一个简单的CUDA实践。用于实现前向传播。
一、算法设计
(一)问题背景描述和算法设计?
问题描述:计算某个点 f 的特征值的“插值”结果。
以二维为例,为了“插值”得到 f 的特征值,需要用到:各顶点的特征值 \(f_i\) 和 f 距离该顶点对面的两条边的距离的乘积之和。
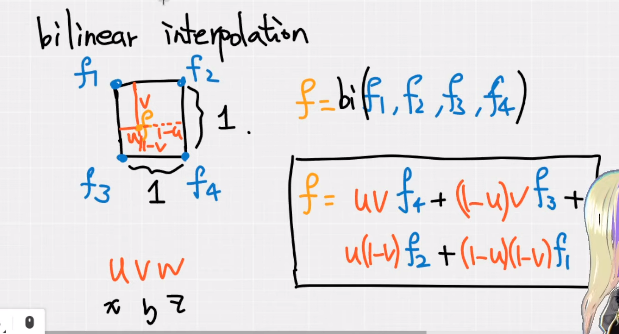
如果扩展到三维,那么需要求出 \(f\) 和 \(XYZ\) 三个面的距离(记为 uvw),然后再用一样的思路即可写出上面的式子。
(二)输入输出、以及它们的维度关系
输入:
- feats 特征向量:
(N,8,F)分别代表:N 个立方体、每个立方体有 8 个顶点、每个顶点的特征向量的长度为 F; - points 待求解的点坐标:
(N,3)分别代表:N 个待求解的f点(和 N 个立方体对应),每个点的坐标是三维的。

输出:feats_interp N 个点插值后的特征向量结果。(N,F) 代表:N 个长度为 F 的特征向量,对应 points 的每个点。
(三)如何并行运算呢?
我们这个问题一共有 N 个立方体,利用每个立方体八个格点的特征值“插值”出最后的特征值;并且每个特征向量的长度是 F,而这 F 个计算也是相互独立的。因此可以并行计算两个量。
其实还有个小技巧:看最后的输出的维度,能并行的数量不大于输出的维度。比如这里输出是 (N,F) 是二维,所以最大能并行两个量。
二、CUDA 编程
(一)GPU的基本结构
GPU 分为:Kernel - Grid - Block - Thread 四级架构。
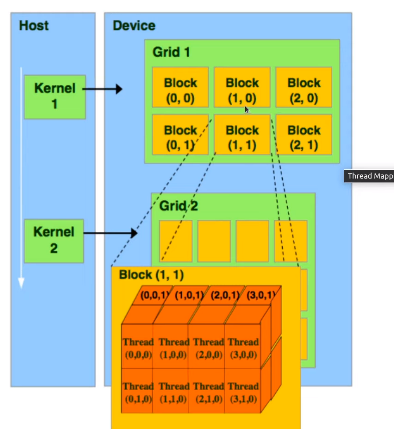
(二)Block 层的作用是什么?
为什么使用 Block+thread 的二层结构,而不是让 grid 直接管理 thread 的一层结构?
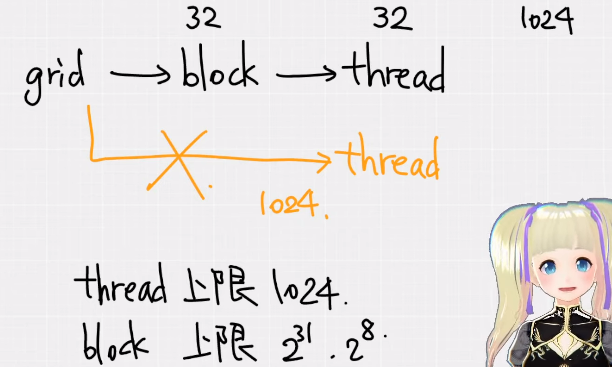
因为受限于 GPU 的硬件结构,Threads 数量是存在上限的。通过引入 Block 这个结构可以扩展线程数量。
(三)如何合理设置Block的大小?
假设 N=20,F=10,那么最后的输出维度是 20x10;我们一个Block的维度是 16*16,所以需要两个Block才能覆盖整个输出。
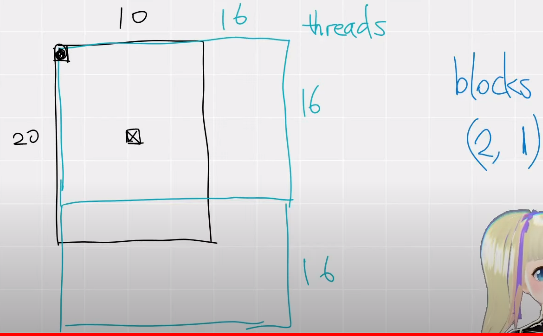
具体到代码上就是下面两行(也比较好理解):
const dim3 threads(16, 16);
const dim3 blocks((N+threads.x-1)/threads.x, (F+threads.y-1)/threads.y);
上面这也提示我们一件事情:有的 thread 是不参与运算的,也就是说 thread 的行、列的 index 值不能超过 N 和 F 的范围,否则会出错。
(三)编写核函数的注意事项?
