

4.1鸭子类型
当看到一只鸟走起来像鸭子、游泳像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子
python类部将各种魔法函数进行了一个组合,就组成了各种各样的对象。
4.2抽象基类(abc模块)
判断某一个对象是否有某一个属性,hasattr()
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __getitem__(self, item):
return self.employee[item]
def __len__(self):
return len(self.employee)
print(hasattr(Company, "__len__"))
company = Company(['tom', 'bob', 'jane'])
print(hasattr(company, "__len__"))
判断某一个对象是否是某种类型,isinstance()
对于判断对象是否可以调用某函数,更好的方法是去判断其是否是某种类型,而不是该对象是否有某个属性。
# 在某些情况下希望判定某个对象的类型,我们需要强制某个子类必须实现某些方法
from collections.abc import Sized
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __getitem__(self, item):
return self.employee[item]
def __len__(self):
return len(self.employee)
company = Company(['tom', 'bob', 'jane'])
print(isinstance(company, Sized))
# 设计一个抽象基类,指定子类必须事项某些方法
# 实现一个web框架,集成cache(redis, cache, memorychache)
class CacheBase():
def get(self, key):
raise NotImplementedError
def set(self, key, value):
raise NotImplemnetedError
class RedisCache(CacheBase):
pass
redis_cache = RedisCache()
redis_cache.set("key", "value")
报错如下示:
# 作如下更改
class RedisCache(CacheBase):
def __init__(self):
self.dic = {}
def get(self, key):
return self.dic[key] if key in self.dic else None
def set(self, key, value):
self.dic[key] = value
redis_cache = RedisCache()
redis_cache.set("key", "value")
print(redis_cache.get("key"))
4.3使用instance而不是type
- type判断一个对象是谁的实例
- isinstance是判断这个对象的继承链,isinstance(a,b)如果a在b的下方就返回True,否则False
class A(object):
pass
class B(A):
pass
class C(B):
pass
c = C()
print(type(c)) # <class '__main__.C'>
print(type(C)) # <class 'type'>
print(isinstance(C, B)) # False
print(isinstance(C, object)) # True
print(isinstance(c, C)) # True
print((isinstance(c, A))) # True
PS: 可以看到子类的实例不仅是子类的类型,也是继承的父类的类型。
isinstance()判断的是一个对象是否是该类型本身,或者位于该类型的父继承链上。
能用type()判断的基本类型也可以用isinstance()判断,并且还可以判断一个变量是否是某些类型中的一种。
print(isinstance('a', str)) # True
print(isinstance(123, int)) # True
print(isinstance(b'a', bytes)) # True
print(isinstance([1, 2, 3], (list, tuple))) # True
print(isinstance((1, 2, 3), (list, tuple))) # True
一般情况下,在判断时,我们优先使用isinstance()判断类型。
4.4类属性和实例属性以及查找顺序
先实例属性再类属性
如果把实例看成是类,那么类变量就是父类中的属性,而实例变量是子类的属性,子类中没有父类有 会从父类中继承,子类中有父类有 相当于覆盖重写
class A:
name = 'bb'
def __init__(self, x):
self.x = x
a1 = A(1)
a2 = A(2)
print(a1.name) #继承类变量bb
print(a1.x) # 就是实例变量x的值
print(A.name) # 类变量bb
A.name = 'dd' # 更改了类变量
print(A.name) # 类变量发生更改dd
print(a1.name) # 实例的类变量也更改dd
a1.name = 'name'
print(a1.name) # 在此更改类变量
print(A.name) # 删除了实例属性
A.name = 'last' # 在此更改了类变量
del a1.name # 删除了实例变量
print(a1.name) # 继承类变量last
类变量和属性的调用顺序:
在python中,为了重用代码,可以使用在子类中使用父类的方法,但是在多继承中可能会出现重复调用的问题,支持多继承的面向对象编程都可能会导致钻石继承(菱形继承)问题 ,如下示:
class A():
def __init__(self):
print("进入A…")
print("离开A…")
class B(A):
def __init__(self):
print("进入B…")
A.__init__(self)
print("离开B…")
class C(A):
def __init__(self):
print("进入C…")
A.__init__(self)
print("离开C…")
class D(B, C):
def __init__(self):
print("进入D…")
B.__init__(self)
C.__init__(self)
print("离开D…")
d = D()
# 实际上会先找B, 然后找A, 然后是C, 再找A
'''
进入D…
进入B…
进入A…
离开A…
离开B…
进入C…
进入A…
离开A…
离开C…
离开D…
'''
钻石继承(菱形继承)会带来什么问题?
