mediaserver_zlmediakit接收URL的时候如何处理特殊字符的转义
zlmediakit会对http,协议,媒体信息三层分别做解析
测试test1:
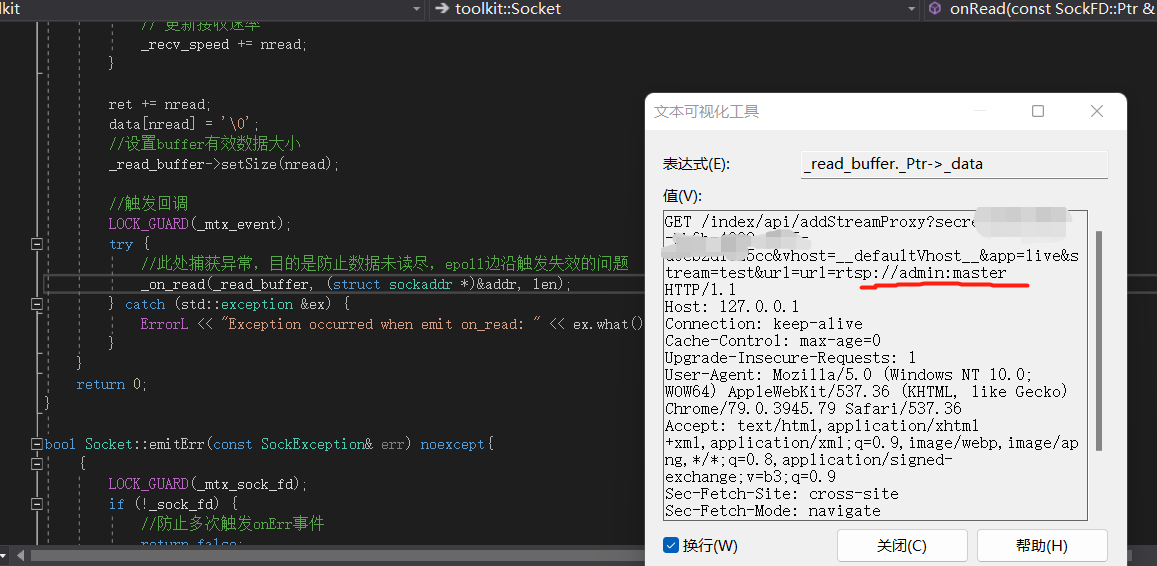
注意你如果从代码层输入这个URL,这里假设你没有对特殊字符进行转义。那么在Http协议接收端,就会把#位置的东西截掉;你送的流媒体URL在解析的时候就会出错
