
高可用的 MySQL 集群
-
主从同步
单节点的 MySQL 肯定不适用于高并发的生产环境,为了提高性能,我们至少要做到读写分离,主库可读可写,从库只读。这里最关键的技术点就是主从同步。
我的 MySQL 配置文件如下(8.0.22):
[mysqld] server_id = 1 # 机器ID,集群下唯一 pid-file = /var/run/mysqld/mysqld.pid socket = /var/run/mysqld/mysqld.sock datadir = /var/lib/mysql secure-file-priv = NULL # 服务端禁止导入导出 max_connections = 1024 # 最大连接数,最多可设置16384 log_timestamps = SYSTEM # 使用本地系统时区 slow_query_log = 1 # 开启慢查询日志 long_query_time = 3 # 慢查询设置为3秒 general_log = 0 # 关闭每一条命令写日志 sync_binlog = 1 # 每次提交事务都落盘 binlog_format = ROW # 日志记录每一行的修改 binlog_expire_logs_seconds = 1209600 # 日志过期秒数 transaction_isolation = READ-COMMITTED # 事务隔离级别 log_bin = /var/log/binlog log_error = /var/log/mysqld.log slow_query_log_file = /var/log/mysql-slow.log general_log_file = /var/log/mysql-general-log.log skip-host-cache # 禁用主机名缓存 skip-name-resolve # 禁用 DNS 解析主库需加上:
binlog-do-db = dclett # 需要同步的数据库名,多个以“,”隔开从库需加上:
replicate-do-db = dclett # 需要同步的数据库名,多个以“,”隔开 read_only = 1 # 只读,root 权限依然可写docker-compose 文件:
version: "3.7" services: mysql-master: image: mysql:8.0.22 container_name: mysql-master restart: always ports: - "3306:3306" volumes: - /work/docker/mysql-master/conf/my.cnf:/etc/mysql/my.cnf - /work/docker/mysql-master/data:/var/lib/mysql - /work/docker/mysql-master/log:/var/log environment: MYSQL_ROOT_PASSWORD: 111111 MYSQL_DATABASE: dclett MYSQL_USER: test MYSQL_PASSWORD: 111111 networks: - dev-net mysql-slave: image: mysql:8.0.22 container_name: mysql-slave restart: always ports: - "3307:3306" volumes: - /work/docker/mysql-slave/conf/my.cnf:/etc/mysql/my.cnf - /work/docker/mysql-slave/data:/var/lib/mysql - /work/docker/mysql-slave/log:/var/log environment: MYSQL_ROOT_PASSWORD: 111111 MYSQL_DATABASE: dclett MYSQL_USER: test MYSQL_PASSWORD: 111111 networks: - dev-net networks: dev-net: driver: bridge主从同步只能同步新增的命令,如果主库上已有数据,则需要事先手动拷贝到从库上。拷贝过程可以借助第三方工具,这里不做讨论。主从同步步骤如下:
给主库上全局读锁,防止有新数据写入:
mysql> use dclett; Database changed mysql> flush tables with read lock; Query OK, 0 rows affected (0.00 sec)查看主库 master 状态:
mysql> show master status; +---------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +---------------+----------+--------------+------------------+-------------------+ | binlog.000001 | 156 | dclett | | | +---------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)接下来需要在从库上面进行连接主库的操作:
mysql> CHANGE MASTER TO GET_MASTER_PUBLIC_KEY = 1; # 请求公钥 Query OK, 0 rows affected (0.02 sec) mysql> change master to master_host='mysql-master',master_port=3306,master_user='root',master_password='111111',master_log_file='binlog.000001',master_log_pos=156; Query OK, 0 rows affected, 2 warnings (0.01 sec)开启从库:
mysql> start slave; Query OK, 0 rows affected, 1 warning (0.01 sec)查看同步状态:
mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: mysql-master Master_User: root Master_Port: 3306 Connect_Retry: 60 Master_Log_File: binlog.000001 Read_Master_Log_Pos: 156 Relay_Log_File: d0ae93470c94-relay-bin.000002 Relay_Log_Pos: 321 Relay_Master_Log_File: binlog.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: dclett Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 156 Relay_Log_Space: 537 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 Master_UUID: dfa84fee-888a-11eb-b60d-0242ac120002 Master_Info_File: mysql.slave_master_info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: Master_public_key_path: Get_master_public_key: 1 Network_Namespace: 1 row in set, 1 warning (0.00 sec)当出现两个 Yes 的时候(
Slave_IO_Running: Yes、Slave_SQL_Running: Yes),说明主从同步配置成功。这时,我们将主库的全局读锁解除:mysql> unlock tables; Query OK, 0 rows affected (0.00 sec) mysql> insert into dc_user values (4, "Tireless"); Query OK, 1 row affected (0.00 sec)从库上面已有新增的数据:
mysql> select * from dc_user; +----+-----------+ | id | username | +----+-----------+ | 1 | 74percent | | 2 | Girofle | | 3 | 1314 | | 4 | Tireless | +----+-----------+ 4 rows in set (0.00 sec) -
主从切换
如果是正常情况下的主从切换,则操作比较简单,步骤如下:
-
给主库上全局读锁,避免新数据写入。
-
查看从库同步状态:
mysql> SHOW PROCESSLIST\G; *************************** 1. row *************************** Id: 5 User: event_scheduler Host: localhost db: NULL Command: Daemon Time: 9879 State: Waiting on empty queue Info: NULL *************************** 2. row *************************** Id: 9 User: system user Host: connecting host db: NULL Command: Connect Time: 7419 State: Waiting for master to send event Info: NULL *************************** 3. row *************************** Id: 10 User: system user Host: db: NULL Command: Query Time: 6976 State: Slave has read all relay log; waiting for more updates Info: NULL *************************** 4. row *************************** Id: 12 User: root Host: localhost db: NULL Command: Query Time: 0 State: init Info: SHOW PROCESSLIST 4 rows in set (0.00 sec)出现
Slave has read all relay log; waiting for more updates则说明从库已经完全与主库同步。 -
在从库上执行以下命令:
stop slave; reset slave; reset master; -
修改原从库配置文件并重启:
binlog-do-db = dclett #replicate-do-db = dclett #read_only = 1 -
修改原主库配置文件并重启:
replicate-do-db = dclett read_only = 1 #binlog-do-db = dclett -
重复主从同步操作就可以了。
如果是不正常情况下的主从切换,比如主库一个事务已经提交(写入了 binlog 日志),然后在传输给从库的时候挂了,这时候从库直接升主库,就有丢失数据的风险。
如果主库只是实例宕机,机器没挂,那我们可以进入主库所在的机器去读取 binlog 日志,然后给从库补齐数据。此时从库升到主库,数据不会丢失。如果主库整个机器都挂了,那就没有办法了,数据肯定会丢失。
这里我们来模拟一下:
update dc_user set username = 'master' where id = 5;当我们在主库执行上述命令时,可以使用
show binlog events in 'binlog.000002'(binlog.000002 是我的 binlog 文件名,可以使用 show master status 查看)命令查看新增的 binlog 日志: -

上图中,SET @@SESSION.GTID_NEXT= 'ANONYMOUS' 代表不使用 GTID(Global Transaction Identifier),也就是全局事务 ID,这个下面再讲。真正用到的用于数据同步的是从 BEGIN 开始,到 COMMIT 结束。假设现在主库的 MySQL 实例挂了,从库没有收到 id = 5 这行记录的修改,我们只需要从主库上导出这次修改的 sql 文件,然后放到从库上执行一下,就 OK 了。具体操作步骤如下。
导出 sql 文件复制到从库:
mysqlbinlog --start-position=2467 --stop-position=2711 binlog.000002 -r log.sql
在从库上执行 sql 文件:
mysql -uroot -p111111 -v < log.sql
