
MySQL之数据查询
外键
外键 ( foreign key ) 是用于建立和加强两个表数据之间的链接的一列或多列。通过将保存表中主键值的一列或多列添加到另一个表中,可创建两个表之间的链接。这个列就成为第二个表的外键。
建立外键的方式
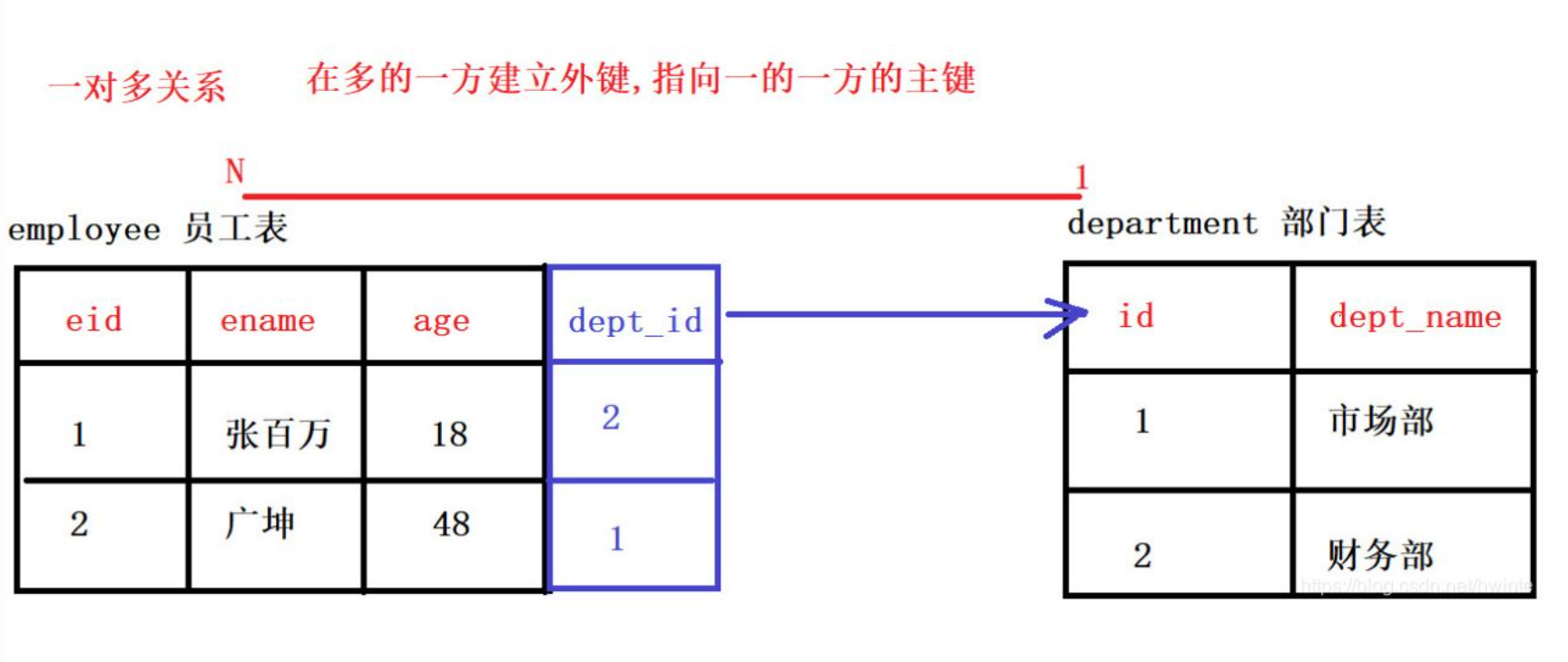
① 一对多形式(一个表的一个数据可以对应另一个表多个数据,另一张表的一个数据只能对应这张表的一个数据)
以员工部门表为例

# 先创建被关联表(一) create table dep( id int primary key auto_increment, dep_name varchar(32), dep_desc varchar(254) ); # 在创建关联表(多) create table emp( id int primary key auto_increment, name varchar(32), age int, dep_id int, foreign key(dep_id) references dep(id) );
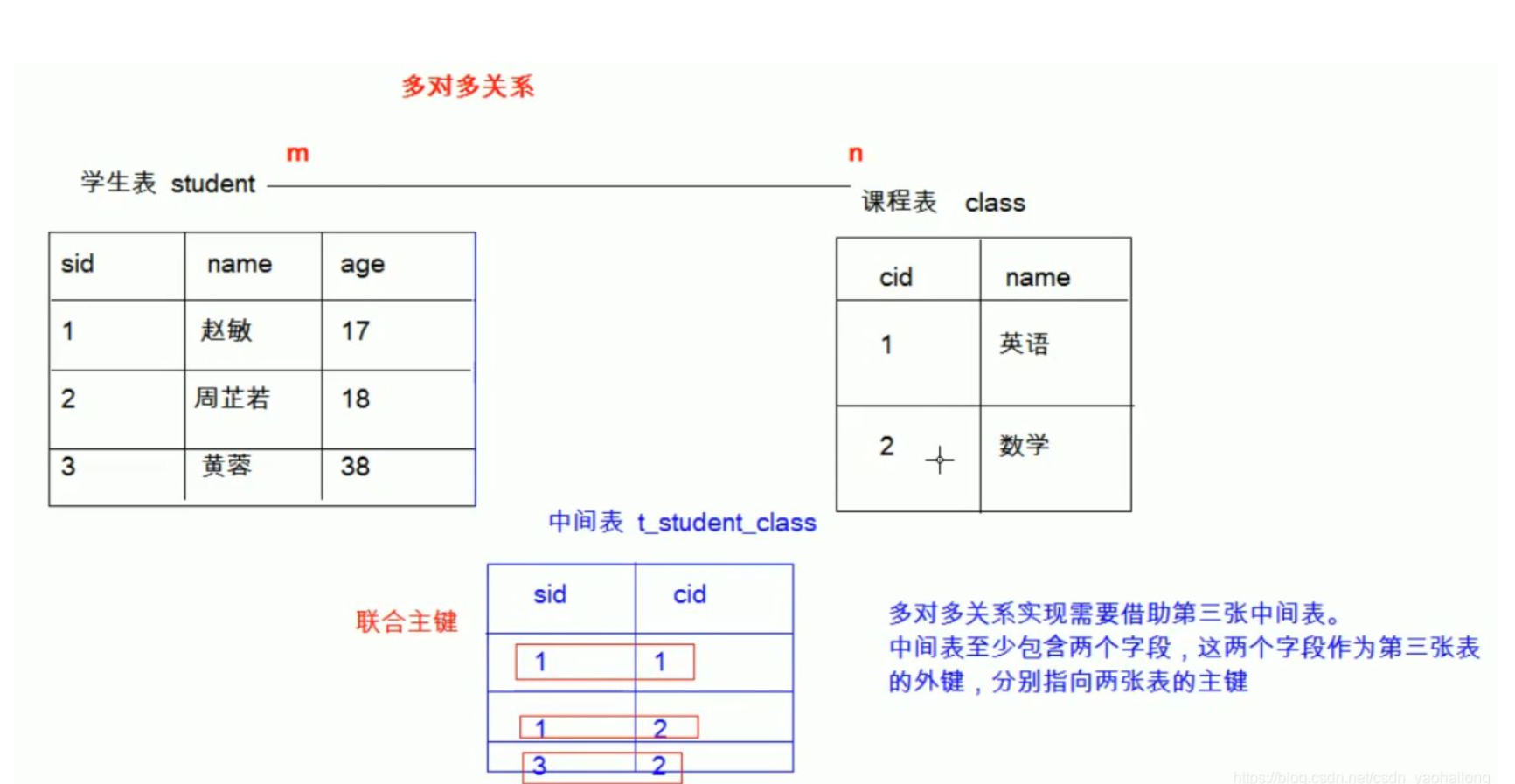
② 多对多形式(一张表的一个数据数据可以对应另一个表多个数据,另一张表的一个数据也能对应这张表的多个数据)
以学生和课程为例
create table student( id int primary key auto_increment, stu_name varchar(32), price float(6,2) ); create table class( id int primary key auto_increment, cls_name varchar(32), ); create table stu2class( id int primary key auto_increment, stu_id int, class_id int, foreign key(author_id) references author(id) on update cascade # 级联更新 on delete cascade, # 级联删除 foreign key(book_id) references book(id) on update cascade # 级联更新 on delete cascade # 级联删除 );
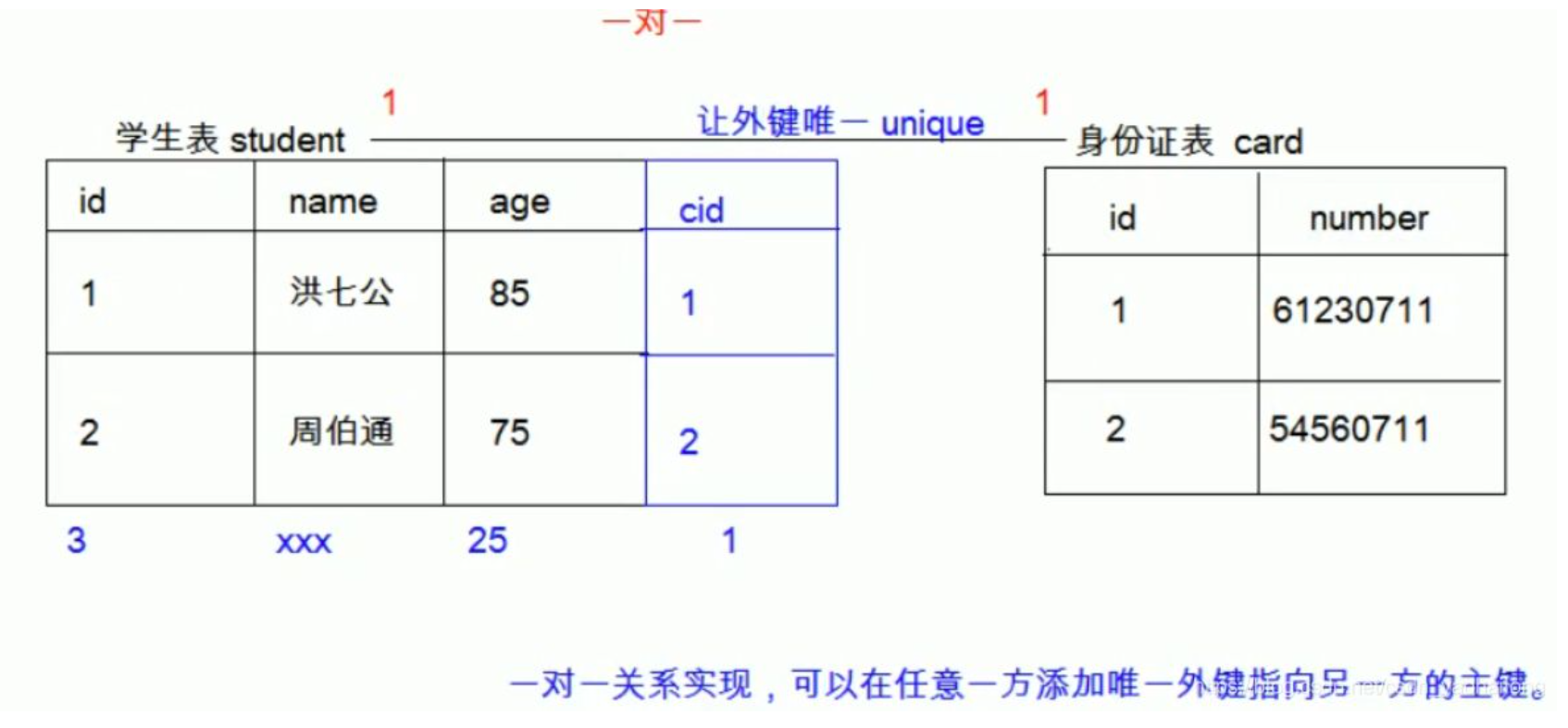
③ 一对一形式(一张表中一个数据只对应另一张表的一个数据,另一张表的数据也只对应该表的一个数据)
在一对一形式中,在哪个表中设置外键都可以,一般情况下我们将外键设置在常用的那个表中
create table student( id int primary key auto_increment, name varchar(32), age int, author_id int unique, foreign key(author_id) references author_detail(id) on update cascade # 级联更新 on delete cascade # 级联删除 ); create table id_card( id int primary key auto_increment, number varchar(32) );
外键约束
- 在创建表时,必须先创建被关联表(没有外键字段的表)
- 在插入新数据时,被关联表中必须有数据
- 在插入新数据时,只能插入被关联表中已存在的诗句
- 在修改和删除被关联表中的数据时,无法直接操作
方式① :将想修改的被关联数据关联的数据删除或者转移。
方式② :给外键增加约束条件
on update cascade # 级联更新
