hadoop集群安装_实战
spark1.6.2+ hadoop2.6.2
词频统计完整案例:http://blog.csdn.net/zythy/article/details/17852579
hadoop学习:http://www.cnblogs.com/admln/category/618480.html
hadoop提交作业:http://weixiaolu.iteye.com/blog/1402919
所以,如果要永久修改RedHat的hostname,就修改/etc/sysconfig/network文件,将里面的HOSTNAME这一行修改成HOSTNAME=NEWNAME,其中NEWNAME就是你要设置的hostname。
1.机器准备:
关闭防火墙:
service iptables stop
service iptables status
10.112.29.177 vm-10-112-29-177 namenode
10.112.29.172 vm-10-112-29-172 datanode
10.112.29.174 vm-10-112-29-174 datanode
2.无密码登录:
生成master公钥:
- cd ~/.ssh (进入用户目录下的隐藏文件.ssh)
- ssh-keygen -t rsa (用rsa生成密钥)
- cp id_rsa.pub authorized_keys (把公钥复制一份,并改名为authorized_keys,这步执行完,应该ssh localhost可以无密码登录本机了,可能第一次要密码)
- scp authorized_key root@vm-10-112-29-172:~/.ssh (把重命名后的公钥通过ssh提供的远程复制文件复制到从机vm-10-112-29-172上面)
- chmod 600 authorized_keys (更改公钥的权限,也需要在从机vm-10-112-29-172中执行同样代码)
- ssh vm-10-112-29-172 (可以远程无密码登录vm-10-112-29-172这台机子了,注意是ssh不是sudo ssh。第一次需要密码,以后不再需要密码)
方法2:
cat id_rsa.pub >> authorized_keys
scp root@master:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
cat~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys

3.安装目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
4.
修改/usr/bigdata/hadoop-2.7.1/etc/hadoop下的配置文件
修改core-site.xml,加上
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm-10-112-29-177:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
5.修改hdfs-site.xml,加上
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm-10-112-29-177:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
6.修改mapred-site.xml,加上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>vm-10-112-29-177:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>vm-10-112-29-177:19888</value>
</property>
7.修改yarn-site.xml,加上
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>vm-10-112-29-177:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>vm-10-112-29-177:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>vm-10-112-29-177:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>vm-10-112-29-177:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>vm-10-112-29-177:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
注意:2048,2 设置过小,nodemanager启动失败 或者log中显示无法分配必要的资源 提交作业有可能一直 accpeted状态
8.
配置/user/bigdata/hadoop-2.7.1/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,否则启动时会报error
export JAVA_HOME=/usr/java/jdk1.7.0_80
9.
配置/user/bigdata/hadoop-2.7.1/etc/hadoop目录下slaves
加上你的从服务器,
vm-10-112-29-172
vm-10-112-29-174
配置成功后,将hadhoop复制到各个从服务器上
scp -r /user/bigdata/hadoop-2.7.1 root@vm-10-112-29-172:/user/bigdata/
scp -r /user/bigdata/hadoop-2.7.1 root@vm-10-112-29-174:/user/bigdata/
scp /usr/bigdata/hadoop-2.6.2/etc/hadoop/yarn-site.xml root@vm-10-112-29-174:/usr/bigdata/hadoop-2.6.2/etc/hadoop
10.
主服务器上执行bin/hdfs namenode -format
进行初始化
sbin目录下执行 ./start-all.sh
可以使用jps查看信息
停止的话,输入命令,sbin/stop-all.sh
11.
