
大数据概述
一.用图表描述Hadoop生态系统的各个组件及其关系。
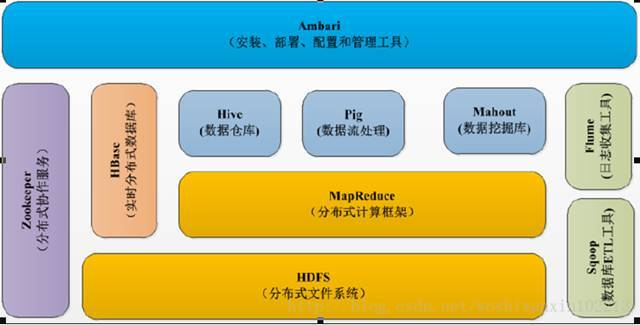
Hadoop生态系统除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括Zookeeper、HBase、Hive、Pig、Mahout、Sqoop、Flume、Ambari等功能组件。

(1).HDFS:具有处理超大数据、流式处理、可以运行在廉价商用服务器上,访问应用程序数据时有很高的吞吐率。
(2).HBase:是一个高可靠、高性能、面向列、可伸缩的分布式数据库,采用基于列的存储,具有良好的横向扩展能力。
(3).MapReduce:分布式并行编程模型,用于大规模数据集(大于1TB)的并行运算,将自己的程序运行在分布式系统上,完成海量数据集的计算。
(4).Hive:数据仓库工具,对数据进行数据整理、特殊查询和分析处理。
(5).Pig:数据分析平台,侧重数据查询和分析。
(6).Zookeeper:提供分布式锁之类的基本服务。
(7).Flume:高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统,定制各类数据发送方,用于收集数据。
(8).Sqoop:主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
二.阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YARN。
(1)HDFS集群:负责海量数据的存储。
(2)YARN集群:负责海量数据运算时的资源调度。
(3)MapReduce:它其实是一个应用程序开发包。
从开源角度看,YARN的提出,从一定程度上弱化了多计算框架的优劣之争。YARN是在Hadoop MapReduce基础上演化而来的,在MapReduce时代,很多人批评MapReduce不适合迭代计算和流失计算,于是出现了Spark和Storm等计算框架,而这些系统的开发者则在自己的网站上或者论文里与MapReduce对比,鼓吹自己的系统多么先进高效,而出现了YARN之后,则形势变得明朗:MapReduce只是运行在YARN之上的一类应用程序抽象,Spark和Storm本质上也是,他们只是针对不同类型的应用开发的,没有优劣之别,各有所长,合并共处,而且,今后所有计算框架的开发,不出意外的话,也应是在YARN之上。这样,一个以YARN为底层资源管理平台,多种计算框架运行于其上的生态系统诞生了。
HDFS
HDFS(Hadoop分布式文件系统)源自于Google的GFS论文,发表于2003年10月,HDFS是GFS的实现版。HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障,在低成本的通用硬件上运行。HDFS简化了文件的一次性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适用带有数据集的应用程序。HDFS提供一次写入多次读取的机制,数据以块的形式,同时分布存储在不同的物理机器上。
HDFS默认的最基本的存储单位是64MB的数据块,和普通文件系统一样,HDFS中的文件被分成64MB一块的数据块存储。它的开发是基于流数据模式访问和处理超大文件的需求。
MapReduce
Mapduce(分布式计算框架)源自于Google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是Google Reduce 克隆版。MapReduce是一种分布式计算模型,用以进行海量数据的计算。它屏蔽了分布式计算框架细节,将计算抽象成Map 和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
HBase
Hbase(分布式列存数据库)源自Google的BigTable论文,发表于2006年11月,HBase是Google Table的实现。HBase是一个建立在HDFS之上,面向结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。HBase采用了BigTable的数据模型,即增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模
YARN
YARN(分布式资源管理器)是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性差,不支持多计算框架而提出的。YARN是下一代Hadoop计算平台,是一个通用的运行时框架,用户可以编写自己的极端框架,在该运行环境中运行。
