RDD 编程
RDD 编程
目录
- RDD 编程
- 一、词频统计:
- 1. 读文本文件生成 RDD lines
- 2. 将一行一行的文本分割成单词 words flatmap()
- 3. 全部转换为小写 lower()
- 4. 去掉长度小于3的单词 filter()
- 5. 去掉停用词
- 6. 转换成键值对 map()
- 7. 统计词频 reduceByKey()
- 8. 按字母顺序排序 sortBy(f)
- 9. 按词频排序 sortByKey()
- 10. 结果文件保存 saveAsTextFile(out_url)
- 11. 词频结果可视化 charts.WordCloud()
- 12. 比较不同框架下(Python、MapReduce、Hive和Spark),实现词频统计思想与技术上的不同,各有什么优缺点.
- 二、学生课程分数案例
- 1. 总共有多少学生?map(), distinct(), count()
- 2. 开设了多少门课程?
- 3. 每个学生选修了多少门课?map(), countByKey()
- 4. 每门课程有多少个学生选?map(), countByValue()
- 5. Tom选修了几门课?每门课多少分?filter(), map() RDD
- 6. Tom选修了几门课?每门课多少分?map(),lookup() list
- 7. Tom的成绩按分数大小排序。filter(), map(), sortBy()
- 8. Tom的平均分。map(),lookup(),mean()
- 9. 生成(课程,分数)RDD,观察 keys(), values()
- 10. 每个分数+5分。mapValues(func)
- 11. 求每门课的选修人数及所有人的总分。combineByKey()
- 12. 求每门课的选修人数及平均分,精确到2位小数。map(),round()
- 13. 求每门课的选修人数及平均分。用 reduceByKey() 实现,并比较与 combineByKey() 的异同。
- 14. 结果可视化。charts, Bar()
- 一、词频统计:
一、词频统计:
1. 读文本文件生成 RDD lines
>>> lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
>>> lines.foreach(print)

2. 将一行一行的文本分割成单词 words flatmap()
>>> words = lines.flatMap(lambda line:line.split())
>>> words.foreach(print)

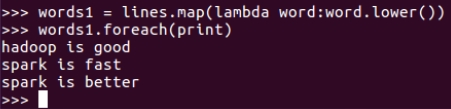
3. 全部转换为小写 lower()
>>> words1 = lines.map(lambda word:word.lower())
>>> words1.foreach(print)
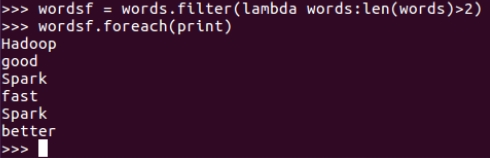
4. 去掉长度小于3的单词 filter()
>>> wordsf = words.filter(lambda words:len(words)>2)
>>> wordsf.foreach(print)
5. 去掉停用词
>>> with open("/usr/local/spark/mycode/rdd/stopwords.txt") as f:
>>> stops = f.read().split()
>>> lines.flatMap(lambda line:line.split()).filter(lambda word:word not in stops).collect()

6. 转换成键值对 map()
>>> words.map(lambda word:(word,1)).collect()

7. 统计词频 reduceByKey()
>>> words.map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b).collect()

8. 按字母顺序排序 sortBy(f)
>>> words.map(lambda word : (word,1)).reduceByKey(lambda a,b:a+b).sortBy(lambda word:word[0]).collect()

9. 按词频排序 sortByKey()
>>> words.map(lambda word:(word.lower(),1)).reduceByKey(lambda a,b:a+b).sortBy(lambda word:word[1],False).collect()

10. 结果文件保存 saveAsTextFile(out_url)
>>> words_out = words.map(lambda word:(word.lower(),1)).reduceByKey(lambda a,b:a+b).sortBy(lambda word:word[1],False)
>>> words_out.saveAsTextFile("file:///usr/local/spark/mycode/rdd/words_out")

$ ls /usr/local/spark/mycode/rdd

11. 词频结果可视化 charts.WordCloud()
12. 比较不同框架下(Python、MapReduce、Hive和Spark),实现词频统计思想与技术上的不同,各有什么优缺点.
二、学生课程分数案例
1. 总共有多少学生?map(), distinct(), count()
>>> lines = sc.textFile("file:///usr/local/spark/mycode/rdd/chapter4-data01.txt")
>>> lines.map(lambda line:line.split(',')[0]).distinct().count()

2. 开设了多少门课程?
>>> lines.map(lambda line:line.split(',')[1]).distinct().count()

