大数据第六次作业
目录
Hadoop使用实例
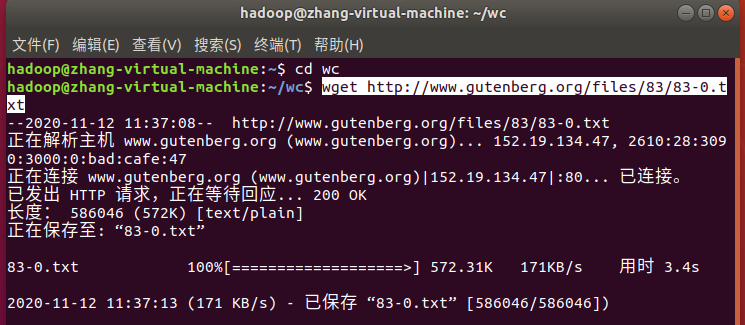
1. 下载喜欢的电子书或大量文本数据,并保存在本地文本文件中
wget http://www.gutenberg.org/files/83/83-0.txt
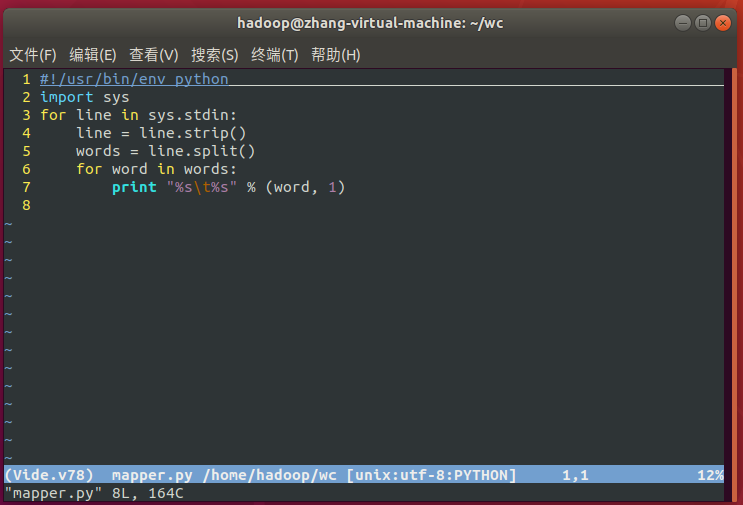
2. 编写map与reduce函数
mapper.py
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print "%s\t%s" % (word, 1)
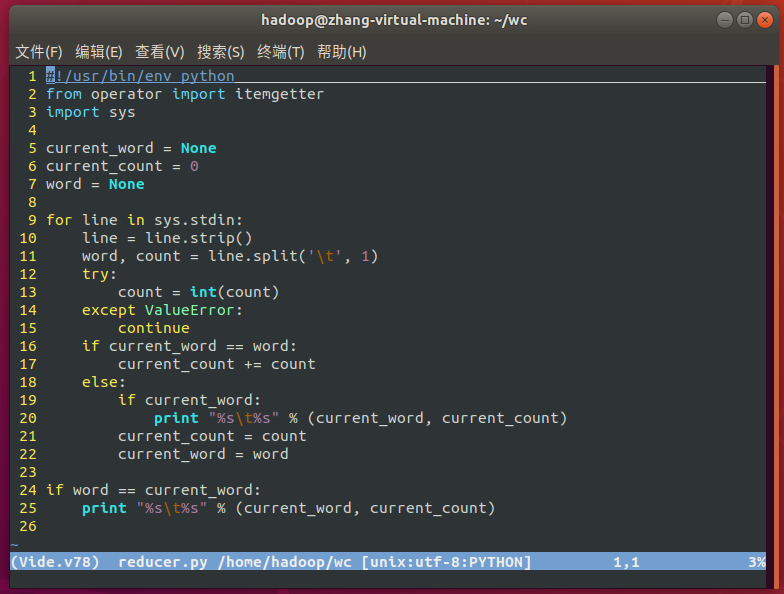
reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word:
print "%s\t%s" % (current_word, current_count)
修改文件权限
chmod a+x mapper.py
chmod a+x reducer.py
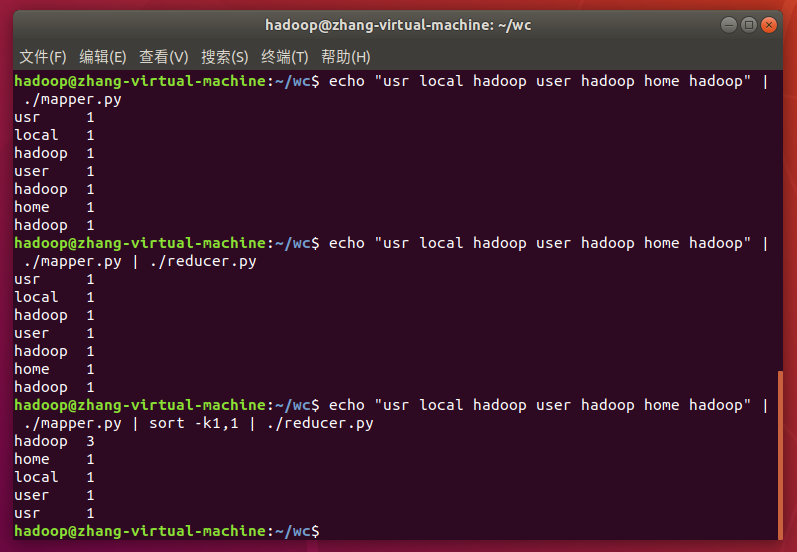
