如何设计一个海量任务调度系统

背景
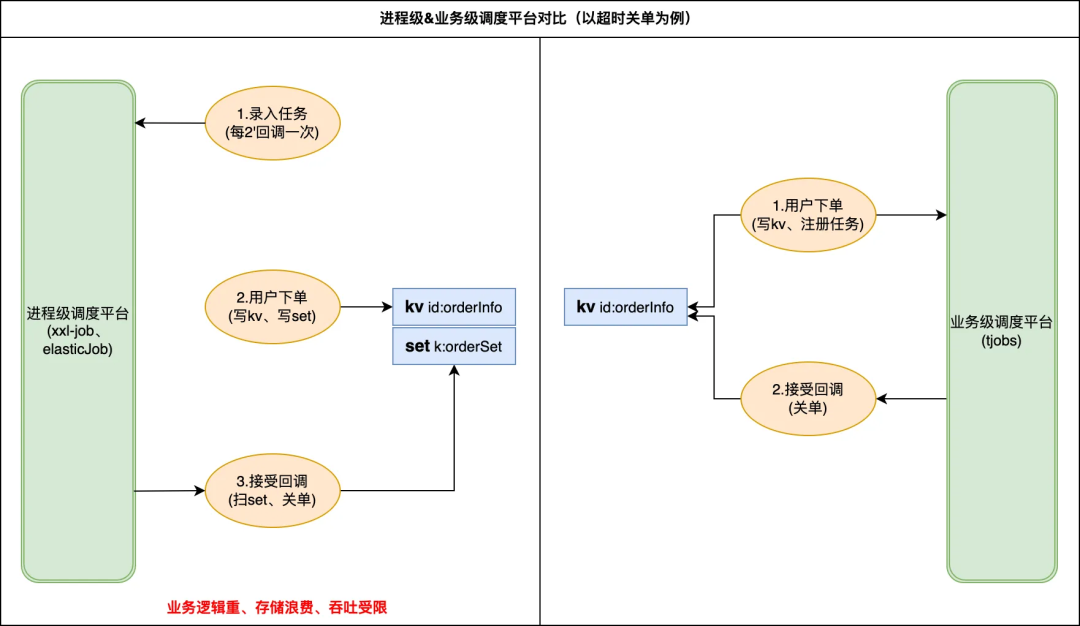
在日常开发中会经常遇到一些需要异步定时执行的业务诉求,典型的使用场景如:超时未支付订单关单、每隔 2h 更新好友排行榜、3.22 日 17 点《xx》剧上线等。目前业务侧多基于以下思路来快速搭建一个调度系统,mysql 或者 redis 队列存储待执行任务,通过 crontab 定时触发应用完成“捞取、计算、执行等操作”。不难看出存在几类亟待解决问题:
1)缺少统一的调度平台导致各业务重复开发;
2)简易版调度实现在任务吞吐、调度时效上缺少保障;
3)业务和调度数据强耦合存储给线上稳定性引入大 key、慢 sql 风险。
目前存在多类开源解决方案如 XXL-Job 、 Elastic-Job、quartz 调度等,但这些都属于进程级调度平台,很难满足更细粒度的业务调用。基于上述的业务诉求和司内现状,我们准备搭建一套通用的分布式任务调度平台(以下统称为 tjobs 平台)以满足业务高可靠、低延迟的海量任务调度诉求。
整体设计
设计目标
旨在提供一个易用、可靠、高性能、低时延的海量任务管理、调度平台,帮助开发工程师专注于面向业务编码设计,而不再担心定时任务的吞吐量、可靠性等非功能需求。由此衍生的功能和非功能诉求分别为:
功能性诉求:
任务管理:包括任务注册、任务启停、任务更新等,
任务查询:主要用于任务追踪、问题排查、调度统计等,
任务回调:由业务提供 spi 回调实现,tjobs 平台定时调用触发
非功能性诉求
tjobs 定位为高可靠、高性能、低延迟、简单易用的任务调度平台,在满足核心功能的基础上提供以下非功能性保障:
平台化:支持多业务接入、百亿级任务注册
易用性:自助化接入、运维,使用成本远低自建
高可靠:全年 3 个 9 可用性、p99(时延)<1s
高性能:支持 100w+TPM 的任务触发
多协议:支持多协议、组播、单播多种回调方式
