从傻逼才做的大创开始的NLP学习
先实名辱骂一下保加利亚电信的毕业生,留个源码,源码里把自己训好的模型删了,洗好的文本删了,什么都给删了,白茫茫一片真他妈干净。
简单说说目前在做的这个东西,姑且算是个项目吧:
给出一个问句,通过实体识别找出问句中的实体,然后再通过问句与现有模板文具匹配抽取出实体关系,在此之后将找到的实体+关系带到知识图谱当中查找问句所对应的答案,图谱中没有就直接返回查找失败。
关于实体关系匹配:
查阅论文找到了依靠trransformer、bert、孪生网络+注意力机制等深度学习框架来进行文本匹配的做法,这些模型有一个共同点,在相似度计算上需要使用现有的问句集。
训练transformer的例子:

训练bert的例子:
https://github.com/WenRichard/DIAC2019-Adversarial-Attack-Share
“训练集根据在实际项目中的数据情况,以问题组的形式提供,每组问句又分为等价部分和不等价部分,等价问句之间互相组合可以生成正样本,等价问句和不等价问句之间互相组合可以生成负样本。我们提供 6000组问句 的训练集, 每组平均有三个等价问句和3个不等价问句 。验证集和测试集则以问句对的格式提供,其中验证集有5000条数据。测试集中除了人工标注的样本外,还会有大量adversarial example。”
由于林业法律文本这一块不存在现有的数据集也难以人工标记构造出此类数据集,查阅了相关的cnki的论文,目前情况下,在没有有效问句集可以进行深度学习的前提下最有效的还是杜何哲学长本身所用的word2vec,采用新闻语料库+自行追加的林法语料库进行训练。
翻查了一下这学长的资料:
翻代码找到这样的一行:
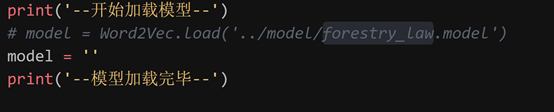
这人直接把之前已经训练完成的模型给删了,得从头来训。
微信已经联系过了,本人告知我换了电脑,东西全部删掉了。哈哈哈,(脏话)
现阶段任务:跑通word2vec,对其语料库加以训练。
另:与其匹配的模板问句库也被删掉了,得自行构造一个问句匹配库
目前阶段思路:
使用卷逼训好的BERT-BILSTM-CRF模型来对其进行实体识别,之后采用word2vec抽取关系,根据所得到的实体+关系,去知识图谱中搜索查找是否存在相应答案,若匹配则返回答案。
目前阶段要做的:
重新构造林法语料库,训练word2vec模型。
目前找到的语料库如下:
https://pan.baidu.com/s/1mh6IBag法律文书语料库(爬取自北大法宝)
http://www.sogou.com/labs/resource/ca.php新闻语料库
学长留下的的林业法律语料文本
下一阶段目标:
整合训练好的BERT-BILSTM-CRF模型+WORD2vec模型+知识图谱
未来计划:
调整知识图谱结构,将***学长所用的3.5版本的neo4j,迁移至目前的4.x版本上来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号