


HDFS读流程
客户端先与NameNode通信,获取block位置信息,之后线性地先取第一个块,然后接二连三地获取,取回一个块时会进行MD5验证,验证通过后会使read顺利进行完,当最终读完所有的block块之后,拼起来就是一个完整的源文件,数据本地化读取是分布式计算中计算向数据移动的一大特征,block块有偏移量和位置信息,HDFS分布式文件系统优化了读取性能,客户端会根据block的信息来分辨这些副本中,哪些副本距离客户端自身最近,那么本地、同机架、以及其他DataNode会是一个由近及远的排序,后面我们再分析MapReduce源代码的时候,会再进行分析这一优化特性。请先记住HDFS读流程的两个重要特性:
(1) block信息的MD5验证
(2) 读取block时距离优先顺序的优化。
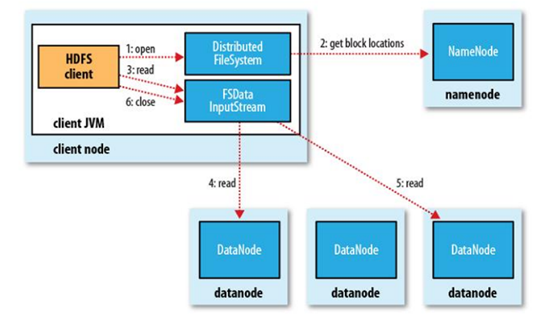
图1.8 HDFS读流程来自《Hadoop:The Definitive Guide》一书
读取文件的具体方式如下:
1. 从Hadoop URL读取数据
要从Hadoop文件系统中读取文件,最简单的方法是使用java.net.URl对象打开数据流,从中读取文件。但是,如何让java程序能够识别Hadoop的hdfs URL呢?这里采用的方法是通过调用java.net.URL对象的setURLStreamHandlerFactory方法,方法中传入FsUrlStreamHandlerFactory的一个实例,就可以让java程序可以识别hadoop的hdfs URL。每个java虚拟机只能调用一次这个setURLStreamHandlerFactory方法,因此通常将其卸载静态方法中。
示例程序:在hdfs中存在着/install.log,
public class test {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
@Test
public void readByUrl() {
InputStream in = null;
try {
in = new URL("hdfs://node1:9000/install.log").openStream();
} catch (IOException e) {
}finally{
IOUtils.closeStream(in);
}
}
}
连不上集群。需要将core-site和hdfs-site放入到src目录下。
2.通过FileSysem API读取数据
正如前一小节所解释,有时不可能在应用程序中设置URLStreamhandlerFactory实例,这种情况下,需要用到FileSystem API来打开一个文件的输入流。Hadoop文件系统中通过Hadoop Path对象来代表文件。FileSystem是一个通用的文件系统API,这个类第一步是检索我们需要使用的文件系统实例,这里是HDFS。利用FileSystem.get()获取FilsSystem实例。Configuration对象封装了客户端或服务器的配置,一般讲hdfs的配置文件(将core-site.xml和hdft-site.xml放到项目的src目录下,configuration实例化的时候就会自动获取)。具体代码如下。
示例程序:在hdfs中存在着/install.log,
@Test
public void readByFileSystem() throws Exception{
String Url = "hdfs://node1:9000/install.log";
//FileSystem fs = FileSystem.get(URI.create(Url), conf);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
InputStream in = null;
in = fs.open(new Path(Url));
IOUtils.copyBytes(in, System.out, 4096,true);
}