综合看需要 tjobs 设计支持百亿级任务量和百万 TPM 并发执行,并在此基础上满足三个 SLA:
-
注册\触发可用性>99.95%
-
任务触达率>99.99%
-
p99(触达延时)<1s
设计思路
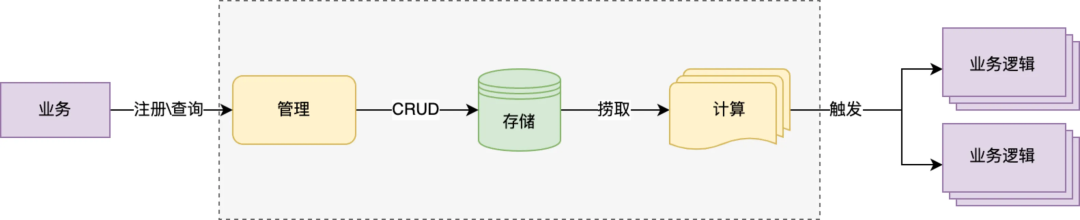
如上图所示描述了对任务注册、触发流程的抽象,不难看出 tjobs 平台为达成上述任务量级和三个 SLA,需要在海量数据存储、高并发、触发时效以及高可用上做出相应的设计保障,下面分别讲述一下:
数据存储:重点解决两个问题数据可靠和海量存储,可靠的存储保障任务不丢、任务高触达率,鉴于 mysql 在持久化以及 master-slave 部署架构对高可用支持表现,优先选用 mysql 作为底层存储;但单 DB 在 TPS 性能、数据量上存在瓶颈,这里选用分库分表策略,通过增加数据库实例打平数据分布以提升整体性能和存储上限;
实时性:类似多级缓存的思路,为保障任务触发时效(p99<1s)这里的设计思路“任务前置”,拆解任务触发步骤,将任务捞取、计算工作尽量提前完成,通过毫秒级延迟的内存时间轮最终触发,保障任务的触发时效性;
高并发:采用可伸缩架构设计,存储层尽量拆分为多个逻辑库,前期通过合并部署降低成本但保留多个逻辑库隔离能力,未来支持快速迁移独立部署以提升性能;应用层采用多级调度思路,按数据分片将大任务拆分成小粒度任务动态根据计算节点数完成分配,实现通过增加计算节点快速提升任务触发能力;
高可用:MTTR 分段治理思路,架构层在设计阶段考虑到单点、单机房风险,不管是存储层还是应用层都采用多机多活架构,并支持 HA 自动切换大大缩短 MTTF 时效;立体化的监控+拨测能力,覆盖从注册到触发全流程波动、成功率、耗时、延迟多维度监控,缩短 MTTI 时效;
整体流程
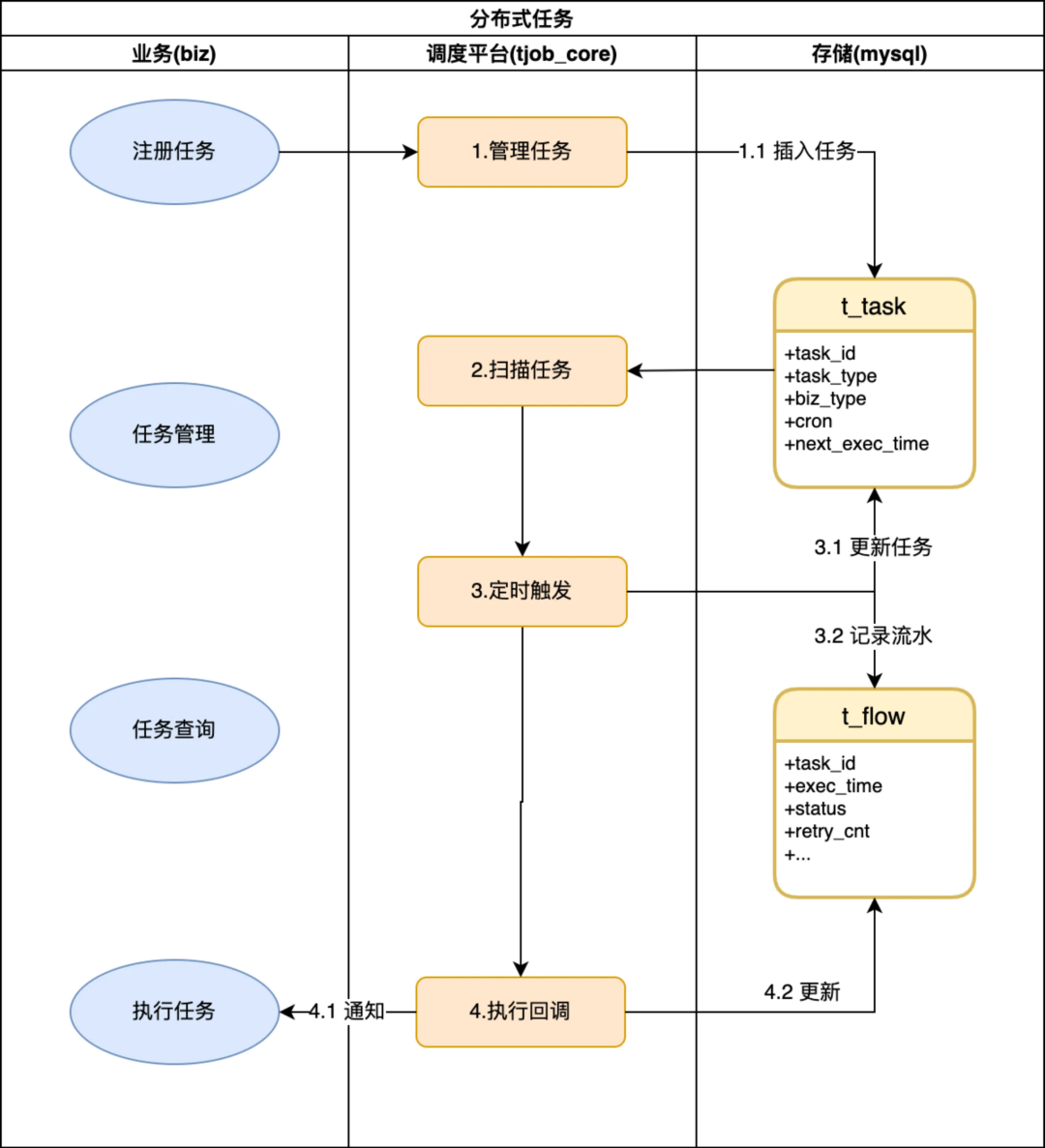
如上图所示一个任务执行流程和生命周期,大概分成四个阶段:
● 初始化:tjobs 提供任务注册接口,完成任务校验、计算并持久化到 mysql 存储,业务根据实际场景选择 CronCycleTask、IntervalCycleTask、FixedTimeSingleTask、DelayedTimeSingleTask 等不同任务类型提交注册即可;
● 待执行:tjobs 会每隔 5min 执行一次,捞取未来 5min 内所有待执行的任务,注册到一个内存 TimingWheels.中,由 timewheel 通过 callBackFunc 实现定时回调从而实现毫秒级延迟触发业务回调;
● 执行中:首先会产生一条 init 状态的调度流水、并根据任务类型、任务周期计算下一次调度时间,将 insert flow 和 update task 两个操作合并到一个事务中更新到 DB,通过事务保证每次任务肯定能被调度到;
● 已触发:根据 init flow 查找业务的回调配置,支持 http、trpc、videopacket-jce 多种协议,支持单播、组播多种类型的回调业务 spi,由业务完成响应的业务操作即完成了一次完整的任务调度。
详细设计
领域模型
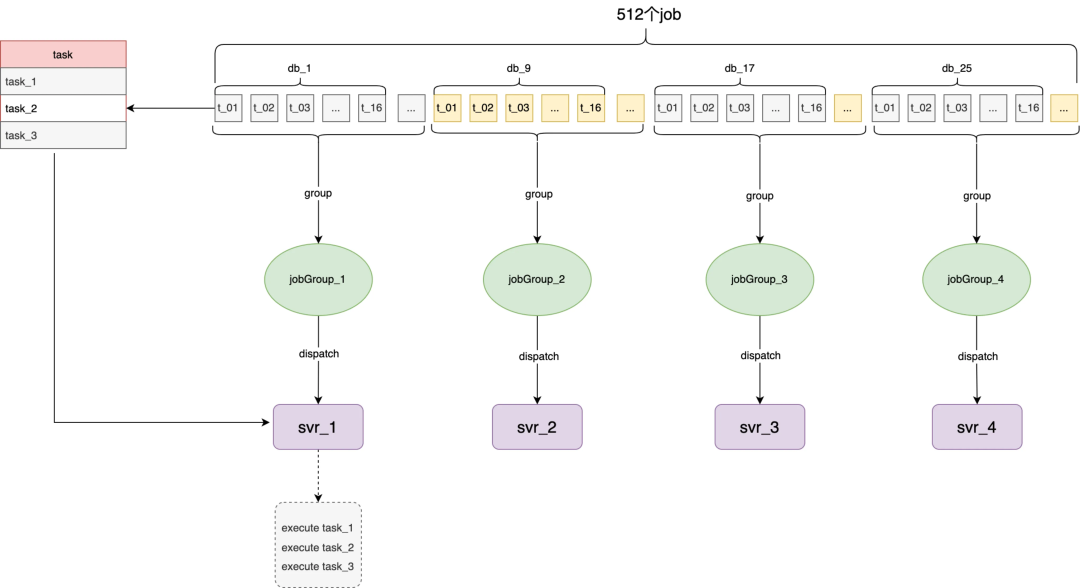
按照整体流程描述,tjobs 的主要职责管理好业务的定时任务调度,为此 tjobs 内部也需要会有一系列的跑批任务来保障调度的实时性,所以这里 tjobs 对两类任务分别做了抽象,如上图所示 tjobs 内部的跑批任务统称为 job、业务定时调度任务称为 task。tjobs 会将整个跑批任务拆分为 512 个最小的执行单元,按照当前可调度机器数打包成不同的 jobGroup 然后分发给 svr。由此衍生的几个关键模型说明:
JobGroup:tjobs 内部分发调度和容灾最小单元,会根据当前 svr 数量动态生成
Job:tjobs 任务最小执行单元,goroutine 协程调度单位(协程模型会详细介绍工作)
