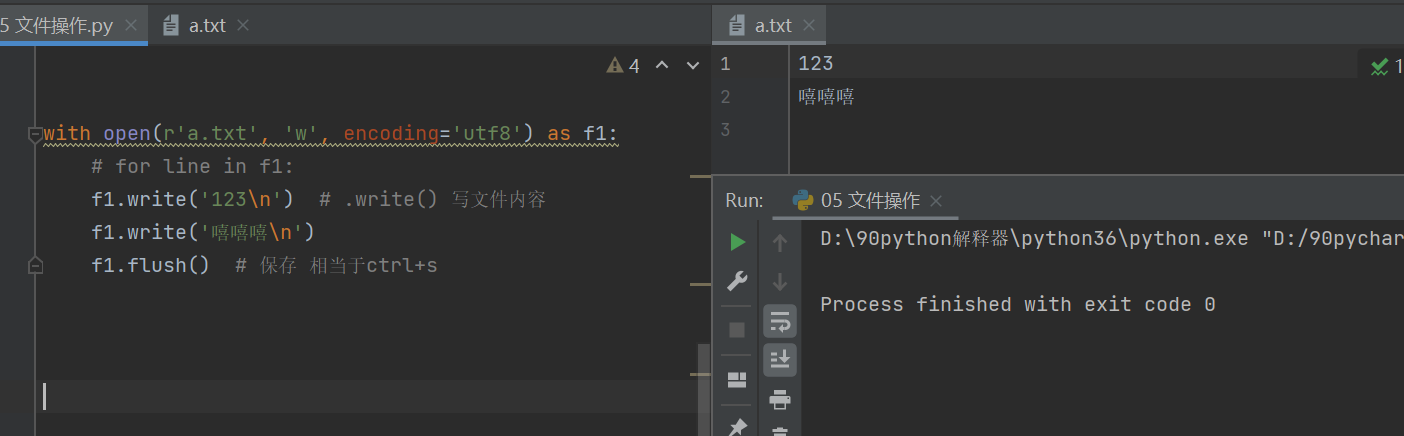
with open(r'a.txt', 'w', encoding='utf8') as f1:
# for line in f1:
f1.write('123\n') # .write() 写文件内容
f1.write('嘻嘻嘻\n')
f1.flush() # 直接将内存内文件数据刷到硬盘 相当于ctrl+s
4.a:只追加模式(追加内容)
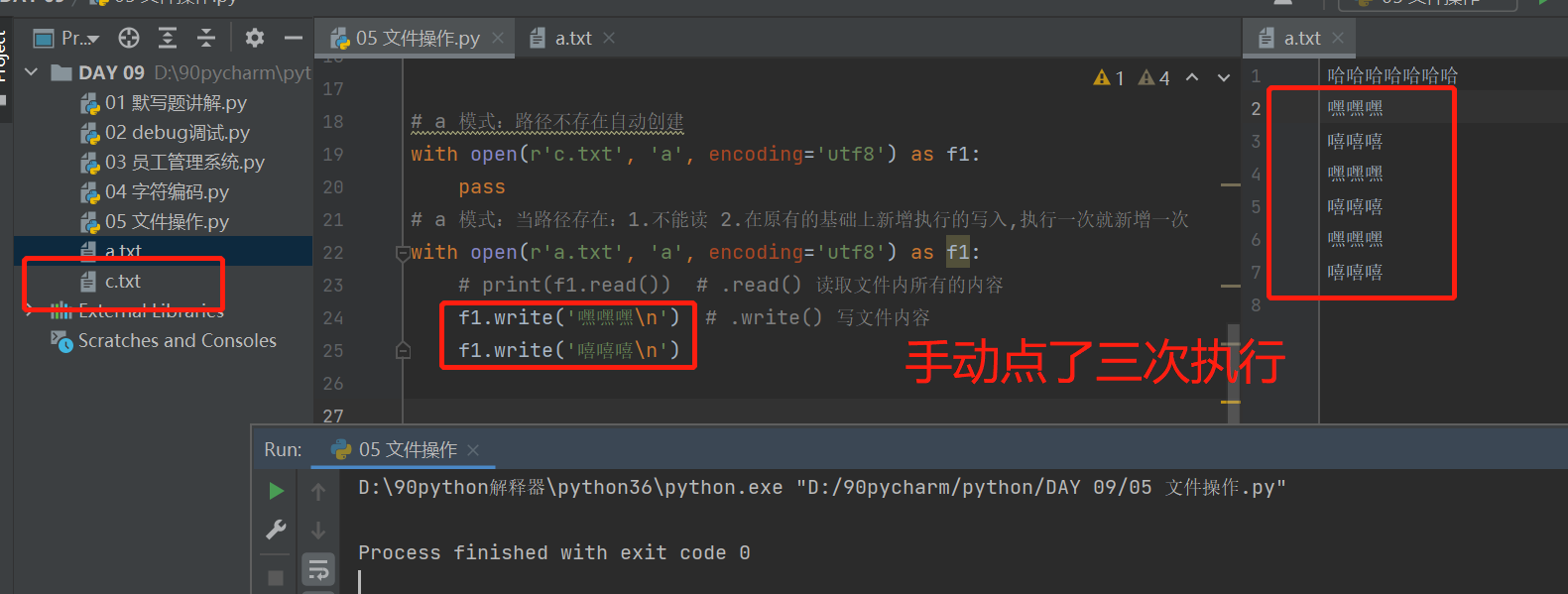
# a 模式:路径不存在自动创建
with open(r'c.txt', 'a', encoding='utf8') as f1:
pass
# a 模式:当路径存在:1.不能读 2.在原有的基础上新增执行的写入,执行一次就新增一次
with open(r'a.txt', 'a', encoding='utf8') as f1:
# print(f1.read()) # .read() 读取文件内所有的内容
f1.write('嘿嘿嘿\n') # .write() 写文件内容
