

简单的神经网络练习
一、第一部分代码
- 部分代码
import torch
x = torch.tensor(666)
print(x)
x = torch.zeros(3,3,dtype=torch.int)
print(x)
y = x.new_ones(4,4)
print(x)
print(y)
z = torch.randn_like(x,dtype=torch.float)
print(z)
a = torch.tensor([[1,2,3]])
b = torch.tensor([[4,5,6]])
print(torch.cat((a,b),0))
print(torch.cat((a,b),1))
- 截图:
二、第二部分代码
- 部分代码
# 未加 Relu 激活函数 部分代码
learning_rate = 1e-3
lambda_12 = 1e-5
model = nn.Sequential(nn.Linear(D,H),nn.Linear(H,C))
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,\
weight_decay = lambda_12)
for t in range(1000):
y_pred = model(x)
loss = criterion(y_pred,y)
score, predicted = torch.max(y_pred,1)
acc = (y == predicted).sum().float()/len(y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait = True)
optimizer.zero_grad()
loss.backward()
optimizer.step()
-
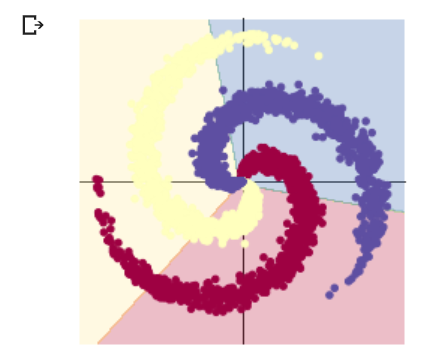
运行截图
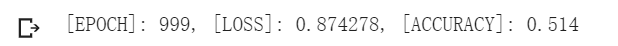
# 添加 Relu 激活函数
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
-
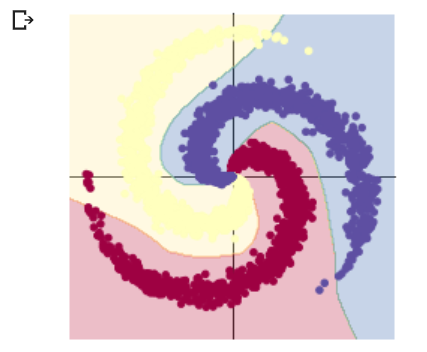
运行截图
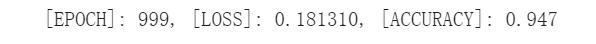
三、想法解读
分享Typora将本地图片上传的方法
两个实验只在两层神经网络之间相差一个激活函数,而得到的预测结果相差很大,可以得知激活函数对于神经网络来说有巨大的意义。为什么会有这样的差距?通过视频学习和CSDN查询的资料,我了解到了一些。
吴恩达深度学习:为什么使用非线性激活的证明?

如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。当两个线性函数的组合本身就是线性函数,所以除非你引入非线性,否则你无法计算更复杂的函数,即使网络层数再多也不行。
问题:如何设计为神经网络设计或者调试一个有效的深度和每一层大概需要多少个神经元。