JobParam:每个 job 批次执行时的输入参数,批任务的执行模式类似 CyclicBarrier,每个周期有每个周期的执行参数
Task:业务注册的定时调度任务,分周期任务、单次任务等(下图以 cron 为例展示 19:01 时模型快照)
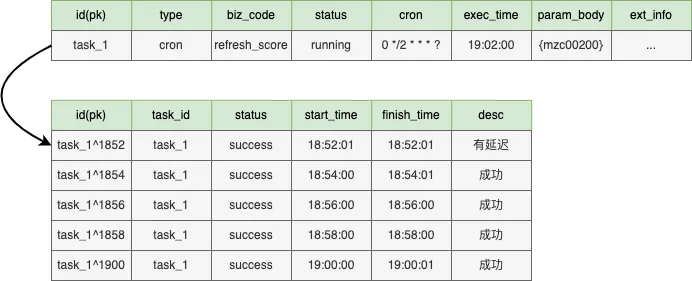
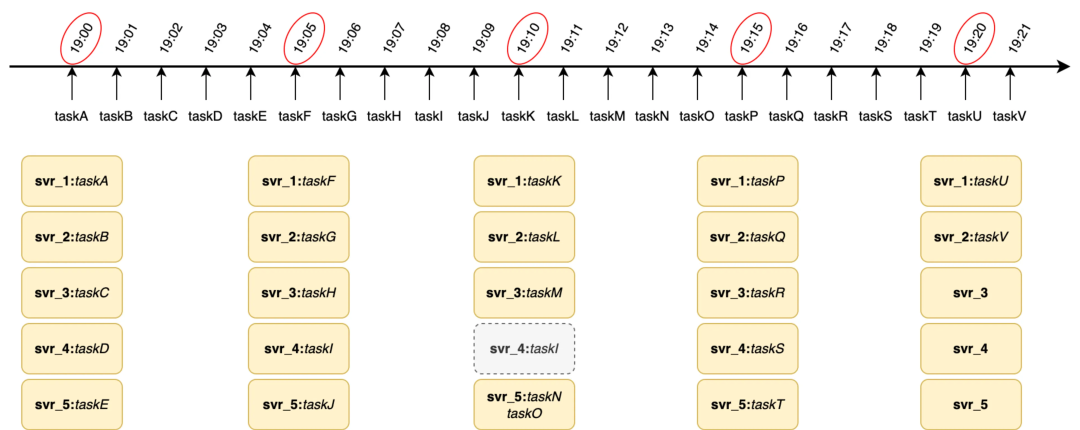
tjobs 的跑批任务的 timeline 原理如下图所示,假设 tjobs 按照 cron(0 0/5 * * ?)执行,在 19:00 时发起调度会拉取 taskA-taskE 任务平均分配给当前可运行的 svr1-svr5 机器上,19.05 以此类推,当 19.10 调度时 svr4 宕机,这会将 taskN 任务和 taskO 任务分配到 svr5 上完成对 svr_4 的容灾。
分库分表
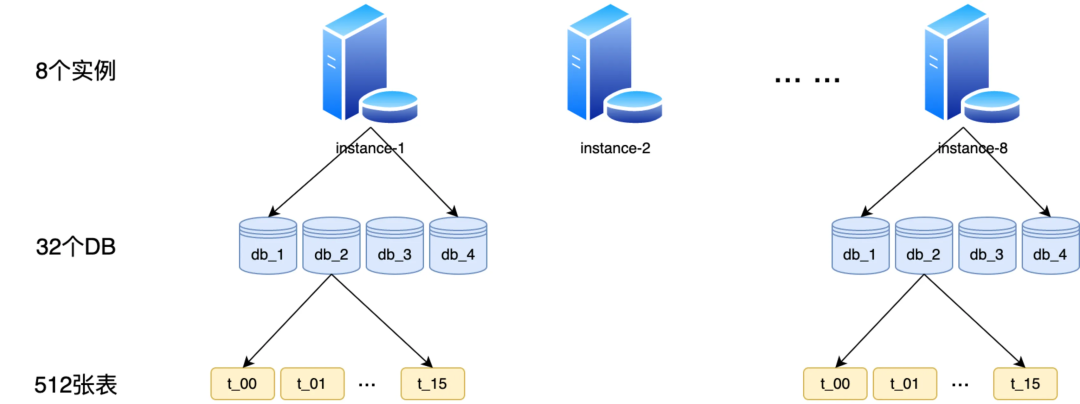
由于 redis 内存型存储,在持久化、事务上保障不足导致生产环境很容易出现丢任务或重复调度的情况,所以本次底层存储不在依赖 redis 存储而选用 mysql 数据库存储。按照百万 TPM 触发和百亿任务存储设计要求需通过分库分表来支持横向扩展能力。
如下图所示,我们生产环境部署了 8 个 DB 实例,每个实例上部署了 4 个逻辑库(目前先通过合并部署减少成本,未来如有更高 TPS 诉求每个逻辑库单独部署即可),每个逻辑库中拆分成 16 个表(拆分多表的目的是保障百亿级任务存储时单表行数不超过 2000w)以保障索引效率和查询性能。
多级调度
解决了 DB 存储的性能问题,接下来需要解决应用层单机性能限制,这里我们选择“多级调度模型”,物理上充分利用多机资源通过多机并发执行突破单机并行线程的限制,最大化提升任务触发的 TPS 上限。实现原理上将一个大的跑批任务拆解成多个小跑批任务分发到多台机器上执行。可以将内部跑批任务分成两个阶段,阶段一为 job 任务打包和派发、阶段二为 job 任务捞取和执行,多级调度主要实现阶段一。