on delete cascade # 级联删除
查询关键字
select与from
# from控制的是查询的是哪一张表 # select控制的是查询哪个字段 select * from t1 # 查询t1表中的所有字段
where与like
""" where 控制的是筛选条件 like :模糊查询:没有明确的筛选条件 关键符号: %:匹配任意个数任意字符 _:匹配单个个数任意字符 show variables like '%mode%se'; """
练习
# 数据准备 create table emp( id int primary key auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); #插入记录 #三个部门:教学,销售,运营 insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('jason','male',18,'20170301','张江第一帅形象代言',7300.33,401,1), #以下是教学部 ('tom','male',78,'20150302','teacher',1000000.31,401,1), ('kevin','male',81,'20130305','teacher',8300,401,1), ('tony','male',73,'20140701','teacher',3500,401,1), ('owen','male',28,'20121101','teacher',2100,401,1), ('jack','female',18,'20110211','teacher',9000,401,1), ('jenny','male',18,'19000301','teacher',30000,401,1), ('sank','male',48,'20101111','teacher',10000,401,1), ('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('呵呵','female',38,'20101101','sale',2000.35,402,2), ('西西','female',18,'20110312','sale',1000.37,402,2), ('乐乐','female',18,'20160513','sale',3000.29,402,2), ('拉拉','female',28,'20170127','sale',4000.33,402,2), ('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3);
# 1.查询id大于等于3小于等于6的数据 select id,name from emp where id >= 3 and id <= 6; select * from emp where id between 3 and 6; # 2.查询薪资是20000或者18000或者17000的数据 select * from emp where salary = 20000 or salary = 18000 or salary = 17000; select * from emp where salary in (20000,18000,17000); # 简写 # 3.查询员工姓名中包含o字母的员工姓名和薪资 # 在你刚开始接触mysql查询的时候,建议你按照查询的优先级顺序拼写出你的sql语句 """ 先是查哪张表 from emp 再是根据什么条件去查 where name like ‘%o%’ 再是对查询出来的数据筛选展示部分 select name,salary """ select name,salary from emp where name like '%o%'; # 4.