Spark
Spark(内存DAG计算模型)是一个Apche项目,被标榜为“快如闪电的集群计算”,它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UC Berkeley AMP Lab所开源的类Hadoop MapReduce的通用计算框架,Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark平台可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
目前Spark是一个非常流行的内存计算(或者迭代式计算,DAG计算)框架。
3.使用Linux的常用命令,教材P15。
系统信息
arch 显示机器的处理器架构
uname -m 显示机器的处理器架构
uname -r 显示正在使用的内核版本
dmidecode -q 显示硬件系统部件 - (SMBIOS / DMI)
hdparm -i /dev/hda 罗列一个磁盘的架构特性
hdparm -tT /dev/sda 在磁盘上执行测试性读取操作
cat /proc/cpuinfo 显示CPU info的信息
cat /proc/interrupts 显示中断
cat /proc/meminfo 校验内存使用
cat /proc/swaps 显示哪些swap被使用
cat /proc/version 显示内核的版本
cat /proc/net/dev 显示网络适配器及统计
cat /proc/mounts 显示已加载的文件系统
lspci -tv 罗列 PCI 设备
lsusb -tv 显示 USB 设备
date 显示系统日期
cal 2007 显示2007年的日历表
date 041217002007.00 设置日期和时间 - 月日时分年.秒
clock -w 将时间修改保存到 BIOS
关机 (系统的关机、重启以及登出 )
shutdown -h now 关闭系统
init 0 关闭系统
telinit 0 关闭系统
shutdown -h hours:minutes & 按预定时间关闭系统
shutdown -c 取消按预定时间关闭系统
shutdown -r now 重启
reboot 重启
logout 注销
文件和目录
cd /home 进入 '/ home' 目录'
cd .. 返回上一级目录
cd ../.. 返回上两级目录
cd 进入个人的主目录
cd ~user1 进入个人的主目录
cd - 返回上次所在的目录
pwd 显示工作路径
ls 查看目录中的文件
ls -F 查看目录中的文件
ls -l 显示文件和目录的详细资料
ls -a 显示隐藏文件
ls *[0-9]* 显示包含数字的文件名和目录名
tree 显示文件和目录由根目录开始的树形结构
lstree 显示文件和目录由根目录开始的树形结构
mkdir dir1 创建一个叫做 'dir1' 的目录'
mkdir dir1 dir2 同时创建两个目录
mkdir -p /tmp/dir1/dir2 创建一个目录树
rm -f file1 删除一个叫做 'file1' 的文件'
rmdir dir1 删除一个叫做 'dir1' 的目录'
rm -rf dir1 删除一个叫做 'dir1' 的目录并同时删除其内容
rm -rf dir1 dir2 同时删除两个目录及它们的内容
mv dir1 new_dir 重命名/移动 一个目录
cp file1 file2 复制一个文件
cp dir/* . 复制一个目录下的所有文件到当前工作目录
cp -a /tmp/dir1 . 复制一个目录到当前工作目录
cp -a dir1 dir2 复制一个目录
cp -r dir1 dir2 复制一个目录及子目录
ln -s file1 lnk1 创建一个指向文件或目录的软链接
ln file1 lnk1 创建一个指向文件或目录的物理链接
touch -t 0712250000 file1 修改一个文件或目录的时间戳 - (YYMMDDhhmm)
file file1 outputs the mime type of the file as text
iconv -l 列出已知的编码
iconv -f fromEncoding -t toEncoding inputFile > outputFile creates a new from the given input file by assuming it is encoded in fromEncoding and converting it to toEncoding.
