

ES基础查询语法介绍
Filter DSL
term 过滤
terms 过滤
range 过滤
exists 和 missing 过滤
bool 过滤
排序查询
分页查询
Query DSL
match_all 查询
match 查询
查询结果部分字段说明:
-
took:耗费了几毫秒。 -
timed_out:是否超时,这里是没有。*
_shards:数据拆成了若干个分片,所以对于搜索请求,会打到所有primary shard(或者是它的某个replica shard也可以)。 hits.total:查询结果的数量,3个document。hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高。hits.hits:包含了匹配搜索的document的详细数据。aggregations: 聚合查询的结果
query_String查询在复杂查询时很那用, DSL使用json的方式进行查询, 一般查询都是使用get方式(post也是可以请求到的, 但是不符合Restful规范), es的get查询支持请求体term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型):
{ “term”: { “age”: 26 }}
{ “term”: { “date”: “2014-09-01” }}
{ “term”: { “public”: true }}
{ “term”: { “tag”: “full_text” }}
完整的例子, hostname 字段完全匹配成 xxx 的数据:

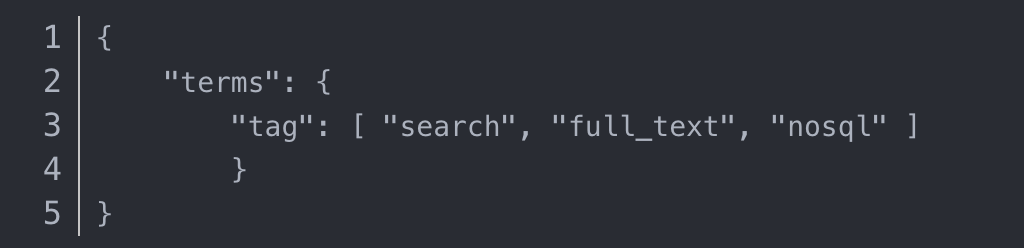
terms 过滤
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
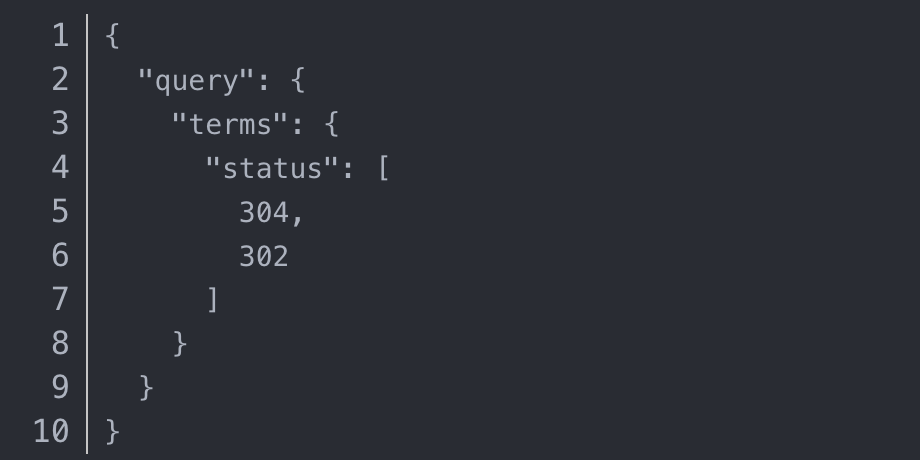
完整的例子,所有http的状态是 302 、304 的, 由于ES中状态是数字类型的字段,所有这里我们可以直接这么写:
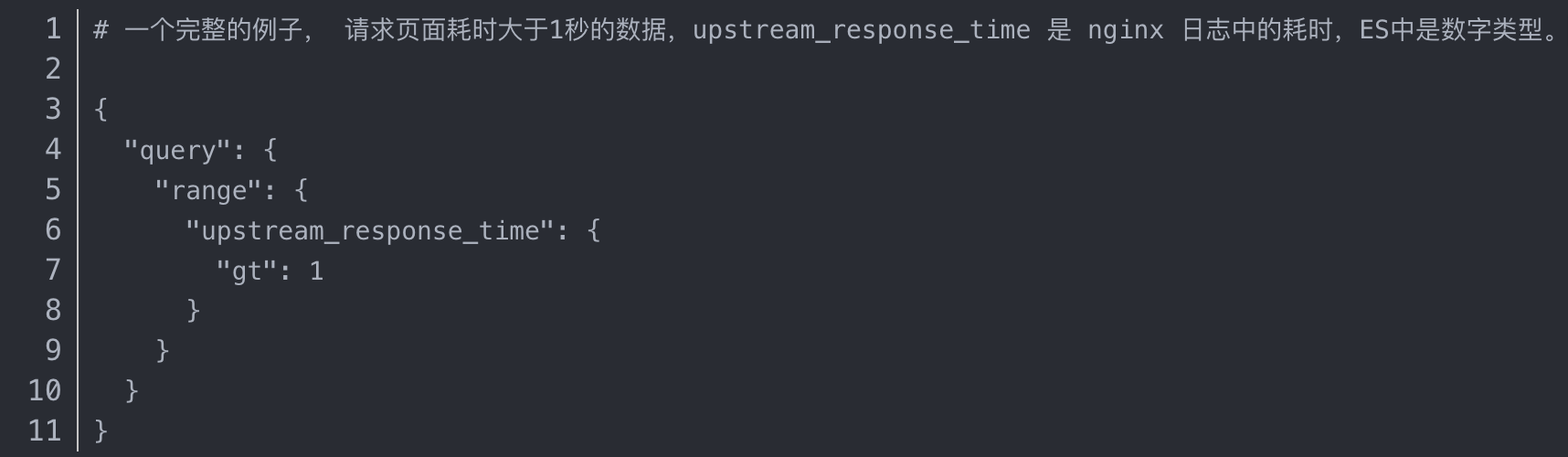
range 过滤
range过滤允许我们按照指定范围查找一批数据:

范围操作符包含:
- gt :: 大于
- gte:: 大于等于
- lt :: 小于
- lte:: 小于等于
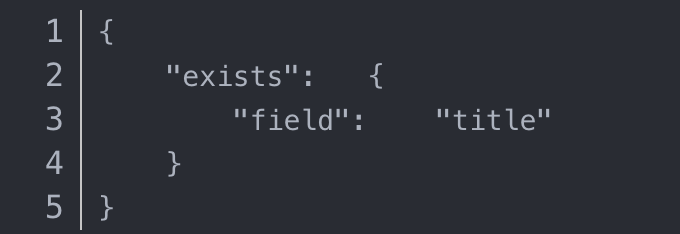
exists 和 missing 过滤
exists 和 missing 过滤可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL条件.
这两个过滤只是针对已经查出一批数据来,但是想区分出某个字段是否存在的时候使用。
bool 过滤
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含一下操作符:
- must :: 多个查询条件的完全匹配,相当于 and。
- must_not :: 多个查询条件的相反匹配,相当于 not。
- should :: 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组:

排序查询
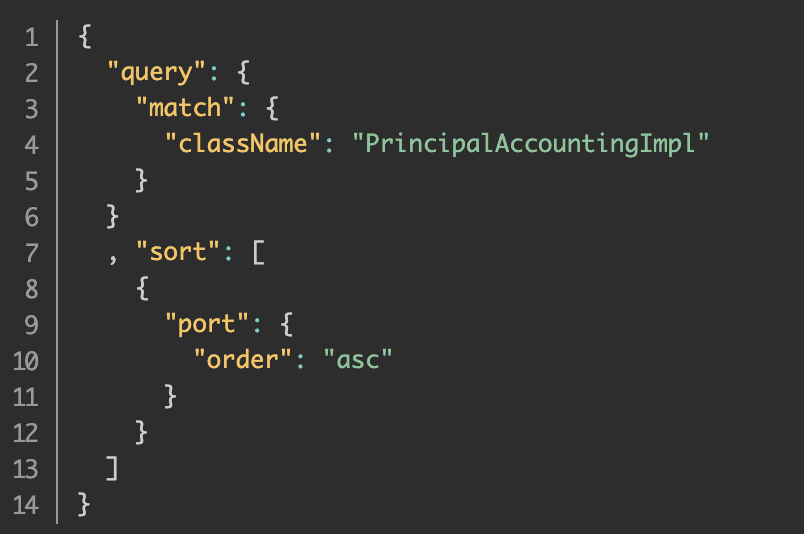
分页查询
from表示从第几行开始,size表示查询多少条文档。from默认为0,size默认为10

Query DSL
match_all 查询
可以查询到所有文档,是没有查询条件下的默认语句。
{
“match_all”: {}
}
此查询常用于合并过滤条件。 比如说你需要检索所有的邮箱,所有的文档相关性都是相同的,所以得到的_score为1.
match 查询
match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析match一下查询字符:
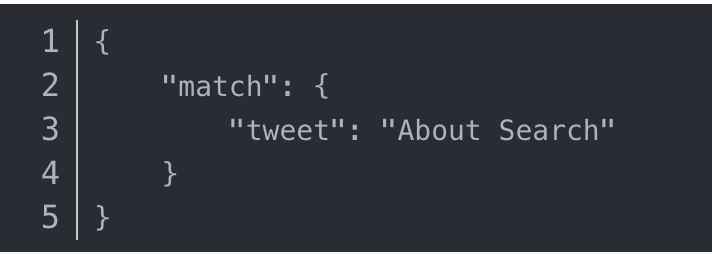
如果用match下指定了一个确切值,在遇到数字,日期,布尔值或者not_analyzed 的字符串时,它将为你搜索你给定的值:

提示: 做精确匹配搜索时,你最好用过滤语句,因为过滤语句可以缓存数据。
match查询只能就指定某个确切字段某个确切的值进行搜索,而你要做的就是为它指定正确的字段名以避免语法错误。
文件来源:
https://blog.csdn.net/mon_star/article/details/102934620
https://www.jianshu.com/p/50dbd7252d0a