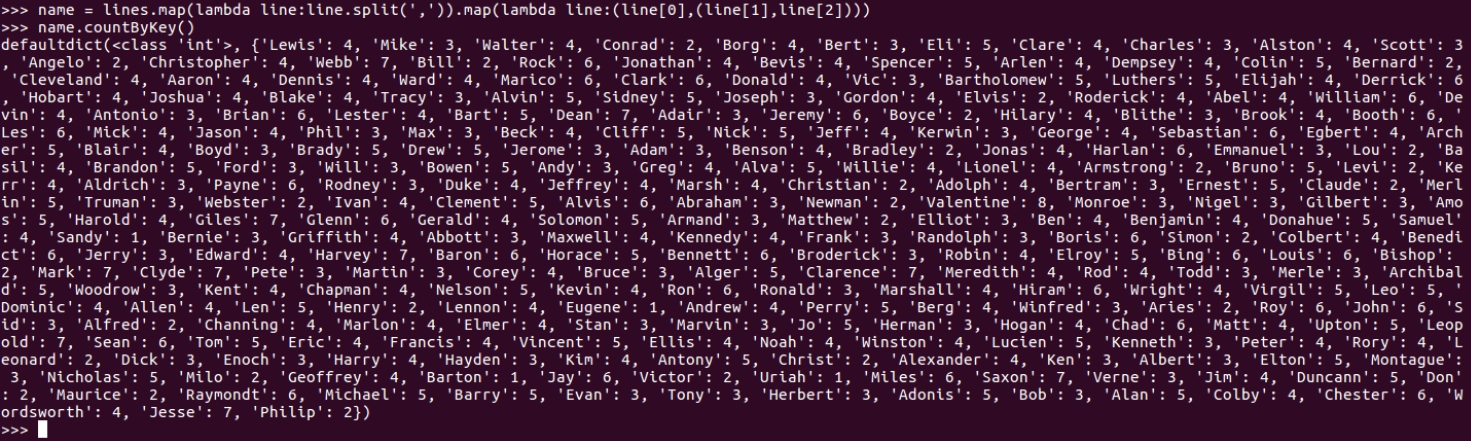
3. 每个学生选修了多少门课?map(), countByKey()
>>> name = lines.map(lambda line:line.split(',')).map(lambda line:(line[0],(line[1],line[2])))
>>> name.countByKey()
4. 每门课程有多少个学生选?map(), countByValue()
>>> name = lines.map(lambda line:line.split(',')).map(lambda line:line[1])
>>> name.countByValue()

5. Tom选修了几门课?每门课多少分?filter(), map() RDD
>>> Tom = lines.filter(lambda line:'Tom' in line).map(lambda line:line.split(','))
>>> Tom.collect()

6. Tom选修了几门课?每门课多少分?map(),lookup() list
>>> lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[2])).lookup('Tom')

7. Tom的成绩按分数大小排序。filter(), map(), sortBy()
>>> Tom.sortBy(lambda word:word[2],False).collect()

8. Tom的平均分。map(),lookup(),mean()
>>> from numpy import mean
>>> tomList=lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[2])).lookup('Tom')
>>> mean([int(x) for x in tomList])

9. 生成(课程,分数)RDD,观察 keys(), values()
>>> course = lines.map(lambda x:x.split(',')).map(lambda x:(x[1],x[2]))
>>> course.keys().take(10)
>>> course.values().take(10)

10. 每个分数+5分。mapValues(func)
>>> course.map(lambda x:(x[0],int(x[1]))).mapValues(lambda x:x+5).take(10)

11. 求每门课的选修人数及所有人的总分。combineByKey()
>>> course_com = course.combineByKey(lambda v: (int(v),1),lambda c,v:(c[0]+int(v),c[1]+1),lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1]))
>>> course_com.collect()

12. 求每门课的选修人数及平均分,精确到2位小数。map(),round()
>>> course_com.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1]))).collect()

13. 求每门课的选修人数及平均分。用 reduceByKey() 实现,并比较与 combineByKey() 的异同。
>>> lines.map(lambda line:line.split(',')).map(lambda x:(x[1],(int(x[2]),1))).reduceByKey(lambda a,b:(a[0]+b[0],a[1]+b[1])).map(lambda y:(y[0],y[1][1],round(y[1][0]/y[1][1]))).collect()

14. 结果可视化。charts, Bar()
转换操作:
| 操作 | 含义 |
|---|---|
| first() | 返回第一个元素 |
| distinct() | 去重,删除重复的元素 |
| randomSplit() | 将RDD以随机数的方式按照比例分为多个RDD |
| union() | 并集 |
| intersection() | 交集 |
| subtract() | 差集 |
| cartesian() | 笛卡尔积 |
| map(func) | 将每个元素传递到函数func中一个新的数据集 |
| flatMap(func) | 与map()相似映射到0或多个输出结果 |
| sortBy(func) | 按func结果将RDD排序 |
行动操作练习:
| 操作 | 含义 |
|---|---|
| filter(func) | 筛选出满足函数func的元素 |
| take(n) | 返回前n个元素 |
| takeOrdered(n) | 返回排序后的前n个元素 |
| top(n) | 返回最大的n个元素 |
| collect() | 返回所有元素,列表 |
| collectAsMap() | 返回所有元素的字典,MAP形式的串行化 |
| count() | 返回元素个数 |
| countByValue() | 返回每个元素重复个数,字典 |
| countByKey() | 返回的是每一键组内的记录数,字典 |
| lookup(key) | 返回某键值下的所有值,列表 |
点击查看隐藏内容
>>> rdd = sc.parallelize([(1,"a"),(2,"b"),(3,"c"),(4,"d"),(5,"e")])
>>> rdd.first()
>>> rdd.take(3)
>>> rdd.takeOrdered(2)
>>> rdd.top(2)
>>> rdd.collect()
>>> rdd.collectAsMap()
>>> rdd.count()
>>> rdd.countByValue()
>>> rdd.countByKey()
>>> rdd.lookup(1)

键值对操作:
- groupByKey()
- reduceByKey(func)
- combineByKey()
- sortByKey()
- keys()
- values()
- mapValues(func)
- join()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号