这时可以浏览器打开10.112.29.177:8088查看集群信息啦
到此配置就成功啦,开始你的大数据旅程吧。。。
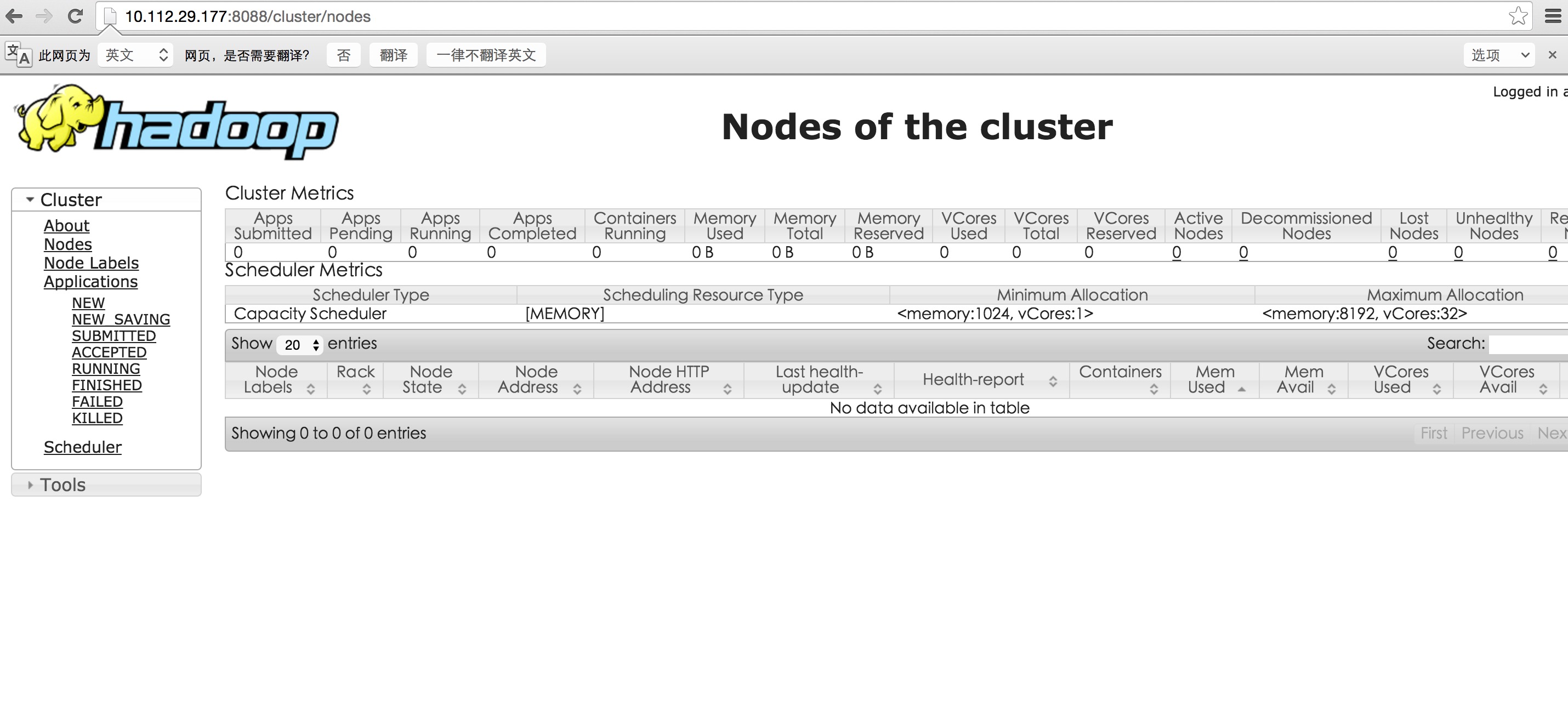
解决nodemanager 启动问题以后:

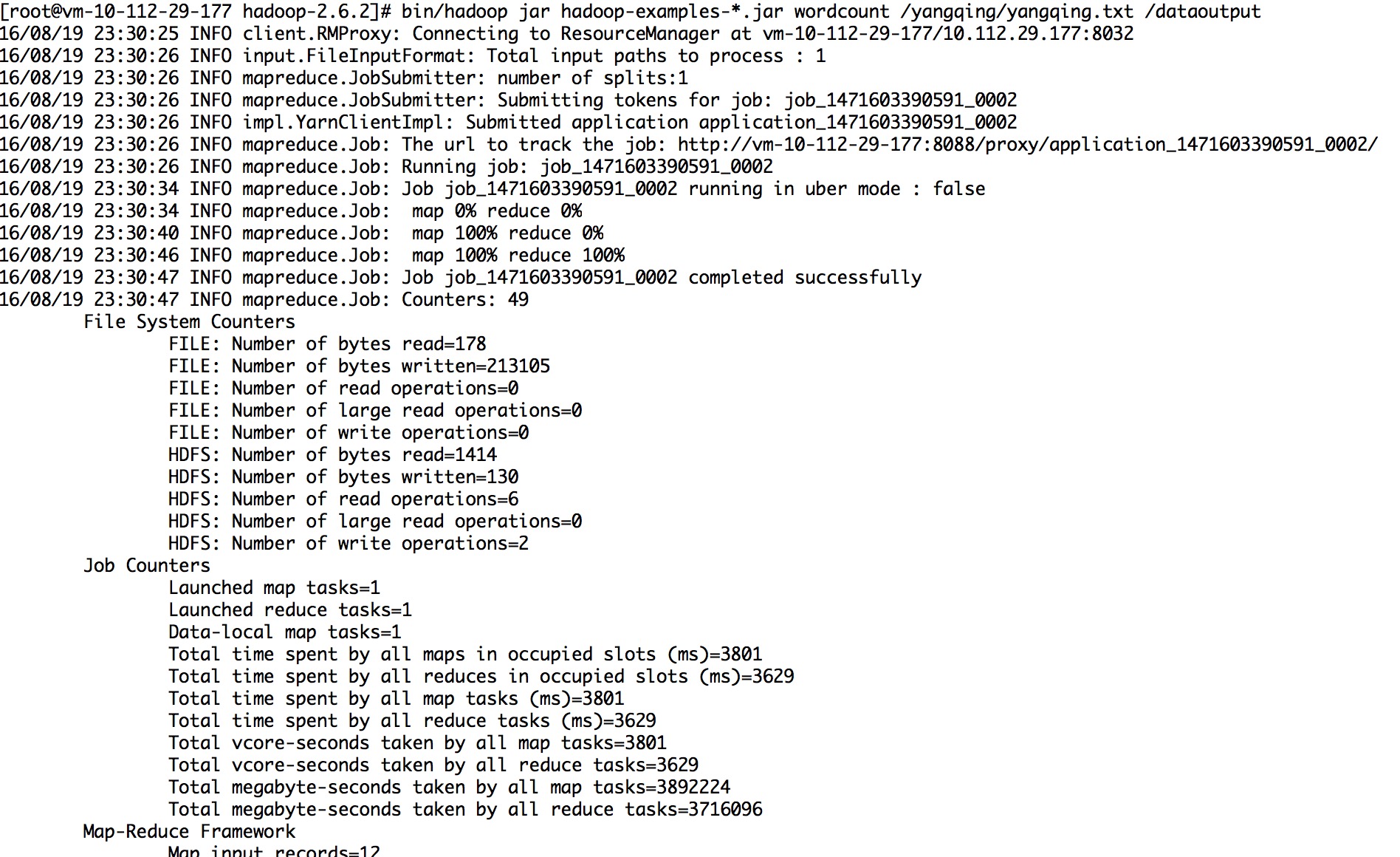
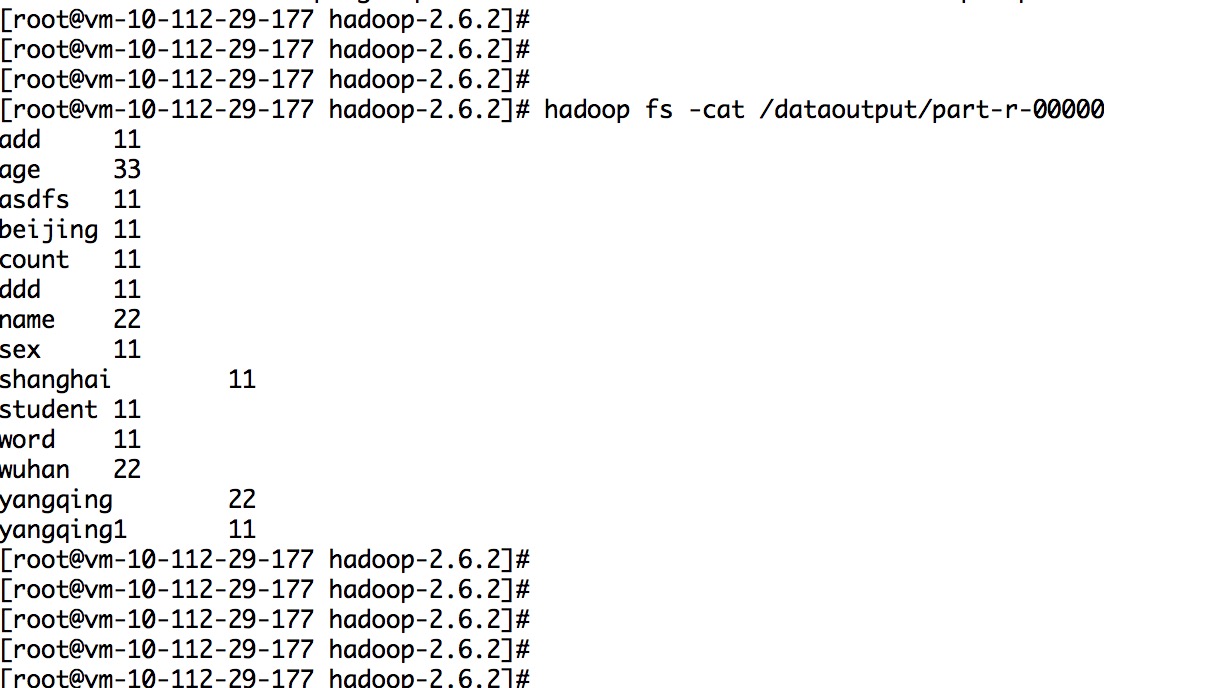
10.实例代码:
http://blog.csdn.net/ylchou/article/details/9264899
sh bin/hadoop fs -mkdir /tttt bin/hadoop fs -put /root/test/tttt.txt /tttt
scp -r /usr/bigdata/hadoop-2.6.2 root@vm-10-112-29-174:/usr/bigdata/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号