mysql总结:存储引擎,树的区别,索引,性能分析,锁,事务,大批量数据插入优化
常见存储引擎
-
Myisam:5.5之前默认引擎,支持表锁,不支持外键和事务,访问速度快
-
InnoDB:支持事务,外键,支持行级锁,5.5之后默认存储引擎,5.6之后支持全文索引
-
Memory:所有数据置于内存中,拥有极高的效率,但是重启数据会丢失,默认hash索引
-
Archive:拥有很快的插入速度,但是查询相对差劲
-
Federated:将不同的mysql服务器联合,逻辑形成一个完整的数据库,适合分布式场景
逻辑存储结构
-
表空间:ibd文件
-
段:数据段,索引段,回滚段
-
区:每个区1M,一个区64页
-
页:存储引擎磁盘管理的最小单元,每页16k,
-
行除了定义字段,还包含隐藏字段,事务id,回滚指针,隐藏主键id(没有主键情况下)
-
每次申请四到五个区,以保证页的连续性
2、树的区别
-
二叉树:可能产生不平衡,顺序数据可能会出现链表结构,层级太深
-
平衡二叉树:需要频繁自旋,维护结构,性能根据层级而定,性能不稳定
-
b+tree:
-
主键聚簇叶子节点存放索引和数据(单向链表维护叶子节点,MySQL优化为了双向链表),非叶子节点存放索引,便于区间查询,排序
-
插入演示:
- 红黑树:
- 层级不确定,无法评估除响应时间
- 不支持范围查询
-
二级索引非叶子节点存放索引,叶子节点存放索引和主键
3、索引
索引概述
-
索引是高效获取数据的数据结构
索引结构
-
B+Tree(),两层1.8w,三层可存储2200w左右记录
-
Hash(不支持范围查询,无法利用索引完成排序,精准匹配效率极高,只需匹配一次即可定位到数据)
索引优缺点
优点
-
大大加快查询速度
-
使用分组和排序时候可以显著减少分组和排序时间
-
唯一索引可以保证字段唯一
-
可以加速表与表之间的连接
缺点
-
创建和维护索引需要消耗时间,随着数据量增加时间也会增加
-
占用磁盘空间
-
对表进行urd操作时候也要动态维护,urd性能会下降
创建索引原则(我们对哪种数据创建索引)
-
数据量少的没必要创建,全表和用索引可能差不多
-
表层面:数据量大,且查询频繁,更新不频繁
-
字段层面:经常在where groupby orderby后的字段
-
索引层: 唯一的建立唯一索引,尽量联合索引,大文本尽量前缀索引
-
附加原则:
-
区分度较高
-
-
索引不易过多
-
索引不为null加上非空约束
-
索引长度尽量短
索引分类
按结构
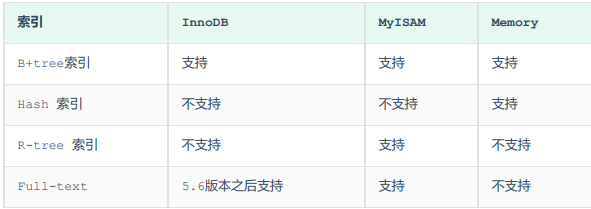
按类型
-
主键索引:唯一且不为null,一个表只能有一个,(聚集索引:叶子节点下存储索引和数据,必须有,且只有一个)
-
唯一索引:唯一且只能有一个Null值(二级索引,叶子节点存储索引和主键)
-
普通索引:没有限制(二级索引,叶子节点存储索引和主键)
-
全文索引:like+%(InnoDB(5.6之后支持)默认3个字符,最大84,MyISam默认4最小1个字符)
按存储形式
聚集索引:必须有,且只有一个,没有会使用唯一索引聚簇,都没有则创建隐藏主键,叶子节点下存放行数据
二级索引:可以多个,叶子节点存放主键id,会回表查询,创建联合索引设计好的话,可避免回表
联合索引
-
对经常查询的多个字段创建组合索引
sql提示
-
多个索引下,可以提醒执行器使用哪个索引,建议使用,忽略使用,强制使用
覆盖索引
-
查询返回字段都在联合索引中会直接拿到数据,无需拿到主键再去回表查询数据
-
针对字段数据库较大的建立索引,缩小索引长度
单列/联合索引
-
避免单列索引在and情况下第二索引不生效,使用联合索引
索引失效
-
索引列进行了函数运算
-
没有遵循最有匹配原则
-
字符串类型索引没有加' ',造成隐士转换,导致索引失效
-
如果联合索引,最左满足,但是使用中间跳过了某个索引字段,会造成后面索引失效
-
范围查询右侧的列会失效,尽量是<= ,>=
-
mysql优化器判定全表比用索引块
-
or链接索引失效
4、性能分析
数据库的执行频次
- show session status like 'Com_____'; --查询当前会话统计结果 - show global status like 'Com_____'; --查询字数据库上次启动至今的结果 - show status like 'Innodb_rows_%';
慢查询日志
-- 查看慢日志配置信息 show variables like '%slow_query_log%’; -- 开启慢日志查询 set global slow_query_log=1; -- 查看慢日志记录SQL的最低阈值时间 show variables like 'long_query_time%’; -- 修改慢日志记录SQL的最低阈值时间 set global long_query_time=4;