多重继承容易导致钻石继承(菱形继承)问题,上边代码实例化 D 类后我们发现 A 前后进入了两次。另外,假设 A 的初始化方法里有一个计数器,那这样 D 一实例化,A 的计数器就跑两次(如果遭遇多个钻石结构重叠还要更多),很明显是不符合程序设计的初衷的(程序应该可控,而不能受到继承关系影响)。
如何避免钻石继承(菱形继承)问题?
为解决这个问题,Python 使用了一个叫“方法解析顺序(Method Resolution Order,MRO)”的东西,还用了一个叫 C3 的算法。
MRO 的顺序基本就是:在避免同一类被调用多次的前提下,使用广度优先和从左到右的原则去寻找需要的属性和方法。有则调用,没有就查找添加到MRO中。
在继承体系中,C3 算法确保同一个类只会被搜寻一次。例子中,如果一个属性或方法在 D 类中没有被找到,Python 就会搜寻 B 类,然后搜索 C类,如果都没有找到,会继续搜索 B 的基类 A,如果还是没有找到,则抛出“AttributeError”异常。
可以使用 类名.mro 获得 MRO 的顺序(注:object 是所有类的基类,金字塔的顶端):
print(D.mro())
# [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
为了防止多继承中的一些问题,使用C3算法解决,它能够保证调用链中所有的类仅出现一次,也就是说每个节点后面的类都不继承它,否则将它从调用链中删除,D.mro()查看调用链。
而super()的使用就是基于这条调用链,当使用super()时,会查找调用链,找到当前类,调用下一个类,没有则找下一个。super()默认是当前类,也可以写类名
class A():
def __init__(self):
print("进入A…")
print("离开A…")
class B(A):
def __init__(self):
print("进入B…")
super().__init__()
print("离开B…")
class C(A):
def __init__(self):
print("进入C…")
super().__init__()
print("离开C…")
class D(B, C):
def __init__(self):
print("进入D…")
super().__init__()
print("离开D…")
d = D()
'''
进入D…
进入B…
进入C…
进入A…
离开A…
离开C…
离开B…
离开D…
'''
4.4.1mro序列
参考博客:https://mp.weixin.qq.com/s?src=11×tamp=1606794886&ver=2739&signature=*SRS5nobqUFoRtzuAsoe8pOknkOYeNxLZz90*OnfG3sQtaaMcaI23ZYMSjmGLKogS997A1whxzOgqTugCvuNSlEz5akZ86QE4myAw2JboDp-DRHrsLiWKCj97Ld2lKTq&new=1
MRO的局限性:类型冲突时, 子类改变了基类的方法搜索顺序。而 子类不能改变基类的方法搜索顺序。在 Python 2.2 的 MRO 算法中并不能保证这种单调性,它不会阻止程序员写出上述具有二义性的继承关系,因此很可能成为错误的根源。
- MRO(Method Resolution Order: 方法解析顺序) 是一个有序列表L,在类被创建时就计算出来。
- 通用的计算公式:
mro(Child(Base1, Base2)) = [Child] + merge(mro(Base1), mro(Base2), [Base1, Base2])
(其中Child继承自Base1, Base2)
- 如果继承至一个基类:class B(A)
这时B的mro序列为 :
mro( B )
= mro( B(A) )
= [B] + merge( mro(A) + [A] )
= [B] + merge( [A] + [A] )
= [B,A]
- 如果继承至多个基类:class B(A1, A2, A3 …)
这时B的mro序列
mro(B)
= mro( B(A1, A2, A3 …) )
= [B] + merge( mro(A1), mro(A2), mro(A3) ..., [A1, A2, A3] )
= ...