查询员工姓名是由四个字符组成的员工姓名与其薪资 select name,salary from emp where name like '____'; select name,salary from emp where char_length(name) = 4; # 5.查询id小于3或者大于6的数据 select * from emp where id not between 3 and 6; # 6.查询薪资不在20000,18000,17000范围的数据 select * from emp where salary not in (20000,18000,17000); # 7.查询岗位描述为空的员工名与岗位名 针对null不能用等号,只能用is select name,post from emp where post_comment = NULL; # 查询为空! select name,post from emp where post_comment is NULL; select name,post from emp where post_comment is not NULL;
group by(分组)
按照某个指定的条件将单个单个的个体分为一个整体,并且分组之后默认只能获取分组的数据,其他的数据都不能获取
针对MySQL5.6版本分组后会获取每个组的第一个数据,我们需要手动设置严格模式set global sql_mode = 'only_full_group_by'
设置sql_mode为only_full_group_by,意味着以后但凡分组,只能取到分组的依据,
不应该在去取组里面的单个元素的值,那样的话分组就没有意义了,因为不分组就是对单个元素信息的随意获取
聚合函数
聚合函数主要就是配合分组一起使用的
max(最大值)
min(最小值)
sum(和)
count(次数)
avg(平均十)
group_concat (数据拼接,用于获取分组后组内的其他数据)
# group_concat 分组之后使用 如果真的需要获取分组意外的数据字段 可以使用group_concat() # 每个部门的员工姓名 select post,group_concat(name) from emp group by post; select post,group_concat(name,'|',sex) from emp group by post; # concat 不分组使用 select concat(name,sex) from emp; select concat(name,'|',sex) from emp;
练习
# 每个部门的最高工资 select post,max(salary) from emp group by post; 补充:在显示的时候还可以给字段取别名 select post as '部门',max(salary) as '最高工资' from emp group by post; as也可以省略 但是不推荐省 因为寓意不明确 # 每个部门的最低工资 select post,min(salary) from emp group by post; # 每个部门的平均工资 select post,avg(salary) from emp group by post; # 每个部门的工资总和 select post,sum(salary) from emp group by post; # 每个部门的人数 select post,count(id) from emp group by post; 统计的时候只要是非空字段 效果都是一致的 这里显示age,salary,id最后演示特殊情况post_comment
having(过滤)
