day34-1 IO模型
IO模型
IO指的是输入输出,对于CPU而言,当我们要输入数据或输出数据通常需要很长一段时间。在这段时间内,CPU就处于闲置状态,造成了浪费浪费。所以学习IO模型,就是为了在等待IO操作的过程中利用CPU执行别的任务
而IO其实有很多类型,例如:socket网络IO,内存到内存的复制copy,等待键盘输入。对比起来,内存的速度大于硬盘的速度大于socket网络IO的速度。所以重点关注socket网络IO
网络IO经历的步骤和过程
操作系统有两种状态:内核态和用户态。
- 内核态:拥有对所有硬件的所有权限
- 用户态:只能操作基础资源,不能操控硬件
当操作系统需要控制硬件时,例如接收网卡上的数据,必须先转换到内核态,接收完数据后再把数据从操作系统缓冲区copy到应用程序的缓冲区,由内核态转为用户态
在这个过程中,从等待数据到达网卡再到系统内核叫做wait_data,从内核态copy到应用程序缓冲区称为copy_data。应用程序在接收数据(如socket.accept()、socket.recv())时,要经历wait_data阶段和copy_data阶段,而在发送数据(如socket.send())时,只经历copy_data阶段
补充:
buffer缓冲:是将数据读入到内存所使用的空间。为了降低IO次数提高效率
cache缓存:从内存中读取数据,存放数据的空间。为了提高读取效率
阻塞IO(blocking IO)
之前写的TCP程序,使用多线程、多进程完成并发都是阻塞IO模型
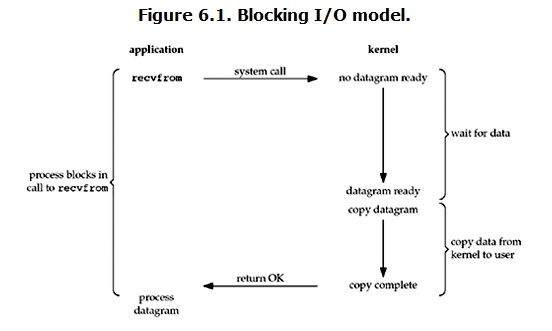
在执行accept/recv时会进入wait_data阶段。进程会主动调用一个block指令,进入阻塞状态,同时让出CPU的执行权。操作系统就会将CPU分配给其他的任务,来提高CPU的利用率
当数据到达时,首先会从内核将数据copy到应用程序缓冲区,并且socket将唤醒处于自身等待队列中的所有进程
# 阻塞IO
from socket import *
s = socket()
s.bind(('127.0.0.1', 8000))
s.listen(5)
while True:
conn, addr = s.accept()
while True:
try:
data = conn.recv(1024)
print('来自客户端:', data.decode('utf8'))
conn.send(data.upper())
except ConnectionResetError:
break
非阻塞IO(non-blocking IO)
非阻塞IO模型与阻塞IO模型相反,将原本阻塞的socket设置为非阻塞,在调用recv/accept时不会阻塞当前线程。
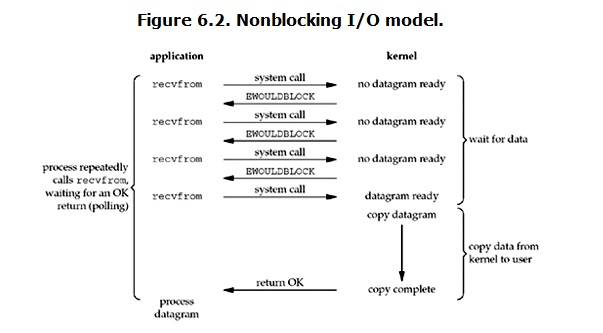
也就是说非阻塞的recvfrom系统调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvfrom系统调用。重复上面的过程,循环往复的进行recvfrom系统调用。这个过程被称作轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。拷贝数据整个过程,进程仍然是属于阻塞的状态。
总结:该模型在没有数据到达时,进程并没有被阻塞,而是会抛出异常,我们需要捕获异常,然后继续不断地询问系统内核直到,数据到达为止。这种模型会大量占用CPU资源做一些无效的循环,效率低于阻塞IO
import time
from socket import *
s = socket()
# 设置为非阻塞模型
s.setblocking(False) # False表示不阻塞
s.bind(('127.0.0.1', 8000))
s.listen(5)
cs = [] # 保存所有的客户端socket
msgs = [] # 保存发送的数据
print('start...')
