hive操作(行转列,列转行)
一、行转列
1.相关函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
2.数据准备
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
3.需求
把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋
4.创建表并导入数据
create table person_info(
name string,//姓名
constellation string,//星座
blood_type string)//血型
row format delimited fields terminated by "\t";
load data local inpath "/home/hadoop/file/ person_info" into table person_info;//导入数据到数据库
5.
select
>
> t1.base,
>
> concat_ws('|', collect_set(t1.name)) name//拼接名字
>
> from
>
> (select
>
> name,
>
> concat(constellation, ",", blood_type) base//拼接星座血型
>
> from
>
> person_info) t1//设置表别名
>
> group by
>
> t1.base;
6.结果截图

二、列转行
1.函数说明
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
2.数据准备
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
3.需求
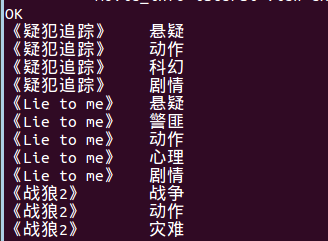
将电影分类中的数组数据展开。结果如下:
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难
4.创建数据库并且导入数据
create table movie_info(
movie string,
category array<string>)
row format delimited fields terminated by "\t"
collection items terminated by ",";‘
load data local inpath "/home/hadoop/file/movie_info" into table movie_info;//讲数据导入到数据库
5.按需求查询
select
>
> movie,
>
> category_name
>
> from
>
> movie_info lateral view explode(category) table_tmp as category_name;
6.显示结果