find . -maxdepth 1 -name *.jpg -print -exec convert "{}" -resize 80x60 "thumbs/{}" \; batch resize files in the current directory and send them to a thumbnails directory (requires convert from Imagemagick)
文件搜索
find / -name file1 从 '/' 开始进入根文件系统搜索文件和目录
find / -user user1 搜索属于用户 'user1' 的文件和目录
find /home/user1 -name \*.bin 在目录 '/ home/user1' 中搜索带有'.bin' 结尾的文件
find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件
find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件
find / -name \*.rpm -exec chmod 755 '{}' \; 搜索以 '.rpm' 结尾的文件并定义其权限
find / -xdev -name \*.rpm 搜索以 '.rpm' 结尾的文件,忽略光驱、捷盘等可移动设备
locate \*.ps 寻找以 '.ps' 结尾的文件 - 先运行 'updatedb' 命令
whereis halt 显示一个二进制文件、源码或man的位置
which halt 显示一个二进制文件或可执行文件的完整路径
挂载一个文件系统
mount /dev/hda2 /mnt/hda2 挂载一个叫做hda2的盘 - 确定目录 '/ mnt/hda2' 已经存在
umount /dev/hda2 卸载一个叫做hda2的盘 - 先从挂载点 '/ mnt/hda2' 退出
fuser -km /mnt/hda2 当设备繁忙时强制卸载
umount -n /mnt/hda2 运行卸载操作而不写入 /etc/mtab 文件- 当文件为只读或当磁盘写满时非常有用
mount /dev/fd0 /mnt/floppy 挂载一个软盘
mount /dev/cdrom /mnt/cdrom 挂载一个cdrom或dvdrom
mount /dev/hdc /mnt/cdrecorder 挂载一个cdrw或dvdrom
mount /dev/hdb /mnt/cdrecorder 挂载一个cdrw或dvdrom
mount -o loop file.iso /mnt/cdrom 挂载一个文件或ISO镜像文件
mount -t vfat /dev/hda5 /mnt/hda5 挂载一个Windows FAT32文件系统
mount /dev/sda1 /mnt/usbdisk 挂载一个usb 捷盘或闪存设备
mount -t smbfs -o username=user,password=pass //WinClient/share /mnt/share 挂载一个windows网络共享
磁盘空间
df -h 显示已经挂载的分区列表
ls -lSr |more 以尺寸大小排列文件和目录
du -sh dir1 估算目录 'dir1' 已经使用的磁盘空间'
du -sk * | sort -rn 以容量大小为依据依次显示文件和目录的大小
rpm -q -a --qf '%10{SIZE}t%{NAME}n' | sort -k1,1n 以大小为依据依次显示已安装的rpm包所使用的空间 (fedora, redhat类系统)
dpkg-query -W -f='${Installed-Size;10}t${Package}n' | sort -k1,1n 以大小为依据显示已安装的deb包所使用的空间 (ubuntu, debian类系统)
用户和群组
groupadd group_name 创建一个新用户组
groupdel group_name 删除一个用户组
groupmod -n new_group_name old_group_name 重命名一个用户组
useradd -c "Name Surname " -g admin -d /home/user1 -s /bin/bash user1 创建一个属于 "admin" 用户组的用户
useradd user1 创建一个新用户
userdel -r user1 删除一个用户 ( '-r' 排除主目录)
usermod -c "User FTP" -g system -d /ftp/user1 -s /bin/nologin user1 修改用户属性
passwd 修改口令
passwd user1 修改一个用户的口令 (只允许root执行)
chage -E 2005-12-31 user1 设置用户口令的失效期限
pwck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的用户
grpck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的群组
newgrp group_name 登陆进一个新的群组以改变新创建文件的预设群组
文件的权限 - 使用 "+" 设置权限,使用 "-" 用于取消