while True:
time.sleep(0.5)
try:
conn, addr = s.accept() # 完成三次握手
print(f'连接客户端{addr}成功')
cs.append(conn)
except BlockingIOError:
print('还没有客户端来连接')
# 没有客户端连接,可以处理通信循环收发数据
# 处理接收数据
for c in cs[:]:
try:
data = c.recv(1024)
if not data:
raise ConnectionResetError
print('来自客户端数据:', data.decode('utf8'))
msgs.append((c, data.upper()))
except BlockingIOError:
print('客户端没发数据')
except ConnectionResetError:
c.close()
cs.remove(c)
# 处理发送数据
for i in msgs[:]:
try:
i[0].send(i[1])
msgs.remove(i)
except BlockingIOError:
pass
except ConnectionResetError:
# 关闭连接
i[0].close()
# 删除数据
msgs.remove(i)
# 删除连接
cs.remove(i[0])
多路复用IO(IO multiplexing)
它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,它的流程图
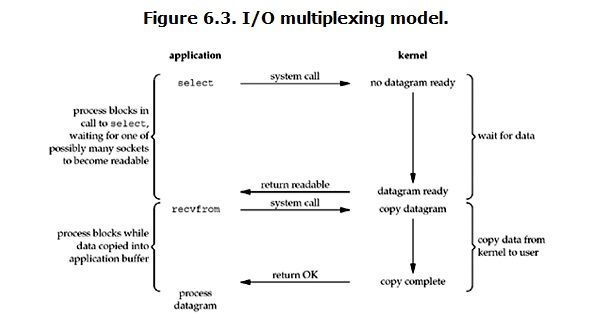
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
# 用selec()实现多路复用IO
from socket import *
import select
s = socket()
s.bind(('127.0.0.1', 8000))
s.listen(5)
r_list = [s] # 待检测是否可读的列表
w_list = [] # 待检测是否可写的列表
msgs = {} # 待发送的数据
print('开始检测了')
while True:
read_ables, write_ables, _ = select.select(r_list, w_list, [])
print('检测出结果了!')
# 处理可读 也就是接收数据的
for obj in read_ables: # 拿出所有可以读数据的socket
# 有可能是服务端 有可能是客户端
if obj == s: # 服务器
print('来了一个客户端要连接')
c, addr = s.accept()
r_list.append(c) # 新的客户端也交给select检测
else: # 如果是客户端,则执行接收数据
try:
print('客户端发来一个数据')
data = obj.recv(1024)
if not data:
raise ConnectionResetError
print('有个客户端说:', data)
# 将要发送数据的socket加入到列表中让select检测
w_list.append(obj)
# 将要发送的数据丢到容器中
if obj in msgs: # 由于容器是一个列表,所以需要先哦安短是否已经存在列表中
msgs[obj].append(data)
else:
msgs[obj] = [data]
except ConnectionResetError:
obj.close()
r_list.remove(obj)
break
# 处理可写的,也就是send发送数据
for obj in write_ables:
msg_list = msgs.get(obj)
if msg_list:
# 遍历发送所有的数据
for m in msg_list:
try:
obj.send(m.upper())
except ConnectionResetError:
obj.close()
w_list.remove(obj)
break
# 数据从容器中删除
msgs.pop(obj)
# 将这个socket从w_list中删除
w_list.remove(obj)
多路复用对比非阻塞 ,多路复用可以极大降低CPU的占用率
注意:多路复用并不完美 ,因为本质上多个任务之间是串行的,如果某个任务耗时较长将导致其他的任务不能立即执行。 优势就是高并发,可以同时处理多个连接,不适用于单个连接
异步IO(Asynchronous IO)
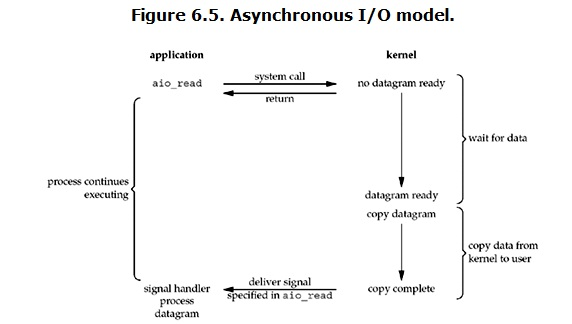
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
非阻塞IO不等于异步IO,因为copy的过程是一个同步任务,会卡主当前线程。而异步IO是发起任务后就可以继续执行其他任务,当数据已经copy到应用程序缓冲区,才会给你的线程发送信号或者执行回调
信号驱动IO模型
就是当某个事情发生后,会给你的线程发送一个信号,你的线程就可以去处理这个任务。但是因为socket的信号太多,处理起来非常繁琐,所以不常用