因为密码后边的包括IP,流ID之类的信息都已经没有了;(http协议认为#后边的东西是一个指向性的位置,所以会把#位置及以后的东西截断)
测试2:
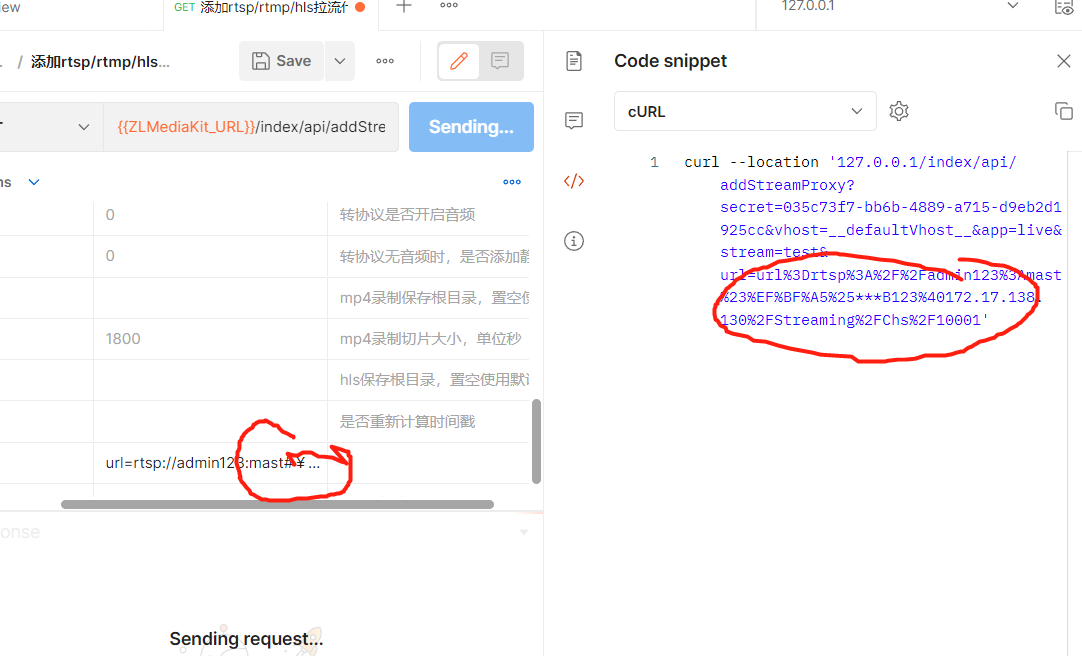
如果你用的是postman ,他在发送前会对你的特殊字符进行转义(编码),还是将上边的URL输入postman,可以看到postman在发送前会对URL中的特殊字符进行编码(注意我这个截图里的URL有点问题 ,多写了一个"url=")
这次ZLmediakit接收到的数据就是编码数据:
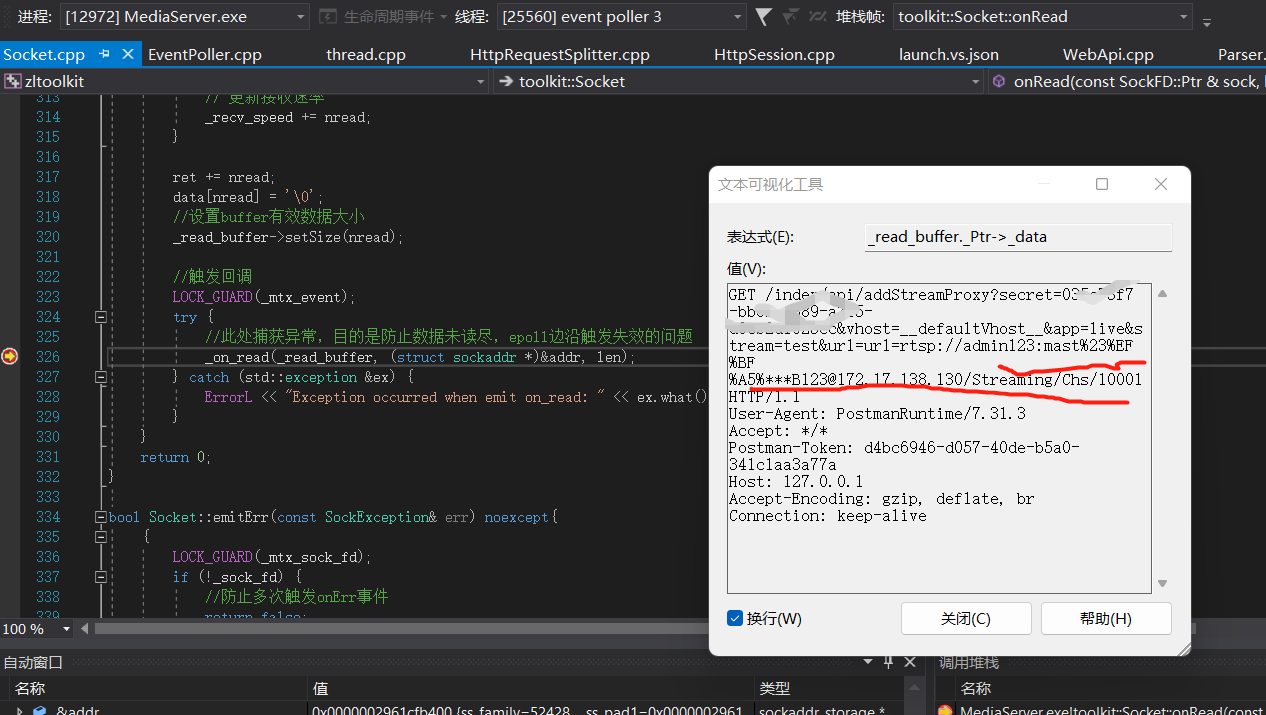
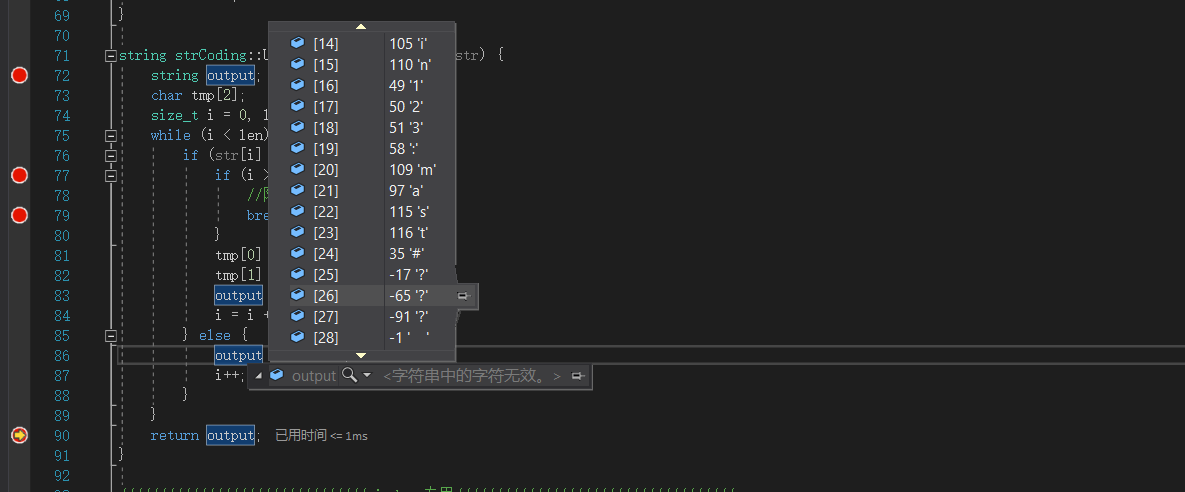
Http层做的第一件事是对Http协议进行拆分,然后会再次对协议进行解码,这里就涉及到 http中的参数map的所有数据进行一次解析,URL,流类型,RTSP-URL