ls -lh 显示权限
ls /tmp | pr -T5 -W$COLUMNS 将终端划分成5栏显示
chmod ugo+rwx directory1 设置目录的所有人(u)、群组(g)以及其他人(o)以读(r )、写(w)和执行(x)的权限
chmod go-rwx directory1 删除群组(g)与其他人(o)对目录的读写执行权限
chown user1 file1 改变一个文件的所有人属性
chown -R user1 directory1 改变一个目录的所有人属性并同时改变改目录下所有文件的属性
chgrp group1 file1 改变文件的群组
chown user1:group1 file1 改变一个文件的所有人和群组属性
find / -perm -u+s 罗列一个系统中所有使用了SUID控制的文件
chmod u+s /bin/file1 设置一个二进制文件的 SUID 位 - 运行该文件的用户也被赋予和所有者同样的权限
chmod u-s /bin/file1 禁用一个二进制文件的 SUID位
chmod g+s /home/public 设置一个目录的SGID 位 - 类似SUID ,不过这是针对目录的
chmod g-s /home/public 禁用一个目录的 SGID 位
chmod o+t /home/public 设置一个文件的 STIKY 位 - 只允许合法所有人删除文件
chmod o-t /home/public 禁用一个目录的 STIKY 位
文件的特殊属性 - 使用 "+" 设置权限,使用 "-" 用于取消
chattr +a file1 只允许以追加方式读写文件
chattr +c file1 允许这个文件能被内核自动压缩/解压
chattr +d file1 在进行文件系统备份时,dump程序将忽略这个文件
chattr +i file1 设置成不可变的文件,不能被删除、修改、重命名或者链接
chattr +s file1 允许一个文件被安全地删除
chattr +S file1 一旦应用程序对这个文件执行了写操作,使系统立刻把修改的结果写到磁盘
chattr +u file1 若文件被删除,系统会允许你在以后恢复这个被删除的文件
lsattr 显示特殊的属性
打包和压缩文件
bunzip2 file1.bz2 解压一个叫做 'file1.bz2'的文件
bzip2 file1 压缩一个叫做 'file1' 的文件
gunzip file1.gz 解压一个叫做 'file1.gz'的文件
gzip file1 压缩一个叫做 'file1'的文件
gzip -9 file1 最大程度压缩
rar a file1.rar test_file 创建一个叫做 'file1.rar' 的包
rar a file1.rar file1 file2 dir1 同时压缩 'file1', 'file2' 以及目录 'dir1'
rar x file1.rar 解压rar包
unrar x file1.rar 解压rar包
tar -cvf archive.tar file1 创建一个非压缩的 tarball
tar -cvf archive.tar file1 file2 dir1 创建一个包含了 'file1', 'file2' 以及 'dir1'的档案文件
tar -tf archive.tar 显示一个包中的内容
tar -xvf archive.tar 释放一个包
tar -xvf archive.tar -C /tmp 将压缩包释放到 /tmp目录下
tar -cvfj archive.tar.bz2 dir1 创建一个bzip2格式的压缩包
tar -jxvf archive.tar.bz2 解压一个bzip2格式的压缩包
tar -cvfz archive.tar.gz dir1 创建一个gzip格式的压缩包
tar -zxvf archive.tar.gz 解压一个gzip格式的压缩包
zip file1.zip file1 创建一个zip格式的压缩包
zip -r file1.zip file1 file2 dir1 将几个文件和目录同时压缩成一个zip格式的压缩包
unzip file1.zip 解压一个zip格式压缩包
RPM 包 - (Fedora, Redhat及类似系统)
rpm -ivh package.rpm 安装一个rpm包
rpm -ivh --nodeeps package.rpm 安装一个rpm包而忽略依赖关系警告
rpm -U package.rpm 更新一个rpm包但不改变其配置文件
rpm -F package.rpm 更新一个确定已经安装的rpm包
rpm -e package_name.rpm 删除一个rpm包
rpm -qa 显示系统中所有已经安装的rpm包
rpm -qa | grep httpd 显示所有名称中包含 "httpd" 字样的rpm包
rpm -qi package_name 获取一个已安装包的特殊信息
rpm -qg "System Environment/Daemons" 显示一个组件的rpm包
rpm -ql package_name 显示一个已经安装的rpm包提供的文件列表
rpm -qc package_name 显示一个已经安装的rpm包提供的配置文件列表
