
实验7 缓冲区溢出 20221418
实验七报告
一、实验内容
1.实验准备:更新实验环境,安装GDB
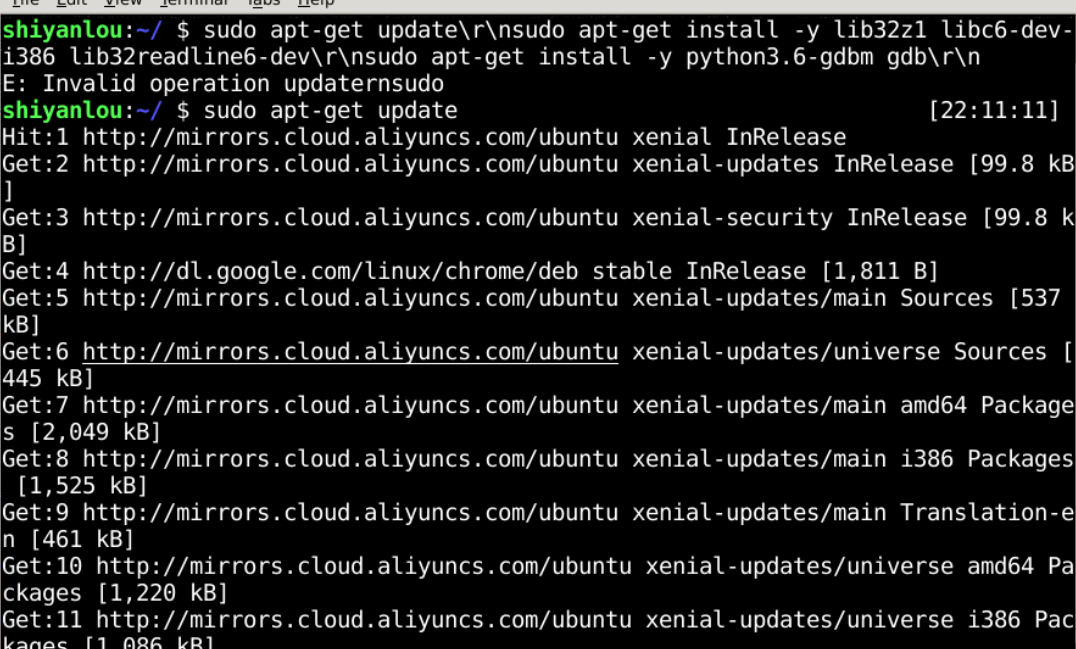

2.初始化设置:(1)关闭地址空间随机化 (2)设置zsh程序 (3)进入32位linux环境
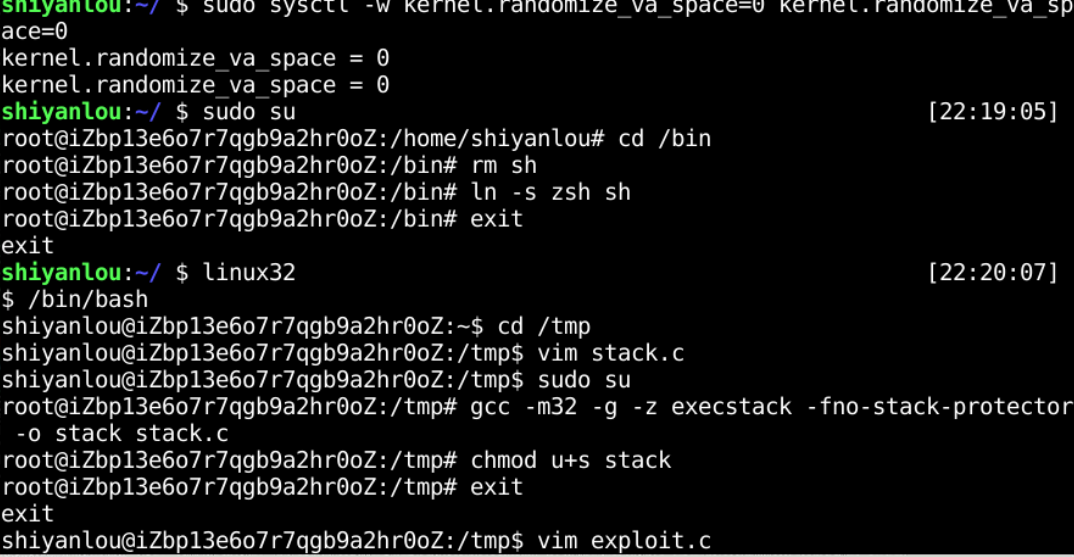
3.编译初始化漏洞程序并设置SET-UID
4.新建攻击程序exploit.c(注意复制时单双横线的变化)
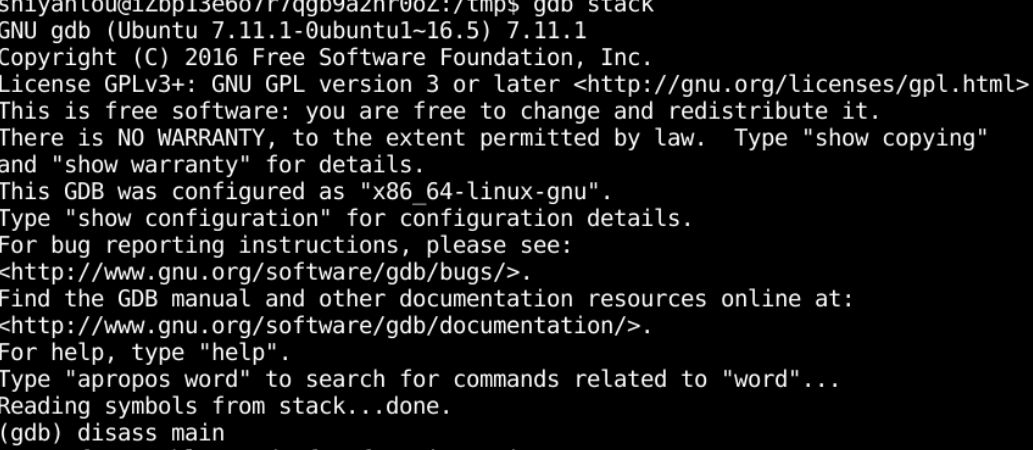
5.得到shell地址(1)进GDB(2)在esp下一位设置断点
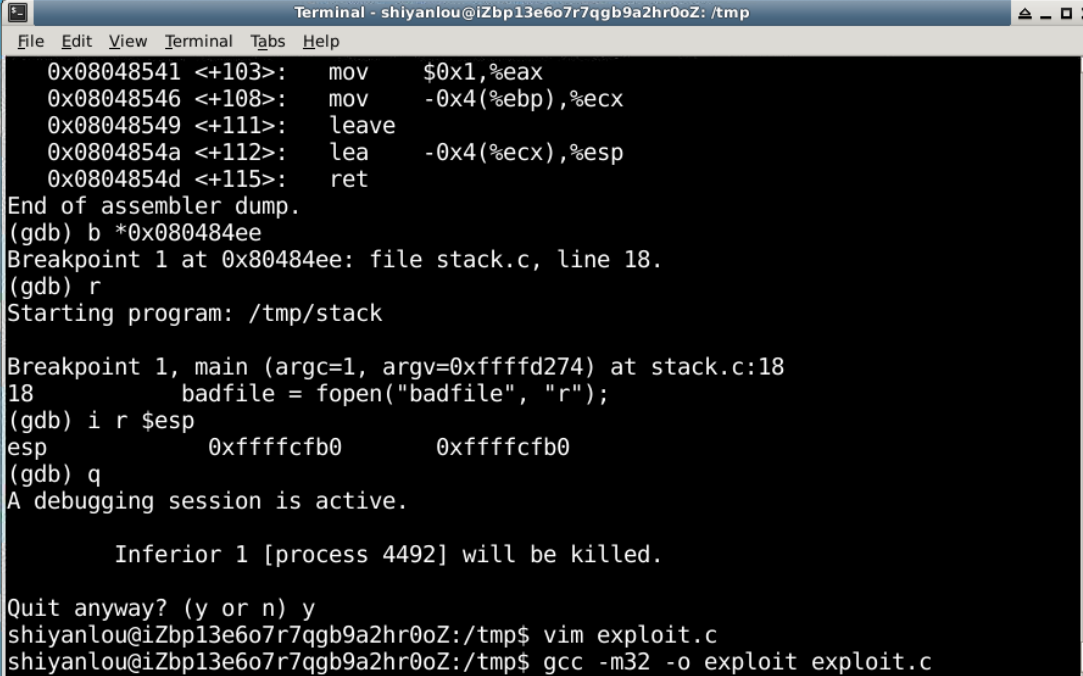
6.运行程序,进行攻击

二、缓冲区溢出原理
1.缓冲区:计算机程序一般都会使用到一些内存,这些内存或是程序内部使用,或是存放用户的输入数据,这样的内存一般称作缓冲区。
2.溢出:在计算机程序中数据使用到了被分配内存空间之外的内存空间。
3.缓冲区溢出:计算机对接收的输入数据没有进行有效的检测,向缓冲区内填充数据时超过了缓冲区本身的容量,导致数据溢出到被分配空间之外的空间,使得溢出的数据覆盖了其他内存空间的数据。(总体论述)
