谈谈过度设计:因噎废食的陷阱

引言
写软件和造楼房一样需要设计,但是和建筑行业严谨客观的设计规范不同,软件设计常常很主观,且容易引发争论。
设计模式被认为是软件设计的“规范”,但是在互联网快速发展的过程中,也暴露了一些问题。相比过程式代码的简单与易于修改,设计模式常常导致代码复杂,增加理解与修改的成本,我们称之为 “过度设计”。因而很多人认为,设计模式只是一种炫技,对系统没有实质作用,甚至有很大的挖坑风险。这个观点容易让人因噎废食,放弃日常编码中的设计。
本文将深入探索如下问题:
-
为什么长期来看,设计模式相比过程式代码是更好的?
-
什么情况下设计模式是有益的,而什么情况下会成为累赘?
-
如何利用设计模式的益处,防止其腐化?
设计模式的缺陷
“过度设计” 这个词也不是空穴来风,首先,互联网软件的迭代比传统软件快很多,传统软件,比如银行系统,可能一年只有两个迭代,而网站的后台可能每周都在发布更新,所以互联网非常注重软件修改的便捷性。其次,设计模式的 “分模块”,“开闭原则” 等主张,天然地易于拓展而不利于修改,和互联网软件频繁迭代产生了一定的冲突。
开闭原则的缺陷
开闭原则:软件中对象应该对扩展开放,对修改关闭。
基于开闭原则,诞生了很多中台系统。应用通过插件的方式,可以在满足自身定制业务需求的同时,复用中台的能力。
当业务需求满足中台的主体流程和规范时,一切看上去都很顺利。一旦需求发生变更,不再符合中台的规范了,往往需要中台进行伤筋动骨的改造,之前看到一篇文章吐嘈 “本来业务上一周就能搞定的需求,提给中台需要8个月”。
所以基于中台无法进行深度的创新,深度创新在软件上必然也会有深度的修改,而中台所满足的开闭原则是不利于修改的。
最小知识原则的缺陷
最小知识原则:一个对象对于其他对象的了解越少越好。
最小知识原则又称为 “迪米特法则”,基于迪米特法则,我们会把软件设计成一个个 “模块”,然后对每个 “模块” 只传递需要的参数。
在过程式编码中,代码片段是拥有上下文的全部信息的,比如下面的薪资计算代码:
// 绩效 int performance = 4; // 职级 int level = 2; String job = "engineer"; switch (job) { case "engineer": // 虽然计算薪资时只使用了 绩效 作为参数, 但是从上下文中都是很容易获取的 return 100 + 200 * performance; case "pm": // .... 其余代码省略 }
而如果我们将代码改造成策略模式,为了满足迪米特法则,我们只传递需要的参数:
// 绩效 int performance = 4; // 职级 int level = 2; String job = "engineer"; // 只传递了需要 performance 参数 Context context = new Context(); context.setPerformance(performance); strategyMap.get(job).eval(context);
需求一旦变成 “根据绩效和职级计算薪资”,过程式代码只需要直接取用上下文的参数,而策略模式中需要分三步,首先在 Context 中增加该参数,然后在策略入口处设置参数,最后才能在业务代码中使用增加的参数。
这个例子尚且比较简单,互联网的快速迭代会让现实情况更加复杂化,比如多个串联在一起模块,每个模块都需要增加参数,修改成本成倍增加。
可理解性的缺陷
设计模式一般都会应用比较高级的语言特性:
-
策略模式在内的几乎所有设计模式都使用了多态
-
访问者模式需要理解动态分派和静态分派
-
...