PS: 计算结果为列表,列表中至少有一个元素即类自己,如上述示例[A1,A2,A3]。merge操作是C3算法的核心。
(参考博客:https://blog.csdn.net/u011467553/article/details/81437780)
4.4.2 表头和表尾
- 表头:
列表的第一个元素 - 表尾:
列表中表头以外的元素集合(可以为空) - 示例
列表:[A, B, C]
表头是A,表尾是B和C
4.4.3 列表之间的+操作
+操作:
list_ = ['A'] + ['B']
print(list_) # ['A', 'B']
4.4.4 merge操作(C3算法)
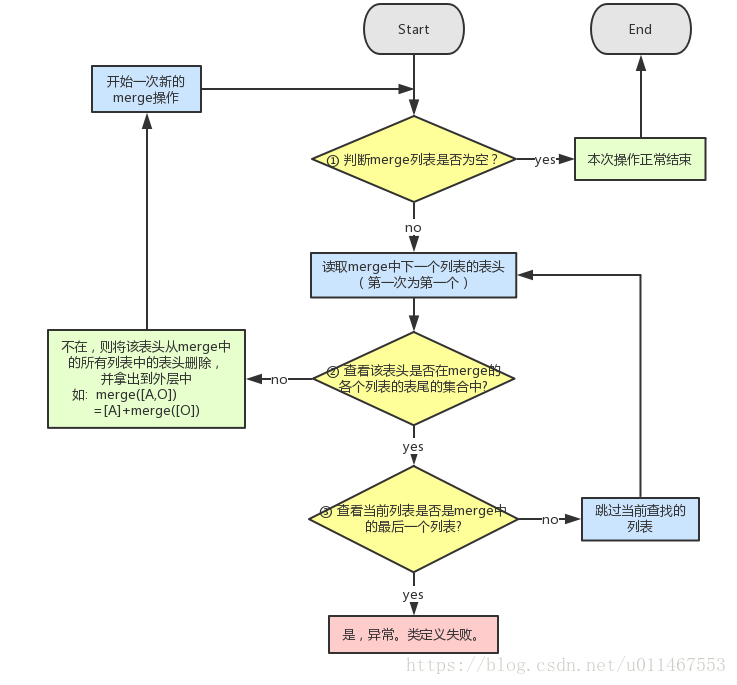
如计算merge( [E,O], [C,E,F,O], [C] )
有三个列表 : list1 list2 list3
1 merge不为空,取出第一个列表列表list1的表头E,进行判断
各个列表的表尾分别是[O], [E,F,O],E在这些表尾的集合中,因而跳过当前当前列表
2 取出列表list2的表头C,进行判断
C不在各个列表的集合中,因而将C拿出到merge外,并从所有表头删除
merge( [E,O], [C,E,F,O], [C]) = [C] + merge( [E,O], [E,F,O] )
3 进行下一次新的merge操作 ......
merge( [E,O], [C,E,F,O], [C])
= [C] + merge( [E,O], [E,F,O] )
= [c] + [E] + merge( [O], [F, 0])
= [c] + [E] + [F] + merge( [O], [0])
= [C] + [E] + [F] + [0]
看看之前的
print(D.mro())
# [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
mro(D(B, C))
= [D] + merge(mro(B(A)), mro(C(A)), [B, C])
= [D] + merge([B] + merge(A(object), [A]), [C] + merge(A(object), [A]), [B, C])
= [D] + merge([B] + merge([A, object], [A]), [C] + merge([A, object], [A]), [B, C])
= [D] + merge([B] + [A, object], [C] + [A, object], [B, C])
= [D] + merge([B, A, object], [C, A, object], [B, C])
= [D] + [B] + merge([A, object], [C, A, object], [C])
= [D] + [B] + [C] + merge([A, object], [A, object])
= [D] + [B] + [C] + [A] + merge([object], [object])
= [D] + [B] + [C] + [A] + [object]
= [D, B, C, A, object]