rpm -q package_name --whatrequires 显示与一个rpm包存在依赖关系的列表
rpm -q package_name --whatprovides 显示一个rpm包所占的体积
rpm -q package_name --scripts 显示在安装/删除期间所执行的脚本l
rpm -q package_name --changelog 显示一个rpm包的修改历史
rpm -qf /etc/httpd/conf/httpd.conf 确认所给的文件由哪个rpm包所提供
rpm -qp package.rpm -l 显示由一个尚未安装的rpm包提供的文件列表
rpm --import /media/cdrom/RPM-GPG-KEY 导入公钥数字证书
rpm --checksig package.rpm 确认一个rpm包的完整性
rpm -qa gpg-pubkey 确认已安装的所有rpm包的完整性
rpm -V package_name 检查文件尺寸、 许可、类型、所有者、群组、MD5检查以及最后修改时间
rpm -Va 检查系统中所有已安装的rpm包- 小心使用
rpm -Vp package.rpm 确认一个rpm包还未安装
rpm2cpio package.rpm | cpio --extract --make-directories *bin* 从一个rpm包运行可执行文件
rpm -ivh /usr/src/redhat/RPMS/`arch`/package.rpm 从一个rpm源码安装一个构建好的包
rpmbuild --rebuild package_name.src.rpm 从一个rpm源码构建一个 rpm 包
YUM 软件包升级器 - (Fedora, RedHat及类似系统)
yum install package_name 下载并安装一个rpm包
yum localinstall package_name.rpm 将安装一个rpm包,使用你自己的软件仓库为你解决所有依赖关系
yum update package_name.rpm 更新当前系统中所有安装的rpm包
yum update package_name 更新一个rpm包
yum remove package_name 删除一个rpm包
yum list 列出当前系统中安装的所有包
yum search package_name 在rpm仓库中搜寻软件包
yum clean packages 清理rpm缓存删除下载的包
yum clean headers 删除所有头文件
yum clean all 删除所有缓存的包和头文件
DEB 包 (Debian, Ubuntu 以及类似系统)
dpkg -i package.deb 安装/更新一个 deb 包
dpkg -r package_name 从系统删除一个 deb 包
dpkg -l 显示系统中所有已经安装的 deb 包
dpkg -l | grep httpd 显示所有名称中包含 "httpd" 字样的deb包
dpkg -s package_name 获得已经安装在系统中一个特殊包的信息
dpkg -L package_name 显示系统中已经安装的一个deb包所提供的文件列表
dpkg --contents package.deb 显示尚未安装的一个包所提供的文件列表
dpkg -S /bin/ping 确认所给的文件由哪个deb包提供
APT 软件工具 (Debian, Ubuntu 以及类似系统)
apt-get install package_name 安装/更新一个 deb 包
apt-cdrom install package_name 从光盘安装/更新一个 deb 包
apt-get update 升级列表中的软件包
apt-get upgrade 升级所有已安装的软件
apt-get remove package_name 从系统删除一个deb包
apt-get check 确认依赖的软件仓库正确
apt-get clean 从下载的软件包中清理缓存
apt-cache search searched-package 返回包含所要搜索字符串的软件包名称
查看文件内容
cat file1 从第一个字节开始正向查看文件的内容
tac file1 从最后一行开始反向查看一个文件的内容
more file1 查看一个长文件的内容
less file1 类似于 'more' 命令,但是它允许在文件中和正向操作一样的反向操作
head -2 file1 查看一个文件的前两行
tail -2 file1 查看一个文件的最后两行
tail -f /var/log/messages 实时查看被添加到一个文件中的内容
文本处理
cat file1 file2 ... | command <> file1_in.txt_or_file1_out.txt general syntax for text manipulation using PIPE, STDIN and STDOUT
cat file1 | command( sed, grep, awk, grep, etc...) > result.txt 合并一个文件的详细说明文本,并将简介写入一个新文件中
cat file1 | command( sed, grep, awk, grep, etc...) >> result.txt 合并一个文件的详细说明文本,并将简介写入一个已有的文件中