having和where都是筛选数据的,where是筛选分组前的数据,having是筛选分组后的数据
# 查询每个部门年龄大于三十岁的且部门平均薪资大于10000的部门 select post,avg(salary) from emp where age>30 group by post having avg(salary)>10000;
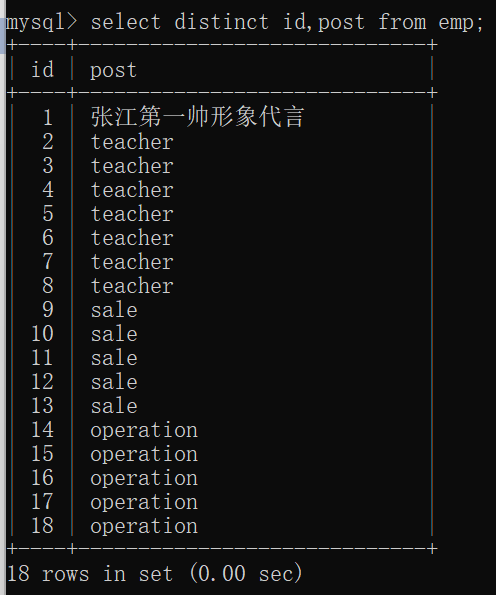
distinct(去重)
distinct用来给重复的数据进行去重操作,如果数据里没有重复的数据则没有效果。
select distinct id,post from emp; # 没有去重的效果 mysql> select distinct post from emp; # 去重成功
order by(排序)
order by是用来给表中的数据进行排序的,不写的话默认是升序asc,想要降序排列则使用desc。
select * from emp order by id asc; # 以id进行升序排序 select * from emp order by id ; # 以id进行升序排序 select * from emp order by id desc; # 以id进行降序排序 #先按照age降序排,在年轻相同的情况下再按照薪资升序排 select * from emp order by age desc,salary asc; # 统计各部门年龄在10岁以上的员工平均工资,并且保留平均工资大于1000的部门,然后对平均工资进行排序 select post,avg(salary) from emp where age>10 group by post having avg(salary)>1000 order by avg(salary) desc;
limit(分页)
limit是用来限制展示数据的条数的
# 限制展示条数 select * from emp limit 3; # 查询工资最高的人的详细信息 select * from emp order by salary desc limit 1; # 分页显示 select * from emp limit 0,5; # 第一个参数表示起始位置,第二个参数表示的是条数,不是索引位置 select * from emp limit 5,5;
regexp(正则)
regexp是用来匹配正则的
select * from emp where name regexp '^j.*(n|y)$';
多表查询思路
# 数据准备 #建表 create table dep( id int primary key auto_increment, name varchar(20) ); create table emp( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into dep values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'), (205,'保洁') ; insert into emp(name,sex,age,dep_id) values ('jason','male',18,200), ('egon','female',48,201), ('kevin','male',18,201), ('nick','male',28,202), ('owen','male',18,203), ('jerry','female',18,204); # 1.查询jason所在的部门名称 涉及到SQL查询题目 一定要先明确到底需要几张表 1.先查询jason所在的部门编号 select dep_id from emp where name='jason'; 2.