= [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
4.4.5实战测试: 案例一
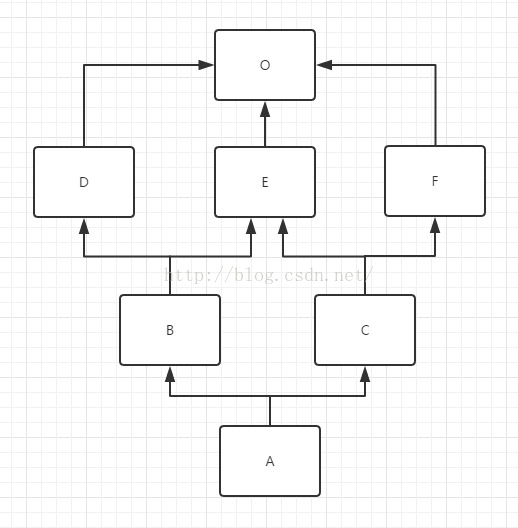
# 备注:O==object, 如何计算mro(A) ?
mro(A)
= mro(A(B, C))
= [A] + merge(mro(B(D, E)), mro(C(E, F)), [B, C])
= [A] + merge([B] + merge(mro(D(O)), mro(E(O)), [D, E]), [C] + merge(mro(E(O)), mro(F(O)), [E, F]), [B, C])
= [A] + merge([B] + merge([D, O], [E, O], [D, E]), [C] + merge([E, O], [F, O], [E, F]), [B, C])
= [A] + merge([B] + [D, E, 0], [C] + [E, F, O], [B, C])
= [A] + merge([B, D, E, 0], [C, E, F, O], [B, C])
merge([D, O], [E, O], [D, E])
= [D] + merge([O], [E, O], [E])
= [D] + [E] + merge([O], [O])
= [D] + [E] + [O]
= [D, E, 0]
merge([E, O], [F, O], [E, F])
= [E] + merge([O], [F, O], [F])
= [E] + [F] + merge([O], [O])
= [E] + [F] + [O]
= [E, F, O]
= [A] + [B] + merge([D, E, 0], [C, E, F, O], [C])
= [A] + [B] + [D] + merge([E, 0], [C, E, F, O], [C])
= [A] + [B] + [D] + [C] + merge([E, 0], [E, F, O])
= [A] + [B] + [D] + [C] + [E] + merge([0], [F, O])
= [A] + [B] + [D] + [C] + [E] + [F]+ merge([0], [O])
= [A] + [B] + [D] + [C] + [E] + [F]+ [O]
= [A, B, D, C, E, F, O]
# 以上案例的代码测试
class D: pass
class E: pass
class F: pass
class B(D,E): pass
class C(E,F): pass
class A(B,C): pass
print("从A开始查找:")
for s in A.__mro__:
print(s)
print("从B开始查找:")
for s in B.__mro__:
print(s)
print("从C开始查找:")
for s in C.__mro__:
print(s)
'''
从A开始查找:
<class '__main__.A'>
<class '__main__.B'>
<class '__main__.D'>
<class '__main__.C'>
<class '__main__.E'>
<class '__main__.F'>
<class 'object'>
从B开始查找:
<class '__main__.B'>
<class '__main__.D'>
<class '__main__.E'>
<class 'object'>
从C开始查找:
<class '__main__.C'>
<class '__main__.E'>
<class '__main__.F'>
<class 'object'>
'''
规律总结: “从一至顶,有子先出”
4.4.6实战测试:案例二
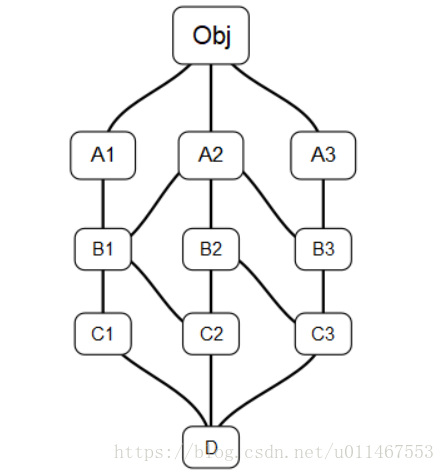
结果参考:

4.5类变量和对象
4.6静态方法、类方法以及对象方法以及参数
- 静态方法:
@staticmethod
和类的关系不是很大,但是又显得不可缺少,较普通函数来说,和类关系密切 - 类方法:
@classmethod
和类的关系密切,接收必须参数cls表示当前类,因为有了cls,所以创建类的时候方便,修改类变量或者修改属性也比较方便 - 实例方法:
它是实例的方法,接收必须参数self,self表示当前实例,因为有self实例,所以在修改实例变量或者属性的时候会很方便
"""
静态方法和类方法和实例方法
静态方法:
- 没有必要参数
类方法:
- 必要参数 cls:默认表示类对象本身
实例方法:
- 必要参数 self: 默认表示实例对象本身
"""
class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
@staticmethod
def parse_from_string(date_str):
year, month, day = date_str.split('-')
# 硬编码,当Date类名修改时,此处的返回值也需要修改
return Date(int(year), int(month), int(day))
@classmethod
def parse_string(cls, date_str):
year, month, day = date_str.split('-')
# 硬编码,当Date类名修改时,此处的返回值也需要修改。此处建议使用类方法
return Date(int(year), int(month), int(day))
def __str__(self):
return "{year}年{month}月{day}日".format(year=self.year, month=self.month, day=self.day)
date = Date(2020, 12, 1)
print(date) # 2020年12月1日
date1 = "2020-1-1"
year, month, day = date1.split('-')
date_str = Date(int(year), int(month), int(day))
print(date_str) # 2020年1月1日
date3 = Date.parse_from_string(date1)
print(date3) # 2020年1月1日
date4 = Date.from_string(date1)
print(date4) # # 2020年1月1日
4.7数据封装和私有属性
Python通过双下划线来实现私有属性 : 但并不是不可查看,只是一种规范 。
实例对象._className__属性名
Python并没有做到从语言的层面保证数据的绝对安全。Java中也不行,反射机制。
# python私有属性
class A:
def __init__(self, x):
self.__x = x
a = A(1)
print(a._A__x) # 1
print(a.x) # AttributeError: 'A' object has no attribute 'x'
私有属性的getter和setter: 通过property来实现
class Rec(object):
def __init__(self, x, y):
self.x = x
self.y = y
self.__z = x * y
@property # 为了让z可以像属性一样调用使用property