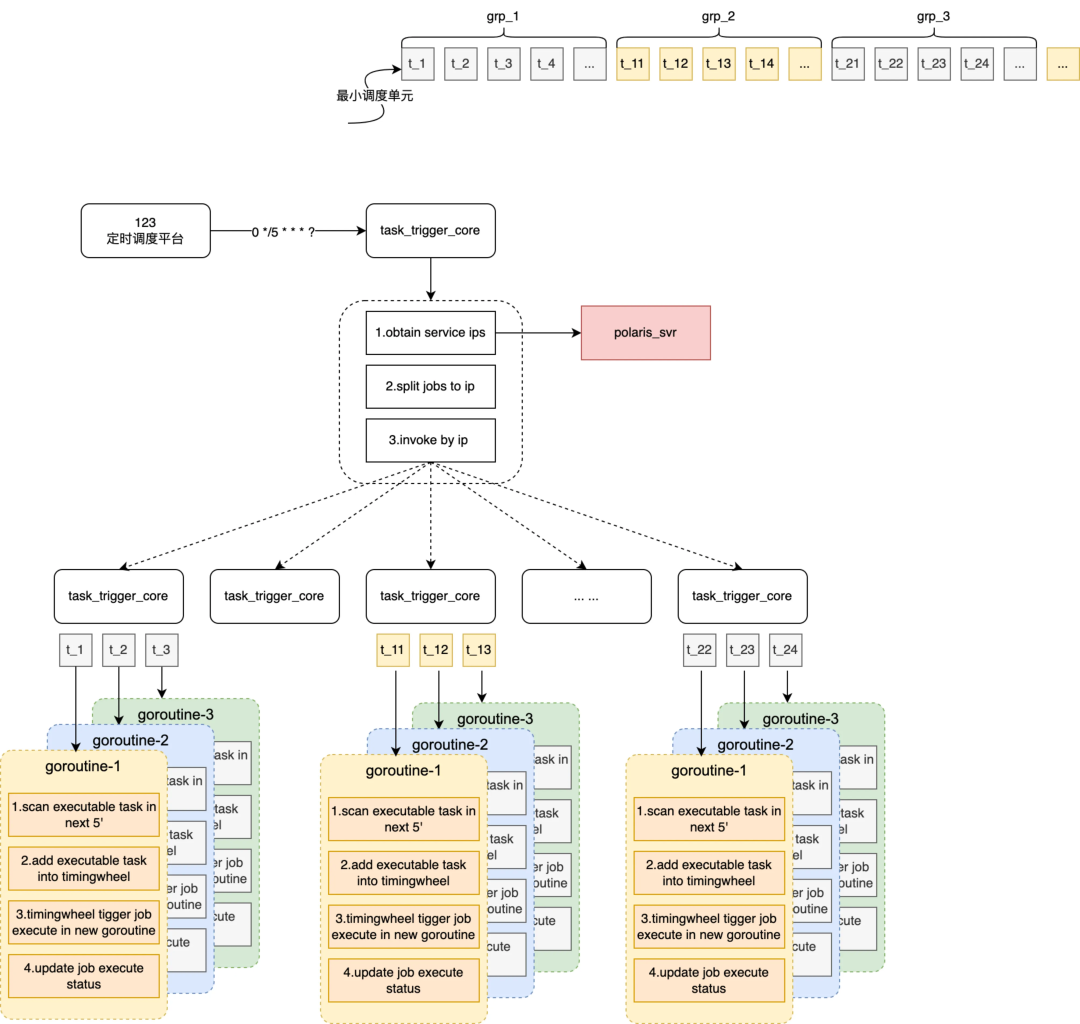
如上图所示,详细的执行流程分成 4 个步骤:
-
基于定时调度平台,每个 5min 做一次 cron 调度通知一台 tjobs 机器
-
tjobs 通过名字服务查询当前服务下所有可用机器供后续分包、调度
-
tjobs 根据当前可调度的机器数(n)将 512 个 job 打包成 n 个 jobGroup
-
将每个 jobGroup 绑定到一个机器上,通过指定 ip 方式通知服务执行阶段二(阶段二的详细实现见下节)
如领域模型中描述 tjobs 跑批任务采用 CyclicBarrier 栅格模式运行,这样做的目的 1)、期望每个周期各个 job 都能完成所有待触发任务(即 T1 周期完成 T1 时间之前所有的任务)防止任务积压;2)、每个任务都以相同的执行周期和参数运行可以幂等,防止任务被重复调度,从平台侧尽力提供 only once 的触发保障。
线程模型
本节接上节会详细介绍一下阶段二每个协程内单个 job 的详细执行流程,如下图所示会拆解 5 个步骤:
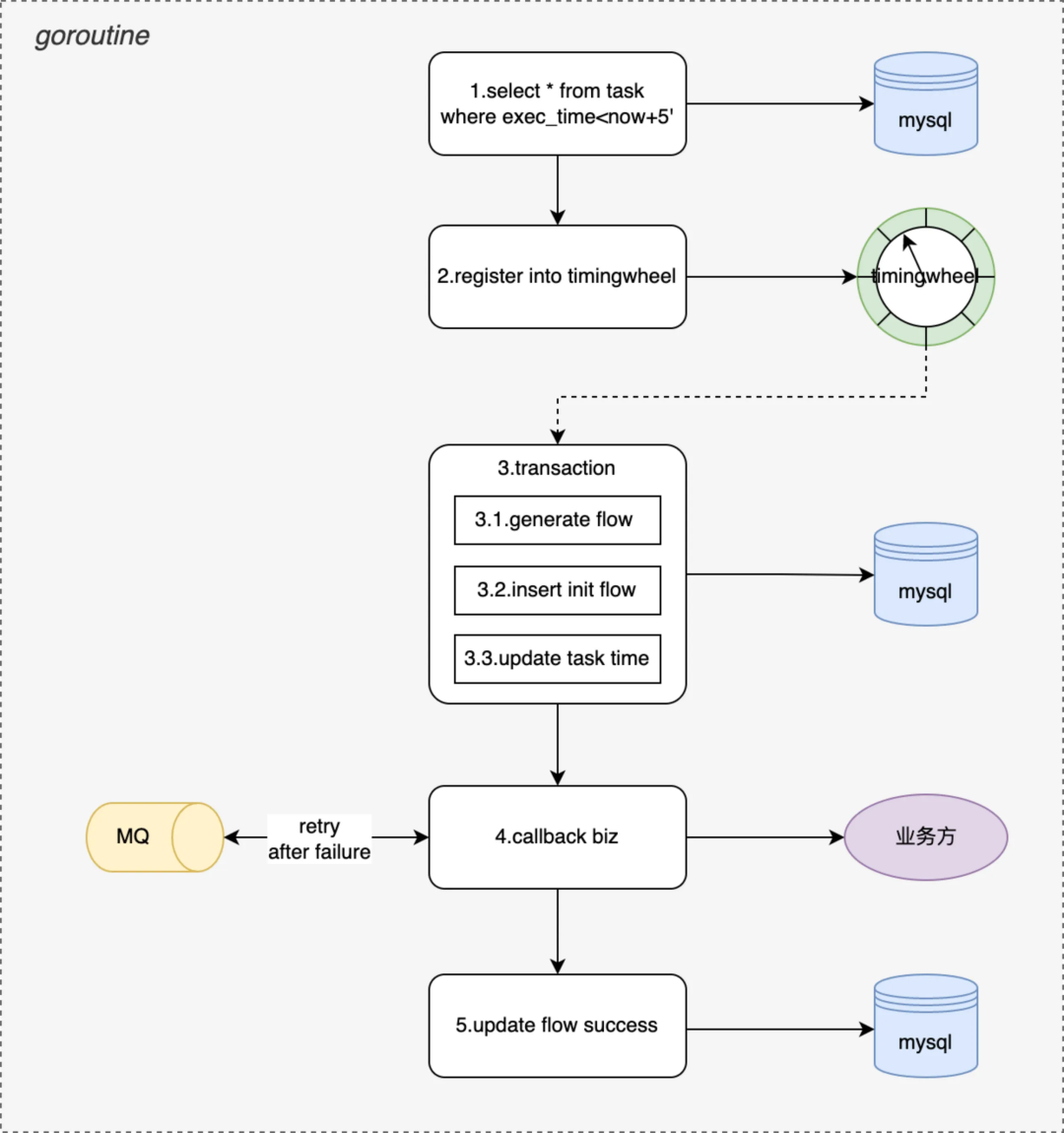
-
扫描本周期内所有待执行的任务,task 在注册、执行后都会更新下次待执行时间
-
将扫描出来的任务按照待触发时间注册到 timingwheel 中(timingwheel 为秒级)
-
timingwheel 到指定时间触发业务主要完成两个操作:生成调度流水并更新 task 下次执行状态 + 执行业务回调
-
根据业务回调配置(包括协议类型、回调方式、超时时间、重试次数等),执行业务回调通知
-
更新调度流水状态,调度成功后或达到重试次数后推进流水到终态
tjobs 的跑批执行周期 5‘,业务 task 可能会按照 30''调度,这里会生成 10 个待执行任务注册到 timingwheel 中。