grep Aug /var/log/messages 在文件 '/var/log/messages'中查找关键词"Aug"
grep ^Aug /var/log/messages 在文件 '/var/log/messages'中查找以"Aug"开始的词汇
grep [0-9] /var/log/messages 选择 '/var/log/messages' 文件中所有包含数字的行
grep Aug -R /var/log/* 在目录 '/var/log' 及随后的目录中搜索字符串"Aug"
sed 's/stringa1/stringa2/g' example.txt 将example.txt文件中的 "string1" 替换成 "string2"
sed '/^$/d' example.txt 从example.txt文件中删除所有空白行
sed '/ *#/d; /^$/d' example.txt 从example.txt文件中删除所有注释和空白行
echo 'esempio' | tr '[:lower:]' '[:upper:]' 合并上下单元格内容
sed -e '1d' result.txt 从文件example.txt 中排除第一行
sed -n '/stringa1/p' 查看只包含词汇 "string1"的行
sed -e 's/ *$//' example.txt 删除每一行最后的空白字符
sed -e 's/stringa1//g' example.txt 从文档中只删除词汇 "string1" 并保留剩余全部
sed -n '1,5p;5q' example.txt 查看从第一行到第5行内容
sed -n '5p;5q' example.txt 查看第5行
sed -e 's/00*/0/g' example.txt 用单个零替换多个零
cat -n file1 标示文件的行数
cat example.txt | awk 'NR%2==1' 删除example.txt文件中的所有偶数行
echo a b c | awk '{print $1}' 查看一行第一栏
echo a b c | awk '{print $1,$3}' 查看一行的第一和第三栏
paste file1 file2 合并两个文件或两栏的内容
paste -d '+' file1 file2 合并两个文件或两栏的内容,中间用"+"区分
sort file1 file2 排序两个文件的内容
sort file1 file2 | uniq 取出两个文件的并集(重复的行只保留一份)
sort file1 file2 | uniq -u 删除交集,留下其他的行
sort file1 file2 | uniq -d 取出两个文件的交集(只留下同时存在于两个文件中的文件)
comm -1 file1 file2 比较两个文件的内容只删除 'file1' 所包含的内容
comm -2 file1 file2 比较两个文件的内容只删除 'file2' 所包含的内容
comm -3 file1 file2 比较两个文件的内容只删除两个文件共有的部分
字符设置和文件格式转换
dos2unix filedos.txt fileunix.txt 将一个文本文件的格式从MSDOS转换成UNIX
unix2dos fileunix.txt filedos.txt 将一个文本文件的格式从UNIX转换成MSDOS
recode ..HTML < page.txt > page.html 将一个文本文件转换成html
recode -l | more 显示所有允许的转换格式
文件系统分析
badblocks -v /dev/hda1 检查磁盘hda1上的坏磁块
fsck /dev/hda1 修复/检查hda1磁盘上linux文件系统的完整性
fsck.ext2 /dev/hda1 修复/检查hda1磁盘上ext2文件系统的完整性
e2fsck /dev/hda1 修复/检查hda1磁盘上ext2文件系统的完整性
e2fsck -j /dev/hda1 修复/检查hda1磁盘上ext3文件系统的完整性
fsck.ext3 /dev/hda1 修复/检查hda1磁盘上ext3文件系统的完整性
fsck.vfat /dev/hda1 修复/检查hda1磁盘上fat文件系统的完整性
fsck.msdos /dev/hda1 修复/检查hda1磁盘上dos文件系统的完整性
dosfsck /dev/hda1 修复/检查hda1磁盘上dos文件系统的完整性
初始化一个文件系统
mkfs /dev/hda1 在hda1分区创建一个文件系统
mke2fs /dev/hda1 在hda1分区创建一个linux ext2的文件系统
mke2fs -j /dev/hda1 在hda1分区创建一个linux ext3(日志型)的文件系统
mkfs -t vfat 32 -F /dev/hda1 创建一个 FAT32 文件系统
fdformat -n /dev/fd0 格式化一个软盘
mkswap /dev/hda3 创建一个swap文件系统
SWAP文件系统
mkswap /dev/hda3 创建一个swap文件系统
swapon /dev/hda3 启用一个新的swap文件系统
swapon /dev/hda2 /dev/hdb3 启用两个swap分区
