爬虫介绍
爬虫是什么
爬虫是一个模仿浏览器行为,向服务器发送请求并且获得数据的应用程序。而互联网好比一张大网,数据是网上的猎物,爬虫就是蜘蛛
爬虫的流程
发起请求 --> 获取数据 --> 解析数据 --> 存储数据
浏览器行为
抓包工具:fiddler、mitmproxy
Elements:浏览器渲染后的代码,爬虫爬取的是原始数据
Console:js控制台,可以执行js代码,在js注入之前进行调试。如document.charset可以查看编码格式
Sources:网页的资源
Network:网页的抓包工具
Http协议中需要关注的
1.请求
- Request URL:请求地址
- Request Method:请求方式
- get
- post
- 请求体:formdata、json、files三种格式
- Request Headers:请求头
- Cookie:保存信息(主要记录用户登录状态)
- User-Agent:用户身份
- Referer:告诉服务器你从哪里来。防止盗链行为
- 服务器特有字段
2.响应
- Status Code:状态码
- 2xx:请求成功,但是不能用这个作为请求成功的唯一标识
- 3xx:重定向
- 4xx:客户端错误
- 5xx:服务器错误
- 响应头
- location:重定向的url
- set-cookie:设置cookie
- 服务器特定字段
- 响应体
- html代码
- 二进制:图片,视频,音频
- json格式
- jsonp格式:可以跨域
爬虫与反爬虫的对抗历史
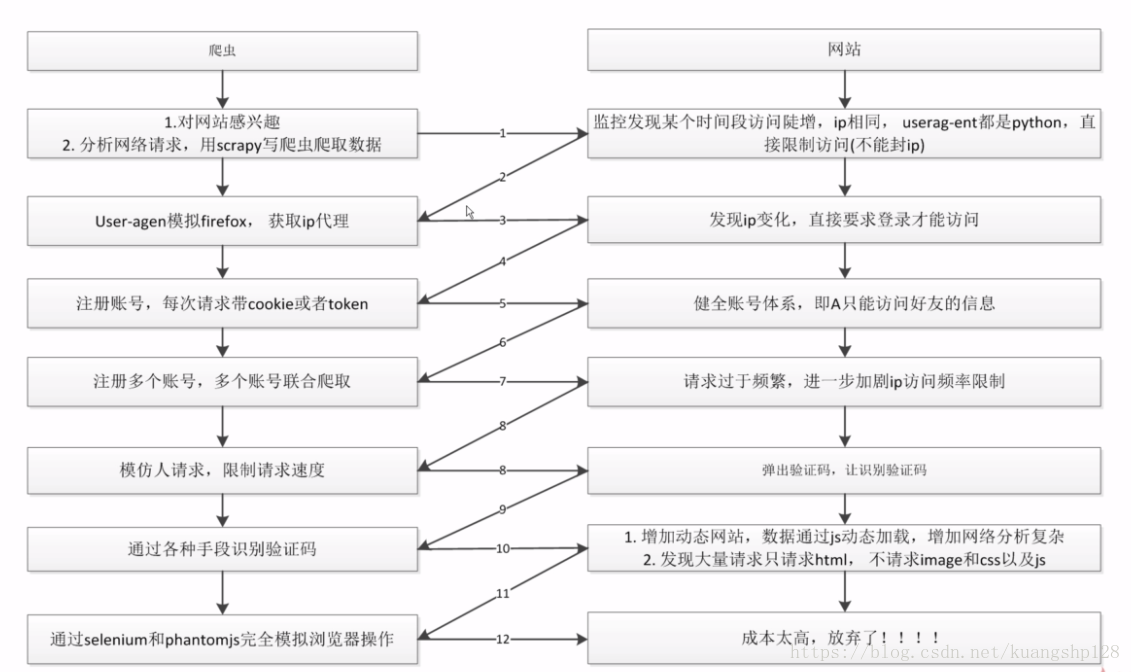
常见的反爬手段
1.检测浏览器headers
2.ip封禁
3.图片验证码
4.滑动模块
5.js轨迹
6.前端反调试
7.js加密算法