f1.write('嘻嘻嘻\n')
5.小练习
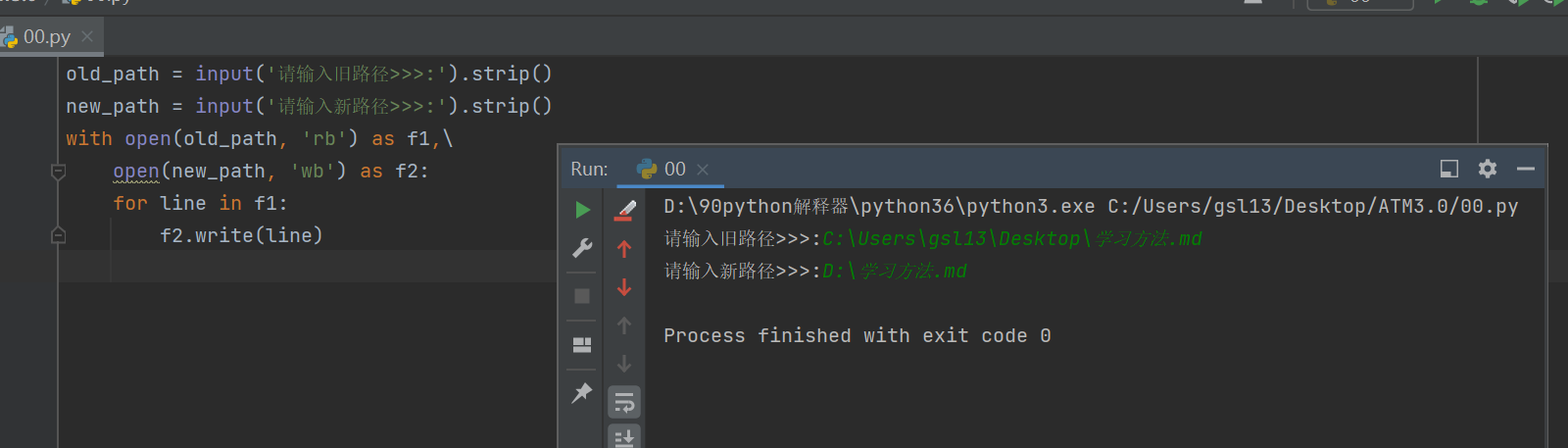
做一个简易版的拷贝功能:
1.获取待拷贝的目标文件路径
2.获取即将拷贝到哪个地方的新路径
3.利用文件操作实现数据拷贝
old_path = input('请输入旧路径>>>:').strip()
new_path = input('请输入新路径>>>:').strip()
with open(old_path, 'rb') as f1,\
open(new_path, 'wb') as f2:
for line in f1:
f2.write(line)
6.二进制模式读写操作
在二进制读模式下,read()括号内可以写数字,代表字节个数,数字和字母使用一个字节表示,中文用三个字节表示。
在一般读模式下,read()括号内可以写数字,代表字符个数。
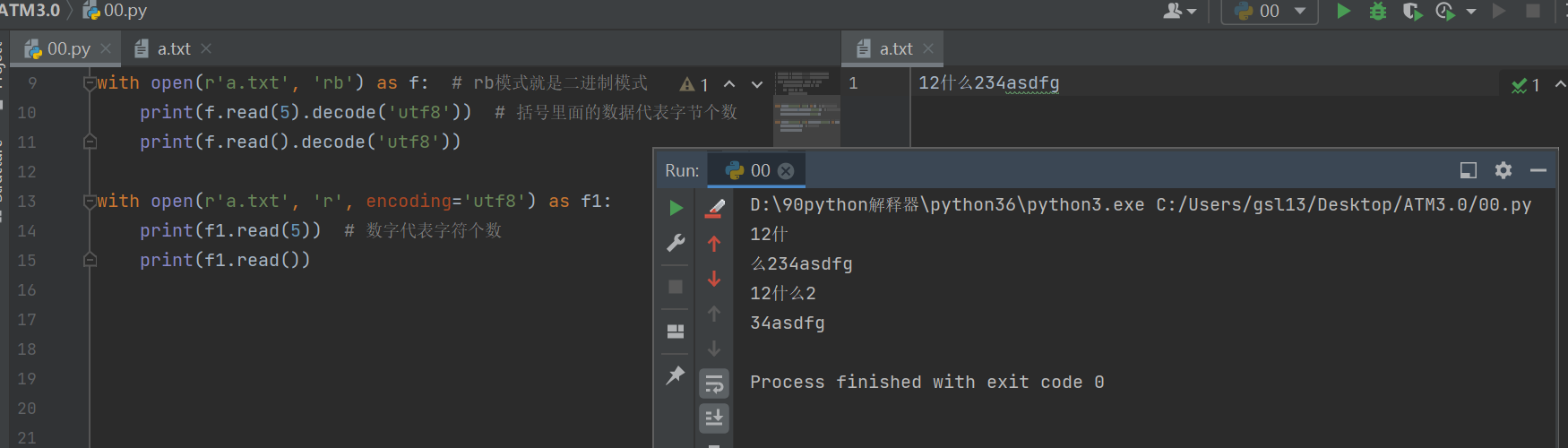
with open(r'a.txt', 'rb') as f: # rb模式就是二进制模式