通过 mysql 事务保障,生成流水和更新 task 下次执行状态在一个事务内,保障任务肯定能被触发到。
tjobs 会有兜底协程持续扫描未到终态的调度流水持续推进,保证任务触达率>99.99%。
HA 支持
作为一个任务调度平台,系统的高可用性和功能的完整性同样重要,所以对外承诺三个核心 SLA(全年可用性>99.95%、任务触达率>99.99%、p99(延迟)<1s)。达成上述 SLA 就需要底层存储、外部依赖均保持高可用外,应用自身架构需要有更强鲁棒性。
DB 容灾
DB 实例按照一主两备部署,依赖 DB 持久化能力、以及主备半同步复制能力,存储层在主库故障时能自动 failover 到备库且保证数据 rpo=0(不丢数据),能应对存储层单机故障,同时两个备库分别部署到两个可用区机房,从而支持同城跨机房灾备能力(考虑成本问题暂不支持跨城容灾)。
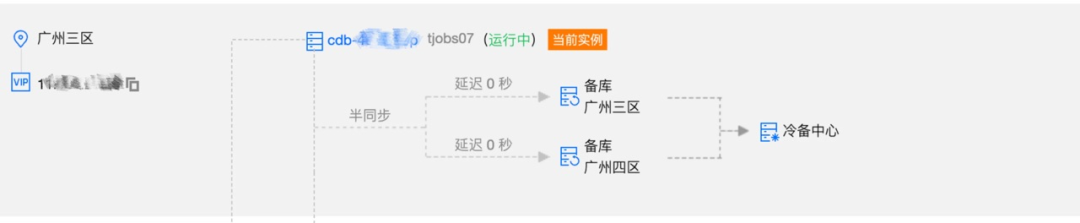
因此从 DB 层看平台的可用性 SLA 满足>99.99%,并且任务 RPO=0 满足不丢任务 SLA,主备切换分钟级 RTO 基本满足全年 P99(延迟)<1s 的 SLA。
应用容灾
根据多机调度模型原理,每隔固定周期执行一次跑批任务,将未来待执行的任务缓存到应用内存中由 timingwheel 触发,其中涉及四个应用服务(定时调度、名字服务、数据库和 tjobs 应用)协作,数据库实例容灾上节已分析基本满足 SLA,名字通过增加本地缓存实现弱依赖也能满足 SLA,现需要对定时调度平台和 tjobs 应用两个强依赖服务做容灾能力保障。
定时调度平台不可用或调度延迟直接导致任务不能被准时调度,这里应对思路有:
-
依赖 linux 的 corntab 触发,存在应用单点问题,导致整体可用性无法保障
-
基于调度平台分钟级 RTO,通过增大调度周期减少对调度平台依赖度
