cuda 没有提供自动求导机制,因此我们需要完成以下两步,实现反向传播。

一、计算所有 trainable 参数的偏微分
判断哪些参数是 trainable 的?
本例中,输入 f 的坐标是固定的,所以 uvw 的值也是固定的,因此只需要求 feats_interp对各个顶点的特征量 \(f_i\) 的偏微分即可。
如何进行反向传播?
思路:先计算正向传播的 Loss 值,然后对各个顶点的特征量 \(f_i\) 求偏微分。
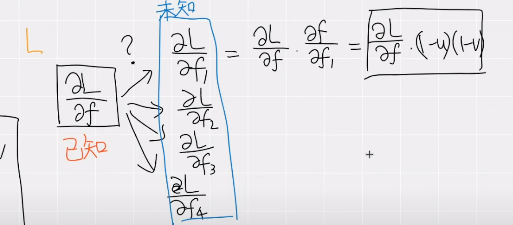
也就是利用了“链式法则”进行计算,但是必须要知道 Loss 对于 feats_interp 的偏导结果,因此我们自己实现反向传播函数需要传入这个参数。
二、代码实现
实现反向传播函数的注意事项?
(1)求偏导得到的维度和输入维度保持一致,因此 dL_dfeats 的维度是 [N,8,F] ,dL_dfeats_interp 的维度是 [N,F] 。
(2)需要把前向传播和反向传播函数都包裹在新类中,它是 torch.autograd.Function 的子类,如下面代码所示:
class Trilinear_interpolation_cuda(torch.autograd.Function):
@staticmethod
def forward(ctx, feats, points):# ctx 即 context 保存了传播过程中的状态量
feat_interp = cppcuda_tutorial.trilinear_interpolation_fw(feats, points)
ctx.save_for_backward(feats, points)
return feat_interp
@staticmethod
def backward(ctx, dL_dfeat_interp):
feats, points = ctx.saved_tensors
dL_dfeats = cppcuda_tutorial.trilinear_interpolation_bw(dL_dfeat_interp.contiguous(), feats, points)
# forward 输入有几个参数,这里就要回传几个参数,如果没有则写 None
# 我们这里求的是对 feats 的偏导,所以写在第一个位置
return dL_dfeats, None
最后的返回值和前向传播的参数保持一致,如果不需要求偏导则需要对应写为 None。
(3)传入的参数都要添加求导支持。
N = 65536; F = 256
rand = torch.rand(N, 8, F, device='cuda')
feats = rand.clone().requires_grad_()
(4)调用:前向传播需要使用 apply 方法,后向传播直接调用:
# 1. 前向传播
out_cuda = Trilinear_interpolation_cuda.apply(feats, points)
# 2. 计算 Loss(只是简单的加起来作为损失)
loss = out_cuda.sum()
# 2. Pytorch 会自动计算 dL_dfeat_interp,也就是 Loss 关于 out_cuda 的梯度,传递给 backward 函数作为参数
loss.backward()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号