
python基础之字符编码
一、字符编码
1.什么是字符编码?
字符-------标准(字符编码)-----》数字
2.为什么要编码?
让计算机认识人的字符
3.常见的字符编码
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可表示256个字符
GBK:2Bytes代表一个字符,由中国人定制
unnicode:兼容万国语言,统一用2Bytes代表一个字符,2**16-1=66535,课代表6万多个字符,因而兼容万国语言,但是对于英文文本来说,就是凭空多了 一倍的存储空间
utf-8:应unnicode的缺点而生,对英文字符只用1Bytes表示,对中文字符用3Bytes
需要强调的是:
uncode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度块,确定啊是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
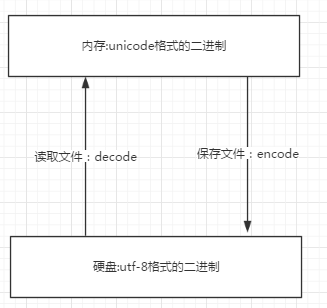
内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大于utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
4.如何正确使用字符编码
文件存:从内存刷到硬盘
文件读:从硬盘读到内存
1)文件执行前:
文件用什么编码保存,读的时候就要用相同的编码打开,否则就会出现乱码,内存中默认都是unicode
文件头:#coding:utf-8
python /a.py
2)文件执行时:才有字符串数据类型的概念
x='hello' #python3中的字符串默认是unicode
x.encode('gbk') #python3中字符编码后的结果是bytes类型
3)在python2中字符串分为:
str=butes:x='hello' #u'hello'.encode('utf-8')
unicode #x=u'hello'
5.程序的执行
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
阶段三:读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x=‘sam’