为达成 p99 延迟<1s,tjobs 会提前将待触发任务缓存到应用内存中,这样如果 tjobs 应用服务器宕机则该服务器上本周期内任务都不能被正常调度,只能等下个执行周期被重新捞起调度,导致 p99(任务延迟)<1s 不达标,这里应对思路有:
-
缩短调度周期(5'->30''),最多影响单机上 30‘’任务的调度延迟,降低延迟概率但不能彻底解决问题,且缩短周期会和调度平台交互更强(有悖减少调度平台依赖)
-
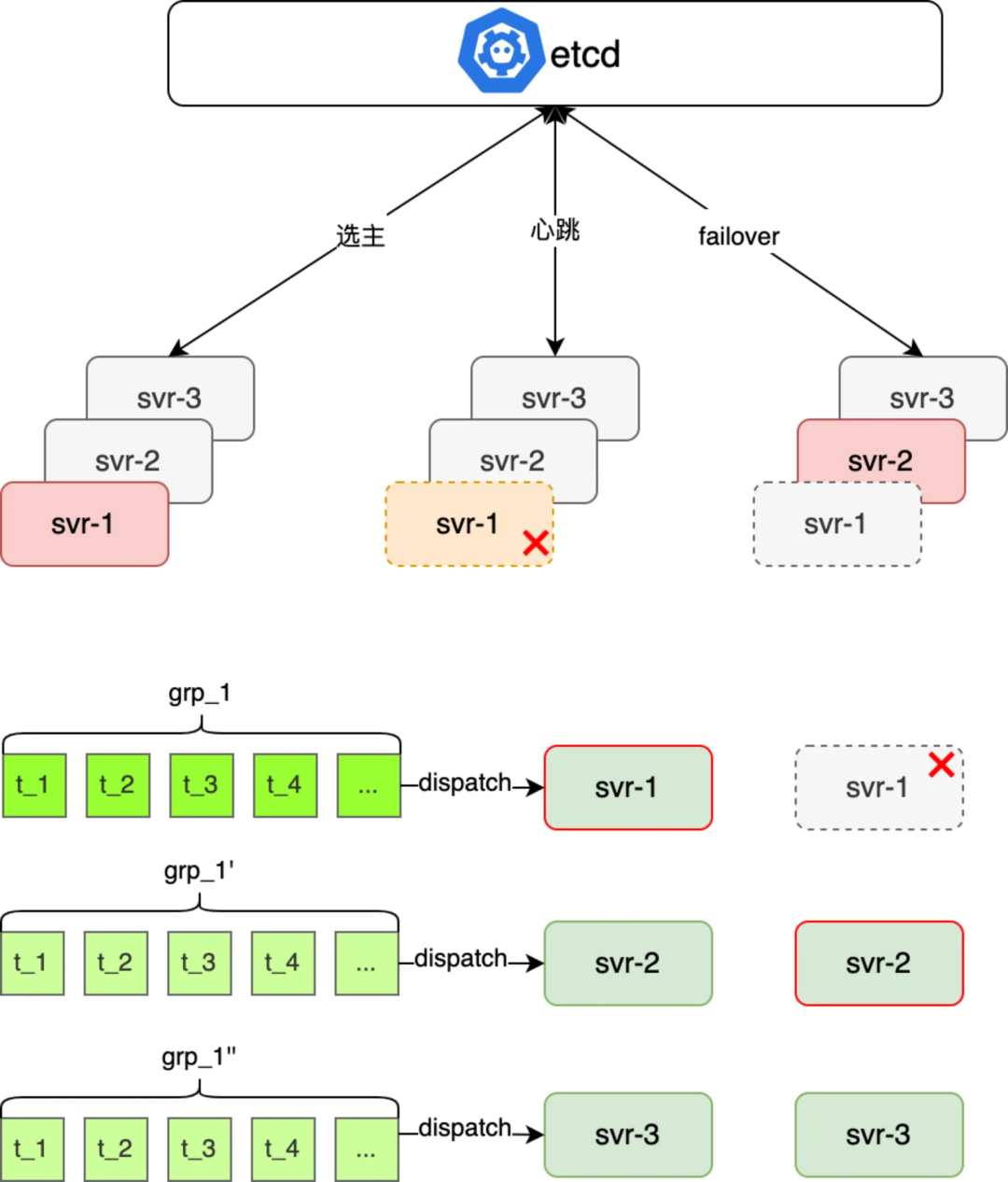
服务器支持主备 failover,每个任务组派发到多个服务器上,通过 etcd 选主一台服务器执行,如果服务器宕机自动 failover 到备机执行,max 延迟就是选主耗时
综合上述分析看,要提升保障平台整体的 P99(延迟)、和 99.95%的可用性 SLA,最优方案是“基于调度平台+应用服务器主备 failover”,具体的实现思路(如下图所示),每个周期内待调度的 jobGroup 分被分配到三个不同应用 svr 上,应用层一主两备的部署运行时,然后三个应用 svr 链接 etcd,利用 etcd 的选主和自动 failover 能力,既保障了任务运行的 only once 又能保障单机故障时该机上待执行任务的准时触发
Misfire 策略
tjobs 平台会有兜底的 misfire 策略以防止任务不能被准时调度时兜底调度过期任务,以保障所有任务触达率不低于 99.99%,目前提供两类 Misfire 策略:
1. 马上触发一次,已过期任务马上触发一次业务回调(默认用于 singleTask)
2. 尽快触发一次,忽略已过期任务触发回调,本周期内尽快执行一次业务回调(默认用于 cronTask 和 intervalTask)
部署落地
部署架构
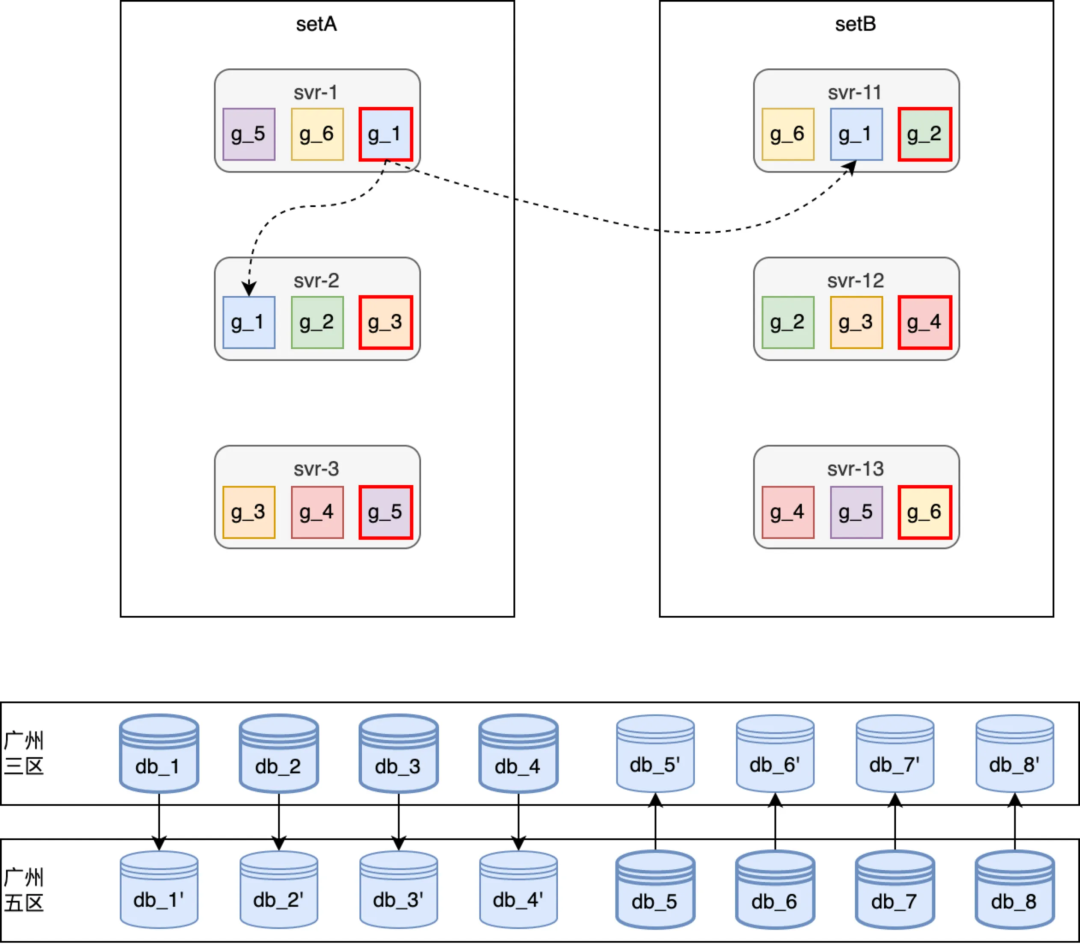
非容灾模式线上运行快照(如上图所示),针对常见的单机宕机或者重启在 HA 章节已经介绍过,比如 svr-2 宕机或重启时 g_3 这个跑批任务组会自动 failover 到 svr-12 或者 svr-3 上继续断点执行,从而保障高可用性。
