
python--day?--常用模块(1)
模块
什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
模块的导入和使用
re模块
re模块与正则的关系
正则表达式本身和python 没有多大关系,就是匹配字符串的一种规则,正则表达式不仅在python的爬虫领域,在整个编程界都占有举足轻重的地位。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
re.match函数
函数语法:
re.match(pattern,string,flags=0)
函数参数说明:
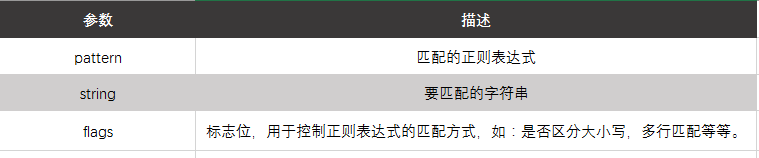
匹配开头成功返回一个匹配对象,否则返回None。


import re print(re.match('8192','8192bit')) #在起始位置 print(re.match('bit','8192bit')) #不在起始位置
我们可以使用group(num)或groups()匹配对象函数来获取匹配表达式,如果对象是None,则报错。

import re line = "Cats are smarter than dogs" matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I) if matchObj: print ("matchObj.group() : ", matchObj.group()) print ("matchObj.group(1) : ", matchObj.group(1)) print ("matchObj.group(2) : ", matchObj.group(2)) else: print ("No match!!")
re.search方法
re.search扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
import re print(re.search('8192','8192bit')) # 在起始位置 print(re.search('bit','8192bit')) # 不在起始位置 输出: <_sre.SRE_Match object; span=(0, 4), match='8192'> <_sre.SRE_Match object; span=(4, 7), match='bit'>
import re line = "Cats are smarter than dogs"; searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I) if searchObj: print ("searchObj.group() : ", searchObj.group()) print ("searchObj.group(1) : ", searchObj.group(1)) print ("searchObj.group(2) : ", searchObj.group(2)) else: print ("Nothing found!!")
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
import re line = "Cats are smarter than dogs"; matchObj = re.match( r'dogs', line, re.M|re.I) if matchObj: print ("match --> matchObj.group() : ", matchObj.group()) else: print ("No match!!") matchObj = re.search( r'dogs', line, re.M|re.I) if matchObj: print ("search --> matchObj.group() : ", matchObj.group()) else: print ("No match!!")
re.findall()
re.findall方法会搜索这个字符串或文本并以列表形式返回所有的匹配。
import re print(re.findall('8192','8192bit')) # 在起始位置 print(re.findall('bit','8192bit')) # 不在起始位置
findall的优先级查询:
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
检索和索引
re.sub()
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
函数参数说明:

import re phone = "2004-959-559 # 这是一个电话号码" # 删除注释 num = re.sub(r'#.*$', "", phone) print ("电话号码 : ", num) # 移除非数字的内容 num = re.sub(r'\D', "", phone) print ("电话号码 : ", num)
当repl为函数时:
import re # 将匹配的数字乘于 2 def double(matched): value = int(matched.group('value')) return str(value * 2) s = 'A23G4HFD567' print(re.sub('(?P<value>\d+)', double, s))
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
正则表达式
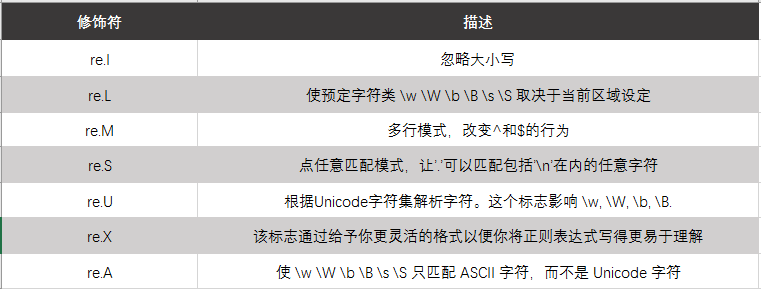
正则表达式修饰符-可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
正则表达式模式
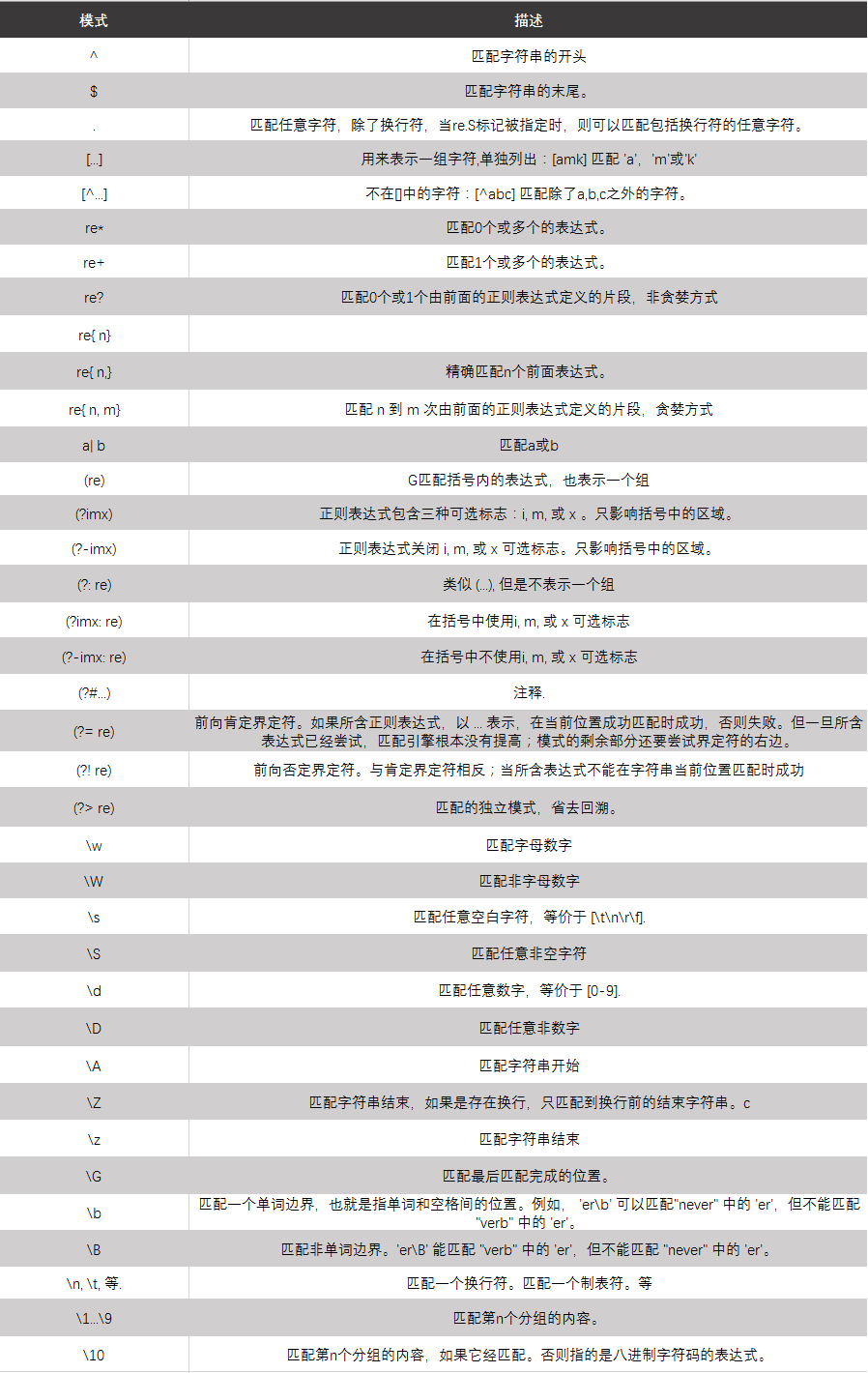
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'/t',等价于'//t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
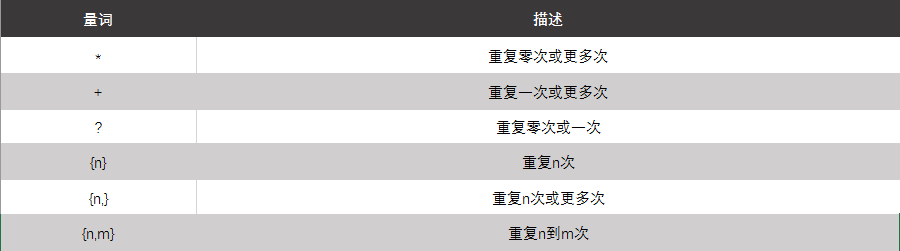
量词:
实例:
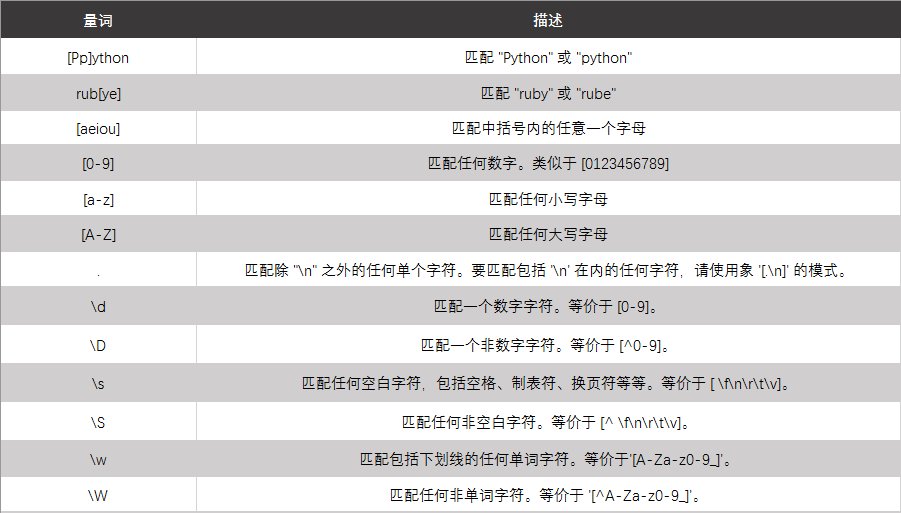
逻辑与分组:

import re ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group('名字')拿到对应的值 print(ret.group('tag_name')) #结果 :h1 print(ret.group()) #结果 :<h1>hello</h1> ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print(ret.group(1)) print(ret.group()) #结果 :<h1>hello</h1>
贪婪匹配:

#实例 import re print(re.findall('ab+','abbbbbbbb')) #贪婪模式 print(re.findall('ab+?','abbbbbbbb')) #非贪婪模式
在线测试工具 http://tool.chinaz.com/regex/
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
这时,namedtuple就派上了用场:

>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
#namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = {} for value in values: if value>66: if my_dict.has_key('k1'): my_dict['k1'].append(value) else: my_dict['k1'] = [value] else: if my_dict.has_key('k2'): my_dict['k2'].append(value) else: my_dict['k2'] = [value] 原生字典解决方法
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in values: if value>66: my_dict['k1'].append(value) else: my_dict['k2'].append(value) defaultdict字典解决方法
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict >>> dd = defaultdict(lambda: 'N/A') >>> dd['key1'] = 'abc' >>> dd['key1'] # key1存在 'abc' >>> dd['key2'] # key2不存在,返回默认值 'N/A'
counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
c = Counter('abcdeabcdabcaba')
print c
输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号