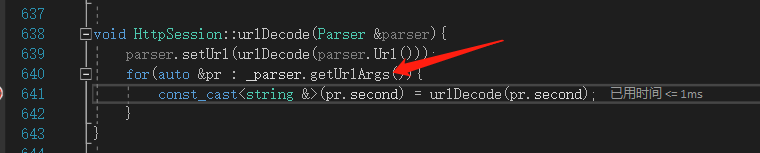
看到了吗,HTTPsession,解析Http协议的时候已经把你输入的编码字符给解码了;
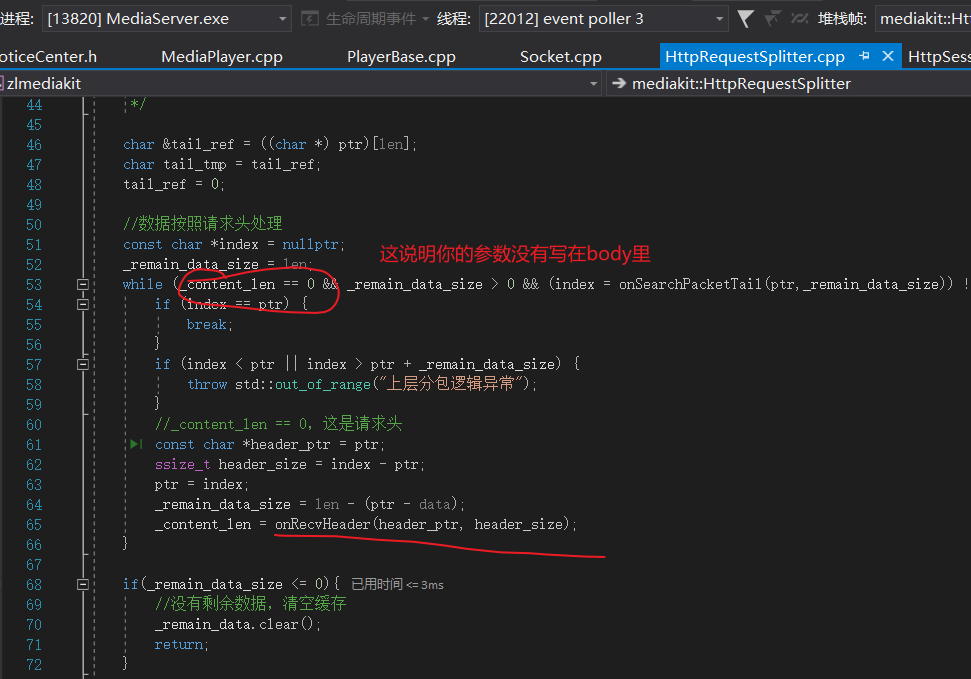

到这里Http链接成功,会继续解析RTSP
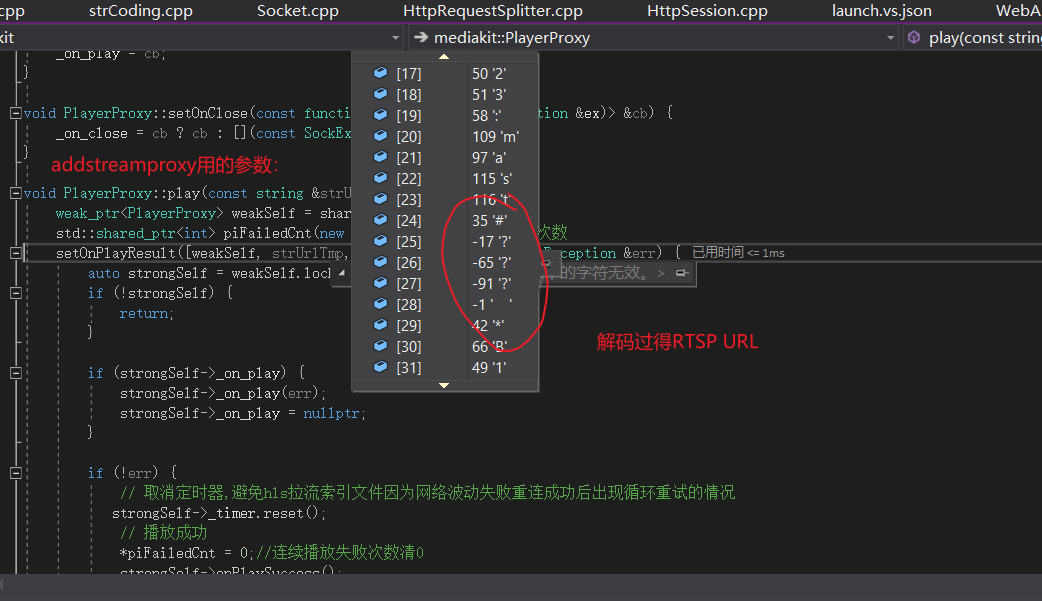
