大数据第四次作业
Hadoop安装 与 HDFS体系结构
1. 用自己的图,描述HDFS体系结构、工作原理与流程。
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
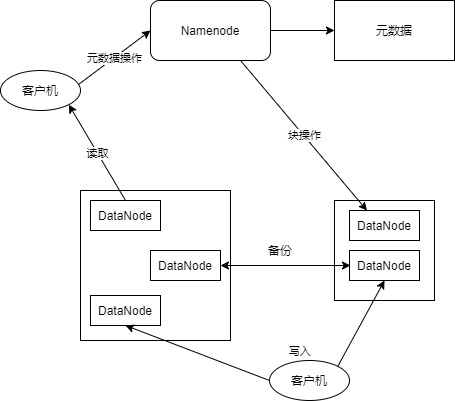
Namenode和Datanode被设计成可以在普通的商用机器上运行。这些机器一般运行着GNU/Linux操作系统(OS)。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个Namenode实例,而集群中的其它机器分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。
集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
2. 伪分布式安装Hadoop。
2.1 安装Java环境
在官网下载Oracle JDK
sudo mkdir /usr/lib/jvm #创建/usr/lib/jvm目录用来存放JDK文件
sudo tar -zxvf jdk-8uversion-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
设置环境变量:
cd ~
vim ~/.bashrc
在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_version
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
2.2 安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
2.3 安装 Hadoop
Hadoop 可以通过 http://mirror.bit.edu.cn/apache/hadoop/common/ 或者 http://mirrors.cnnic.cn/apache/hadoop/common/ 下载,一般选择下载最新的稳定版本,即下载 “stable” 下的 hadoop-3.x.y.tar.gz 这个格式的文件。
我们选择将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxf ~/下载/hadoop-version.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-version/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
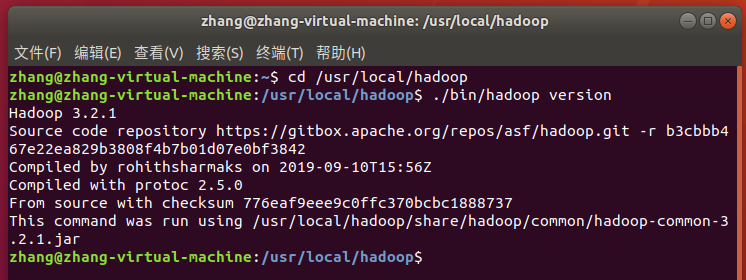
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
2.4 Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将当中的
<configuration>
</configuration>
修改为下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
修改hadoop-env.sh文件,在里面指定JAVA_HOME的具体路径:
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
在以下位置添加JAVA路径:
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/local/java
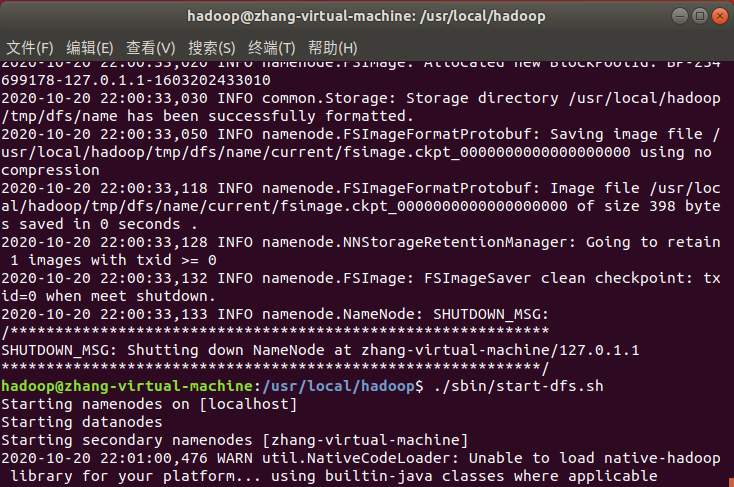
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
接着开启 NameNode 和 DataNode 守护进程:
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
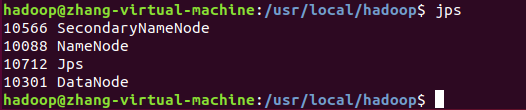
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”
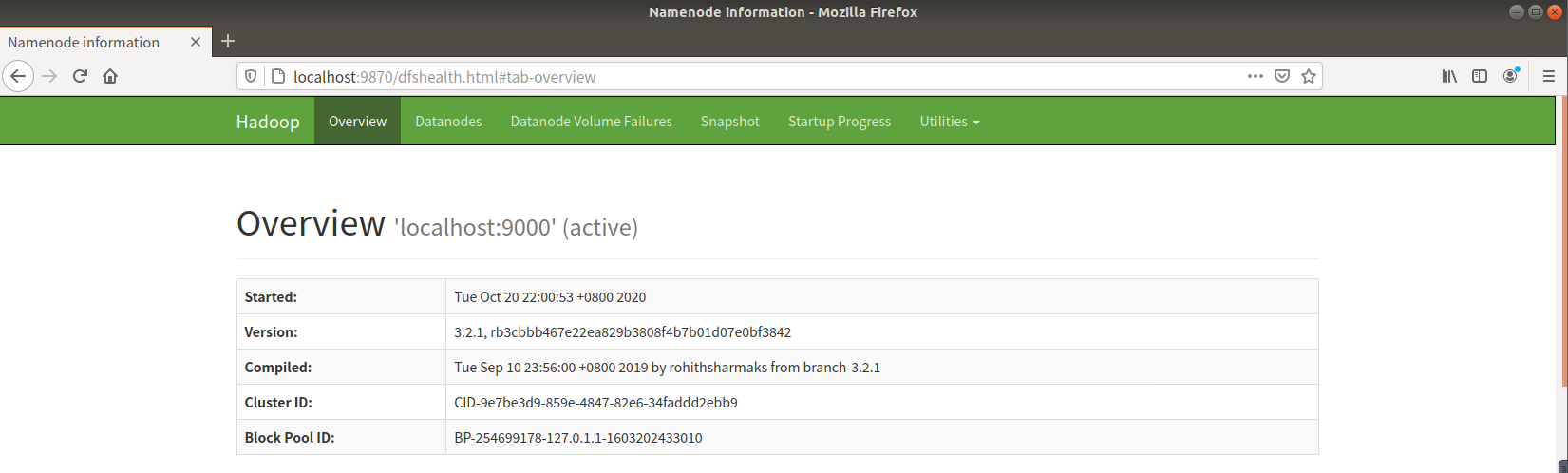
成功启动后,可以访问 Web 界面查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号