以下面的核函数为例:
template <typename scalar_t>
__global__ void trilinear_fw_kernel(
const torch::PackedTensorAccessor<scalar_t, 3, torch::RestrictPtrTraits, size_t> feats,
const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> points,
torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> feat_interp
){
const int n = blockIdx.x * blockDim.x + threadIdx.x;
const int f = blockIdx.y * blockDim.y + threadIdx.y;
// 如果超过输出范围,则跳过不能算
if (n>=feats.size(0) || f>=feats.size(2)) return;
// point -1~1. 需要正规化到 [0,1] 之间
const scalar_t u = (points[n][0]+1)/2;
const scalar_t v = (points[n][1]+1)/2;
const scalar_t w = (points[n][2]+1)/2;
const scalar_t a = (1-v)*(1-w);
const scalar_t b = (1-v)*w;
const scalar_t c = v*(1-w);
const scalar_t d = 1-a-b-c;
// 保存计算结果
feat_interp[n][f] = (1-u)*(a*feats[n][0][f] +
b*feats[n][1][f] +
c*feats[n][2][f] +
d*feats[n][3][f]) +
u*(a*feats[n][4][f] +
b*feats[n][5][f] +
c*feats[n][6][f] +
d*feats[n][7][f]);
}
核函数没有任何返回值,因此需要把输入、输出通过参数传递到函数内部。并且这里是个泛型函数(scalar_t 代表所有可能的数据类型)。__global__ 是 CUDA 特有的关键字,代表该函数是被CPU调用、GPU执行;类似的还有 __host__ 代表 cpu 调用 + 执行、__device__ 代表 GPU 调用 + 执行。
torch::PackedTensorAccessor 的作用是把 Tensor 的类型具体化,才能给C++使用。也就是说:torch::Tensor 这种类型在 C++ 中指代不明确,需要进行具体化。我们以 feats 为例讲一下它的几个参数:
- 第二个参数 3 代表
[N,8,F]共三维结构,类比points是[N,F]是二维结构,所以它的参数写的是 2 ; size_t是位置索引的类型,默认都是size_t类型;
最后还有个细节,如何确定每个 thread 的 index 呢?也就是代码的这两行:
const int n = blockIdx.x * blockDim.x + threadIdx.x;
const int f = blockIdx.y * blockDim.y + threadIdx.y;
blockDim.x 代表 x 方向上(竖直向下)每个 block 由多少行 thread 构成,也就是 threads[0] 的值;blockIdx.x 则就是第几个 block 了;threadIdx.x 代表当前 block 内的第 x 行。
(四)如何调用核函数?
调用核函数主要有两个工作:输入输出、Block&Thread 的大小。
torch::Tensor trilinear_fw_cu(
const torch::Tensor feats,
const torch::Tensor points
){
// 1. 输入输出
const int N = feats.size(0), F = feats.size(2);
torch::Tensor feat_interp = torch::empty({N, F}, feats.options());
// 2. thread & block 大小
const dim3 threads(16, 16);// 这里N和F是可并行的,共两个次元(256不会出错)
const dim3 blocks((N+threads.x-1)/threads.x, (F+threads.y-1)/threads.y);
// 建议调用该Kernel的第二个参数为当前函数名,方便报错debug
AT_DISPATCH_FLOATING_TYPES(feats.type(), "trilinear_fw_cu",
([&] {
trilinear_fw_kernel<scalar_t><<<blocks, threads>>>(
feats.packed_accessor<scalar_t, 3, torch::RestrictPtrTraits, size_t>(),
points.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
feat_interp.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>()
);
}));
return feat_interp;
}
我们以上面这个例子为例。feat_interp 是最后的输出,它的维度是 (N,F) ,这里直接通过 feats.options() 设置参数属性;如果需要自定义的话,比如 torch::empty({N,F}, torch::dtype(torch::kInt32).device(feats.device)); 来自定义类型和位置。
threads 的总数一般是 256 或 512,最大不超过 1024。上面我们分析过,可并行量共有两个,所以我们设置 256=16*16 作为 threads 的大小,blocks 的数量就按照上面的公式计算即可。
我们使用了 AT_DISPATCH_FLOATING_TYPES 这个函数来调用核函数,注意调用时通过 <<<, >>> 包裹 blocks 和 threads 的大小,这是 cuda 的特殊写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号