下边的截图我把RTSP的URL的手误改了一下,不过不影响分析;
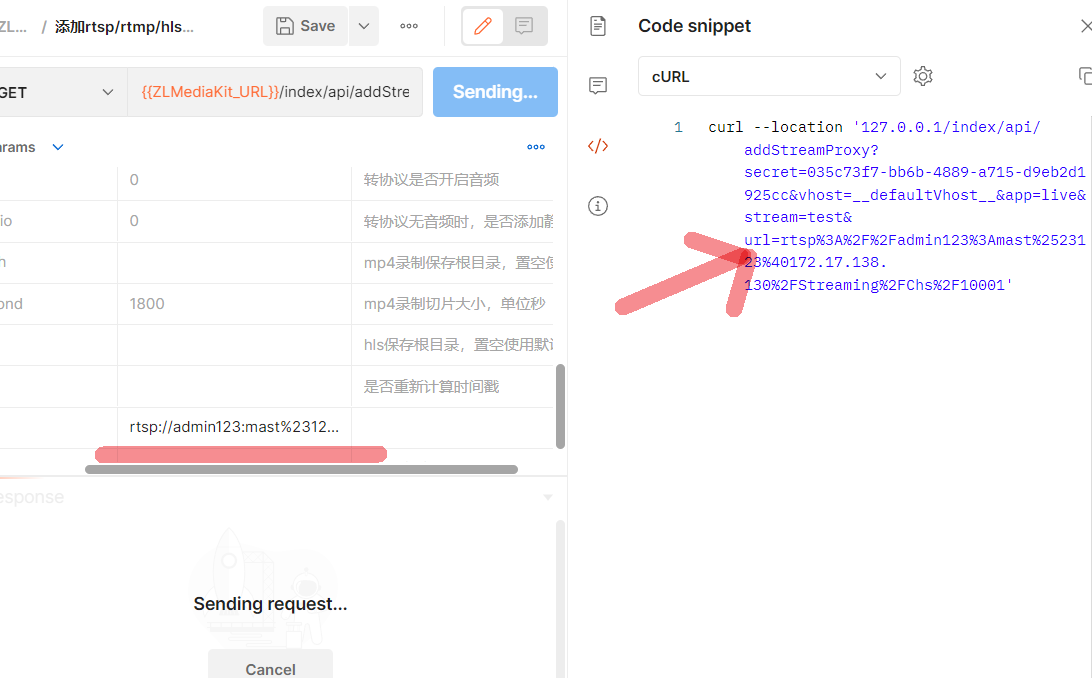
这里在url参数中过滤到rtsp字段,然后创建rtspplayer,然后开始解析RTSP的URL了:
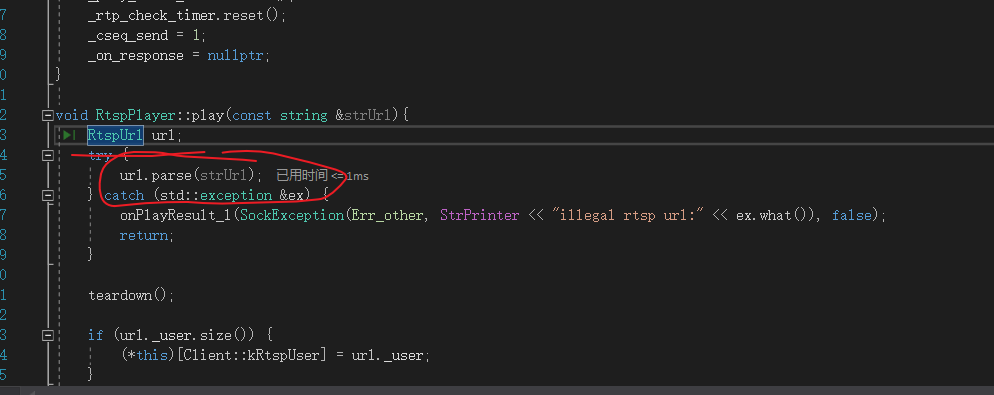
这里解析出RTSP的IP,用户名,和参数:
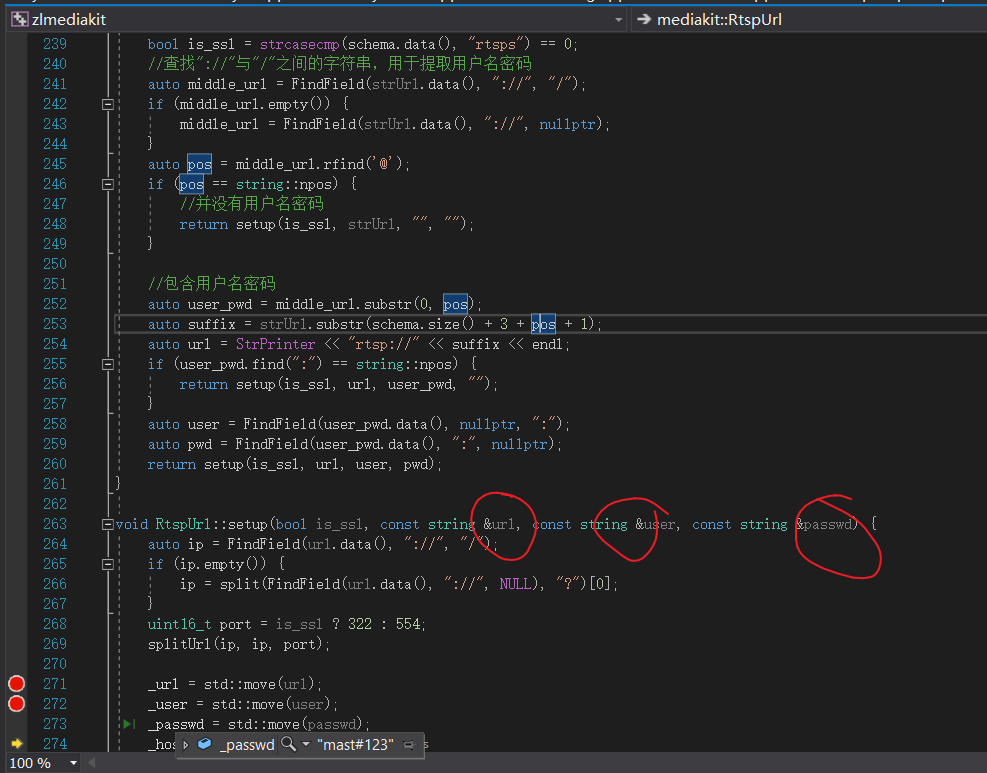
这之后,会进行mediasource解析,会对RTSP的URL进行进一步解析
测试3
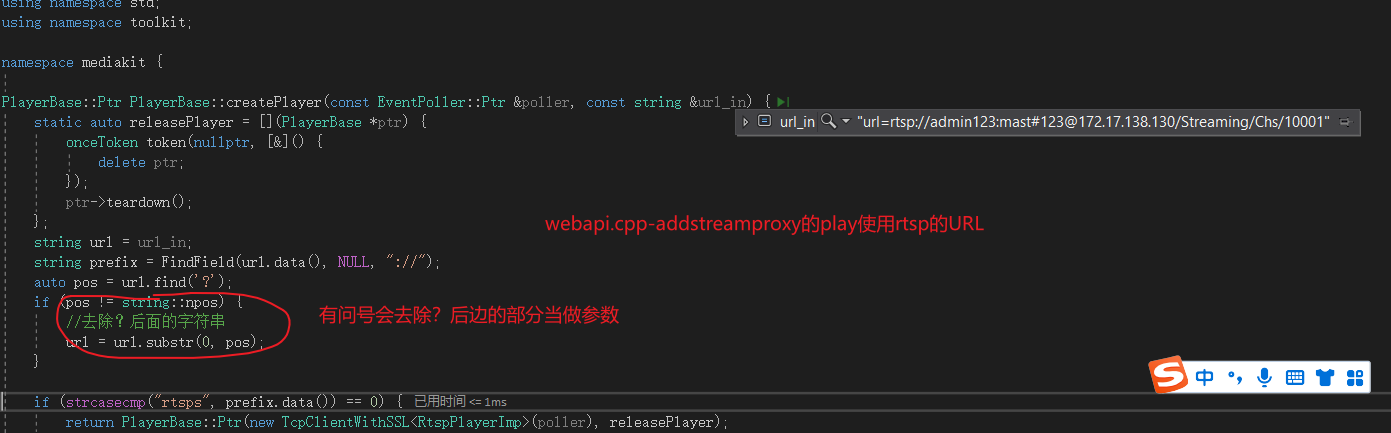
post发addstreamproxy,RTSP的URL用body发
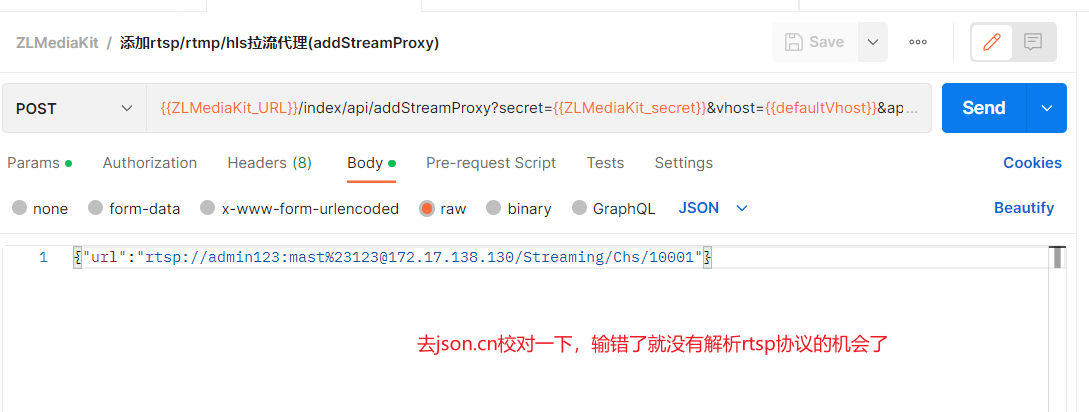