针对常见的单机房故障,在任务 dispatch 环节会将一个任务 jobGroup 的主备执行机器分配到不同的 set,从而保障单机房故障时从应用到 DB 都能自动 failover 到其他可用区机房;针对日常的停机发布,由于应用支持分 set 主备 failover,因此发布时按 a、b set 依次发布即可。
性能压测
详细的压测执行过程不在展开,这里只同步一下压测结论
压测摸高峰值:任务注册 1.5w/s、任务触发 2.2w/s
应用&DB 峰值:
| 机型配置 | 机器数量 | 峰值负载 | 说明 | |
|---|---|---|---|---|
| 应用服务器 | 4C8G | 20 | 45% | 支持横向扩展,通过扩容保留 20 倍容量空间 |
| 数据库服务 | 8C32G | 8 | 75% | 目前合并部署,通过调整部署保留 4 倍空间通过 DB 升配保留 8 倍的容量空间 |
峰值 SLA:可用性>99.99%、1s 内触发占比>99.95%、任务触达率~100%。
总结
tjobs 作为一个高性能、低延迟的分布式任务调度平台,在满足通用的任务注册、查询、触发等基本功能同时,也通过可伸缩的架构、HA 能力、体系化可用性建设保障系统在百亿任务量、百万 TPM 触发能力下满足系统可用性、延迟、触达率 SLA。
支持将任务划分到不同的分片分配到不同的应用机器上执行,既保留了高峰时百万 TPM 的触发能力、也支持低峰时合并部署以节省成本;通过任务前置使用定时任务扫描、内存时间轮保证任务及时触发,保证了任务执行的低延迟;通过主备热活、自动 failover 能力建设保证系统整体从存储层到应用的全栈高可用。
附录
etcd 选主实现故障主备秒级切换高可用架构 | KL 博客
作者:timgc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号