根据部门编号查询部门名称 select name from dep where id=(select dep_id from emp where name='jason'); """一条SQL语句的查询结果既可以看成是一张表也可以看成是查询条件""" """ 多表查询的思路 1.子查询 将SQL语句查询的结果括号括起来当做另外一条SQL语句的条件 大白话:就是我们日常生活中解决问题的方式>>>:分步操作 2.连表操作(重要) 先将需要使用到的表拼接成一张大表 之后基于单表查询完成 inner join 内连接 left join 左连接 right join 右连接 union 全连接 """ # 涉及到多表查询的时候 字段名称容易冲突 需要使用表名点字段的方式区分 # inner join:只拼接两张表中共有的部分 select * from emp inner join dep on emp.dep_id = dep.id; # left join:以左表为基准展示所有的内容 没有的NULL填充 select * from emp left join dep on emp.dep_id = dep.id; # right join:以右表为基准展示所有的内容 没有的NULL填充 select * from emp right join dep on emp.dep_id = dep.id; # union:左右表所有的数据都在 没有的NULL填充 select * from emp left join dep on emp.dep_id = dep.id union select * from emp right join dep on emp.dep_id = dep.id; """ 疑问:上述操作一次只能连接两张表 如何做到多张表? 将两张表的拼接结果当成一张表与跟另外一张表做拼接 依次往复 即可拼接多张表 """
多表查询练习题
建表语句 CREATE DATABASE test2 USE test2; DROP TABLE IF EXISTS class; CREATE TABLE class ( cid int(11) NOT NULL AUTO_INCREMENT, caption varchar(32) NOT NULL, PRIMARY KEY (cid) ) insert into class(cid,caption) values (1,‘三年二班’),(2,‘三年三班’),(3,‘一年二班’) ,(4,‘二年九班’); DROP TABLE IF EXISTS course; CREATE TABLE course ( cid int(11) NOT NULL AUTO_INCREMENT, cname varchar(32) NOT NULL, teacher_id int(11) NOT NULL, PRIMARY KEY (cid), KEY fk_course_teacher (teacher_id), CONSTRAINT fk_course_teacher FOREIGN KEY (teacher_id) REFERENCES teacher (tid) ) insert into course(cid,cname,teacher_id) values (1,‘生物’,1),(2,‘物理’,2),(3,‘体育’,3) ,(4,‘美术’,2); DROP TABLE IF EXISTS score; CREATE TABLE score ( sid int(11) NOT NULL AUTO_INCREMENT, student_id int(11) NOT NULL, course_id int(11) NOT NULL, num int(11) NOT NULL, PRIMARY KEY (sid), KEY fk_score_student (student_id), KEY fk_score_course (course_id), CONSTRAINT fk_score_course FOREIGN KEY (course_id) REFERENCES course (cid), CONSTRAINT fk_score_student FOREIGN KEY (student_id) REFERENCES student (sid) ) insert into score(sid,student_id,course_id,num) values (1,1,1,10),(2,1,2,9), (5,1,4,66),(6,2,1,8),(8,2,3,68),(9,2,4,99),(10,3,1,77),(11,3,2,66),(12,3,3,87),(13,3,4,99), (14,4,1,79),(15,4,2,11),(16,4,3,67),(17,4,4,100),(18,5,1,79),(19,5,2,11), (20,5,3,67),(21,5,4,100),(22,6,1,9),(23,6,2,100) ,(24,6,3,67),(25,6,4,100),(26,7,1,9),(27,7,2,100),(28,7,3,67) ,(29,7,4,88),(30,8,1,9),(31,8,2,100),(32,8,3,67), (33,8,4,88),(34,9,1,91),(35,9,2,88),(36,9,3,67),(37,9,4,22) ,(38,10,1,90),(39,10,2,77),(40,10,3,43),(41,10,4,87) ,(42,11,1,90),(43,11,2,77),(44,11,3,43),(45,11,4,87), (46,12,1,90),(47,12,2,77),(48,12,3,43),(49,12,4,87),(52,13,3,87); DROP TABLE IF EXISTS student; CREATE TABLE student ( sid int(11) NOT NULL AUTO_INCREMENT, gender char(1) NOT NULL, class_id int(11) NOT NULL, sname varchar(32) NOT NULL, PRIMARY KEY (sid), KEY fk_class (class_id), CONSTRAINT fk_class FOREIGN KEY (class_id) REFERENCES class (cid) ) insert into student(sid,gender,class_id,sname) values (1,‘男’,1,‘理解’), (2,‘女’,1,‘钢蛋’),(3,‘男’,1,‘张三’),(4,‘男’,1,‘张一’),(5,‘女’,1,‘张二’),(6,‘男’,1,‘张四’ ),(7,‘女’,2,‘铁锤’), (8,‘男’,2,‘李三’),(9,‘男’,2,‘李一’),(10,‘女’,2,‘李二’),(11,‘男’,2,‘李四’) ,(12,‘女’,3,‘如花’),(13,‘男’,3,‘刘三’),(14,‘男’,3,‘刘一’),(15,‘女’,3,‘刘二’),(16,‘男’,3,‘刘四’); DROP TABLE IF EXISTS teacher; CREATE TABLE teacher ( tid int(11) NOT NULL AUTO_INCREMENT, tname varchar(32) NOT NULL, PRIMARY KEY (tid) )


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现