print(f.read(5).decode('utf8')) # 括号里面的数据代表字节个数
print(f.read().decode('utf8'))
with open(r'a.txt', 'r', encoding='utf8') as f1:
print(f1.read(5)) # 数字代表字符个数
print(f1.read())
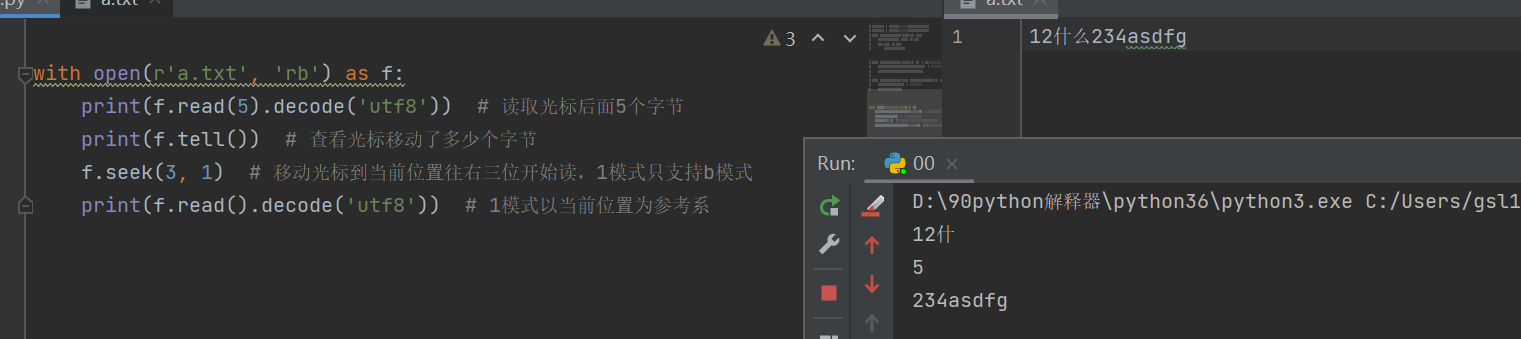
7.文件内光标的移动
f.seek(offset位移量,whence模式)
offset位移量正数即从左往右,负数即从右往左。
whence模式:0支持b,t模式,以文件开头为参考系;1支持b模式,以当前位置为参考系;2支持b模式,以文件末尾为参考系。
with open(r'a.txt', 'rb') as f:
print(f.read(5).decode('utf8')) # 读取光标后面5个字节
print(f.tell()) # 查看光标移动了多少个字节