在实际生产中,因为数据量很大,不是很容易找到开始的 pos 和结束的 pos,那么这个时候,导出精确的 sql 文件无疑变得困难重重。此时我们就不能用 --start-position 和 --stop-position 了,而要用 --start-datetime 和 --stop-datetime,截取宕机前后的日志。这样就会有新的问题,sql 重复了怎么办?因为为了确保数据的不丢失,根据时间找的 pos 肯定是提前的。这样就会出现从库已经执行过的 sql 语句再被执行。像 update、alter 语句还好,反正执行后的最终结果都是一样的。但像 insert、delete 语句就有问题了,两次执行同样的 insert 语句会报错唯一键冲突(1062),两次执行同样的 delete 语句会报错找不到行记录(1032)。这个时候,我们只需要在从库配置文件中加入如下一句,忽略掉这两种报错就行。
slave_skip_errors = 1032,1062
mysql> show variables like 'slave_skip%';
+-------------------+-----------+
| Variable_name | Value |
+-------------------+-----------+
| slave_skip_errors | 1032,1062 |
+-------------------+-----------+
1 row in set (0.00 sec)
注意:在从库升主库之后,一定要把这个参数注释掉,避免之后真的出现了主从数据不一致,也跳过了。
除了上述方法,还可以使用 GTID 忽略错误。GTID 是 MySQL 5.6 版本引入的,全称是 Global Transaction Identifier,也就是全局事务 ID。是一个事务在提交的时候生成的,是这个事务的唯一标识。它由两部分组成,格式是:
GTID = server_uuid:gno
其中:
- server_uuid 是一个实例第一次启动时自动生成的,是一个全局唯一的值;
- gno 是一个整数,初始值是1,每次提交事务的时候分配给这个事务,并加1。
在 MySQL 官方文档中,GTID 格式是这么定义的:
GTID = source_id:transaction_id
source_id 就是 server_uuid,后面的 transaction_id 就是 gno。transaction_id 字面意思是事务 ID,而事务 ID 是在事务执行过程中分配的,如果这个事务回滚了,事务 ID 也会递增。而这里的 transaction_id 是在事务提交的时候才会分配,所以改成 gno 方便区分也避免误解。
我们可以在 MySQL 配置文件中加入如下两行,开启 GTID。
gtid_mode = on
enforce_gtid_consistency = on
在 GTID 模式下,每个事务都会跟一个 GTID 一一对应。这个 GTID 有两种生成方式,而使用哪种方式取决于 session 变量 gtid_next 的值。
- 如果 gtid_next=automatic,代表使用默认值。这时,MySQL 就会把 server_uuid:gno 分配给这个事务。
- 记录 binlog 的时候,先记录一行
SET @@SESSION.GTID_NEXT = 'server_uuid:gno'; - 把这个 GTID 加入本实例的 GTID 集合。
- 记录 binlog 的时候,先记录一行
- 如果 gtid_next 是一个指定的 GTID 的值,比如通过
set gtid_next = 'current_gtid’指定为 current_gtid,那么就有两种可能:- 如果 current_gtid 已经存在于实例的 GTID 集合中,接下来执行的这个事务会直接被系统忽略;
- 如果 current_gtid 没有存在于实例的 GTID 集合中,就将这个 current_gtid 分配给接下来要执行的事务,也就是说系统不需要给这个事务生成新的 GTID,因此 gno 也不用加1。
注意:一个 current_gtid 只能给一个事务使用。这个事务提交后,如果要执行下一个事务,就要执行 set 命令,把 gtid_next 设置成另外一个 gtid 或者 automatic。
这样,每个 MySQL 实例都维护了一个 GTID 集合,用来对应“这个实例执行过的所有事务”。
当我开启 GTID 后,就可以使用如下命令建立主从同步:
change master to master_host='mysql-master',master_port=3306,master_user='root',master_password='111111',master_auto_position=1;
可以看到,已经不再需要 master_log_file 和 master_log_pos 了。
当我在主库提交事务时,会发现 Executed_Gtid_Set 里面已经有了 GTID:
mysql> update dc_user set username = 'slave_' where id = 6;
Query OK, 1 row affected (0.00 sec)
mysql> show master status\G;
*************************** 1. row ***************************
File: binlog.000001
Position: 476
Binlog_Do_DB: dclett
Binlog_Ignore_DB:
Executed_Gtid_Set: dfa84fee-888a-11eb-b60d-0242ac120002:1
1 row in set (0.00 sec)
此时,如果主库要给从库同步一个已经存在的值,就会产生唯一键冲突,影响到从库的数据同步,Slave_SQL_Running 已经变成了 No。
2021-03-23T09:34:36.416080-00:00 10 [ERROR] [MY-010584] [Repl] Slave SQL for channel '': Could not execute Write_rows event on table dclett.dc_user; Duplicate entry '7' for key 'dc_user.PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000001, end_log_pos 1061, Error_code: MY-001062
我们需要做的就是手动提交一个空事务,将主库上的 GTID 加入到从库中的 GTID 集合中。show slave status\G 命令可以查看到是哪个 GTID 执行失败,Executed_Gtid_Set 代表已经执行好了的 GTID 集合,Retrieved_Gtid_Set 代表接收到了的 GTID 集合。
set gtid_next='dfa84fee-888a-11eb-b60d-0242ac120002:3';
begin;
commit;