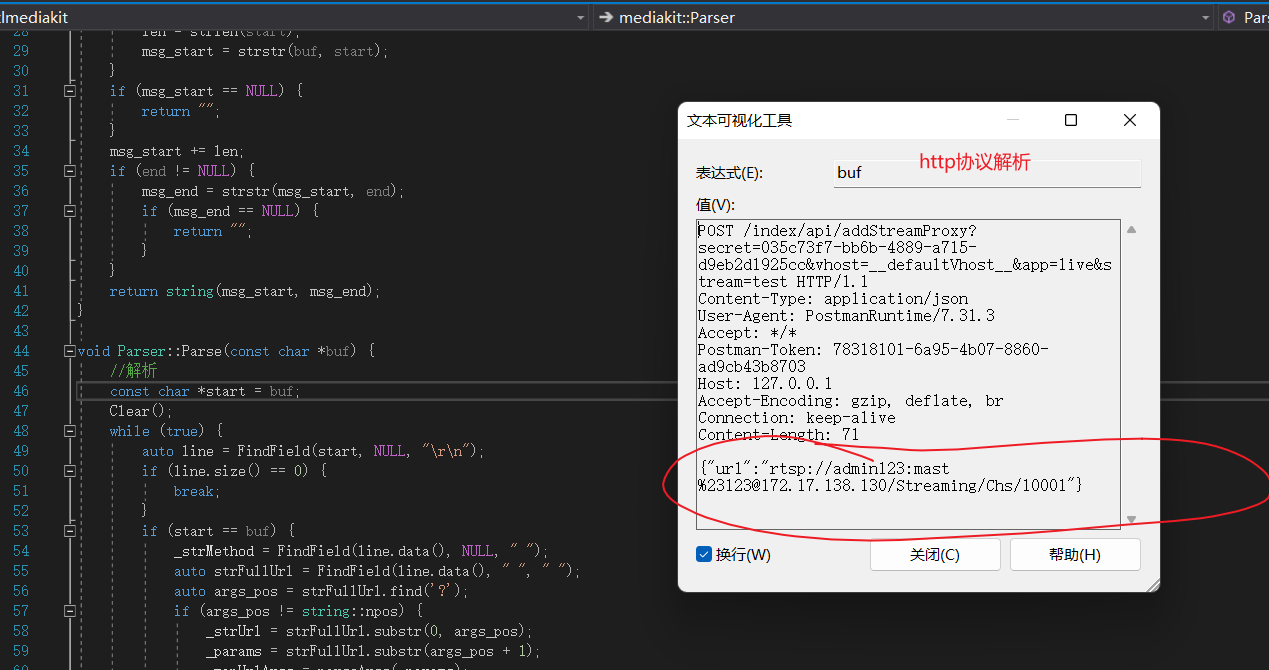
注意,body传参一般用于post请求,body传参时需要在body里写json数组,参数不会显示在地址栏中;body是URL不可见的;
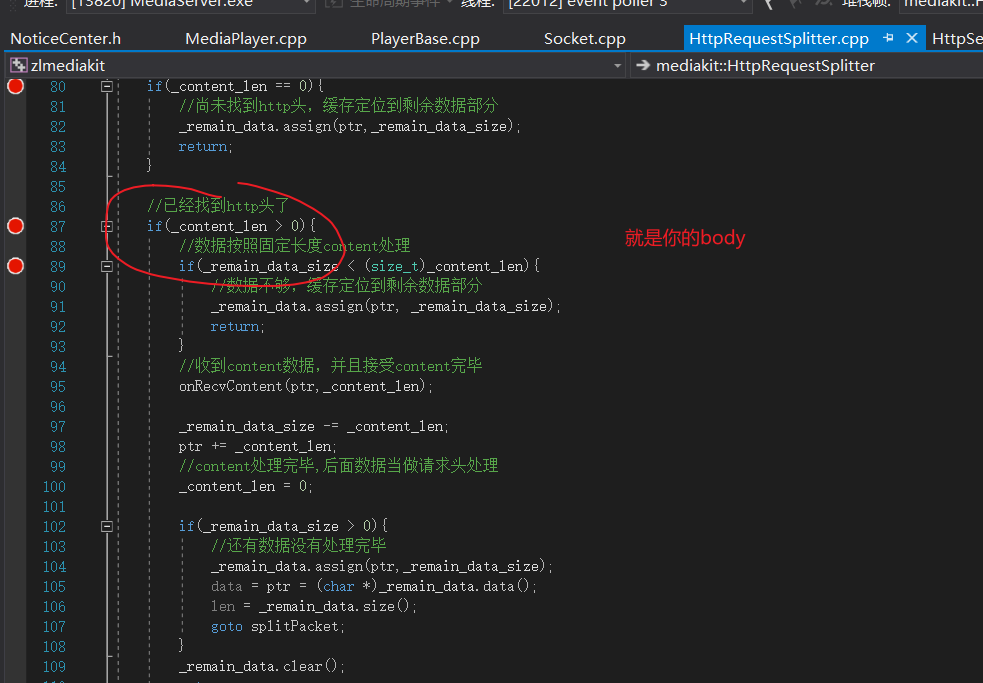
此时这个rtsp url 是从content过来的,是没有解码过得:
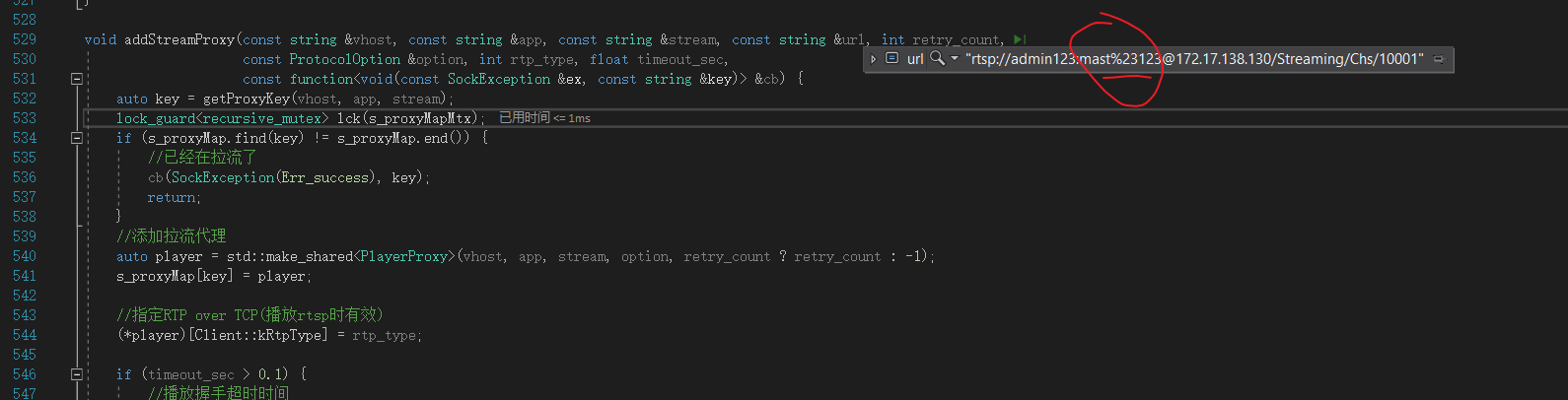
此时在进行rtsp解析得到用户名和密码的时候,你就会发现他其实没有解码%23为#(我们实际用户输入的密码是 mast#123,这里为什么没有解码,因为http层没对content解码)此时的密码其实是不对的,后边用的时候会发现密码错误;出现连接错误

 浙公网安备 33010602011771号
浙公网安备 33010602011771号