f.seek(3, 1) # 移动光标到当前位置往右三位开始读,1模式只支持b模式
print(f.read().decode('utf8')) # 1模式以当前位置为参考系
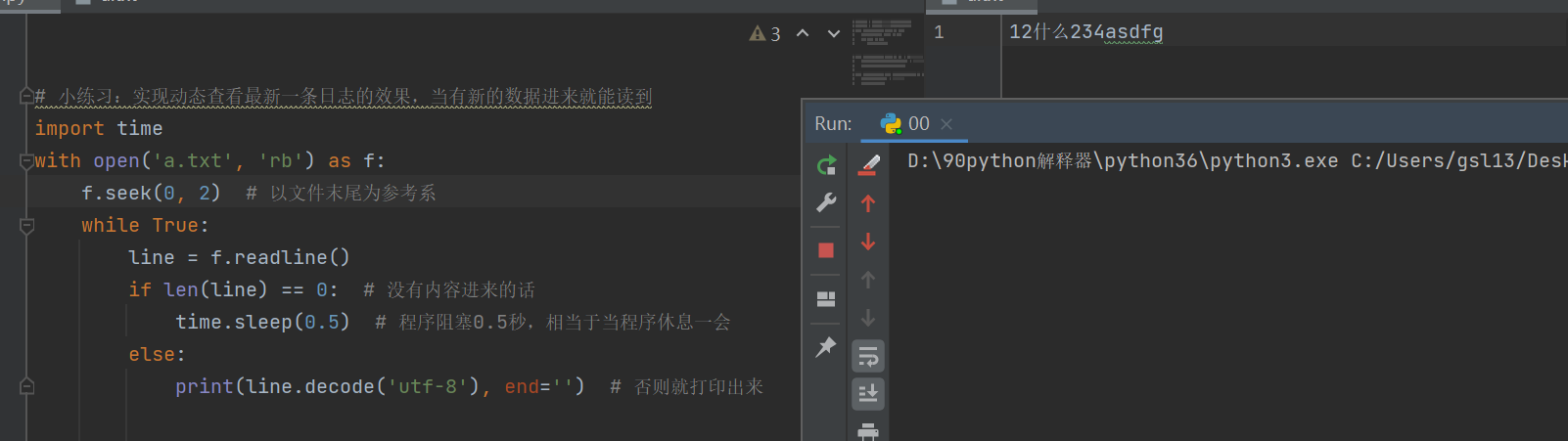
# 小练习:实现动态查看最新一条日志的效果,当有新的数据进来就能读到
import time
with open('a.txt', 'rb') as f:
f.seek(0, 2) # 以文件末尾为参考系
while True:
line = f.readline()
if len(line) == 0: # 没有内容进来的话
time.sleep(0.5) # 程序阻塞0.5秒,相当于当程序休息一会
else:
print(line.decode('utf-8'), end='') # 否则就打印出来
8.文件内容的修改
有两种修改方法:
1.覆盖修改:把数据全部读出来,修改完再存回去。
2.新建修改:新建一个文件,把文件内容一行行读出来修改后写入新文件,完成后删除旧文件,把新文件改名为旧文件的名字。