set gtid_next=automatic;
start slave;
mysql> set gtid_next='dfa84fee-888a-11eb-b60d-0242ac120002:3';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
mysql> set gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: mysql-master
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000001
Read_Master_Log_Pos: 1409
Relay_Log_File: d0ae93470c94-relay-bin.000002
Relay_Log_Pos: 1618
Relay_Master_Log_File: binlog.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB: dclett
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1409
Relay_Log_Space: 1834
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: dfa84fee-888a-11eb-b60d-0242ac120002
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: dfa84fee-888a-11eb-b60d-0242ac120002:1-4
Executed_Gtid_Set: dfa84fee-888a-11eb-b60d-0242ac120002:1-4,
ffb87746-8892-11eb-8e88-0242ac130002:1
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 1
Network_Namespace:
1 row in set, 1 warning (0.01 sec)
很明显,使用 GTID 既方便,又安全。
上面说的主从同步方式都是 MySQL 默认的异步复制,这种是性能最高的同步方式,也是最不安全的。当主库所在的机器在同步过程中宕机,则可能会出现数据丢失的情况。为了避免这种情况发生,MySQL 还支持半同步复制和全同步复制。
半同步复制是 MySQL 5.5 开始以插件的形式支持的,意思是主库在收到一台从库的返回信息时,才会提交事务。否则等待超时,会切成异步复制再提交。
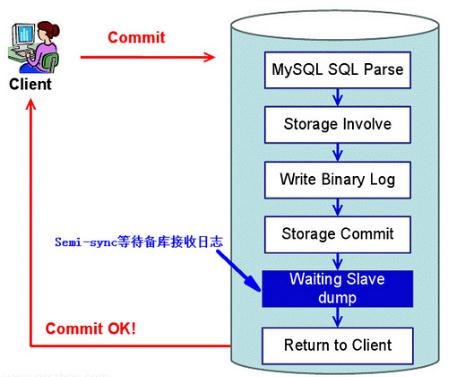
上图所示的半同步方式是老的方案,Storage Commit 代表在引擎层提交事务,然后才是等待从库返回。这样就会出现一个问题,当主库等待从库 dump 的时候,其实主库已经 commit 了,此时客户端还是未提交状态,其他客户端已经能读到这个事务了。如果这个时候主库宕机,就有可能出现这两种情况:
-
事务还没发送到从库上
客户端收到事务提交失败的信息(其实主库已经提交成功了),会重新提交该事务到新主库上,此时宕机的主库重启后,以从库的身份加入到新主从结构中,会发现事务提交了两次。一次是之前宕机的主库提交的,一次是被新主库同步过来的。
-
事务已经发送到从库上
此时,从库已经收到并且应用了该事务,但是客户端仍然会收到事务提交失败的消息(其实老的主库已经提交成功了),会重新提交该事务到新的主库上。
针对上述问题,MySQL 5.7 优化了半同步复制,将 Waiting Slave dump 放到了 Storage Commit 前面。主库在收到从库应答后,才会提交事务。体现在 rpl_semi_sync_master_wait_point 参数的值在 MySQL 5.7 之后默认为 AFTER_SYNC,老的同步方案默认值为 AFTER_COMMIT。
要使用半同步复制,只需要在配置文件中加入如下几行:
# master
plugin_load = "rpl_semi_sync_master=semisync_master.so" # 加载 master 半同步组件
rpl_semi_sync_master_enabled = 1 # master 开启半同步
rpl_semi_sync_master_timeout = 3000 # 超时时间,超时后转为异步同步
# slave
plugin_load = "rpl_semi_sync_slave=semisync_slave.so" # 加载 slave 半同步组件
rpl_semi_sync_slave_enabled = 1 # slave 开启半同步
重启之后建立主从关系,查看半同步是否在运行:
# master
mysql> show status like 'rpl_semi_sync_master_status';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| Rpl_semi_sync_master_status | ON |
+-----------------------------+-------+
1 row in set (0.00 sec)
# slave
mysql> show status like 'rpl_semi_sync_slave_status';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
1 row in set (0.00 sec)
此时如果从库都挂掉的话,主库会在半同步等待超时后改为异步复制。等从库重启后,主库察觉到从库的连接时,会再次开启半同步复制,并且会将之前同步失败的数据再次同步给从库,保证了数据的一致性。
mysql> insert into dc_user values (9, 'semi_sync');
Query OK, 1 row affected (3.01 sec)
如果主库挂掉了,也分两种情况:
-
事务还没发送到从库上
主库没有提交事务,从库也没有提交事务,主从切换后没有任何影响。
-
事务已经发送到从库上
主库还没来得及提交事务就挂掉了,从库收到并且应用了该事务,但是客户端仍然会收到事务提交失败的消息,会重新提交该事务到新的主库上。(这里还是有问题的,MySQL 集群只能保证数据不丢失,不能保证数据一致性。不管怎么样,多了数据总比少了要好。)
全同步复制指的是所有的从库都 ACK 主库后,主库才 Commit。一主一从下,半同步等于全同步。生产环境是不可能使用全同步的。
参考资料:《MySQL实战45讲》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号