这些大大增加了设计模式代码的理解成本。而过程式编码只需要会基本语法就可以写了,不需要理解这么多高级特性。
小结
这三点缺陷造成了设计模式和互联网快速迭代之间的冲突,这也是应用设计模式时难以避免的成本。
过程式编码相比设计模式,虽然有着简单,易于修改的优点,但是却有永远无法回避的本质缺陷。
过程式编码的本质缺陷
上文中分析,过程式编码的优点就是 “简单,好理解,易于修改”。这些有点乍看之下挺对的,但是仔细想想都很值得怀疑:
-
“简单”:业务逻辑不会因为过程式编码而变得更加简单,相反,越是大型的代码库越会大量使用设计模式(比如拥有 2400w 行代码的 Chromium);
-
“好理解”:过程式编码只是短期比较好理解,因为没有设计模式的学习成本,但是长期来看,因为它没有固定的模式,理解成本是更高的;
-
“易于修改”:这一点我相信是对的,但是设计模式同样也可以是易于修改的,下一节将会进行论述,本节主要论述前两点。
软件复杂度
软件工程著作 《人月神话》 中认为软件复杂度包括本质复杂度和偶然复杂度。
本质复杂度是指业务本身的复杂度,而偶然复杂度一般是因为方法不对或者技术原因引入的复杂度,比如拆分服务导致的分布式事务问题,就是偶然复杂度。
如果一段业务逻辑本来就很复杂,即本质复杂度很高,相关模块的代码必然是复杂难以理解的,无论是采用设计模式还是过程式编码。“用过程式编码就会更简单” 的想法在这种情况下显然是荒谬的,相反,根据经验,很多一直在采用过程式编码的复杂模块,最后都会变得逻辑混乱,缺乏测试用例,想重构时已经积重难返。
那么设计模式会增加偶然复杂度吗?阅读有设计模式的代码,除了要理解业务外,还要理解设计模式,看起来是增加了偶然复杂度,但是下文中我们会讨论,从长期的角度来看,这不完全正确。
理解单一问题 vs 理解一类问题
开头提到,设计模式是软件设计的“规范”,和建筑业的设计规范类似,规范能够帮助不同背景的人们理解工程师的设计,比如,当工人们看到三角形的结构时,就知道这是建筑师设计的支撑框架。
过程式代码一般都是针对当前问题的某个特殊解决方法,不包含任何的 “模式”,虽然表面上减少了 “模式”的学习成本,但是每个维护者/调用者都要去理解一遍这段代码的特殊写法,特殊调用方式,无形中反而增加了成本。
以数据结构的遍历为例,如果全部采用过程式编码,比如二叉树打印的代码是:
public void printTree(TreeNode root) { if (root != null) { System.out.println(root.getVal()); preOrderTraverse1(root.getLeft()); preOrderTraverse1(root.getRight); } }
图的节点计数代码是:
public int countNode(GraphNode root) { int sum = 0; Queue<Node> queue = new LinkedList<>(); queue.offer(root); root.setMarked(true); while(!queue.isEmpty()){ Node o = queue.poll(); sum++; List<Node> list = g.getAdj(o); for (Node n : list) { if (!n.isMarked()) { queue.add(n); n.setMarked(true); } } } return sum; }
这些代码本质上都是在做数据结构的遍历,但是每次读到这样的代码片段时,你都要将它读到底才发现它其实就是一个遍历逻辑。幸好这里的业务逻辑还比较简单,就是一个打印或者计数,在实际工作中往往和更复杂的业务逻辑耦合在一起,更难发现其中的遍历逻辑。
而如果我们使用迭代器模式,二叉树的打印代码就变成:
public void printTree(TreeNode root) { Iterator<TreeNode> iterator = root.iterator(); while (iterator.hasNext()) { TreeNode node = iterator.next(); System.out.println(node); } }
图的节点计数代码变成:
public int countNode(GraphNode root) { int sum = 0; Iterator<TreeNode> iterator = root.iterator(); while (iterator.hasNext()) { iterator.next(); sum++; } return sum; }
这两段代码虽然有区别,但是它们满足一样的 ”模式“,即 “迭代器模式”,看到 Iterator 我们就知道是在进行遍历,甚至都不需要关心不同数据结构具体实现上的区别,这是所有遍历统一的解决方案。虽然在第一次阅读这个模式的代码时需要付出点成本学习 Iterator,但是之后类似代码的理解成本却会大幅度降低。
设计模式中类似上面的例子还有很多:
-
看到 XxxObserver,XxxSubject 就知道这个模块是用的是观察者模式,其功能大概率是通过注册观察者实现的
-
看到 XxxStrategy 策略模式,就知道这个模块会按照某种规则将业务路由到不同的策略
-
看到 XxxVisitor 访问者模式 就知道这个模块解决的是嵌套结构访问的问题
-
...
