
xlrd的使用详细介绍以及基于Excel数据参数化实例详解
1.安装xlrd
xlrd是python用于读取excel的第三方扩展包,所以在使用xlrd前,需要使用以下命令来安装xlrd。pip install xlrd
在使用这个命令之前先确定自己有没有安装pip模块
我们需要在C:\Python27\Scripts这个目录下来执行我们的pip命令
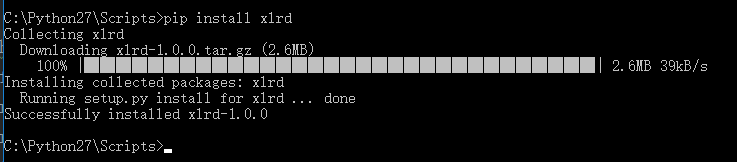
2.使用介绍
- 导入模块
import xlrd - 打开excel表
excel=xlrd.open_workbook("excel.xls")
- 获取表格
#通过索引顺序获取 sytable=excel.sheets()[0] sytable=excel.sheet_by_index(0) #通过工作表名获取 bmtable=excel.sheet_by_name(u"Sheet1")
注意:通过工作表名获取的"Sheet1"是填写你excel中标签"Sheet1","Sheet2","Sheet3"....
- 获取行数和列数
#获取行数 hs=bmtable.nrows #获取列数 ls=bmtable.ncols
- 获取整行货整列的值
#打印第一行的值 rows_values=bmtable.row_values(0) print rows_values #打印第一列的值 cols_values=bmtable.col_values(0) print cols_values
打印结果为:
C:\Python27\python.exe "D:/PyCharm Community Edition 5.0.3/代码/excel.py" [u'\u82b1\u82b1 ', u'\u82b1\u82b1_\u767e\u5ea6\u641c\u7d22'] [u'bb', u'\u82b1\u82b1_\u767e\u5ea6\u641c\u7d22', u'\u563f\u563f_\u767e\u5ea6\u641c\u7d22', u'\u62c9\u62c9_\u767e\u5ea6\u641c\u7d22']
注意:行号,列号是从索引0开始的
- 循环行列表值
#获取行数 hs=bmtable.nrows #通过行数值的多少遍历出表格中的值 for i in range(1,hs): print bmtable.row_values(i)
- 单元格
cell_a1=bmtable.cell(0,0).value print cell_a1 cell_b4=bmtable.cell(3,1).value print cell_b4
打印结果:
C:\Python27\python.exe "D:/PyCharm Community Edition 5.0.3/代码/excel.py" aa 拉拉_百度搜索
表格信息
注意:索引是从0开始的,cell(3,1)的格式是cell(行row,列col)
总结示例:将表格中的所有的数值打印出来(表格还是上图的表格)
#coding=utf-8 import xlrd excel=xlrd.open_workbook(u"aa.xlsx") table=excel.sheet_by_index(0) hs=table.nrows for i in range(hs): print table.row_values
打印结果:
3.示例演示
将上表格中的第一列内容到百度去搜索,然后将搜索的标题与表格的一列作比较
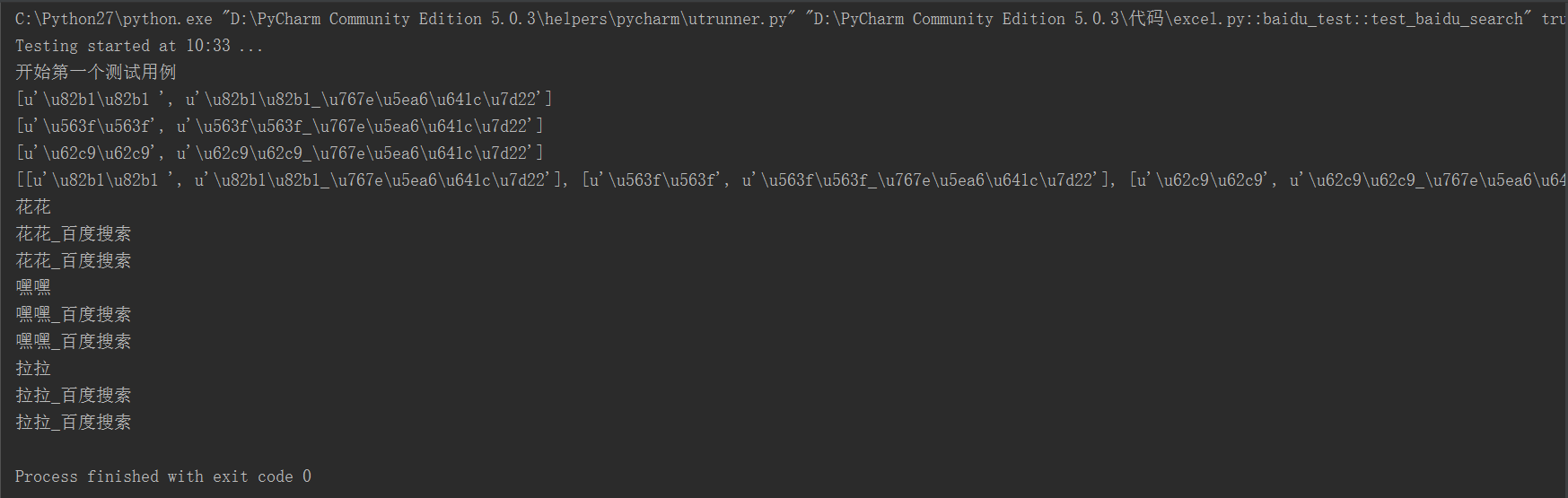
1 #coding=utf-8 2 from selenium import webdriver 3 import unittest 4 import HTMLTestRunner 5 import sys 6 from time import sleep 7 import xlrd 8 reload(sys) 9 sys.setdefaultencoding("utf-8") 10 class baidutest: 11 def __init__(self,path): 12 self.path=path 13 def load(self): 14 #打开一个excel文件 15 excel=xlrd.open_workbook(self.path) 16 #获取一个工作表格 17 table=excel.sheets()[0] 18 #获取工作表格的行数 19 nrows=table.nrows 20 #循环遍历数据,将他存到list中去 21 test_data=[] 22 for i in range(1,nrows): 23 print table.row_values(i) 24 test_data.append(table.row_values(i)) 25 #返回数据列表 26 return test_data 27 class baidu(unittest.TestCase): 28 def setUp(self): 29 self.driver=webdriver.Chrome() 30 self.driver.implicitly_wait(30) 31 self.url="http://www.baidu.com" 32 self.path=u"aa.xlsx" 33 34 def test_baidu_search(self): 35 driver=self.driver 36 print u"开始第一个用例百度搜索" 37 #加载测试数据 38 testinfo=baidutest(self.path) 39 data=testinfo.load() 40 print data 41 #循环参数化 42 for d in data: 43 #打开百度首页 44 driver.get(self.url) 45 #验证标题 46 self.assertEqual(driver.title,u"百度一下,你就知道") 