def z(self):
return self.__z
@z.setter # 可以使用setter来实现订阅-发布的功能,当新的setter时执行时,for循环遍历订阅者。发布订阅
def z(self, z):
if isinstance(z, int) or isinstance(z, float): # 判断
self.__z = z
else:
raise Exception("z必须是整数或者小数")
rec = Rec(2, 3)
print(rec.z) # 6
rec.z = 4
print(rec.z) # 4
rec.z = 'a' # Exception: z必须是整数或者小数
4.8python对象的自省机制
自省机制是通过一定的机制查询到对象的内部结构
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# @Time : 2020/12/1 19:46
# @Author : RoadGod
# @Project : python_high
# @File : 4.9_自省机制.py
# @Software : PyCharm
class Person:
""" 人 """
name = 'IU'
age = 18
class Student(Person):
def __init__(self, school_name):
self.school_name = school_name
stu = Student('李知恩')
# 通过__dict__查询属性
print(stu.__dict__) # {'school_name': '李知恩'}
# 可以使用__dic__直接去值和赋值
print(stu.__dict__['school_name']) # 李知恩
stu.__dict__['school_addr'] = '重庆市'
print(stu.school_addr) # 重庆市
print(stu.name) # IU
# {'__module__': '__main__', '__init__': <function Student.__init__ at 0x00000256E421DE50>, '__doc__': None}
print(Student.__dict__)
'''
{
'__module__': '__main__',
'__doc__': ' 人 ',
'name': 'IU',
'age': 18,
'__dict__': <attribute '__dict__' of 'Person' objects>,
'__weakref__': <attribute '__weakref__' of 'Person' objects>
}
__module__: 所处模块
__doc__: 文档
name、age: 属性
__weakref__: 弱引用
'''
print(Person.__dict__)
# dir()内置函数,可以查询对象的所有属性名称(没有值)和方法名
'''
['__class__', '__delattr__', '__dict__', '__dir__',
'__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__module__',
'__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__', '__weakref__', 'age', 'name',
'school_addr', 'school_name']
'''
print(dir(stu))
a = [1, 2, 3]
print(dir(a)) # 可以累出list对象的所属性名称和函数名称
print(a.__dict__) # AttributeError: 'list' object has no attribute '__dict__'
4.9super函数
- 一、为何重写了父类的构造函数,还要去调用父类的构造函数?
答:需要用到父类构造函数对某些字段的校验或者其他格外的操作。如线程的名称
from threading import Thread
class MyThread(Thread):
def __init__(self, name, user):
self.user = user
super().__init__(name=name)
- 二、super的执行顺序是怎样的?
super的执行顺序和C3 MRO序列是一致的
4.10django rest framework中对多继承使用的经验
***暂时省略重点,以后补充
mixin模式:组合模式
模式特点:1. Mixin功能单一 2. 不和基类关联,可以和任意基类组合 3.在Minin中不要使用super这种用法
4.11 python中的with语句
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# @Time : 2020/12/1 20:27
# @Author : RoadGod
# @Project : python_high
# @File : 4.11_上下文管理语句.py
# @Software : PyCharm
# try-except-else-finally语句块
# 执行流程
def exe_try():
try:
print("code start")
raise KeyError
return 1
except KeyError:
print("kye Error")
return 2
else:
print("other error")
return 3
finally:
print("finally")
return 4
res = exe_try()
# code start
# kye Error
# finally
# 4
# 将需要返回的值压入栈,最后结果去栈顶元素
print(res)
# 上下文管理器,将上诉代码做了优化
# 最常见的open()上下文管理
# 上下文管理器协议(和魔法函数进行了挂钩):需要实现__enter__ 和 __exit__ 函数
class Sample:
def __enter__(self):
# 获取资源
print("enter")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
# 释放资源
print("exit")
def do_something(self):
# 需要进行的操作
print("doing something")
with Sample() as sample:
sample.do_something()
'''打印的结果如下:
enter
doing something
exit
'''
4.12 contextlib实现上下文管理器
使用contextlib.contextmanager装饰器对函数进行了装饰,使函数变成了上下文管理器
import contextlib
@contextlib.contextmanager
def file_open(file_name):
# 获取资源
print("enter")
# 对资源的各种操作
# 生成器是必要的
yield {}
# 释放资源
print("exit")
with file_open("我的大叔") as fp:
print("do something")
'''结果如下所示:
enter
do something
exit
'''