是面对具体问题 case by case 的学习,还是掌握一个通用原理理解一类问题?肯定是学习后者更有效率。
“过程式代码更加好理解”往往只是针对某个代码片段的,当我们将范围扩大到一个模块,甚至整个系统时,其中会包含大量的代码片段,如果这些代码片段全部是无模式的过程代码,理解成本会成倍增加,相似的模式则能大大降低理解成本,越大的代码库从中的收益也就越大。
新人学习过程式编码和设计模式的学习曲线如下图:
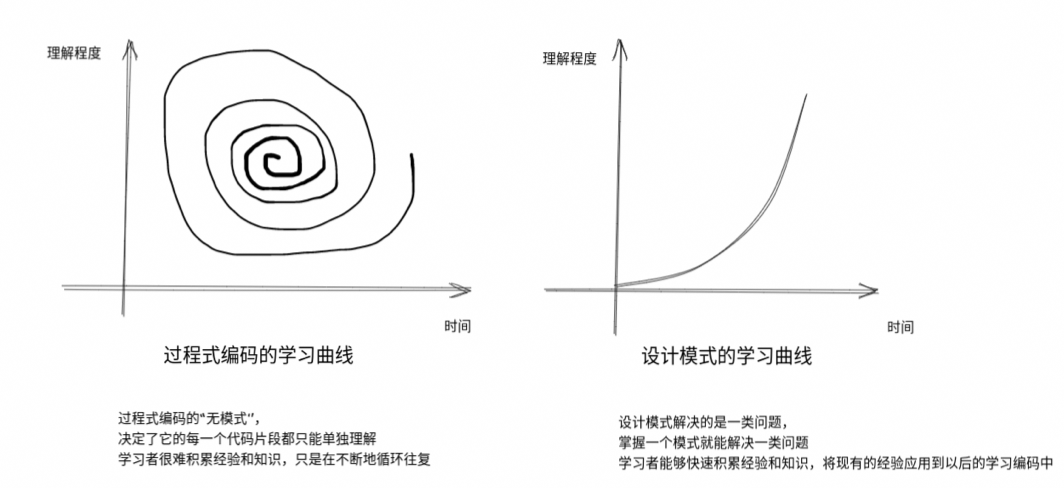
过程式编码虽然刚开始时没有任何学习压力,但是不会有任何积累。设计模式虽然刚开始时很难懂,但是随着学习和应用,理解会越来越深刻。
设计模式防腐
前文中提到,互联网软件非常注重修改的便捷性,而这是过程式编码的长处,设计模式天然是不利于修改的。但是过程式编码又有着很多致命的问题,不宜大规模使用。我们如何才能在发挥设计模式长处的同时,扬长补短,跟上业务的快速演进呢?