profile Sql执行查询
explain/desc执行计划查询
- 字段含义
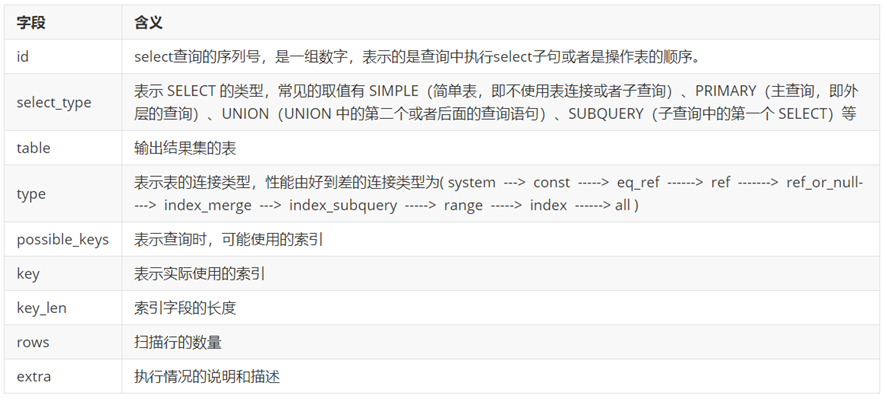
-
-
id 相同表示加载表的顺序是从上到下。
-
id 不同id值越大,优先级越高,越先被执行。
-
id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
-
-
type含义
![]()
-
extra含义
![]()


5、锁机制
锁的分类
按粒度分
-
全局锁:锁定全局,用于数据备份保证数据库完整性
-
表锁(加锁快,并发低,不会死锁):
-
表锁:锁定整张表
-
元数据锁:为了避免DML与DDL冲突,保证读写正确性
-
意向锁:为了避免加表锁时候,全局扫描行锁
-
-
行锁(加锁慢,锁冲突低,并发高,会死锁)
-
行锁:锁定单行数据
-
间隙锁:防止其他事务插入间隙,间隙锁可以共存,一个事务间隙锁,不影响另一个事务在同一间隙加锁
-
索引上等值查询(唯一索引),给不存在的数据加锁时,会优化为间隙锁
-
索引上等值查询(非唯一索引),向后遍历时最后一个值不满足查询需求时,会退化为间隙锁
-
-
临键锁:锁定当前数据和间隙(行锁+间隙锁)
-
索引上范围查询(唯一索引),会访问到不满足条件的第一个值为止
-
-
按类型分
-
读锁(共享):阻塞写,可读
-
写锁(排他):阻塞读写
行锁升级
-
行锁时针对唯一索引进行检索的,对已存在的记录进行等值匹配时,将自动优化为行锁
-
不通过索引条件检索数据时,行锁则会升级为表锁
6、事务
事务特性
-
-
一致性:事务完成后,必须使所有的数据都保持一致状态
-
隔离性:事务之间互不影响
-
持久性:事务一旦提交或者回滚,对数据库中的数据改变时永久的
事务隔离级别
-
读未提交:一个事务可以读取另一个事务未提交的数据(脏读,不可重复读,幻读)
-
读已提交:可读取另一个事务已经提交的事务(不可重复读,幻读)
-
可重复读(默认):事务开启时不在允许修改操作,可避免脏读,不可重复读但是会造成(幻读)
-
串行化:最高事务隔离级别,效率低下
事务原理
-
原子性:undo_log(逻辑日志),通过回滚日志保证事务原子性,不仅回滚需要,快照读也需要,不会立即删除
-
持久性:redo_log(物理日志),缓冲区的脏页刷新到磁盘的过程当中出现问题,通过redo_log进行回滚保证数据的持久性,只在回滚时需要,事务结束可被立即删除
-
一致性:undo_log+redo_log
-
隔离性:锁+mvcc(多版本并发控制)
MVCC
-
作用:快照读时候,通过mvcc来查找对应的历史版本
-
实现组件:
-
记录隐藏字段(最后一次修改事务id,回滚指针)
-
undo_log版本链(头部最新记录,尾部最老)
-
readView(当前活跃事务id集合,最小活跃事务id,预分配事务id,当前最大事务id+1,readView创建者的事务id)
-
7、大批量数据插入优化
主键顺序插入
批量插入减少IO,批量最好500左右
load加载数据至数据结构
-- 1、首先,检查一个全局系统变量 'local_infile' 的状态, 如果得到如下显示 Value=OFF,则说明这是不可用的 show global variables like 'local_infile'; -- 2、修改local_infile值为on,开启local_infile set global local_infile=1; -- 3、加载数据 /* 脚本文件介绍 : sql1.log ----> 主键有序 sql2.log ----> 主键无序 */ load data local infile 'D:\\sql_data\\sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n';
关闭唯一性校验,加载后再打开
-- 关闭唯一性校验 SET UNIQUE_CHECKS=0; truncate table tb_user; load data local infile 'D:\\sql_data\\sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n'; SET UNIQUE_CHECKS=1;
减少事务,批量执行数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号