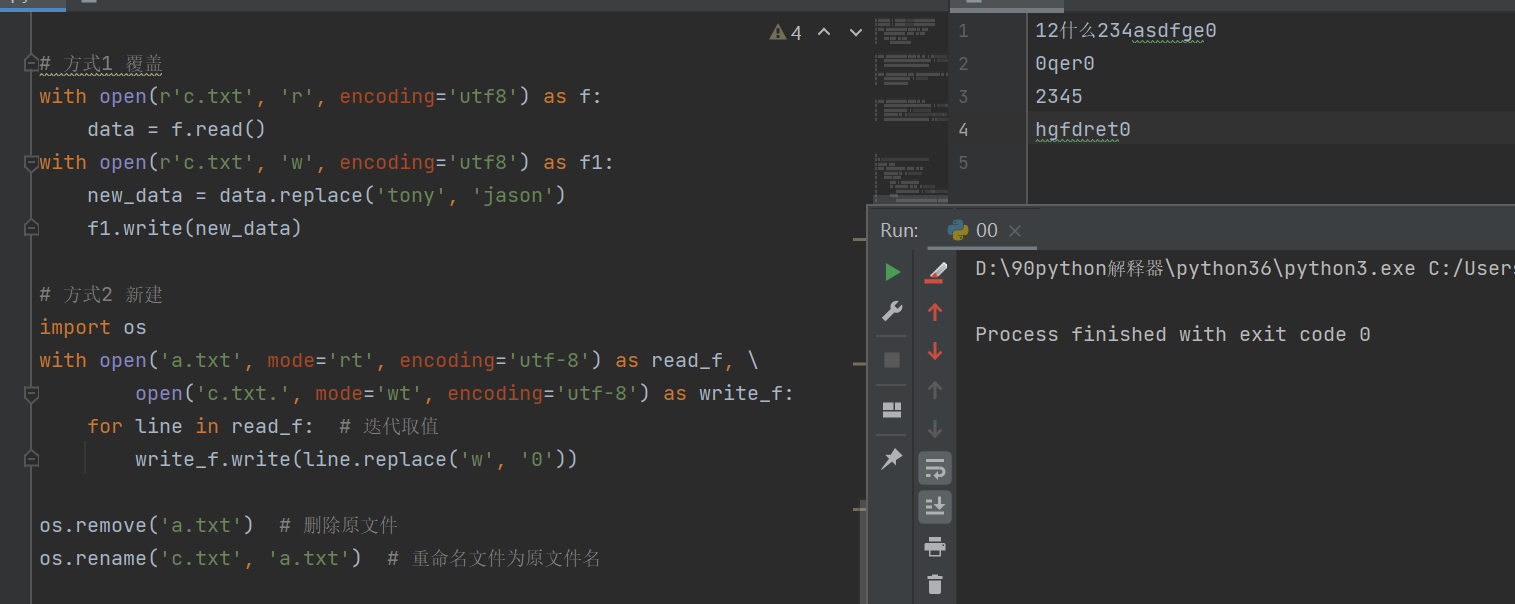
# 方式1 覆盖
with open(r'c.txt', 'r', encoding='utf8') as f:
data = f.read()
with open(r'c.txt', 'w', encoding='utf8') as f1:
new_data = data.replace('tony', 'jason')
f1.write(new_data)
# 方式2 新建
import os
with open('a.txt', mode='rt', encoding='utf-8') as read_f, \
open('c.txt.', mode='wt', encoding='utf-8') as write_f:
for line in read_f: # 迭代取值
write_f.write(line.replace('w', '0'))
os.remove('a.txt') # 删除原文件
os.rename('c.txt', 'a.txt') # 重命名文件为原文件名