腐败的设计模式
有一条恶龙,每年要求村庄献祭一个少女,每年这个村庄都会有一个少年英雄去与恶龙搏斗,但无人生还。
又一个英雄出发时,有人悄悄尾随,龙穴铺满金银财宝,英雄用剑刺死恶龙。然后英雄坐在尸身上,看着闪烁的珠宝,慢慢地长出鳞片、尾巴和触角,最终变成恶龙。
以上是缅甸著名的 “屠龙少年变成恶龙” 的传说。见过很多系统,最初引入设计模式是为了提高可维护性,当时或许实现了这个目标,但是随着时间推移,变成了系统中没人敢修改,“不可维护” 的部分,最终成为一个 “过度设计”,主要原因有以下两点:
-
无法调试: 新的维护者无法通过调试快速学习模块中的 “模式”,或者说因为学习成本太高,人们常在没有弄清楚“模式”的情况下就着手改代码,越改越离谱,最终覆水难收
-
没有演进: 系统中的设计模式也是要跟随业务不断演进的。但是现实中很多系统发展了好几年,只在刚开始创建的时候进行过一次设计,后来因为时间紧或者懒惰等其他原因,再也没有人改过模式,最终自然跟不上业务,变成系统中的累赘。
可调试的模块
“模块” 是软件调试的基本单位,一个模块中可能会应用多种 “设计模式” 来辅助设计。设计模式相比过程式编码,逻辑不是线性的,无法通过逐行阅读来确认逻辑,调试就是后来人学习理解设计的重要途径。在理解的基础上,后人才能进行正确的模式演进。
“模块” 在软件工程中的概念比较含糊:
-
模块可以是一个独立的系统。由多个微服务构成的一个系统,每个微服务可以认为是一个 “模块”;
-
在同一个应用中和一个功能相关的对象集合也可以认为是一个模块。
随着微服务概念的兴起,很多人误认为只有将代码拆成单独的系统,才能叫 “模块”,其实不然,我们应该先在同一个应用中将模块拆分开来,然后再演化成另一个单独的应用,如果一上来就强行拆的话,只会得到两个像量子纠缠一样耦合在一起的应用。
关于软件调试。有的人倾向于每做一点修改就从应用的入口处(点击图形界面或者调用 http 接口)进行测试,对他来说应用内部的分模块就是一种负担,因为一旦测试不通过,他需要理解模块之间复杂的交互,然后确认传入被修改模块的参数是什么。对他来说,肯定是全部使用过程式编码更好理解一些,然后抱怨系统 ”过度设计“,虽然可能设计并没有过度。
有经验的工程师在修改完代码后,会先测试被修改模块的正确性,没有问题后,应用入口处的测试只是走个流程,大多可以一遍通过。但是如果一个模块没有办法独立调试的话,那么它所有人来说都是一个累赘。
对于独立系统的模块,它的接口应该在脱离整个应用后也明确的含义的,接口参数也应该尽量简单且容易构造。
对于同一应用中的代码模块,它还应该具备完善的单元测试,维护者通过单元测试就可以理解模块的特性和限制,通过本地 debug 就可以理解模块的整体设计。
John Ousterhout 教授(Raft 的发明者)的著作 《软件设计哲学》中提到深模块的概念,给我们设计模块提供了非常好的指导。
深模块是指接口简单,但是实现复杂的模块,就像我们的电脑,它看上去只是一块简单的板,却隐藏了内部复杂的功能实现。John 认为设计良好的模块都应该是深的,设计良好的应用应该由深模块组成。
从软件调试的角度来说,接口简单意味着它易于调试和理解,实现复杂意味着它能够帮助我们屏蔽掉很多的业务复杂性,分模块的代价是值得的。
上面的论述可能比较偏向于思想认知层面,关于是实践层面可以参考我的另一篇文章 代码重构:面向单元测试。
可调试的模块能够让我们修改设计模式的心理压力大大降低,因为有任何问题我们都可以很快发现。有了这个基础,我们才能跟着业务去演进我们的模式。
模式演进
互联网应用更新迭代频繁,因为设计模式不易于修改,外加模块不好调试,很多团队就懒得对模式进行演进,而是各种绕过的 “黑科技”。很多应用都已经发展了好几年,用的还是系统刚创建时的模式,怎么可能还跟得上业务发展,于是就变成了人们眼中的 “过度设计”。
设计模式也是需要跟着业务演进的。当对未来的业务进行规划,也要同时对系统模式进行思考,系统的模式是否还能跟上未来业务的规划?在迭代中不断探索最符合业务的设计模式。
Java8 引入的很多新特性可以帮助我们降低业务频繁演进时,模式的迁移成本。当我们对是否要应用某个模式犹豫不绝的时候,可以考虑使用 函数式设计模式,以策略模式为例,在面向对象中,策略模式必须采用如下编码:
interface Strategy { void doSomething(); } class AStrategy implements Strategy { //... 代码省略 } class BStrategy implements Strategy { //... 代码省略 } 及 // 业务代码 class AService { private Map<String, Strategy> strategyMap; public void doSomething(String strategy) { strategyMap.get(strategy).doSomething(); } }