4.分类:
(1)栈溢出:在栈中分配的缓冲区由于拷贝的数据过长,导致覆盖了函数的返回地址或其他一些重要数据结构、函数指针等。
(2)堆溢出:与栈溢出类似,区别在于结果是覆盖了堆管理结构
(3)整型溢出:【1】宽度溢出:尝试存储一个超过变量表示范围的大数到变量中【2】运算溢出:存储值为运算操作【3】符号溢出 一个无符号的变量被视作有符号或者一个有符号的变量被视作无符号。
(4)格式化字符串溢出:printf函数是不定参数输入,因此不会检查输入参数的个数
(5)其他溢出类型:datasection溢出,PEB/TEB溢出,文件流溢出等等。
三、缓冲区溢出危害的防范
目前主要有四种基本的方法
1、通过操作系统使得缓冲区不可执行,从而阻止攻击者植入攻击代码
通过使被攻击程序的数据段地址空间不可执行,从而使得攻击者不可能执行被植入被攻击程序输入缓冲区的代码,这种技术被称为非执行的缓冲区技术。在早期的Unix系统设计中,只允许程序代码在代码段中执行。但是Unix和MS Windows系统由于要实现更好的性能和功能,往往在数据段中动态地放入可执行的代码,这也是缓冲区溢出的根源。为了保持程序的兼容性,不可能使得所有程序的数据段不可执行,但是可以设定堆栈数据段不可执行,这样就可以保证程序的兼容性。除了linux中的信号传递过程和gcc的在线重用过程之外,这种方法是兼容性极好的
2、强制写正确的代码的方法
即使是像C语言这种风格自由的计算机语言,我们知道有一种“良好的代码风格”,而遵循这种代码风格就可以让我们减少漏洞,另外也有一些工具可以辅助你写出正确且安全的代码,最简单的方法就是用grep来搜索源代码中容易产生漏洞的库的调用,还有如fault injection等人为随机产生缓冲区溢出来检测程序安全性的
3、利用编译器的边界检查来实现缓冲区的保护
我们知道缓冲区溢出的一个基本条件是在缓冲区的高地址附近存在着可供溢出覆盖的函数地址指针,如果我们将静态数据段中的函数地址指针存放地址与其他数据的存放地址分离,那就会使缓冲区溢出无法覆盖函数地址指针。
4、在程序指针失效前进行完整性检查
原理是在每次在程序指针被引用之前先检测该指针是否己被恶意改动过,如果发现被改动,程序就拒绝执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号