47 sleep(1) 48 driver.find_element_by_id("kw").clear() 49 #参数化搜索词 50 driver.find_element_by_id("kw").send_keys(d[0]) 51 sleep(1) 52 driver.find_element_by_id("su").click() 53 sleep(1) 54 print d[0] 55 print driver.title 56 print d[1] 57 #验证搜索结果的标题 58 self.assertEqual(driver.title,d[1]) 59 sleep(2) 60 61 def tearDown(self): 62 self.driver.quit() 63 64 if __name__=='__main__': 65 test=unittest.TestSuite() 66 test.addTest(baidu("test_baidu_search")) 67 htmlpath=u"D:\\aaaaaaaa.html" 68 fp=file(htmlpath,'wb') 69 runner=HTMLTestRunner.HTMLTestRunner(stream=fp,title=u"baidu测试",description=u"测试用例结果") 70 runner.run(test) 71 fp.close()
打印结果:
练习兔展的登录(参数化)
表格数据: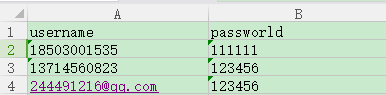
代码实例:
1 #coding=utf-8 2 from selenium import webdriver 3 from selenium.common.exceptions import NoSuchElementException 4 from selenium.webdriver.common.keys import Keys 5 from selenium.webdriver.support.ui import WebDriverWait 6 import time 7 import xlrd 8 def excel(): 9 data=xlrd.open_workbook('login.xlsx') 10 table=data.sheet_by_index(0) 11 nrows=table.nrows 12 print nrows 13 list=[] 14 for i in range(1,nrows): 15 print table.row_values(i) 16 list.append(table.row_values(i)) 17 print list 18 return list 19 def login(): 20 listdata=excel() 21 for d in listdata: 22 driver=webdriver.Chrome() 23 driver.get("http://www.rabbitpre.com/") 24 time.sleep(3) 25 driver.implicitly_wait(30) 26 driver.maximize_window() 27 driver.find_element_by_css_selector("span[class=\"login j-login\"]").click() 28 time.sleep(1) 29 driver.switch_to_frame(1) 30 print u"我要开始登陆咯" 31 time.sleep(3) 32 driver.find_element_by_xpath("//div[@id='LOGREG_1000']//input[@class='user-account']").clear() 33 driver.find_element_by_xpath("//input[@class='user-account']").send_keys(str(d[0])) 34 driver.find_element_by_xpath("//div[@id='LOGREG_1000']//div[contains(@class,'login-container')]//input[@class='user-pass']").clear() 35 driver.find_element_by_xpath("//div[contains(@class,'login-container')]//input[@class='user-pass']").send_keys(str(d[1])) 36 driver.find_element_by_xpath("//div[@id='LOGREG_1000']//div[contains(@class,'login-container')]//button").click() 37 time.sleep(3) 38 try: 39 elem=driver.find_element_by_xpath("//div[@id='DIALOG_1000']//i[@class='icon icon-close']") 40 print u"登陆成功" 41 except NoSuchElementException: 42 assert 0,u"登录失败,找不到兔展公告" 43 44 driver.quit() 45 if __name__ == '__main__': 46 login()
运行结果:

需要注意的地方:
- 在参数化表格数据的时候,如果数据是手机号,在运行代码的时候会自己后面补一位小数(解决方法,在excel中输入的时候,前面补上一个单引号)
- 在第17行与第18行之间,一定要记住是在for语句循环之后才能return的。不然永远都只能return第一行的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号