我们新建了好多类,一旦日后反悔,迁移的成本非常高。而使用函数式策略模式,我们可以将他们暂且全部写在一起:
class AService { private Map<String, Runnable> strategyMap; static { strategyMap.put("a", this::aStrategy); strategyMap.put("b", this::bStrategy); } public void doSomething(String strategy) { strategyMap.get(strategy).run(); } private void aStrategy() { //... } private void bStrategy() { //... } }
可以看到设计模式的函数式版本,相比面向对象版本,在隔离和封装上相对差些,但是便捷性好一些。
所以我们可以在业务不稳定的初期先使用函数式设计模式,利用它的便捷性快速演进,等到业务逐渐成熟,模式确定之后,再改成封装性更好的面向对象设计模式。
更多的函数式设计模式可以参考《Java8 实战》中的 函数式设计模式 相关章节。
小结
“设计模式” 作为对抗 “软件复杂度” 恶龙的少年,可能业务发展,缺乏演进等原因,最终自己腐坏成了新的 “恶龙”。
为了对抗设计模式的腐坏:
-
构造可调试的模块,保证后来的维护者能够通过调试快速理解设计。
-
在业务发展中不断探索最合适的模式。
开发效率与系统的成长性
在思考业务的同时,还要思考模式的演进,开发效率似乎变低了。但是这额外的时间并没有被浪费,在设计过程也是对业务的重新思考,进一步加深对业务的理解,编码和业务之间必然是存在巨大的鸿沟,设计模式能够帮助我们弥补这条鸿沟,演进出和业务更加贴合的模块,从而提升长期的效率。
复杂软件是需要长期成长演化的。JetBrains 花了十几年时间才让 Idea 形成优势,清扫免费 IDE 占据的市场; 米哈游也用了接近十年的时间才形成足够的技术优势,在市场上碾压了同时期的竞争对手。
而设计模式就是在帮助我们对业务进行合理的抽象,尽可能地复用,这样系统可以从每个模块地成长中收益,而不是像过程式编码,每次都重头开始,重复解决那些已经解决过的问题。
举一个我工作中的例子,钉钉审批的表单有着复杂的嵌套结构,它由控件和明细组成,而明细中又子控件(有的控件中还有子控件,甚至还有关联其他表单的控件,总之很复杂就对了),最初我们采用过程式编码,每当需要处理控件时,就手写一遍遍历:
// 统计 a 控件的总数 public int countComponentAB(Form form) { int sum = 0; for (Component c: form.getComponents()) { if (c.getType() == "A") { sum++; } else if (c.getType == "Table") { // 明细控件含有子控件 for (Component d: c.getChildren()) { if (d.getType() == "A") { sum++; } } } } return sum; }
// 返回表单中所有的 A 控件和 B 控件 public List<Component> getComponentAB(Form form) { List<Component> result = new ArrayList<>(); getComponentABInner(result, form.getItems()); return result; } private getComponentABInner(List<Component> result, List<Component> items) { for (Component c: items) { if (c.getType() == "A" || c.getType() == "B") { result.add(c); } else if (!c.getChildren().isEmtpy()) { // 递归访问子控件 getComponentABInner(result, c.getChildren()); } } }
这两段代码各自有点 “小 bug”:
-
第一段代码只展开了一层子控件,但是审批表单是支持多层子控件的
-
第二段代码虽然用递归支持了多层子控件,但是并不是所有的子控件都属于当前表单(前面提到过,审批支持关联其他比表单的控件)
两段代码风格都不一样,因此只能分别在上面修修补补,新同学来大概率还会犯相同的错误,此时,系统也就谈不上 “成长”。
但是 Visitor 模式可以帮助我们将嵌套结构的遍历逻辑统一抽象出来,使用 Visitor 模式重新编码后的两段代码看起来如下:
// 统计 a 控件的总数 class CountAVisitor extends Visitor { public int sum; @Override public void visitA(ComponentA a) { sum++; } } public int countComponentAB(Form form) { CountAVisitor aVisitor = new CountAVisitor(); // 遍历逻辑统一到了 accept 中 form.accept(aVisitor); return aVisitor.sum; }
// 返回表单中所有的 A 控件和 B 控件 class GetComponentABVisitor extends Visitor { public List<Component> result; @Override public void visitA(ComponentA a) { result.add(a); } @Override public void visitB(ComponentB b) { result.add(b); } } public List<Component> getComponentAB(Form form) { GetComponentABVisitor abVisitor = new GetComponentABVisitor(); form.accept(abVisitor); return abVisitor.result; }
关于 Visitor 模式的细节,可以参考我的另一篇文章 重新认识访问者模式。
对于使用者来说,虽然第一次看到这种写法时,需要花点时间学习模式,和理解其中的特性,但是一旦理解之后,不仅可以快速理解所有类似代码,还可以利用这个模块解决所有遍历问题,而且这个模块是经过验证,能够健壮地解决问题。
相比之下,过程式编码,尽管都是遍历逻辑,每一段风格都不一样,每一次都要重新理解,每一段都有不一样的特性和 bug,明明知道逻辑就在那里,但是却无法复用,每一任维护者只能继续踩前人踩过的坑,重复地解决问题。对于系统的长期成长是不利的。
幸福的家庭都是类似的,不幸的家庭各有各的不幸。
因噎废食的陷阱
软件工程师的成长
在工程师成长的路上,有很多坎坷,“不要过度设计” 就是其中无比甜蜜的陷阱,因为它给我们偷懒一个很好的理由,让我们可以安然地停在五十步,反而去嘲笑已经跑了一百步的人。
如果有两位工程师,前者因为过度设计而犯错; 后者则是不进行设计,安于系统现状,认为 “代码无错就是优”[引用5]。
我认为前者更有成长性,因为他至少是有代码和技术上的追求的,只要有正确的指导,迟早会成为一名优秀的工程师。
最怕的是团队没有人指导,任由其自由发展,或者批评阻碍其发展。这正是 CR 以及评审机制的意义。
互联网精耕细作的新时代
设计模式能够帮助我们大幅度提升复杂软件的开发与维护效率,也本文围绕的主要命题。
但是人们总是能找出反例,“很多公司工程做得很糟糕,业务也十分成功”。
之前看红学会的直播,对抗软件复杂度的战争,也有人问了晓斌类似的问题,晓斌的回答是 “如果你有一片田,种啥长啥,那么你不需要耕作,只要撒种子就可以了”。
在互联网野蛮发展时期,大量的人才和热钱涌入,软件快速上线比一切都重要,开发效率的问题,只要招聘更多的人就能解决,哪怕在一个公司开发好几套功能一样的系统。
但是随着互联网人口红利的消失,不再有充足的资源去承接业务,我们就不得不做好精耕细作的准备,扎实地累积自己的产品和技术优势,继续创造下一个十年的辉煌。
本文的边界情况
真理是有条件的。
本文并非走极端地认为所有代码都应该应用模式。至少在以下情况下,是不适合用模式的:
-
一次性脚本,没有多次阅读和修改的可能。我自己在写工具类脚本时也不会去应用模式,但是我相信阿里巴巴的应用代码,100% 都是要被反复阅读和修改的。
-
真的很简单的模块。前文提到过 ”模块应该是深“,如果这个模块真的很简单,它或许抽象不足,我们应该将它和其他模块整合一下,变得更加丰满。如果应用中抽不出复杂模块,那可能不是事实,只是我们的实现方式太简单了(比如全是过程式编码),反过来又对外宣称 ”我们的业务很复杂“。
-
团队内都是喜欢攀比代码设计的疯子,需要告诫警醒一下。真的有团队达到这个程度了吗?如果到了这个程度,才可以 “反对设计”。
参考:
[1]《人月神话》
[2]《软件设计哲学》
[3]《Java 8 实战》
[4]《设计模式 - 可复用的面向对象软件元素》
[5]《大话设计模式》
[6] 代码重构:面向单元测试
[7] 重新认识访问者模式
[8] 对抗软件复杂度的战争
作 者 | 杜沁园(悬衡)
本文来自博客园,作者:古道轻风,转载请注明原文链接:https://www.cnblogs.com/88223100/p/Talk-about-over-design-the-trap-of-giving-up-eating-for-choking.html