3. 本地测试map与reduce
echo "usr local hadoop user hadoop home hadoop" | ./mapper.py
echo "usr local hadoop user hadoop home hadoop" | ./mapper.py | ./reducer.py
echo "usr local hadoop user hadoop home hadoop" | ./mapper.py | sort -k1,1 | ./reducer.py
4. 将文本数据上传至HDFS上
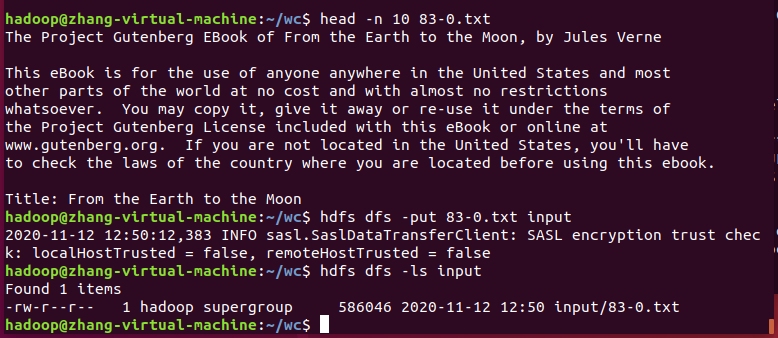
head -n 10 83-0.txt
hdfs dfs -put 83-0.txt input
hdfs dfs -ls input
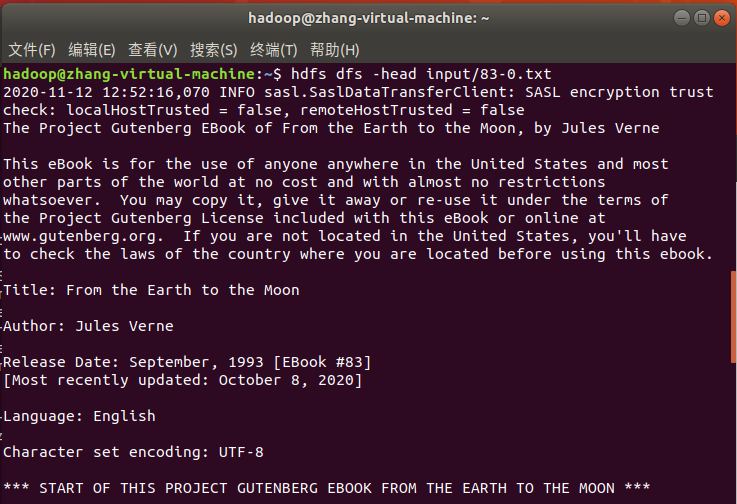
hdfs dfs -head input/83-0.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号