K折验证的使用和python实现
K-fold validation
参考书籍《Deep learning with python》
K 折验证(K-fold validation)将数据划分为大小相同的 K 个分区。对于每个分区 i,在剩余的 K-1 个分区上训练模型,然后在分区 i 上评估模型。最终分数等于 K 个分数的平均值。与留出验证一样,这种方法也需要独立的验证集进行模型校正。
Step0 导入可能需要的包
import numpy as np
from sklearn.metrics import precision_score
from sklearn.svm import LinearSVC
from sklearn.model_selection import KFold
Step1 划分数据集
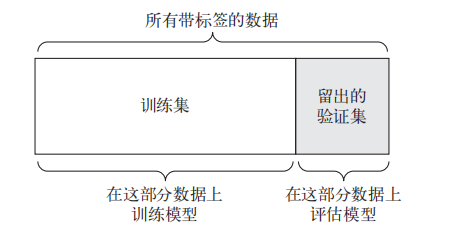
我们同样需要留出一部分测试集,这部分数据不参与任何训练过程。
- 随机打乱原始数据集
- 以8:2的比例分出 非测试数据 和 测试数据。
split_rate = 0.8
class getData(object):
def __init__(self):
data = np.load('Your path')
label = np.load('Your path').ravel()
self.num = len(label)
shuffle_index = np.random.permutation(self.num)
data = data[shuffle_index]
label = label[shuffle_index]
self.train_X = data[:int(self.num * split_rate)]
self.train_y = label[:int(self.num * split_rate)]
self.test_X = data[int(self.num * split_rate):]
self.test_y = label[int(self.num * split_rate):]
data = getData()
Step2 进行K-fold 验证 以及 超参数的调整
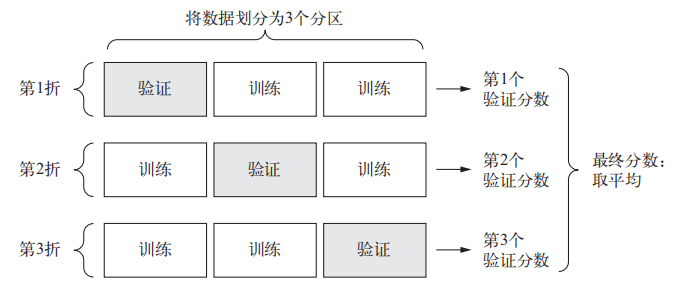
对Step1获得的80%的非测试数据进行k-fold验证:
- 划分数据集为10份,每次选择1份作为验证集,其他9份作为训练集。
- 使用scikit-sklearn的方法来实现。
这里使用LinearSVC作为测试的模型,precision作为评价指标。
kf = KFold(n_splits=10)
kf.get_n_splits(data.train_X)
num_vali = data.num//10 # 每次留出的验证分区数量
vali_scores = [] # 保存每 k 验证的结果
num = 0
for train_index, vali_index in kf.split(data.train_X):
train_X, vali_X = data.train_X[train_index], data.train_X[vali_index]
train_y, vali_y = data.train_y[train_index], data.train_y[vali_index]
model = LinearSVC() # 每折都提供一个没有经历训练的模型
model.fit(train_X, train_y) # 模型进行拟合
pred = model.predict(vali_X) # 模型进行验证
score = precision_score(vali_y, pred) # 记录该折训练效果
print("Fold " + str(num+1) + " ============> Precision:" + str(round(score, 4)))
num += 1
vali_scores.append(score)
vali_score = np.average(vali_scores) # K折验证的平均值
print("Fold_avg ============> Precision:" + str(round(vali_score, 4)))
# 现在,你可以调节模型、重新训练、评估、然后再次调节....
在得到结果后,如果数值不好,可以对模型的超参数进行调整,反复进行这一步。
Step3 测试部分
使用未训练过的数据对你的模型进行测试。
- 在上一步得到合适的超参数后,再提供一个未训练过的模型。
- 对所有非测试数据进行训练,得到一个训练好的模型和模型参数。
- 使用训练好的模型,对未训练过的测试集进行测试。
model = LinearSVC()
model.fit(data.train_X, data.train_y)
pred = model.predict(data.test_X)
test_score = precision_score(data.test_y, pred)
print("Test ============> Precision:" + str(round(test_score ,4)))
完整代码
import numpy as np
from sklearn.metrics import precision_score
from sklearn.svm import LinearSVC
from sklearn.model_selection import KFold
# 1 划分训练集 测试集
split_rate = 0.8
class getData(object):
def __init__(self):
data = np.load('Your path')
label = np.load('Your path').ravel()
self.num = len(label)
shuffle_index = np.random.permutation(self.num)
data = data[shuffle_index]
label = label[shuffle_index]
self.train_X = data[:int(self.num * split_rate)]
self.train_y = label[:int(self.num * split_rate)]
self.test_X = data[int(self.num * split_rate):]
self.test_y = label[int(self.num * split_rate):]
data = getData()
# 2 k-fold 验证和调整超参数
kf = KFold(n_splits=10)
kf.get_n_splits(data.train_X)
num_vali = data.num//10 # 每次留出的验证分区数量
vali_scores = [] # 保存每 k 验证的结果
num = 0
for train_index, vali_index in kf.split(data.train_X):
train_X, vali_X = data.train_X[train_index], data.train_X[vali_index]
train_y, vali_y = data.train_y[train_index], data.train_y[vali_index]
model = LinearSVC() # 每折都提供一个没有经历训练的模型
model.fit(train_X, train_y) # 模型进行拟合
pred = model.predict(vali_X) # 模型进行验证
score = precision_score(vali_y, pred) # 记录该折训练效果
print("Fold " + str(num+1) + " ============> Precision:" + str(round(score, 4)))
num += 1
vali_scores.append(score)
vali_score = np.average(vali_scores) # K折验证的平均值
print("Fold_avg ============> Precision:" + str(round(vali_score, 4)))
# 3 测试数据
model = LinearSVC()
model.fit(data.train_X, data.train_y)
pred = model.predict(data.test_X)
test_score = precision_score(data.test_y, pred)
print("Test ============> Precision:" + str(round(test_score ,4)))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现